作者:耿宏宇
1 表引擎简述
1.1 官方描述
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
ReplacingMergeTree 引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写。
1.2 本地表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[PRIMARY KEY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]参数介绍
- ver — 版本列。类型为 UInt*, Date 或 DateTime。可选参数。
在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:
1.如果 ver 列未指定,保留最后一条。
2.如果 ver 列已指定,保留 ver 值最大的版本。 - PRIMARY KEY expr 主键。如果要 选择与排序键不同的主键,在这里指定,可选项。
默认情况下主键跟排序键(由 ORDER BY 子句指定)相同。 因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。 - SAMPLE BY EXPR 用于抽样的表达式,可选项
- PARTITION BY expr 分区键
- ORDER BY expr 排序键
1.3 分区表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]参数介绍
- cluster 集群名
- table 远程数据表名
- sharding_key 分片规则
- policy_name 规则名,它会被用作存储临时文件以便异步发送数据
2 键的概念
Clickhouse的部署,分为单机模式和集群模式,还可以开启副本。两种模式,数据表在创建语法、创建步骤和后续的使用方式上,存在一定的差异。

在定义表结构时,需要指定不同的键,作用如下。

分片:所有分片节点的权重加和得到S,可以理解为sharing动作取模的依据,权重X=W/S。分片键 Mod S 得到的值,与哪个分片节点匹配,则会写入哪个分片。不同分片可能存在于不同的集群节点,即便不同分片在同一节点,但ck在merge时,维度是同一分区+同一分片,这是物理文件的合并范围。
如果我们权重分别设置为1,2,3 那么总权重是6,那么总区间就是[0,6),排在shard配置第一位的node01,权重占比为1/6,所以属于区间[0,1),排在shard配置第二位的node02,占比2/6,所以区间为[1,3),至于最后的node03就是[3,6).所以如果rand()产生的数字除以6取余落在哪个区间,数据就会分发到哪个shard,通过权重配置,可以实现数据按照想要的比重分配.
3 分片的作用
3.1 分片规则
在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的- - - sharding策略,让业务可以根据实际需求选用。
- random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
- constant固定分片:写入数据会被分发到固定一个节点上。
- column value分片:按照某一列的值进行hash分片。
- 自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
3.2 类比
以MySQL的分库分表场景为例:
- 2个库,1个表分4个子表,采用一主一从模式。
- db01包含tab-1和tab-2,db-2包含tab-3和tab-4;
- 在配置sharding规则时,需要设置分库规则、分表规则;
一条记录写入时,会计算它要写入哪个表、哪个库,写入的记录会被从节点复制。
这个MySQL的例子,与CK的分区+分片+副本在逻辑上基本一致。分区理解为数据写入哪个表,分片可以理解为数据写入哪个库,副本则是从节点的拷贝。
