1、原子操作概念
在并发编程中,原子操作(Atomic Operation)是实现线程安全的基础机制之一。从宏观上看,原子操作是“不可中断”的单元,但若深入微观层面,其本质是由底层处理器提供的一组特殊指令来保证其原子性。
2、从宏观角度来看原子操作
2.1、概念
在宏观层面,原子操作被视为保证数据一致性和系统稳定性的关键。在多线程程序中,如果多个线程同时访问和修改同一数据,没有适当的同步机制,就会导致竞态条件(race condition,如果输出的结果依赖于不受控制的事件的出现顺序,那么我们便称发生了 race condition),从而引发数据不一致的问题。
例如,在多核处理器系统中,有个转账程序,假设有两个账户,里面的余额都是 500,现在要分两次从 A 账户(accountSource)转账 300 到 B 账户(accountTarget),伪代码设计如下:
Function TRANSFER (amount, accountSource, accountTarget) is
if accountSource < accountTarget then
return;
end
accountTarget.balance += amount;
accountSource.balance -= amount;
end
这两次转账操作分别有一个线程执行。如果第二次转账是在第一次转账后发生的,那么第二次转账就会判断发现 A 账户余额不足(accountSource < accountTarget),从而转账失败。
但是,如果这两次转账在两个线程内同时执行,那么就可能出现不可预测的结果。如下图,两个线程检查 A 账户余额时都是 500,都进行了转账操作,结果 A 账户最后余额是 -100,这样的结果明显是不正确的。

2.2、程序级别的实现
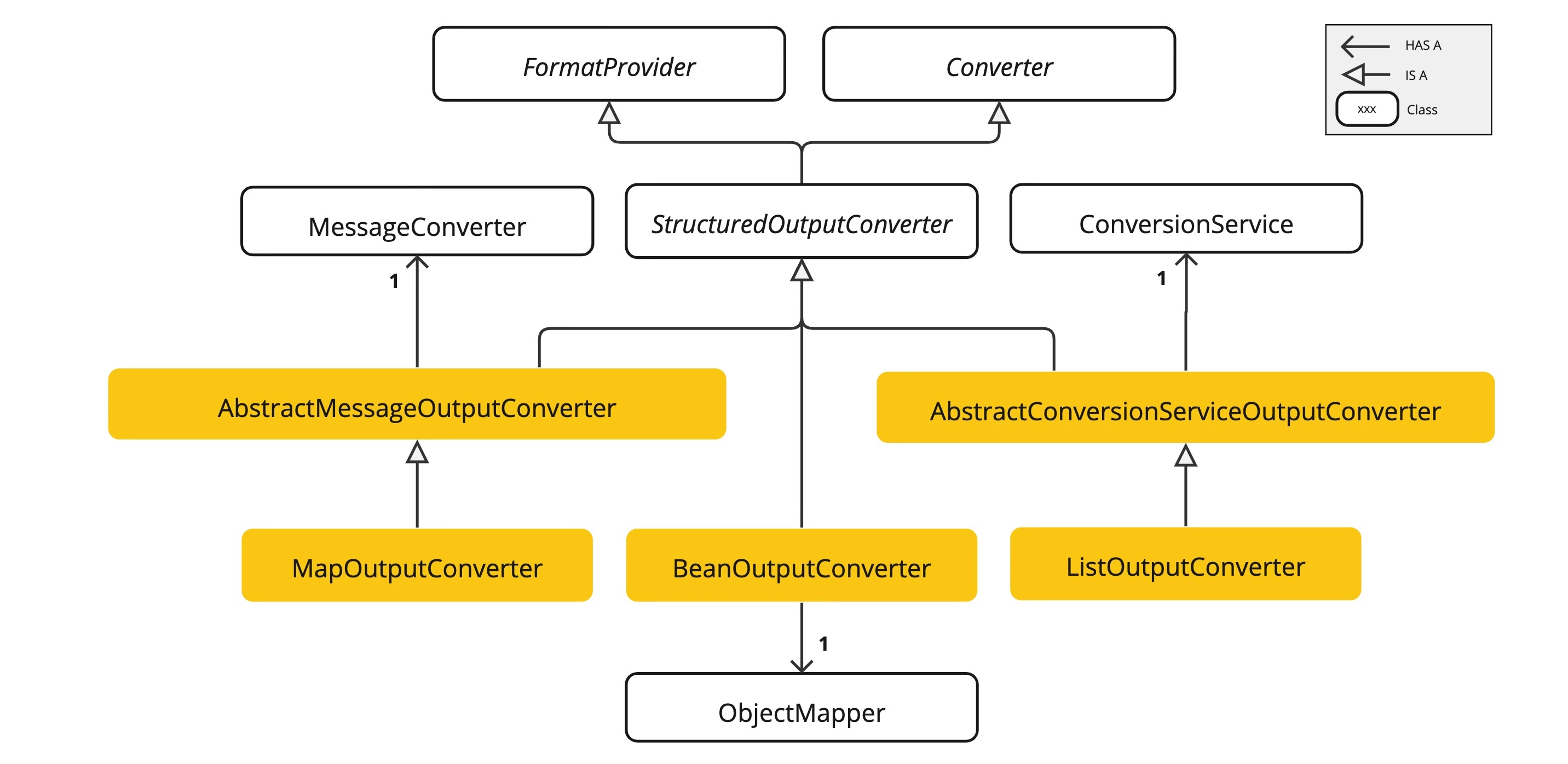
从宏观角度来看,互斥锁(Mutex)、同步锁(Synchronization Lock)、自旋锁(Spin Lock)等锁机制可以被理解为是为了确保某一操作或一系列操作在执行时具有原子性。这些锁机制是并发编程中用来控制多个线程对共享资源访问的同步工具,它们通过限制同一时间内只有一个线程可以执行特定的代码段(临界区),从而避免了竞态条件和数据不一致的问题。
