目录
一、SoC总线结构
二、NoC结构
2.1 NoC层次
2.2 NoC基本组成和属性
2.3 NoC常见的拓扑结构
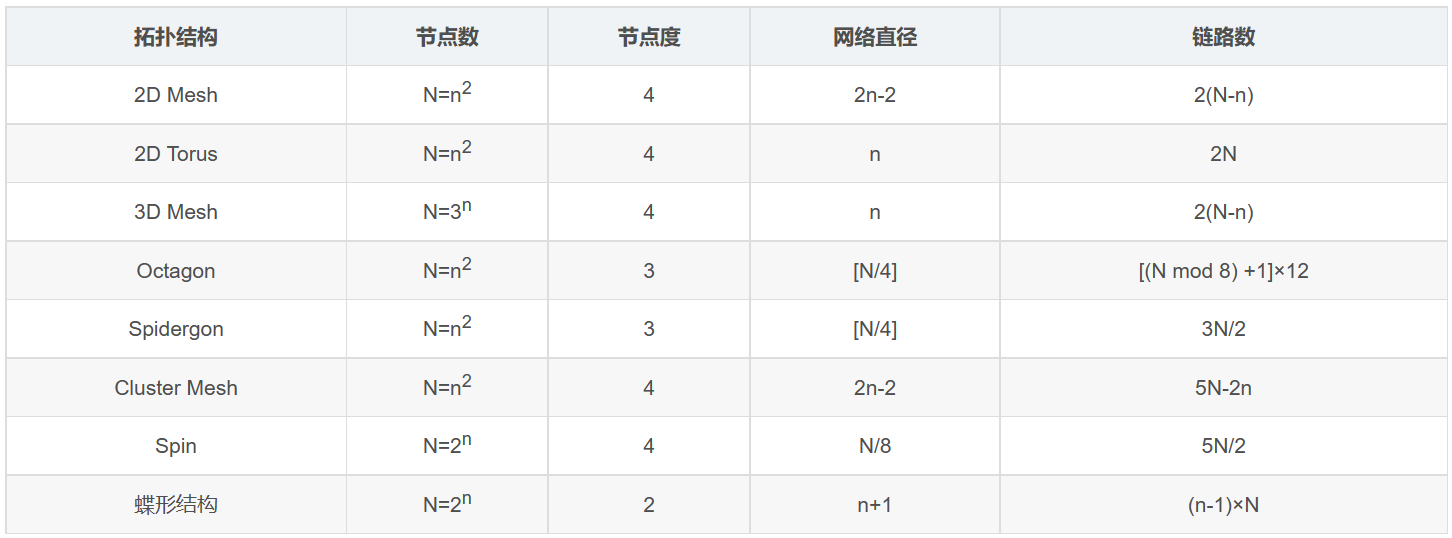
2.3.1 2D Mesh
2.3.2 2D Torus
2.3.3 3D Mesh
2.3.4 Octagon/Spidergon结构
2.3.5 Cluster Mesh结构
2.3.6 树状结构
2.3.7 蝶状结构
2.4 各种结构之间的比较
2.5 NoC优势
三、Chiplet的通信结构
一、SoC总线结构
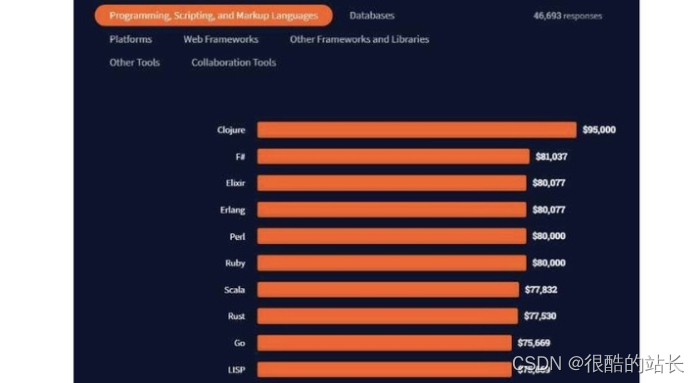
随着SoC所包含的IP核数目的增加,特别是片上计算资源的快速增加,片上模块间通信对SoC系统性能的影响也随之增大。片上连接方式成为影响SoC的关键因素。SoC系统片内各组件间通信方式一直采用传统的总线通讯方式,典型的SoC结构如下图所示。虽然人们对片上总线技术作了很多改进,从单一的共享总线改进为多总线的桥接,甚至层次化总线等更复杂的结构。但是,当MPSoC集成的处理器越来越多时,仍无法解决片上通信问题,如Sony 公司的Emotion Enginel1.101和IBM公司的CELL。
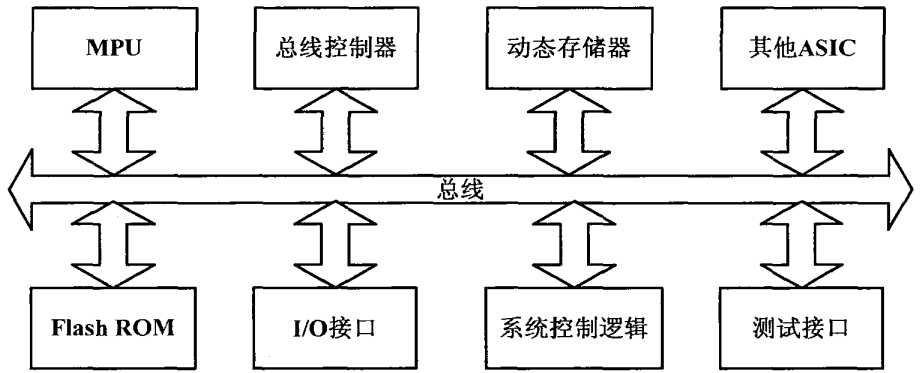
典型的SoC结构
SoC的总线结构在性能、功耗、延迟信号完整性、时钟同步和可靠性等方面面临着巨大的挑战,成为限制 MPSoC发展的主要瓶颈。
- 设备扩展性。总线限制了所连接的设备的数量。总线是一种共享介质的互连结构,只能实现共享信道的通信。某一时刻只允许一个设备使用总线,在总线被占用期间,其他所有请求被阻塞,直到总线空闲。当多个设备同时争用一条总线时,就会带来严重的竞争冲突,降低信道的吞吐量。