3.3 分片、分区与副本
Clickhouse分片是集群模式下的概念,可以类比MySQL的Sharding逻辑,副本是为了解决Sharing方案下的高可用场景所存在的。
下图描述了一张Merge表的各类键的关系,也能反映出一条记录的写入过程。
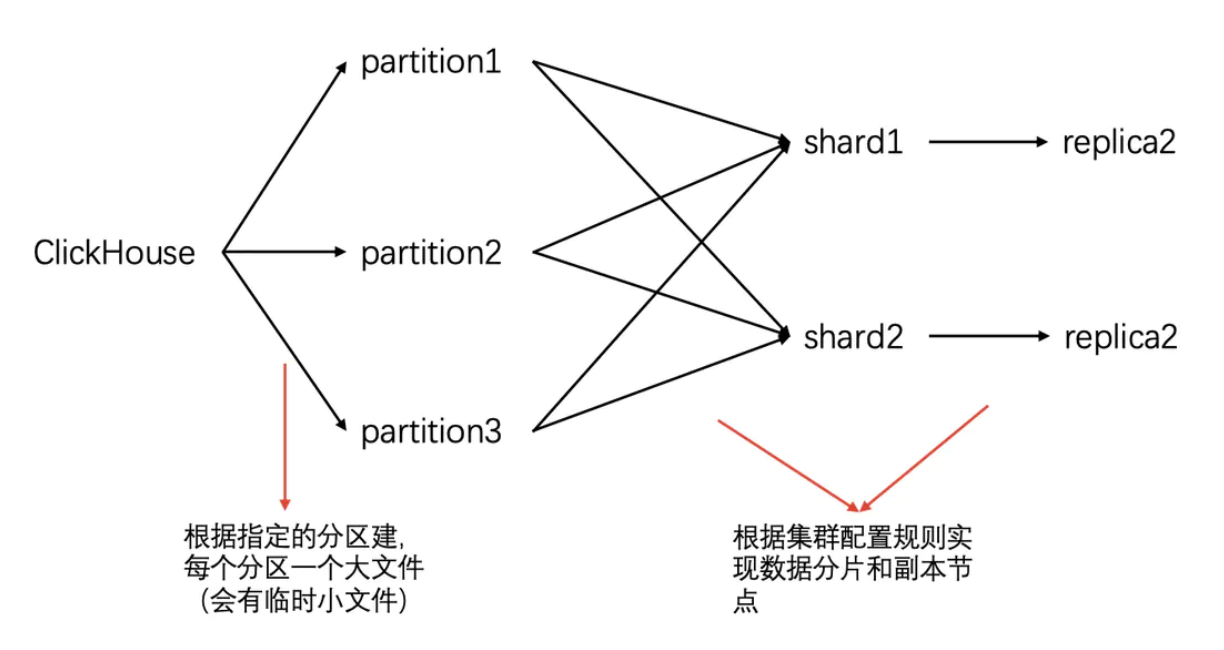
4 数据合并限制
理清了分区与分片的概念,也就明白CK的数据合并,为什么要限制相同分区、相同分片,因为它们影响数据的存储位置,merge操作只能针对相同物理位置(分区目录)的数据进行操作,而分片会影响数据存储在哪个节点上。
一句话,使用CK的ReplacingMergeTree引擎的去重特性,期望去重的数据,必须满足拥有 相同排序键、同一分区、同一分片。
接下来针对这一要求,在数据上进行验证。
5 数据验证
5.1 场景设置
这里是要验证上面的结论,“期望去重的数据,必须满足在相同排序键、同一分区、同一分片”;
首先拥有相同排序键才会在merge操作时进行判断为重复,因此保证测试数据的排序键相同;剩余待测试场景则是分区与分片。
由此进行场景设置:
- 相同记录,能够写入同一分区、同一分片
- 相同记录,能够写入同一分区,不同分片
- 相同记录,能够写入不同分区,不同分片
- 相同记录,能够写入不同分区、相同分片
再叠加同步写入方式: - 直接写本地表
- 直接写分布式表
补充:分区键与分片键,是否必须相同?
5.2 第一天测试
场景1: 相同记录,能够写入同一分区、同一分片
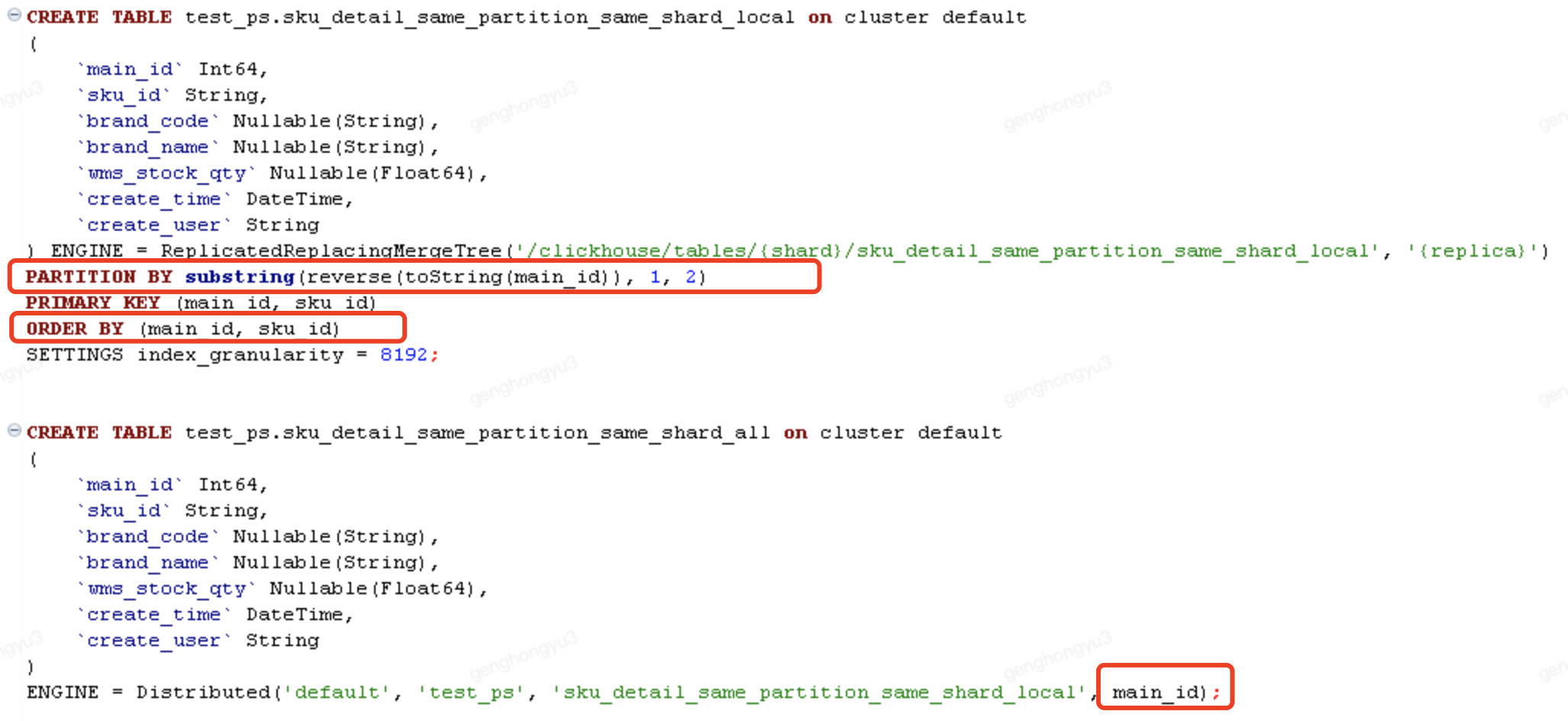
一次执行3条插入,插入本地表
[main_id=101,sku_id=SKU0002;barnd_code=BC01,BC02,BC03]
select * from test_ps.sku_detail_same_partition_same_shard_all;