操作系统中的锁——信号量(同步信号量、互斥信号量)、P/V操作、自旋锁
上面的案例,使用互斥锁就可以解决,解决方法如下:
Function TRANSFER (amount, accountSource, accountTarget) is
MutexLock(race)
if accountSource < accountTarget then
return;
end
accountTarget.balance += amount;
accountSource.balance -= amount;
MutexULock(&race)
end
3、从微观角度来看原子操作
3.1、概念
不同的架构采用不同方式实现原子语义。例如:
在 x86 架构中,通过 LOCK 前缀对读写指令加锁,以阻止总线或缓存干扰;
在 ARM 架构中,采用 LDREX / STREX 指令对指定地址建立“独占访问”监控;
而在更现代的处理器中,还结合缓存一致性协议(如 MESI)与内存屏障,实现高效的无锁同步。
从这一层面理解原子操作,不仅有助于深入掌握并发控制原理,也为构建高性能、正确性的底层系统组件奠定基础。
3.2、X86
我们首先来看下,Linux 中 x86 架构下是如何实现 “原子自增” 的。
arch\x86\include\asm\atomic.h
/**
* arch_atomic_inc - increment atomic variable
* @v: pointer of type atomic_t
*
* Atomically increments @v by 1.
*/
static __always_inline void arch_atomic_inc(atomic_t *v)
{
asm volatile(LOCK_PREFIX "incl %0"
: "+m" (v->counter) :: "memory");
}
这其中,关于宏 “LOCK_PREFIX” 的解释如下:
/*
* arch\x86\include\asm\alternative-asm.h
*/
#ifdef CONFIG_SMP
.macro LOCK_PREFIX
672: lock
.pushsection .smp_locks,"a"
.balign 4
.long 672b - .