- 信号完整性。随着特征尺寸的减小和集成电路规模的增大,互连线宽度及间距相应减小,线间耦合电容则相应增大,细长的全局并行总线会引起较大的信号串扰,影响信号完整性及传输正确性,导致额外的延迟。而且导线越长电阻越大,将消耗大量的能量。
- 信号延迟。随着集成特征尺寸的下降,连线延迟成为影响信号延迟的主要因素。总线结构为全局控制,在10亿晶体管时代,全局连线延迟大于时钟周期,因此,总线结构的全局连线使得时钟的偏移很难管理。
- 全局同步。总线结构要求采用全局同步时钟,随着芯片集成度的增加和芯片速度提高,在芯片内部将形成庞大的时钟树,片上各部分模块很难实现全局信号同步。当工艺特征尺寸在180nm 以下、工作频率达到几个GHz时,时钟信号的布线成为最为棘手的问题。虽然采用时钟树(Clock Tree)优化的方法可以改善由时钟翻转信号引起的时钟偏差和时钟抖动,但同步时钟网络所产生的动态功耗始终难以接受,甚至可占据芯片总功耗的40%以上。因此,设计单一系统时钟控制的全局同步电路变得极其困难。为了保持甚至提高系统时钟频率,只能对全局连线采用分布式流水线模式,或采用全局异步局部同步(Global Asynchronous LocalSynchronous, GALS) 时钟策略。
二、NoC结构
NoC技术是在SoC(System on Chip)基础上发展演变来的。SoC通常是指在单一芯片上实现的数字计算机系统,通过总线完成其中各模块之间的交互,但随着半导体工艺和需求的快速发展,总线的宽度已经成为SoC发展的瓶颈,大大限制了SoC内部通信的速度。上世纪90年代NoC技术被提出来解决SoC的架构问题,并一直发展到现在。
片上网络(Network on Chip, NoC) 借鉴了分布式计算系统的通信方式,采用路由和分组交换技术替代传统总线,是最有希望解决复杂片上通信问题的新方法。NoC技术从体系结构上解决了SoC的总线结构所固有的三大问题:
