学更好的别人,
做更好的自己。
——《微卡智享》

本文长度为2548字,预计阅读8分钟
前言
前三章介绍了pyTorch训练的相关,我们也保存模型成功了,今天这篇就是使用C++ OpenCV的DNN模块进行手写图片的推理。

实现效果
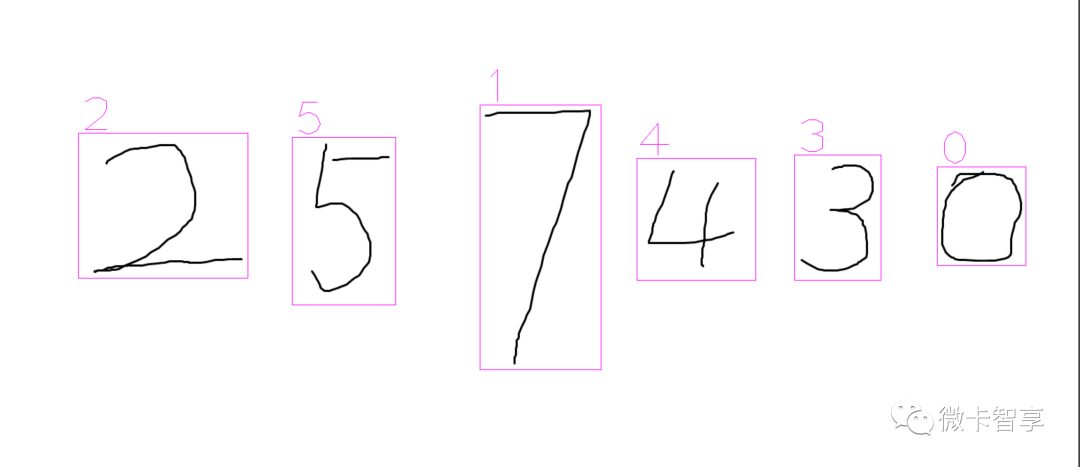
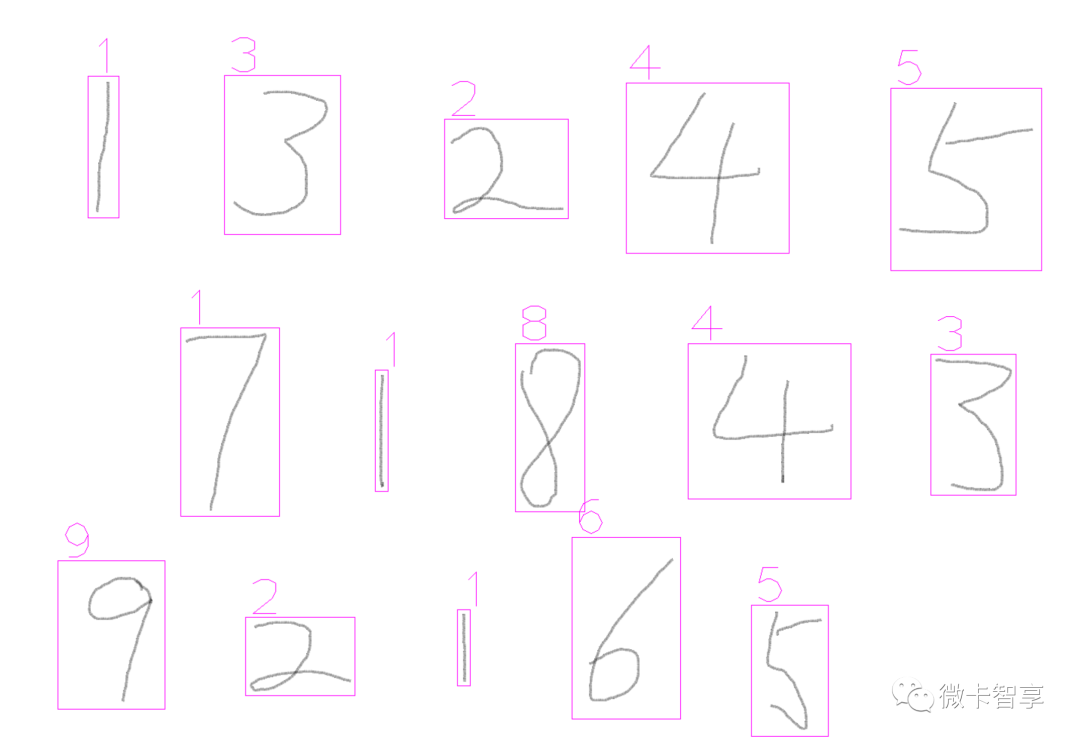
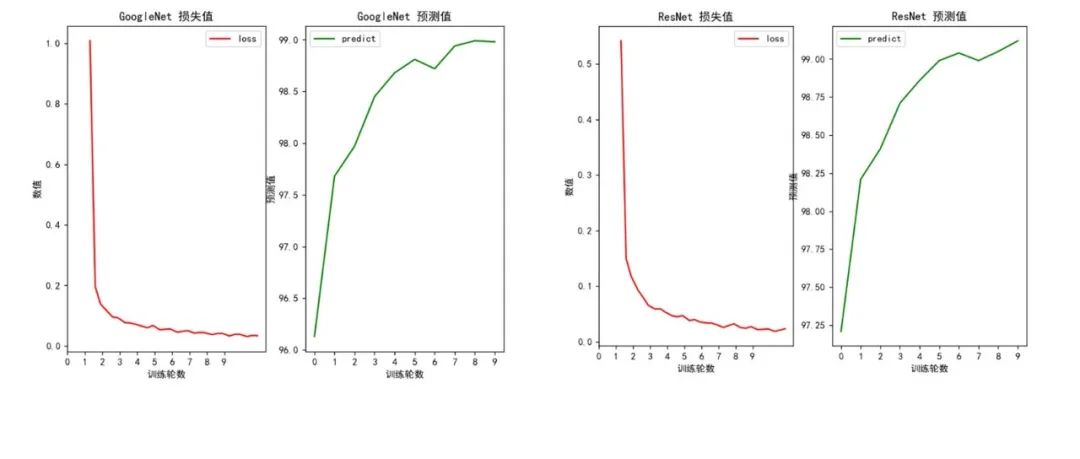
导出的推理模型使用的是Minist中训练预测率为99%的ResNet模型,从上面两张图来看,大部分数字识别是没问题的,但是两张图中数字7都识别为数字1了。这个暂时不是本篇要解决的问题,我们先看看怎么实现的导出模型和推理。
微卡智享
导出模型
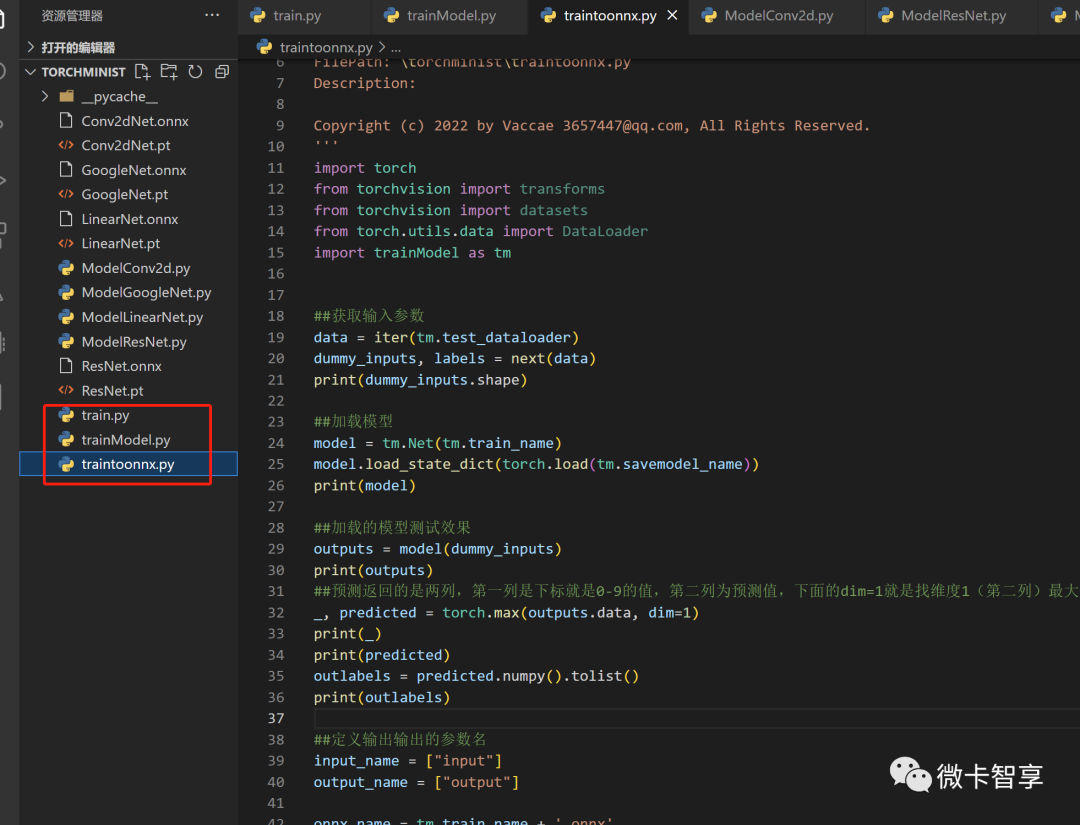
由于不想再重新写一篇网络模型了,所以将原来train.py中的加载训练集和测试集,网络模型等都改为trainmodel.py里面了。然后新建了一个traintoonnx.py的文件,用于导出ONNX的模型文件。接下来直接放源码,说重点
train.py
import torch
import time
import torch.optim as optim
import matplotlib.pyplot as plt
from pylab import mpl
import trainModel as tm
##训练轮数
epoch_times = 10
##设置初始预测率,用于判断高于当前预测率的保存模型
toppredicted = 0.0
##设置学习率
learnrate = 0.01
##设置动量值,如果上一次的momentnum与本次梯度方向是相同的,梯度下降幅度会拉大,起到加速迭代的作用
momentnum = 0.5
##生成图用的数组
##预测值
predict_list = []
##训练轮次值
epoch_list = []
##loss值
loss_list = []
model = tm.Net(tm.train_name)
##加入判断是CPU训练还是GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
##优化器
optimizer = optim.SGD(model.parameters(), lr= learnrate, momentum= momentnum)
# optimizer = optim.NAdam(model.parameters(), lr= learnrate)
##训练函数
def train(epoch):
running_loss = 0.0
current_train = 0.0
model.train()