.popsection
.endm
#else
.macro LOCK_PREFIX
.endm
#endif
关于 x86 下的 lock 指令前缀,在 Intel® 64 and IA-32 Architectures Software Developer’s Manual 中的章节 LOCK-Assert LOCK$ Signal Prefix 中给出了详细解释:

简单概括一下上面的描述:
- x86 中的 LOCK 是一个指令前缀,也就是说 LOCK 会使紧跟在其后面的指令变成原子指令(atomic instruction)
- “LOCK” 前缀会锁定数据总线,这样同一总线上别的 CPU 就暂时不能通过总线访问该内存了,保证了这条指令在多处理器环境中的原子性
- LOCK 指令前缀只能加在以下这些指令前面:ADD,ADC,AND,BTC,BTR,BTS,CMPXCHG,CMPXCH8B,CMPXCHG16B,DEC,INC,NEG,NOT,OR,SBB,SUB,XOR,XADD,XCHG,否则就会触发异常

- 从 P6 系列处理器开始,Intel 对原子操作的实现方式进行了优化。处理器在执行原子操作时,是否锁住整个系统总线(bus),取决于该操作是否跨越了缓存行(cache line)
- 如果原子操作跨越了两个或多个缓存行(cross cache-line),那么就必须通过锁住总线(触发 bus lock)来保证操作的原子性
- 而如果原子操作完全落在同一个缓存行内,则不需要锁总线,处理器可以借助 MESI 缓存一致性协议,通过缓存锁定(cache lock)来保证原子性,这样效率更高。
浅论Lock 与X86 Cache 一致性
3.2.1 CAS
CAS(Compare-And-Swap)是一种广泛用于实现无锁、并发算法的原子操作。它的基本语义是:比较一个内存位置的当前值是否为预期值,若相同则将其更新为新值,否则不做修改。 CAS 的原子性由底层硬件保障。通常通过以下过程完成:
- 比较某个变量的当前值是否等于预期值;
- 如果相等,则将该变量更新为新值;
- 如果不相等,则重试操作,直到更新成功。
CAS 的伪代码逻辑如下:
int CAS(int *addr, int expected, int new_val) {
if (*addr == expected) {
*addr = new_val;
return 1; // 成功
} else {
return 0; // 失败
}
}
X86 下 CAS 操作的实现如下:
/*
* Atomic compare and exchange. Compare OLD with MEM, if identical,
* store NEW in MEM. Return the initial value in MEM. Success is
* indicated by comparing RETURN with OLD.
*/
#define __raw_cmpxchg(ptr, old, new, size, lock) \
({ \
__typeof__(*(ptr)) __ret; \
__typeof__(*(ptr)) __old = (old); \
__typeof__(*(ptr)) __new = (new); \
switch (size) { \
case __X86_CASE_B: \
{ \
volatile u8 *__ptr = (volatile u8 *)(ptr); \
asm volatile(lock "cmpxchgb %2,%1" \
: "=a" (__ret), "+m" (*__ptr) \
: "q" (__new), "0" (__old) \
: "memory"); \
break; \
}
可以看到, “CAS 的原子性由底层硬件保障” 其实最终使用的就是 “lock” 指令前缀。
3.3 ARM
再来看看在 ARM 上,是如何实现 “原子自增” 的。
arch\arm\include\asm\atomic.h
/*
* ARMv6 UP and SMP safe atomic ops. We use load exclusive and
* store exclusive to ensure that these are atomic. We may loop
* to ensure that the update happens.
*/
#define ATOMIC_OP(op, c_op, asm_op) \
static inline void arch_atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
prefetchw(&v->counter); \
__asm__ __volatile__("@ atomic_" #op "\n" \
"1: ldrex %0, [%3]\n" \
" " #asm_op " %0, %0, %4\n" \
" strex %1, %0, [%3]\n" \
" teq %1, #0\n" \
" bne 1b" \
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
}
可以看到,ARM 架构下主要是通过 LDREX、STREX 指令来实现原子操作:
(1)LDREX:Load-Exclusive
LDREX 指令用于从指定内存地址读取数据,并为该地址建立一个独占访问的监视状态(exclusive monitor):
LDREX Rx, [Ry]
该指令的语义如下:
- 从 Ry 指向的内存地址读取 4 字节内容,存入寄存器 Rx;
- 同时在该地址上设置一个本地 CPU 的独占访问标记(exclusive tag),表示当前处理器正在尝试对该地址进行原子更新;
- 如果在后续执行 STREX 之前,该内存地址被其他处理器或总线设备访问(即产生干扰),则该独占标记会被清除。
(2)STREX:Store-Exclusive
STREX 指令尝试将新的值写入某个内存地址,并仅在该地址仍保持独占访问状态时写入成功:
STREX Rt, Rx, [Ry]
其语义如下:
- 检查当前处理器是否仍对 Ry 指向的内存地址持有独占访问权;
- 如果是,写入寄存器 Rx 的值到该地址,并将 Rt 置为 0(表示写入成功);
- 如果不是(即独占访问状态已失效),则不进行写入,并将 Rt 置为非 0(通常为 1,表示写入失败,需要重试)。
4、什么是弱内存序
有些 cpu 为了提高性能,引入了一些优化手段,导致指令实际执行的 “效果” 可能与程序顺序不同,具有这种内存模型的 cpu 通常被称为 ”弱内存模型“。同时,还有另外一些原因可能导致指令乱序的效果:
- 编译器对指令做重排序
- cache 一致性优化引入的乱序(可参考 ibm 的文章,看一下 store buffer 和 invalid queue 怎么影响指令执行顺序)
- 指令多发射,有的流水线的指令由于没有阻塞而先执行,有的被阻塞了后执行从而导致顺序变化
4.1 指令乱序的最小约束条件
看起来比较反直觉,毕竟大多数同学写程序时都不会考虑乱序问题,为什么从不出错?