- 由于地址空间有限而引起的可扩展性问题
- 由于分时通讯而引起的通讯效率问题
- 以及由于全局同步而引起的功耗和面积问题
-
2.1 NoC层次
NoC技术和网络通信中的OSI(Open System Interconnection)技术有很多相似之处,NoC技术的提出也是因为借鉴了并行计算机的互联网络和以太网络的分层思想,二者的相同点有:支持包交换、路由协议、任务调度、可扩展等。NoC更关注交换电路和缓存器的面积占用,在设计时主要考量的方面也是这些。
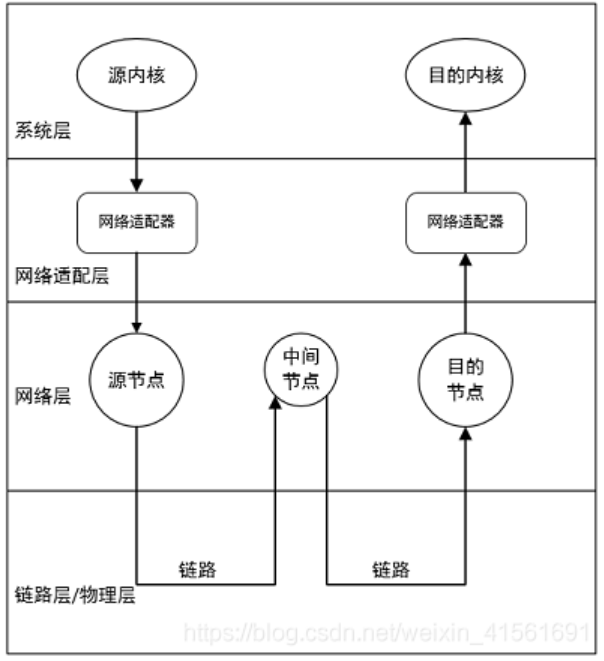
2.2 NoC基本组成和属性
NoC由计算资源和通信网络两部分组成:
- 计算资源:一般由IP核(资源节点)和本地内存组成,完成广义的“计算”任务,IP核可以是CPU、DSP、RAM、高带宽的I/O设备、可重构硬件单元等。
- 通信网络:实现计算资源之间的通信,主要包含:路由器(通信节点)、网络适配器(资源网络接口)以及网络链路(通道)。
IP核和路由器位于系统层,网络适配器位于网络适配层。所有IP核都通过网络适配器与路由器进行连接,通过一定的路由协议可以实现任意两个IP核之间的数据通信。针对NoC的这四个基本组成,也衍生出了许多的研究方向和优化途径。有效的IP核映射及拓扑结构,能够缩短路由跳数,减少通信量,避免数据拥塞。合理的缓冲分配、可靠的交换技术、高效的路由算法以及合理的功耗管理策略可以提高通信效率,降低整体功耗。
- 资源节点:主要包含计算节点和存储节点。计算节点包含处理器即IP核(CPU、DSP等),存储节点包含ROM、RAM、DRAM、SDRAM等
- 通信节点:即路由节点或路由器,主要负责完成IP核之间的数据通信任务。NoC中资源节点产生一个数据包后,会通过特定的接口发送到源路由器中,源路由器会读取数据包的头微片中的地址信息,通过特定的路由算法计算出最佳路由路径,从而树立可靠的传输到目的节点,最终由目的IP核接收此信息。
