前言
当前大部分多模态工作都集中在图片-文本、视频-文本中,关于音频、深度图、热值图的工作则比较少,在IMAGEBIND中,作者提出了一种同时建模图片、文本、视频、音频、深度信息、热值图信息的方法,本文简要介绍,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用(https://www.zhihu.com/column/c_1265262560611299328)
微信公众号:机器学习杂货铺3号店
在互联网中,图片-文本、视频-文本对随处可得,因此近年来出现了很多采用图文、视文进行大规模预训练的工作,如CLIP、ALIGN、WenLan等。但是由于互联网中缺少大量的音频、深度图、热值图等数据对,如果对这些数据采用原先的对比学习预训练范式,则难以找到同时具有<图片, 文本, 视频, 音频, 深度图, 热值图>的数据,即是多模态数据的共现数据(co-occur)难获取。
在Image Bind [1] 中,作者提出将图片作为关联这些不同模态数据的中间桥梁,从而使得可以同时建模不同模态的语义信息,<图片, 文本>数据是在互联网中最为可得的数据,而<图片, 深度图>,<视频,音频>等模态对则是容易获得的数据,通过采用图片作为模态之间的桥梁,如Fig 1. 所示,能够将<图片, 文本>学习好的语义在其他模态之间传递,从而其他模态也能得到充分的预训练。

让我们进行形式化表达, < I , M > <\mathcal{I}, \mathcal{M}> <I,M>表示一个图片-模态M的数据对,其中的模态M可以是文本、音频、深度图、热值图以及IMU数据等,用 f ( ⋅ ) f(\cdot) f(⋅)和 g ( ⋅ ) g(\cdot) g(⋅)表示编码器,那么给定图片 I i I_{i} Ii和对应模态的成对样本 M i M_{i} Mi,有 q i = f ( I i ) , k i = g ( M i ) q_i = f(I_i), k_i = g(M_i) qi=f(Ii),ki=g(Mi)。通过infoNCE损失函数进行建模,如公式(1)所示,其中 τ \tau τ为温度系数,具体作用可见 [2]。通常对于模态对 < I , M > <\mathcal{I}, \mathcal{M}> <I,M>,会采用双向的对比损失,即是 L I , M = L < I , M > + L < M , I > L_{\mathcal{I}, \mathcal{M}} = L_{<\mathcal{I}, \mathcal{M}>}+L_{<\mathcal{M}, \mathcal{I}>} LI,M=L<I,M>+L<M,I>。在训练过程中,文本编码器采用了CLIP中的text encoder,图片编码器采用了CLIP中的image encoder,两者的参数都在Image Bind训练过程中被冻结,只有其他模态(音频、视频、IMU等等)的编码器会被更新,因此可视为其他模态的embedding往着图片、文本模态的embedding空间对齐。
L < I , M > = − log exp ( q i T k i / τ ) exp ( q i T k i / τ ) + ∑ j ≠ i exp ( q i T k j / τ ) (1) L_{<\mathcal{I}, \mathcal{M}>} = -\log{\dfrac{\exp(q_i^{\mathrm{T}} k_i / \tau)}{\exp(q_i^{\mathrm{T}} k_i / \tau)+\sum_{j \neq i} \exp(q_i^{\mathrm{T}} k_j / \tau)}} \tag{1} L<I,M>=−logexp(qiTki/τ)+∑j=iexp(qiTkj/τ)exp(qiTki/τ)(1)
让我们再细看Fig 1.的框架,不难发现图片与音频、IMU数据的关联,是通过视频作为媒介去传递的,这一点不难理解,图片和音频,图片和IMU很难采集共现的数据,而在视频中则很容易收集(特别是音频,IMU则在某些数据集中可得,比如Ego4D dataset)。通过图片/视频作为桥梁进行语义传递的方式,即便训练时候采用的多模数据对是 < I , M 1 > <\mathcal{I}, \mathcal{M}_{1}> <I,M1>和 < I , M 2 > <\mathcal{I}, \mathcal{M}_{2}> <I,M2>,没有显式出现 < M 1 , M 2 > <\mathcal{M}_1, \mathcal{M}_{2}> <M1,M2>的数据对,也能隐式地学习到 < M 1 , M 2 > <\mathcal{M}_1, \mathcal{M}_{2}> <M1,M2>的关联。这就有点像NLP任务,提供了中英文对、中日文对,即便没有显式的英文-日文对,也能学到日文-英文的语义关联。这种能力,作者称之为涌现(emergency)。
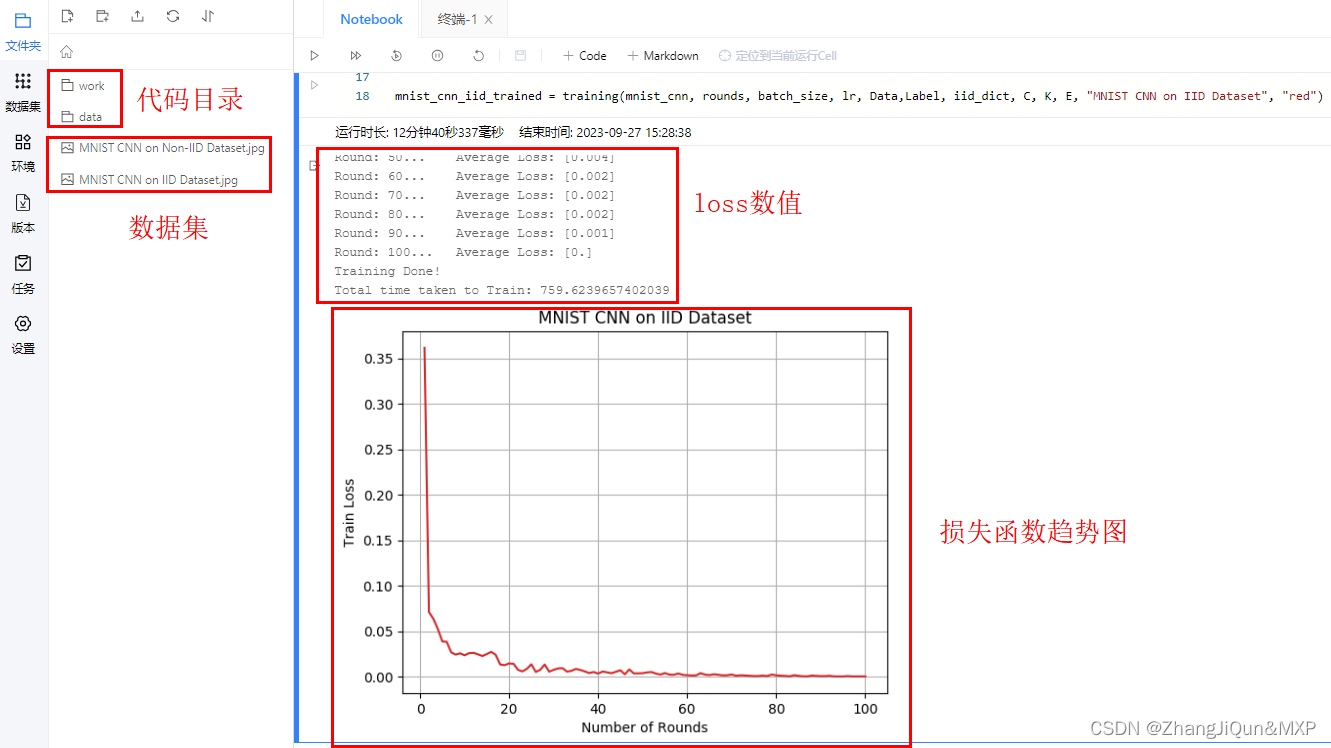
为了验证这种能力,作者在zero-shot任务上进行了若干实验,笔者只摘取其中一个结果进行说明,如Fig 2.所示,MSR-VTT是视频检索数据集,即便训练数据中并没有显式地见过文本-音频数据,但是其文本-音频检索的效果仍然能比肩一些文本-视频检索的方法,如MIL-NCE,这说明了这种训练方式能间接地学习出不同模态之间的关联,将所有模态的嵌入表达(Embedding)都往着视觉方向靠拢。读者也可以参考Fig 3.,其中IMAGEBIND一行表示的是zero-shot 分类的能力(通过文本prompt激发分类能力,用蓝色区域表示),不难发现,即便没有文本-视频、文本-深度图、文本-音频等显式的数据对,其zero-shot分类能力也比较可观,这进一步证实了多个模态之间的表征能够通过图片作为中介进行对齐。至于其他实验数据和细节分析,读者若感兴趣请自行翻阅论文 [1]。