for batch_idx, data in enumerate(tm.train_dataloader, 0):
inputs, target = data
##加入CPU和GPU选择
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
#前馈,反向传播,更新
outputs = model(inputs)
loss = model.criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
##计算每300次打印一次学习效果
if batch_idx % 300 == 299:
current_train = current_train + 0.3
current_epoch = epoch + 1 + current_train
epoch_list.append(current_epoch)
current_loss = running_loss / 300
loss_list.append(current_loss)
print('[%d, %5d] loss: %.3f' % (current_epoch, batch_idx + 1, current_loss))
running_loss = 0.0
def test():
correct = 0
total = 0
model.eval()
##with这里标记是不再计算梯度
with torch.no_grad():
for data in tm.test_dataloader:
inputs, labels = data
##加入CPU和GPU选择
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
##预测返回的是两列,第一列是下标就是0-9的值,第二列为预测值,下面的dim=1就是找维度1(第二列)最大值输出
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
currentpredicted = (100 * correct / total)
##用global声明toppredicted,用于在函数内部修改在函数外部声明的全局变量,否则报错
global toppredicted
##当预测率大于原来的保存模型
if currentpredicted > toppredicted:
toppredicted = currentpredicted
torch.save(model.state_dict(), tm.savemodel_name)
print(tm.savemodel_name+" saved, currentpredicted:%d %%" % currentpredicted)
predict_list.append(currentpredicted)