- 资源网络接口:其功能就是作为通信节点与功能节点之间的接口。主要功能有完成数据包的封装与解封装,在源节点的资源网络接口中将原地址信息以及目的地址信息等封装到数据包的头微片中;在目的节点的资源网络接口中将原地址信息以及目的地址信息等删除。
- 通道:实质为双向金属链路,用以保证节点间的数据传输。分为内部通道和外部通道,内部通道为资源节点和通信节点之间的金属链路,外部通道指通信节点之间的金属链路。
NoC的基本属性包括:
- 节点度:一个节点与相邻节点连接链路的数目。
- 网络直径:网络中任意两个节点之间的最短路径的长度的最大值,与网络的通信延迟成线性正比关系。
- 平均最短距离:网络中任意两IP节点之间的最小距离的和与该和所包含的路径数之比。
- 网络规模:网络中节点的数目。
- 可扩展性:网络模块的可扩展能力,扩展必须伴随着所期望的性能按比例地提高。
2.3 NoC常见的拓扑结构
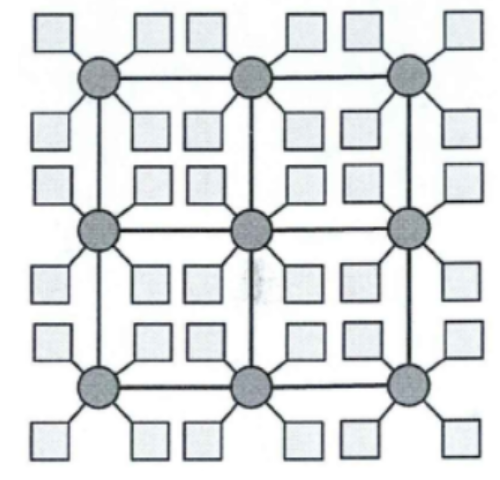
2.3.1 2D Mesh
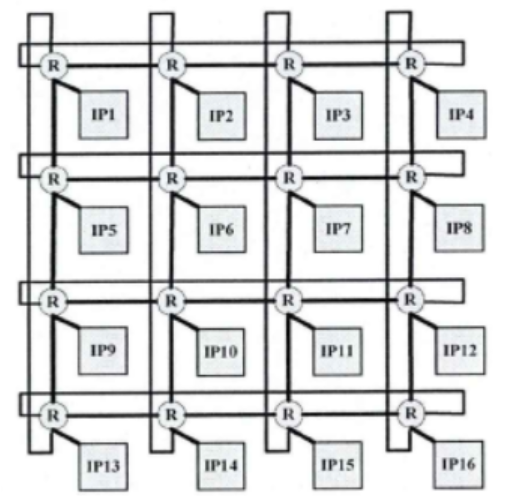
2D Mesh结构为二维网格架构,路由器节点按二维网格的方式排列,每个节点上再连接网络适配器和IP核。下图所示为一个4×4的2D Mesh结构。
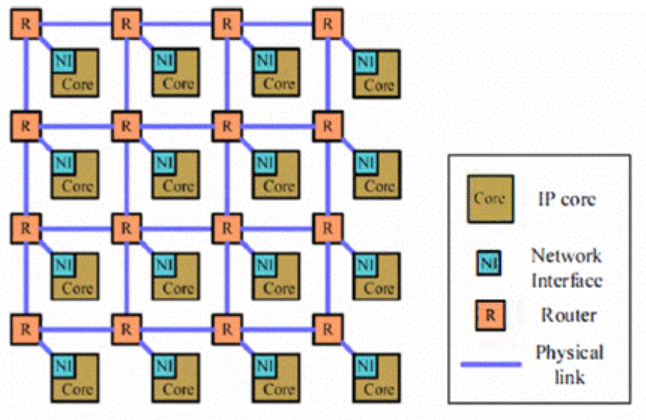
在 N×N 的2D Mesh中,每个节点与相邻的节点连接(边界节点除外)。该结构具有结构简单,易于实现,可扩展性好等优点,较为广泛使用。
2.3.2 2D Torus