分三次执行,插入本地表
[main_id=101,sku_id=SKU0001;barnd_code=BC01,BC02,BC03]
select * from test_ps.sku_detail_same_partition_same_shard_all;

分三次执行,插入分布式表
[main_id=101,sku_id=SKU0001;barnd_code=BC001,BC002,BC003]
select * from test_ps.sku_detail_same_partition_same_shard_all;

select * from test_ps.sku_detail_same_partition_same_shard_all final;

结论1
1.采用分布式表插入数据,保证分片键、分区键的值相同,才能保证merge去重成功
排除本地表插入场景
2.采用本地表插入数据,在分片键、分区键相同的情况下,无法保证merge去重
- 在一个session(一次提交)里面包含多个记录,直接会得到一条记录,插入过程去重
在第一次insert时,准备的3条insert语句是一次执行的,查询后只有1条记录。 - 在多个session(多次提交)记录,不会直接去重,但有可能写到不同集群节点,导致无法去重
分3次执行3条insert语句,查询后有3条记录,且通过final查询后有2条记录,合并去重的那2条记录是写入在同一集群节点。【参考SKU0002的执行结果】
后面直接验证插入分布式表场景。
场景2:相同记录,能够写入同一分区,不同分片
- 分片键采用的rand()方式,随机生成。
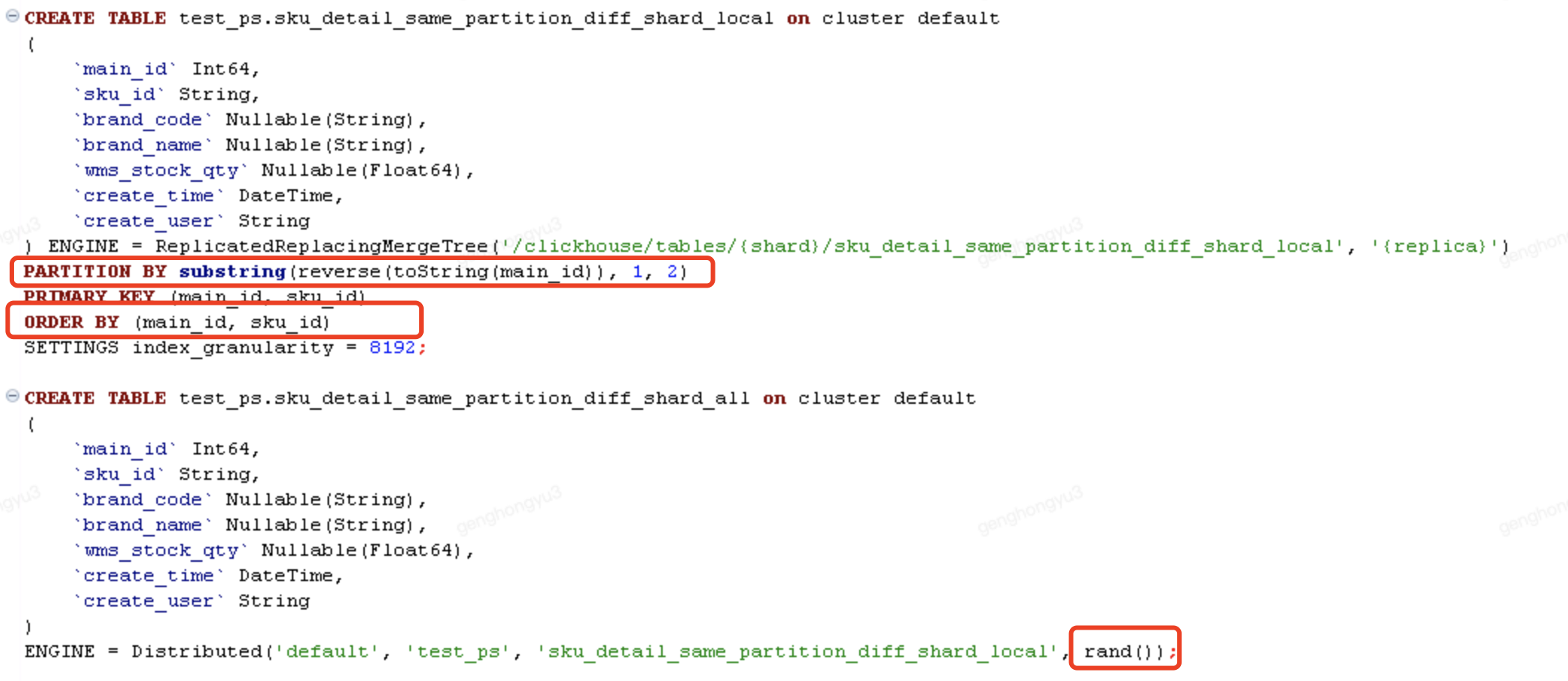
分三次执行,插入分布式表
[main_id=103,sku_id=SKU0003;barnd_code=BC301,BC302,BC303]
检查数据插入状态
select * from test_ps.sku_detail_same_partition_diff_shard_all where main_id =103 ;

检查merge的去重结果
select * from test_ps.sku_detail_same_partition_diff_shard_all final where main_id =103 ;

分五次执行,插入分布式表
[main_id=104,sku_id=SKU0004;barnd_code=BC401,BC402,BC403,BC404,BC405]
检查数据插入状态
select * from test_ps.sku_detail_same_partition_diff_shard_all where main_id =104 ;