print('Accuracy on test set: %d %%' % currentpredicted)
##开始训练
timestart = time.time()
for epoch in range(epoch_times):
train(epoch)
test()
timeend = time.time() - timestart
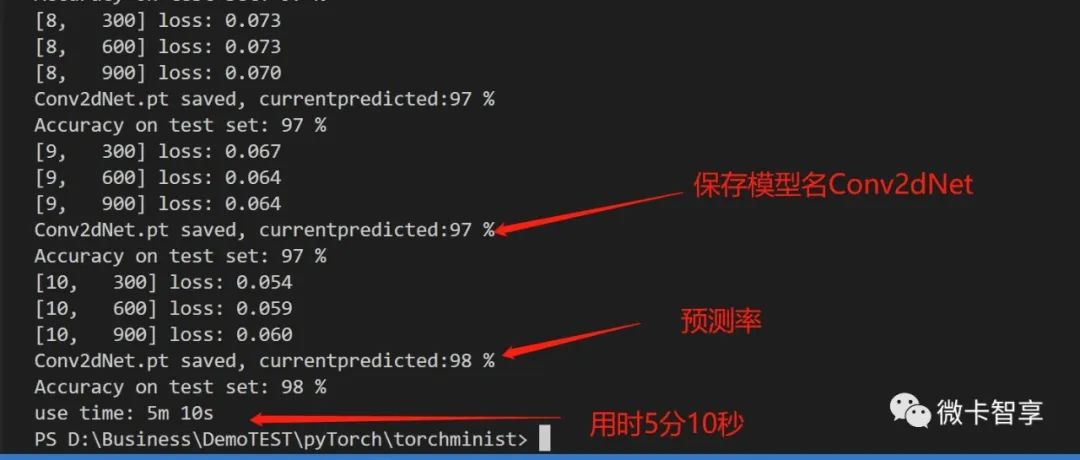
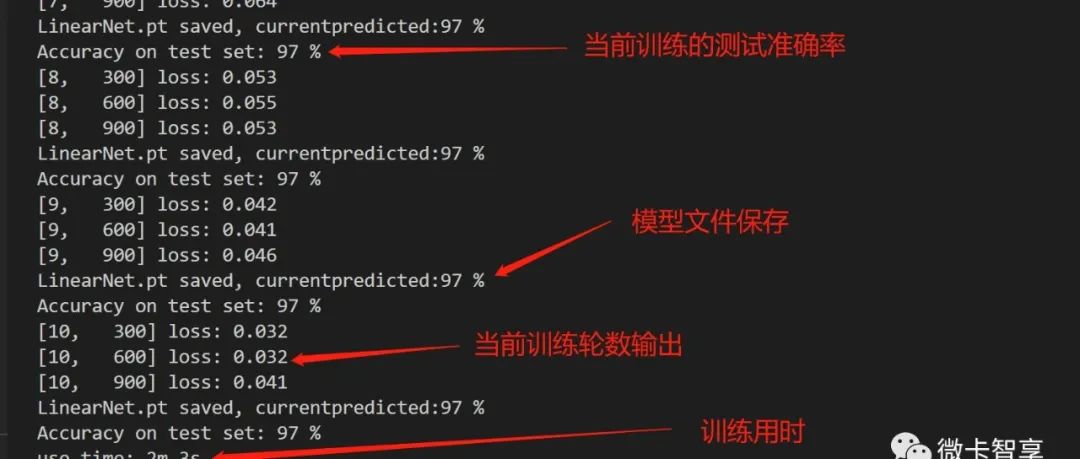
print("use time: {:.0f}m {:.0f}s".format(timeend // 60, timeend % 60))
##设置画布显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
##设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
##创建画布
fig, (axloss, axpredict) = plt.subplots(nrows=1, ncols=2, figsize=(8,6))
#loss画布
axloss.plot(epoch_list, loss_list, label = 'loss', color='r')
##设置刻度
axloss.set_xticks(range(epoch_times)[::1])
axloss.set_xticklabels(range(epoch_times)[::1])
axloss.set_xlabel('训练轮数')
axloss.set_ylabel('数值')
axloss.set_title(tm.train_name+' 损失值')
#添加图例
axloss.legend(loc = 0)
#predict画布
axpredict.plot(range(epoch_times), predict_list, label = 'predict', color='g')
##设置刻度
axpredict.set_xticks(range(epoch_times)[::1])
axpredict.set_xticklabels(range(epoch_times)[::1])
# axpredict.set_yticks(range(100)[::5])
# axpredict.set_yticklabels(range(100)[::5])
axpredict.set_xlabel('训练轮数')
axpredict.set_ylabel('预测值')
axpredict.set_title(tm.train_name+' 预测值')
#添加图例
axpredict.legend(loc = 0)
#显示图像
plt.show()trainmodel.py