将2D Mesh结构的每行首尾节点连接起来,每列的首位节点也连接起来,便是2D Torus结构,该结构每个节点在几何上都是等价的,缩短了节点间的平均距离,减小了网络直径,同时该结构可能因为过长的环形链路而产生额外的延迟。
2.3.3 3D Mesh
3D Mesh为三维的网格结构,将多个2D Mesh叠加并对应节点连接起来,这样做进一步降低了网络直径和平均距离,但物理实现难度比较大。
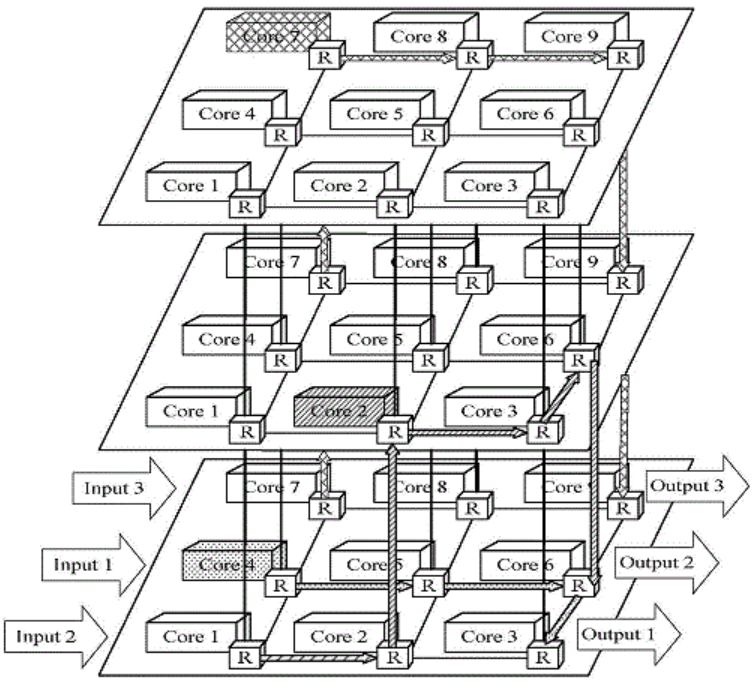
2.3.4 Octagon/Spidergon结构
Octagon为八边形结构,共包含8个IP核,每个节点与三个节点相连,分别是序号相邻的节点和最远的节点。该结构也可以扩展为8个以上节点,变为Spidergon结构。
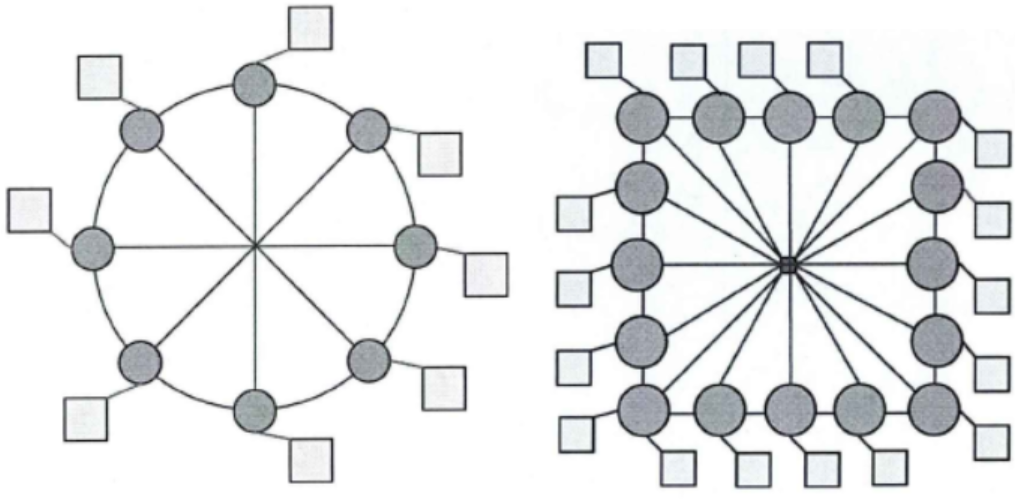
2.3.5 Cluster Mesh结构
Cluster Mesh 结构改变了传统的一个IP核连接一个路由器,将4个IP核连接1个路由器。这样做减少了路由器数量,简化了拓扑结构,但更容易造成数据拥塞。
2.3.6 树状结构
该结构类似于数据结构中的树结构,IP为叶子节点,路由器节点作为父节点,在父节点之上可以在增加父节点,层层相扣。降低了设计难度,也降低了物理设计的复杂度。
SPIN结构是一种树状结构,具有16个叶子节点以及8个路由器节点。每个节点拥有4个父节点,通过增加路由节点冗余度的方式,增加多路径选择性,提高系统性能。但是该结构的路由节点复杂,芯片实现难度大。
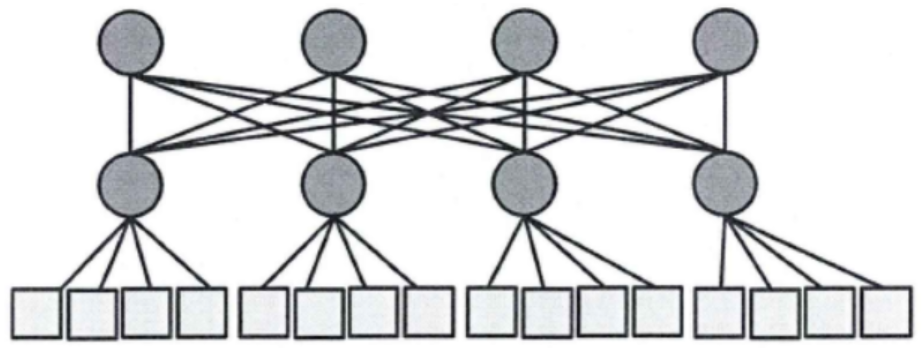
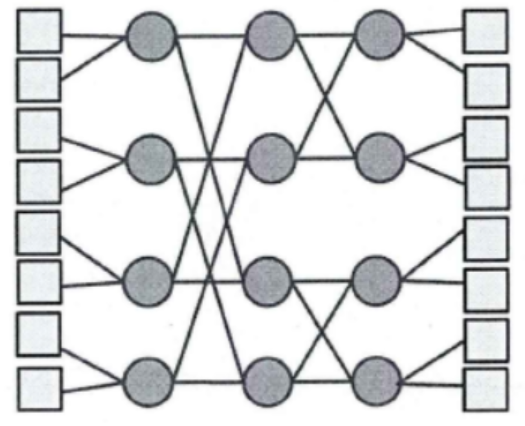
2.3.7 蝶状结构
该结构有些类似于FFT中的结构,是一种对数结构。一个n维的蝶形拓扑结构由2n个IP核和n×(2n-1)个路由器的节点组成,路由器分为n层,每层有N/2个路由器。