检查merge的去重结果
select * from test_ps.sku_detail_same_partition_diff_shard_all final where main_id =104 ;

结论2
采用分布式表插入数据,保证分区键的值相同、分片键的值随机,无法保证merge去重
- 如果插入记录时,通过rand()生成的数字取模后的值一样,很幸运最终可以merge去重成功
- 如果插入记录时,通过rand()生成的数字取模后的值不一样,最终无法通过merge去重
场景3:相同记录,能够写入不同分区,不同分片
- 分片键采用的rand()方式,随机生成;
- 分区键为了方便测试,采用创建时间。
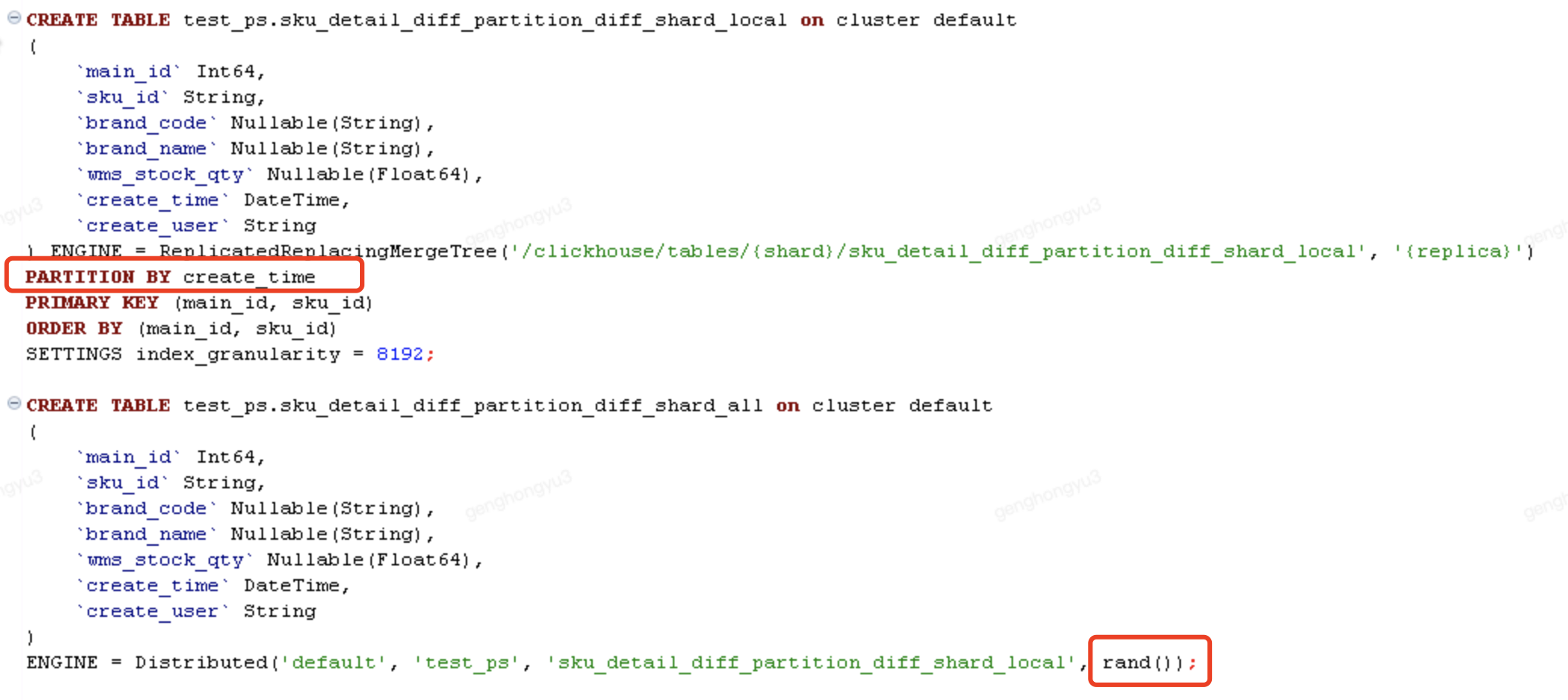
分五次执行,插入分布式表
[main_id=105,sku_id=SKU0005;barnd_code=BC501,BC502,BC503,BC504,BC505]
检查数据插入状态
select * from test_ps.sku_detail_diff_partition_diff_shard_all where main_id =105 ;