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
from ModelLinearNet import LinearNet
from ModelConv2d import Conv2dNet
from ModelGoogleNet import GoogleNet
from ModelResNet import ResNet
batch_size = 64
##设置本次要训练用的模型
train_name = 'ResNet'
print("train_name:" + train_name)
##设置模型保存名称
savemodel_name = train_name + ".pt"
print("savemodel_name:" + savemodel_name)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))
]) ##Normalize 里面两个值0.1307是均值mean, 0.3081是标准差std,计算好的直接用了
##训练数据集位置,如果不存在直接下载
train_dataset = datasets.MNIST(
root = '../datasets/mnist',
train = True,
download = True,
transform = transform
)
##读取训练数据集
train_dataloader = DataLoader(
dataset= train_dataset,
shuffle=True,
batch_size=batch_size
)
##测试数据集位置,如果不存在直接下载
test_dataset = datasets.MNIST(
root= '../datasets/mnist',
train= False,
download=True,
transform= transform
)
##读取测试数据集
test_dataloader = DataLoader(
dataset= test_dataset,
shuffle= True,
batch_size=batch_size
)
##设置选择训练模型,因为python用的是3.9,用不了match case语法
def switch(train_name):
if train_name == 'LinearNet':
return LinearNet()
elif train_name == 'Conv2dNet':
return Conv2dNet()
elif train_name == 'GoogleNet':
return GoogleNet()
elif train_name == 'ResNet':
return ResNet()
##定义训练模型
class Net(torch.nn.Module):
def __init__(self, train_name):