有几点原因,一个是对单线程来说,即便乱序发生了也不会影响程序的执行结果,另一个是在多线程程序中,对临界区加锁和解锁本身就自带了内存屏障语义,所以也不会出错。一般在多线程下写无锁算法时才需要考虑乱序,这个一会分析。
所以首先回答一个关键问题,乱序的边界在哪里?是所有指令都能乱序,还是有一定的约束?
事实上,为了保证程序的正确性,不管是编译器的指令重排序还是 cpu 指令执行乱序或者是 cache 一致性优化引入的乱序,指令的可见性顺序必须满足单线程语义下的正确性。换句话说,在指令执行的每个时间点上对内存的可见性顺序必须和程序顺序保持一致。
例如以下程序:
a = 1;
b = 2;
c = a;
这里 c = a 必须保证此时能看到 a 对应的内存值为 1,这是符合程序顺序的,否则程序结果就错了,所以以上程序不可能执行成这样:
c = a;
a = 1;
b = 2;
而其余 “保证可见性顺序和程序顺序一致” 的乱序,理论上都是有可能发生的(只要乱序不会破坏单线程语义下的执行结果,编译器/CPU 就可能这样做)。即,可能发生以下 “不影响结果的乱序”:
b = 2;
a = 1;
c = a;
4.2 多线程下的乱序问题
根据上述讨论可以知道,单线程情况下即便有乱序行为发生也不会影响程序的执行结果,所以无需担心。然而,在多线程下仅凭以上的约束就不足以保证程序的正确性了。比如以下程序:
T1: T2:
a = 123;
b = true;
if (b == true) {
print(a);
}
按照程序顺序,print(a) 应该打印出 123,但实际执行结果并不一定。按照上一节的约束条件,T1 的执行顺序可能是:
b = true;
a = 123;
这并不影响 T1 对其访问的内存的可见性顺序,但问题是,这改变了 T2 对 a 和 b 的可见性顺序,即 print(a) 的时候,看到了 b 为 true,但还没有看到 a 的最新值 123,导致打印出的 a 是旧值。
所以,多线程下乱序会引起问题,本质上是因为不管是编译器还是 cpu,在处理指令时其本身并没有 “线程” 的概念,无法从多线程角度对指令的执行增加新的约束。
4.3 解决乱序问题
既然编译器和 cpu 都没有线程概念,那需要的 “约束” 条件就要求程序员手工来加了,这就引入了 “内存屏障” (memory barrier)。对上面的程序来说,如果把读写 b 作为同步 a 的手段,想要保证内存可见性顺序须保证两件事:
- 从 T1 的角度来看,当
b = true对外部可见时,a = 123也必须对外部可见,这个约束叫做release 语义(通常实现为 write barrier) - 从 T2 的角度来看,当
b = true可见时,如果 T1 的b = true具有 release 语义,那么 happens beforeb = true的所有指令的结果对 T2 也必须可见,这种叫做acquire 语义(通常实现为 read barrier)
加上内存屏障后的代码就一定能保证 print(a) 输出为 123:
T1: T2:
a = 123;
write_barrier();
b = true;
if (b == true) {
read_barrier();
print(a);
}
弱内存模型的 CPU 乱序问题检测方法
4.4 内存屏障的使用场景
还是以上面的场景为例:
T1: T2:
a = 123;
b = true;
if (b == true) {
print(a);
}
不同架构下,是否需要内存屏障、内存屏障的种类、使用方法都可能不同。这就需要具体问题具体分析,因文章篇幅的关系,这里不会详解。下图列出了常见的架构,对于内存乱序方面的差异:

例如,对于 X86 架构来说,不需要给 T1 和 T2 显式的加上内存屏障。因为 x86 硬件上保证了 T1 和 T2 场景下,不会出现内存乱序。
- T1:Store → Store
- T2:Load → Load
但对于 ARM 架构来说,就需要给 T1 和 T2 显式的加上内存屏障,因为 ARM 架构对于 T1 和 T2 场景下,允许发生内存乱序。
5、原子操作与内存屏障之间的联系与区别
5.1 联系
还是以上面的场景为例:
T1: T2:
a = 123;
b = true;
if (b == true) {
print(a);
}
不知道你是否有考虑过,在 ARM 架构下,该场景的内存乱序行为,是否可以通过 原子操作——互斥锁 来解决这个问题?例如:
T1: T2:
mutex(&lock)
a = 123;
b = true;
mutex_unlock(&lock)
mutex(&lock)
if (b == true) {
print(a);
}
mutex_unlock(&lock)