检查merge的去重结果
select * from test_ps.sku_detail_diff_partition_diff_shard_all final where main_id =105;

结论3
采用分布式表插入数据,分区键的值与排序键不一致、分片键的值随机,无法保证merge去重
- 按当前测试结果,虽然create_time都不相同,也就是分区不同,也发生了数据合并
- 数据发生合并,但结果并不是完全按排序键进行合并的
场景4:相同记录,能够写入 不同分区、相同分片
- 分片键采用main_id;
- 分区键为了方便测试,采用创建时间。
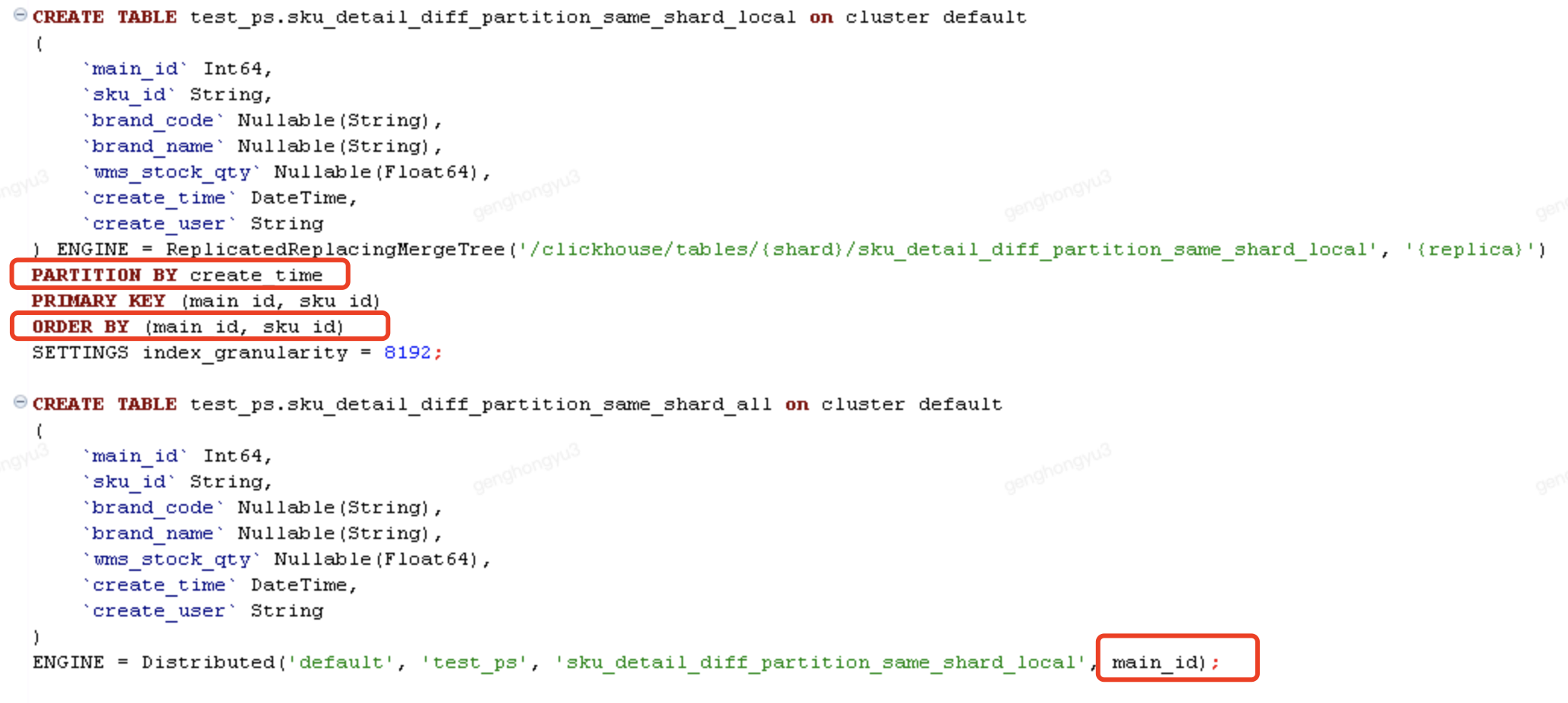
分六次执行,插入分布式表
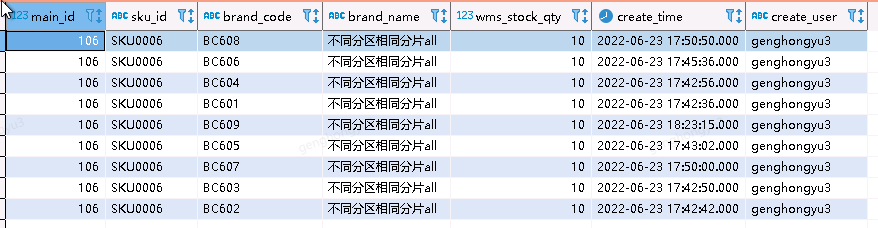
[main_id=106,sku_id=SKU0006;barnd_code=BC601,BC602,BC603,BC604,BC605,BC606]
检查数据插入状态
select * from test_ps.sku_detail_diff_partition_same_shard_all where main_id =106 ;