2.4 各种结构之间的比较
2.5 NoC优势
- 良好的可扩展能力。一方面,相比于SoC架构,不在受限于总线架构,可以扩展任意数量的计算节点。另一方面,需要对系统功能进行扩展时,只需要将设计好的功能模块通过资源网络接口植入网络,无需重新设计网络整体架构。
- 较高的通信效率。一方面NoC将IP核之间的数据传输演变成为路由器之间的数据转发,IP核节约了一部分的计算资源。另一方面避免了总线架构同一时刻只能有一对通信节点进行通信的问题,可以实现同一时刻多对节点通信。
- 功耗。NoC中采用全局异步局部同步的时钟机制,其功耗开销远低于SoC。NoC中局部模块运用同步时钟域,而全局上采用异步时钟,降低了由于全局时钟同步所带来的动态开销,同时,NoC中的时钟树设计复杂度也低于SoC。
三、Chiplet的通信结构
芯片的主流通信结构有总线和片上网络2种,但是目前Chiplet之间的通信没有统一的标准,各个厂商都有自己的通信方案。例如AMD采用的可扩展数据结构(SDF),TSMC采用的LIPINCON技术,Intel采用的高级接口总线(advanced interface bus,AIB)和其他厂商的NoC结构。具体可参看:(10条消息) 傻白探索Chiplet,互连技术研究现状(七)_好啊啊啊啊的博客-CSDN博客
本文不讨论具体的通信细节和标准协议,只讨论各个产商采取的通信结构。大多数Chiplet之间的通信结构还是基于总线和NoC的创新。例如AMD的第1代EPYC处理器就是类似总线的通信结构,没有路由节点,芯片之间只能进行边到边的通信。第2代EPYC处理器就类似于NoC的结构,中间的I/O芯片是起到节点路由的功能,所有的芯片通信都必须通过它来调度。
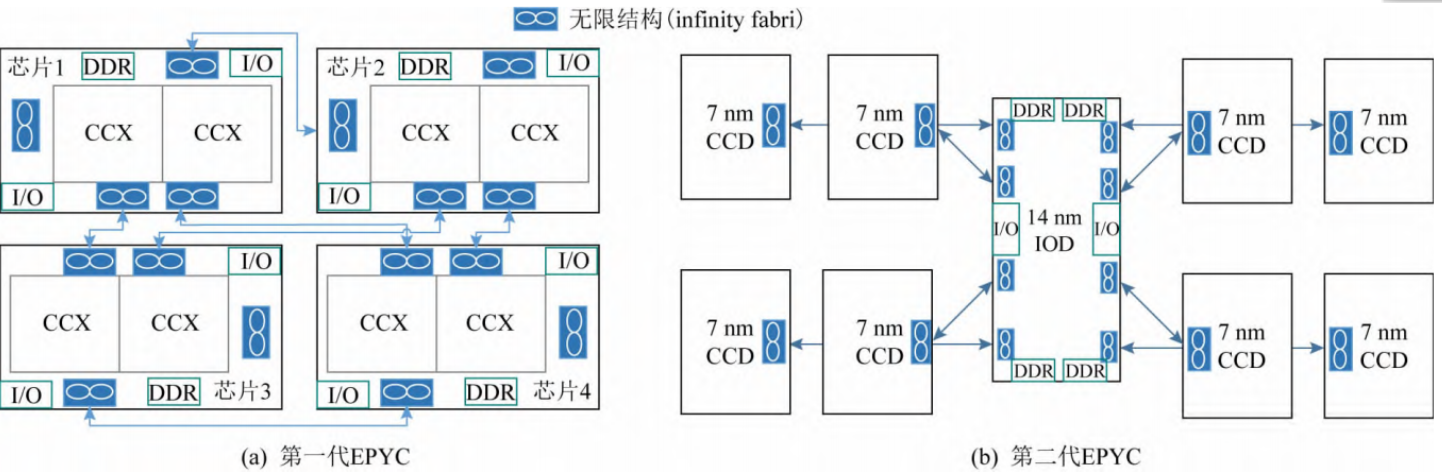