答案是,可以。因为互斥锁的实现中,都会带有内存屏障相关指令的,并且还是多处。
void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
if (!__mutex_trylock_fast(lock))
__mutex_lock_slowpath(lock);
}
/*
* Optimistic trylock that only works in the uncontended case. Make sure to
* follow with a __mutex_trylock() before failing.
*/
static __always_inline bool __mutex_trylock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
unsigned long zero = 0UL;
if (atomic_long_try_cmpxchg_acquire(&lock->owner, &zero, curr))
return true;
return false;
}
/**
* atomic_long_try_cmpxchg_acquire() - atomic compare and exchange with acquire ordering
* @v: pointer to atomic_long_t
* @old: pointer to long value to compare with
* @new: long value to assign
*
* If (@v == @old), atomically updates @v to @new with acquire ordering.
* Otherwise, updates @old to the current value of @v.
*
* Unsafe to use in noinstr code; use raw_atomic_long_try_cmpxchg_acquire() there.
*
* Return: @true if the exchange occured, @false otherwise.
*/
static __always_inline bool
atomic_long_try_cmpxchg_acquire(atomic_long_t *v, long *old, long new)
{
instrument_atomic_read_write(v, sizeof(*v));
instrument_atomic_read_write(old, sizeof(*old));
return raw_atomic_long_try_cmpxchg_acquire(v, old, new);
}
可以看到 atomic_long_try_cmpxchg_acquire() - atomic compare and exchange with acquire ordering。互斥锁的实现,通常都会包含内存屏障指令。
常见函数的后缀:_acquire、_release、_releax 的含义如下:
_acquire:读取方屏障,防止之后的操作被提前 保证后续读取是“看到的最新的”
_release:写入方屏障,防止之前的操作被延后 保证写入对其他线程是可见的
_relaxed:无序,不插入任何内存屏障 完全依赖用户手动控制同步
再例如,以 ARM 架构下的 spin_lock 为例:
spin_lock -> raw_spin_lock -> LOCK_CONTENDED -> do_raw_spin_lock -> arch_spin_lock
/*
* ARMv6 ticket-based spin-locking.
*
* A memory barrier is required after we get a lock, and before we
* release it, because V6 CPUs are assumed to have weakly ordered
* memory.
*/
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->slock);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
smp_mb();
}
自旋锁实现的结尾,也都会有内存屏障相关指令。
5.2 区别
内存屏障:
- 不能阻止多个线程同时访问共享资源
- 不能提供互斥性
- 不具有睡眠/调度行为
- 是构建原子操作、无锁队列、自旋锁等的基础
互斥锁:
- 可能会引起线程上下文切换(如果被阻塞)
- 比内存屏障更“重”