super(Net, self).__init__()
self.model = switch(train_name= train_name)
self.criterion = self.model.criterion
def forward(self, x):
x = self.model(x)
return xtraintoonnx.py
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import trainModel as tm
##获取输入参数
data = iter(tm.test_dataloader)
dummy_inputs, labels = next(data)
print(dummy_inputs.shape)
##加载模型
model = tm.Net(tm.train_name)
model.load_state_dict(torch.load(tm.savemodel_name))
print(model)
##加载的模型测试效果
outputs = model(dummy_inputs)
print(outputs)
##预测返回的是两列,第一列是下标就是0-9的值,第二列为预测值,下面的dim=1就是找维度1(第二列)最大值输出
_, predicted = torch.max(outputs.data, dim=1)
print(_)
print(predicted)
outlabels = predicted.numpy().tolist()
print(outlabels)
##定义输出输出的参数名
input_name = ["input"]
output_name = ["output"]
onnx_name = tm.train_name + '.onnx'
torch.onnx.export(
model,
dummy_inputs,
onnx_name,
verbose=True,
input_names=input_name,
output_names=output_name
)划重点
01
加载模型后导出
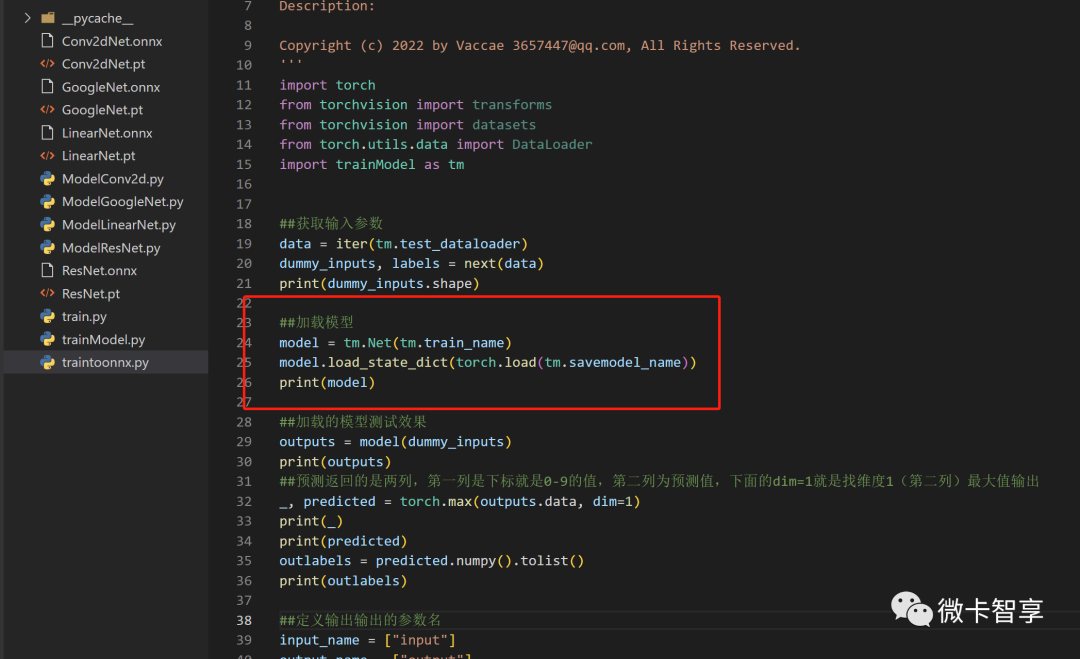
导出Onnx的模型,在《超简单的pyTorch训练->onnx模型->C++ OpenCV DNN推理(附源码地址)》有说过,那里面是先训练完后直接导出了,而traintoonnx.py中则是前面训练已经保存好模型了,这里我们直接加载模型读取,然后再进行导出。
02
导出ONNX模型在使用OpenCV推理时,x.view不能用
这个是比较关键的,原来的我们的训练模型中,在前向传播里面用的都是x.view这个,如下图
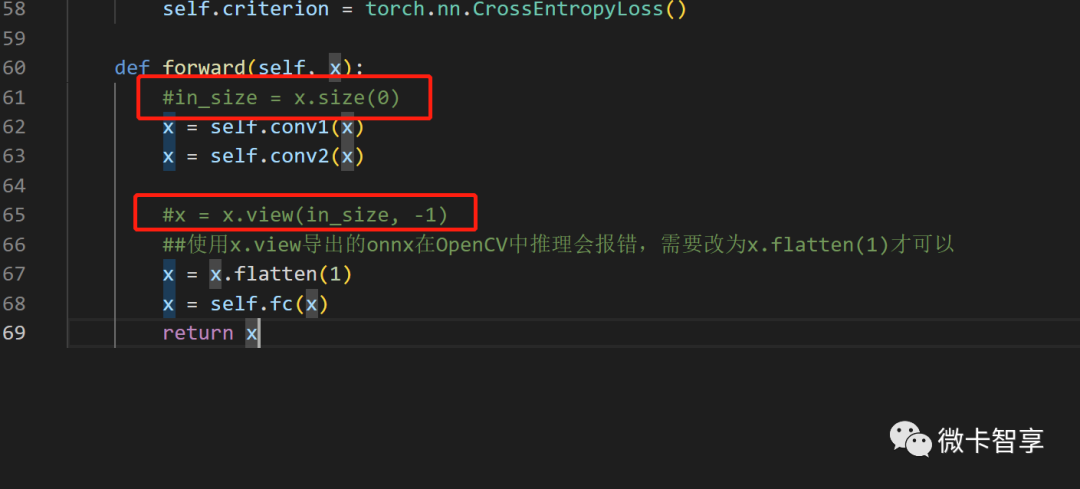
导出ONNX在OpenCV中推理时直接报错了,所以这里要改为x = x.flatten(1)