检查merge的去重结果
select * from test_ps.sku_detail_diff_partition_same_shard_all final where main_id =106;

此场景,经过第二天检索,数据并没有进行merge,而是用final关键字依然能检索出去重后的结果。也就是说final关键字只是在内存中进行去重,由于所在分区不同,文件是没有进行merge合并的,也就没有去重。反观相同分区、相同分片的数据表,数据已经完成了merge合并,普通检索只能得到一条记录。
结论4
采用分布式表插入数据,分区键的值与排序键不一致、分片键的值固定,无法实现merge去重
5.3 第二天检查
以下均采用普通查询,发现如下情况
- 分片不同的表,其数据没有合并
- 分片相同、分区不同的没有合并
- 分片相同、分区相同的已经完成了合并
select * from test_ps.sku_detail_same_partition_same_shard_all;

select * from test_ps.sku_detail_same_partition_diff_shard_all;

select * from test_ps.sku_detail_diff_partition_diff_shard_all;

select * from test_ps.sku_detail_diff_partition_same_shard_all;
6 总结
根据测试结果,在不同场景下的合并情况:
- 如果数据存在在相同分片,且相同分区,绝对可以实现合并去重。
- 如果数据存储在不同分片,不同分区,将不会进行合并去重。
- 如果数据存储在不同分片,但同一分片内保证在相同分区,会进行此分片下的merge去重。
- 如果数据存在在相同分片,但不同分区,不会进行merge去重,但通过final关键字可以在CK内存中对相同分区、相同分片的数据进行去重。
在Clickhouse的ReplacingMergeTree进行merge操作时,是根据排序键(order by)来识别是否重复、是否需要合并。而分区和分片,影响的是数据的存储位置,在哪个集群节点、在哪个文件目录。那么最终ReplacingMergeTree表引擎在合并时,只会在当前节点、且物理位置在同一表目录下的数据进行merge操作。
最后,我们在设计表时,如果期望利用到ReplacingMergeTree自动去重的特性,那么必须使其存储在相同分区、相同分片下;而在设置分区键、分片键时,二者不要求必须相同,但必须稳定,稳定的含义是入参相同出参必须相同。


![[附源码]计算机毕业设计Python第三方游戏零售平台(程序+源码+LW文档)](https://img-blog.csdnimg.cn/ddc3e6ce45714a0998add4c465841949.png)



![[附源码]Python计算机毕业设计Django智能衣橱APP](https://img-blog.csdnimg.cn/7d13634c36e84acb8f6feb5dcd9cad52.png)