基于总线的通信结构更加简洁,没有路由节点的开销,但是一旦Chiplet的数量过多,通信就会变得低效,并且只针对边到边的通信结构也不支持多个芯片通信。
如果采用路由节点,以第2代EPYC为例,芯片设计以I/O芯片为核心,将计算芯片变成可扩展的部分,如图(b),所有计算芯片通过无线结构和I/O芯片相连,数据的输入输出由I/O芯片统一调配,各个计算芯片之间没有数据通信。这就消除了原先计算芯片之间相连,但是只能边与边通信的限制。并且采用I/O芯片统一调配的方式还可以有效降低芯片通信死锁的风险,缺点是所有芯片的通信都必须通过I/O芯片,一旦芯片过多,需要设计高效的仲裁算法且仍会效率降低。解决方案是采用中介层来实现片上网络。
不同中介层实现NoC的方法不同,为了在有源中介层中实现NoC,我们只需将NoC链接(电线)和路由节点(晶体管)都放在中介层,下图(a)显示一个小型的采取有源中介层的NoC实例,其中NoC的链接和节点全部在中介层上。如果使用无源中介层,不能放有源器件,如下图(b),将路由器的活动组件(例如缓冲区、仲裁器)放置在CPU裸片上,但是NoC链接仍使用中介层的路由资源。这种方法可以利用中介层的金属层进行NoC路由,但要花费一些CPU裸片来实现NoC的逻辑组件。下图中的2个NoC在拓扑和功能上都是相同的。
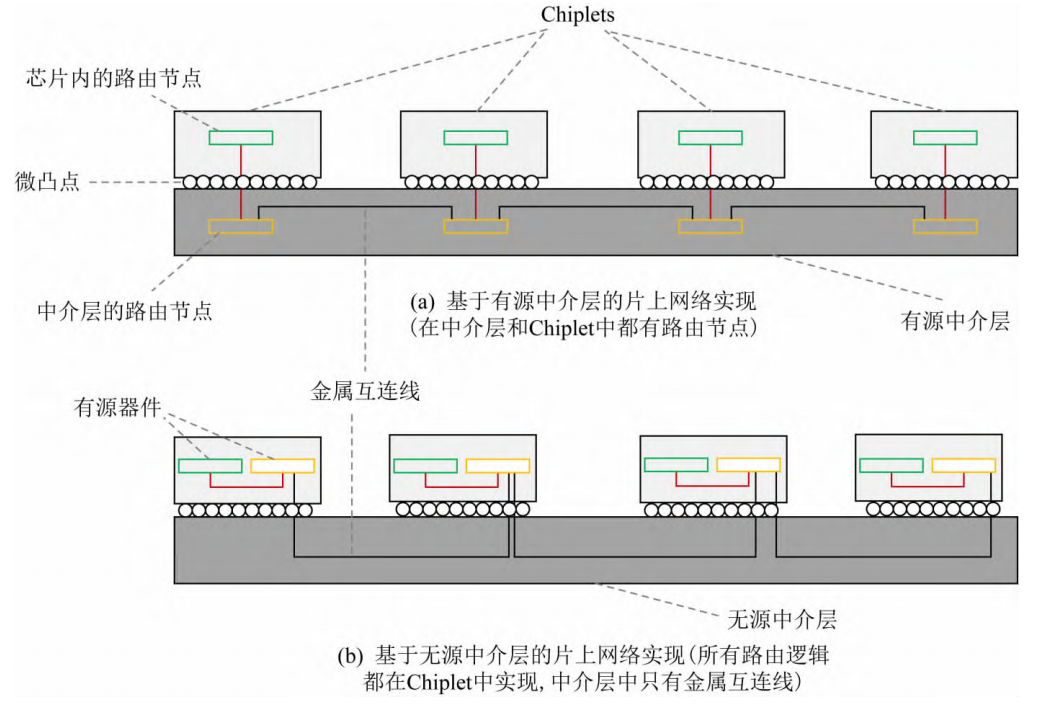
基于中介层的NoC结构更加高效,但是节点开销较大,不过在大量Chiplets通信的情况下性能更好。NoC提供了统一的接口来连接不同的系统组件。NoC方法不是要求系统设计人员对每个通信模块之间实现特定的接口,而是采用了模块化和可扩展性更高的设计方法,从而使不同的小芯片自然地组合在一起。