微卡智享
C++ OpenCV推理
使用OpenCV DNN进行推理时,就不像《超简单的pyTorch训练->onnx模型->C++ OpenCV DNN推理(附源码地址)》中那么简单了,因为是手写的数字识别,并且Minist训练时的图像都是1X28X28的样本,所以推理前需要将图像进行预处理,下面是实现的思路。
| # | 思路 |
|---|---|
| 1 | 读取图像,做灰度处理,高斯模糊,二值化 |
| 2 | 形态学操作,使用膨胀(防止轮廓查找有问题) |
| 3 | 轮廓查找,根据顺序排序截图图像 |
| 4 | 排序后的图像进行处理缩放为(28X28) |
| 5 | 使用DNN传入处理后的图像进行推理 |
C++推理源码
#pragma once
#include<iostream>
#include<opencv2/opencv.hpp>
#include<opencv2/dnn/dnn.hpp>
using namespace cv;
using namespace std;
dnn::Net net;
//排序矩形
void SortRect(vector<Rect>& inputrects) {
for (int i = 0; i < inputrects.size(); ++i) {
for (int j = i; j < inputrects.size(); ++j) {
//说明顺序在上方,这里不用变
if (inputrects[i].y + inputrects[i].height < inputrects[i].y) {
}
//同一排
else if (inputrects[i].y <= inputrects[j].y + inputrects[j].height) {
if (inputrects[i].x > inputrects[j].x) {
swap(inputrects[i], inputrects[j]);
}
}
//下一排
else if (inputrects[i].y > inputrects[j].y + inputrects[j].height) {
swap(inputrects[i], inputrects[j]);
}
}
}
}
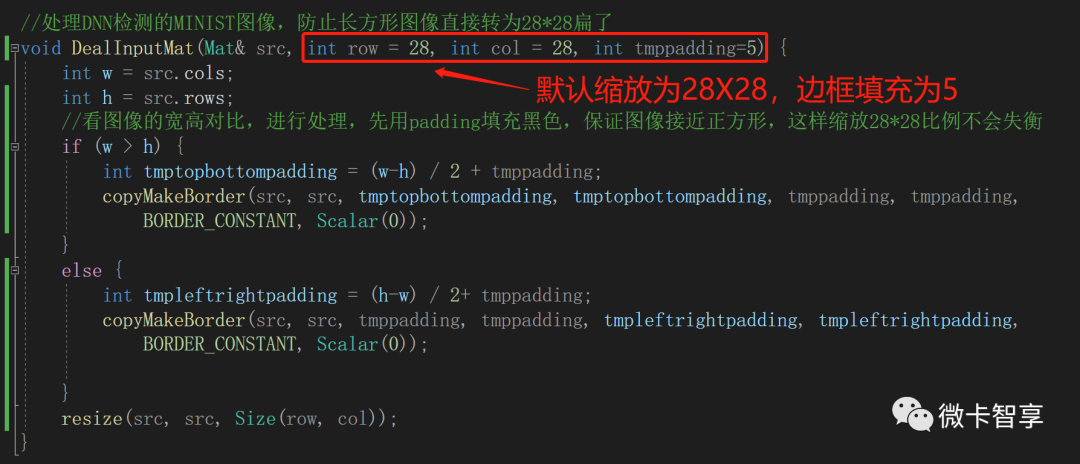
//处理DNN检测的MINIST图像,防止长方形图像直接转为28*28扁了
void DealInputMat(Mat& src, int row = 28, int col = 28, int tmppadding=5) {
int w = src.cols;
int h = src.rows;
//看图像的宽高对比,进行处理,先用padding填充黑色,保证图像接近正方形,这样缩放28*28比例不会失衡
if (w > h) {
