机器学习的定义
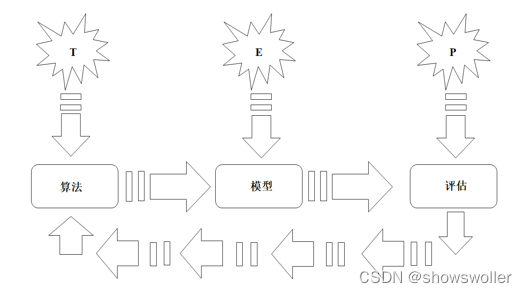
机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。机器学习的构建过程是利用数据通过算法构建出模型并对模型进行评估,评估的性能如果达到要求就拿这个模型来测试其他的数据,如果达不到要求就要调整算法来重新建立模型,再次进行评估,如此循环往复,最终获得满意的经验来处理其他的数据。
机器学习的分类
1:监督学习
通过已有的训练样本(即已知数据以及其对应的输出)训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。例如分类、回归和推荐算法都属于有监督学习。
2:无监督学习
根据类别未知(没有被标记)的训练样本,而需要直接对数据进行建模,我们无法知道要预测的答案。例如聚类、降维和文本处理的某些特征提取都属于无监督学习。
3:半监督学习
半监督学习(Semi-supervised Learning)是介于监督学习与无监督学习之间的一种机器学习方式,是模式识别和机器学习领域研究的重点问题。它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。
4:强化学习
通过观察来学习动作的完成,每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
MLlib的简介
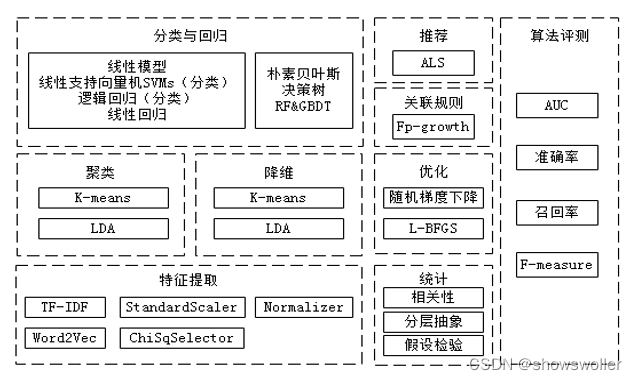
MLlib是Spark提供的可扩展的机器学习库,其中封装了一些通用机器学习算法和工具类,包括分类、回归、聚类、降维等,开发人员在开发过程中只需要关注数据,而不需要关注算法本身,只需要传递参数和调试参数。
MLlib数据类型
1:密集向量(Dense)
密集向量是由Double类型的数组支持,例如,向量(1.0,0.0,3.0)的密集向量表示的格式为[1.0,0.0,3.0]。

2:稀疏向量(Sparse)
稀疏向量是由两个并列的数组支持,例如向量(1.0,0.0,3.0)的稀疏向量表示的格式为(3,[0,2],[1.0,3.0]),其中3是向量(1.0,0.0,3.0)的长度,[0,2]是向量中非0维度的索引值,即向量索引0和2的位置为非0元素,[1.0,3.0]是按索引排列的数组元素值。

3:标注点
标注点是一种带有标签的本地向量,标注点通常用于监督学习算法中,MLlib使用Double数据类型存储标签,因此可以在回归和分类中使用标记点。

4:密集矩阵
密集矩阵将所有元素的值存储在一个列优先的双精度数组中。

5:稀疏矩阵
稀疏矩阵则将以列优先的非零元素压缩到稀疏列(CSC)格式中

创建一个3行2列的稀疏矩阵[ [9.0,0.0], [0.0,8.0],[0.0,6.0]] 第一个数组参数Array(0,1,3)表示列指针,表示每一列非零元素的索引值。 第二个数组参数Array(0,2,1)表示行索引,表示对应的非零元素是属于哪一行。 第三个数组Array(9,6,8)是按列优先排序的所有非零元素,通过列指针和行索引即可判断每个元素所在的位置。
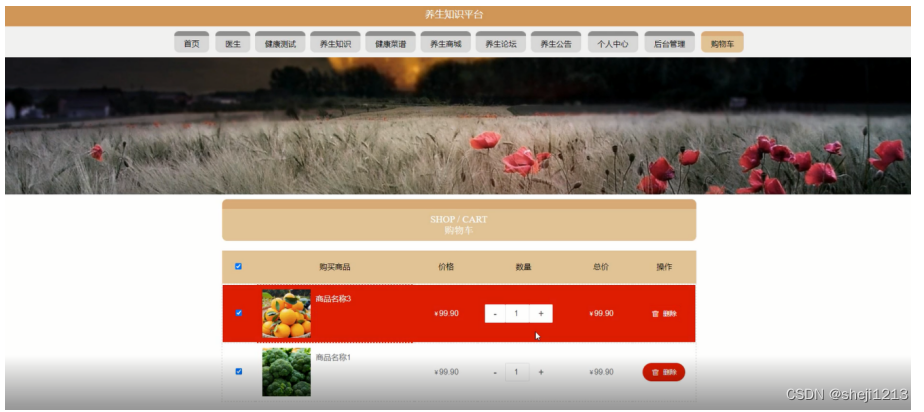
创作不易 觉得有帮助请点赞关注收藏~~~

![[oeasy]python0031_挂起进程_恢复进程_进程切换](https://img-blog.csdnimg.cn/img_convert/9f9420c17a6517a37e0382e5899934e4.png)