作者为了证实这些效果是由于不同模态的特征向着图片特征对齐导致的,进行了一些可视化分析,如Fig 4. (a) 所示,给定一个图片
I
I
I和一个声音
M
M
M,那么将其表征相加后,有
e
=
f
(
I
)
+
g
(
M
)
e = f(I)+g(M)
e=f(I)+g(M),然后用相加后的表征在图片数据中进行最近邻检索,取top4结果。不难发现top 4结果很好的结合了原始图片和音频的语义,这意味着实现了音频特征向着图片特征的语义对齐。如Fig 4. (b) 所示,还能用音频作为query,指定物体检测的目标,这也同样说明了这件事情。

对于笔者而言,这篇论文的价值在于探索了一种切实可行的,让真正意义多模态(音频、视频、IMU、热值图、文本等)数据进行语义对齐的途径,从而不依赖与不同多模态数据的完美成对共现,要知道现实中很多数据都是异构的,本论文能让我们充分利用异构的多模态数据进行预训练。无论是多模还是单模的异构数据的使用,能够大大增加模型的表征能力,实现1+1 > 2的效果,笔者认为这必然是未来趋势,值得继续关注。
Reference
[1]. Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K. V., Joulin, A., & Misra, I. (2023). Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 15180-15190).
[2]. https://blog.csdn.net/LoseInVain/article/details/125194144,《混合精度训练场景中,对比学习损失函数的一个注意点》