int tmptopbottompadding = (w-h) / 2 + tmppadding;
copyMakeBorder(src, src, tmptopbottompadding, tmptopbottompadding, tmppadding, tmppadding,
BORDER_CONSTANT, Scalar(0));
}
else {
int tmpleftrightpadding = (h-w) / 2+ tmppadding;
copyMakeBorder(src, src, tmppadding, tmppadding, tmpleftrightpadding, tmpleftrightpadding,
BORDER_CONSTANT, Scalar(0));
}
resize(src, src, Size(row, col));
}
int main(int argc, char** argv) {
//定义onnx文件
string onnxfile = "D:/Business/DemoTEST/CPP/OpenCVMinistDNN/torchminist/ResNet.onnx";
//测试图片文件
string testfile = "D:/Business/DemoTEST/CPP/OpenCVMinistDNN/test5.png";
net = dnn::readNetFromONNX(onnxfile);
if (net.empty()) {
cout << "加载Onnx文件失败!" << endl;
return -1;
}
//读取图片,灰度,高斯模糊
Mat src = imread(testfile);
//备份源图
Mat backsrc;
src.copyTo(backsrc);
cvtColor(src, src, COLOR_BGR2GRAY);
GaussianBlur(src, src, Size(3, 3), 0.5, 0.5);
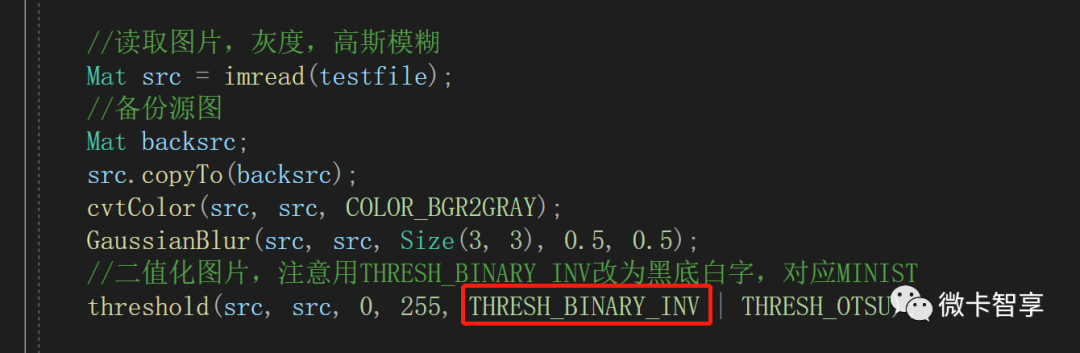
//二值化图片,注意用THRESH_BINARY_INV改为黑底白字,对应MINIST
threshold(src, src, 0, 255, THRESH_BINARY_INV | THRESH_OTSU);
//做彭账处理,防止手写的数字没有连起来,这里做了3次膨胀处理
Mat kernel = getStructuringElement(MORPH_RECT, Size(5, 5));
morphologyEx(src, src, MORPH_DILATE, kernel, Point(-1,-1), 3);
imshow("src", src);
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
vector<Rect> rects;