路由会显著影响网络性能、可靠性和功耗。设计不正确的路由算法可能会导致网络中的资源依赖关系,从而导致死锁,这可能对系统造成致命影响。解决死锁的方案有虚拟通道和转向模型,其中虚拟通道必须提前配置且每个虚拟通道都有自己的输入缓冲区,增加虚拟通道的数量会增大NoC的面积,代价很高;另外,在3D NoC中,基于转向的算法要求每个路由节点都与其他芯片层垂直连接,增加了每个芯片层的TSV区域开销,代价也很高。
因此,针对这种具有各种拓扑结构的小芯片系统,南加州大学和多伦多大学联合提出了一种模块化的,没有死锁的路由方法(Modular routing,具体见参考资料2)。该方案无需了解其他Chiplet或中介层NoC的详细信息,每个Chiplet都可以单独设计。从任何一个Chiplet的角度看,系统的其他部分(与Chiplet的总数或者中介层的复杂性无关)都可以看作1个虚拟节点,然后应用了转向限制的边界路由将Chiplet和虚拟节点连接起来,这种模块化的方法易于分析和优化Chiplet的粒度。

基于有源介质的3D封装
参考资料:
Chiplet封装结构与通信结构概述_陈桂林
Modular Routing Design for Chiplet-Based Systems | IEEE Conference Publication | IEEE Xplore (7条消息) 片上网络NOC(Network on Chip)相关总结转载~_一起倾听丶的博客-CSDN博客_片上网络
(7条消息) NoC(Network on Chip)学习笔记(2)_Tommyll的博客-CSDN博客_forwarding-noc
(7条消息) NoC(Network on Chip)学习笔记(1)_Tommyll的博客-CSDN博客_noc学习








![[思维模式-10]:《如何系统思考》-6- 认识篇 - 结构决定功能,如何进行深度思考](https://img-blog.csdnimg.cn/d2c91c7b9731473199f34c5eca510db0.png)