//查找轮廓
findContours(src, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_NONE);
for (int i = 0; i < contours.size(); ++i) {
RotatedRect rect = minAreaRect(contours[i]);
Rect outrect = rect.boundingRect();
//插入到矩形列表中
rects.push_back(outrect);
}
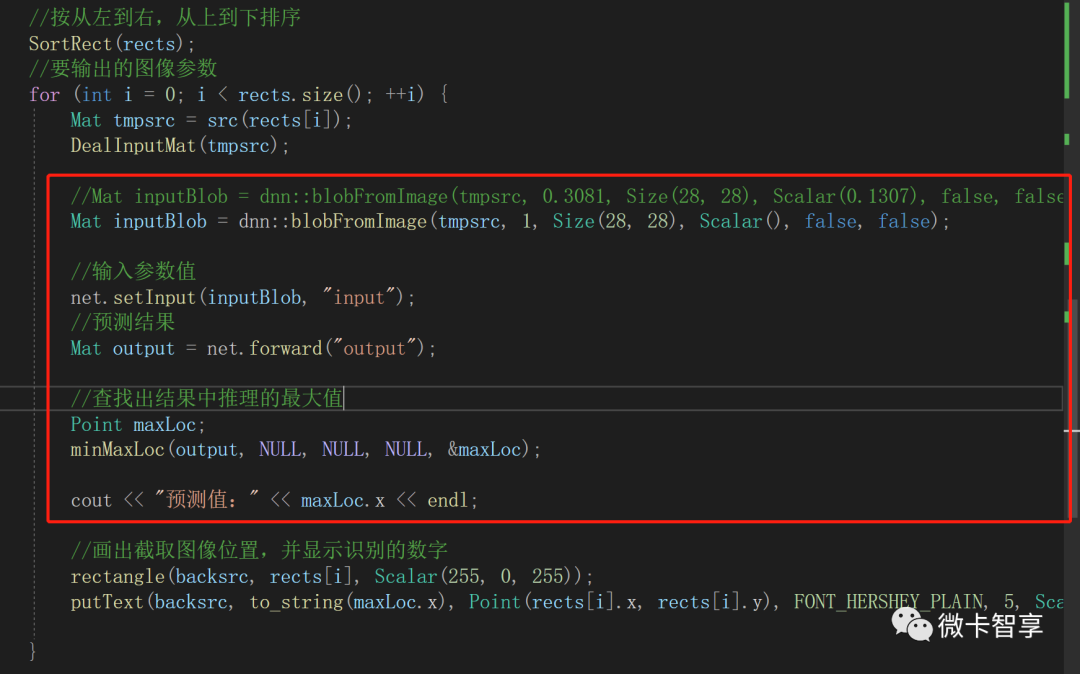
//按从左到右,从上到下排序
SortRect(rects);
//要输出的图像参数
for (int i = 0; i < rects.size(); ++i) {
Mat tmpsrc = src(rects[i]);
DealInputMat(tmpsrc);
//Mat inputBlob = dnn::blobFromImage(tmpsrc, 0.3081, Size(28, 28), Scalar(0.1307), false, false);
Mat inputBlob = dnn::blobFromImage(tmpsrc, 1, Size(28, 28), Scalar(), false, false);
//输入参数值
net.setInput(inputBlob, "input");
//预测结果
Mat output = net.forward("output");
//查找出结果中推理的最大值
Point maxLoc;
minMaxLoc(output, NULL, NULL, NULL, &maxLoc);
cout << "预测值:" << maxLoc.x << endl;
//画出截取图像位置,并显示识别的数字
rectangle(backsrc, rects[i], Scalar(255, 0, 255));
putText(backsrc, to_string(maxLoc.x), Point(rects[i].x, rects[i].y), FONT_HERSHEY_PLAIN, 5, Scalar(255, 0, 255), 1, -1);
}
imshow("backsrc", backsrc);
waitKey(0);
return 0;
}划重点
01
二值化时使用THRESH_BINARY_INV
Minist训练集中的图片都全用的黑底白字,所以在二值化的时候需要使用THRESH_BINARY_INV直接变为黑底白字。
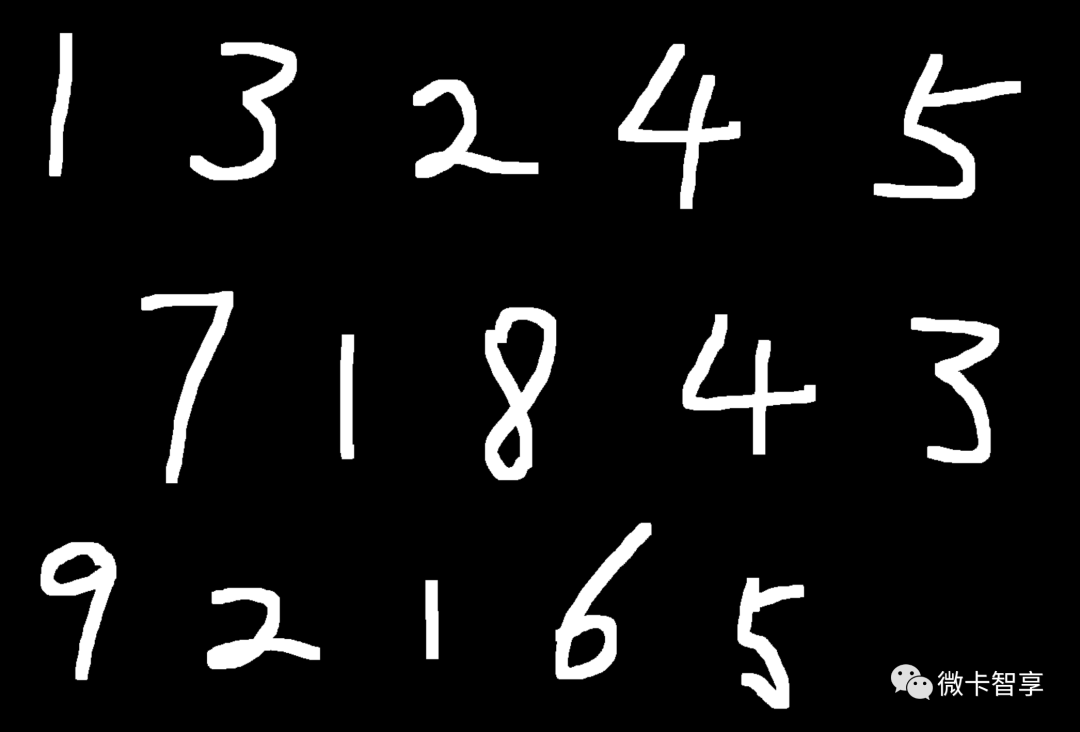
02
形态学操作膨胀
使用膨胀主要是防止手写的数字断开,造成轮廓查找时变为两个轮廓了

这里用5X5的卷积,膨胀了三次,使用膨胀和没使用的对比:
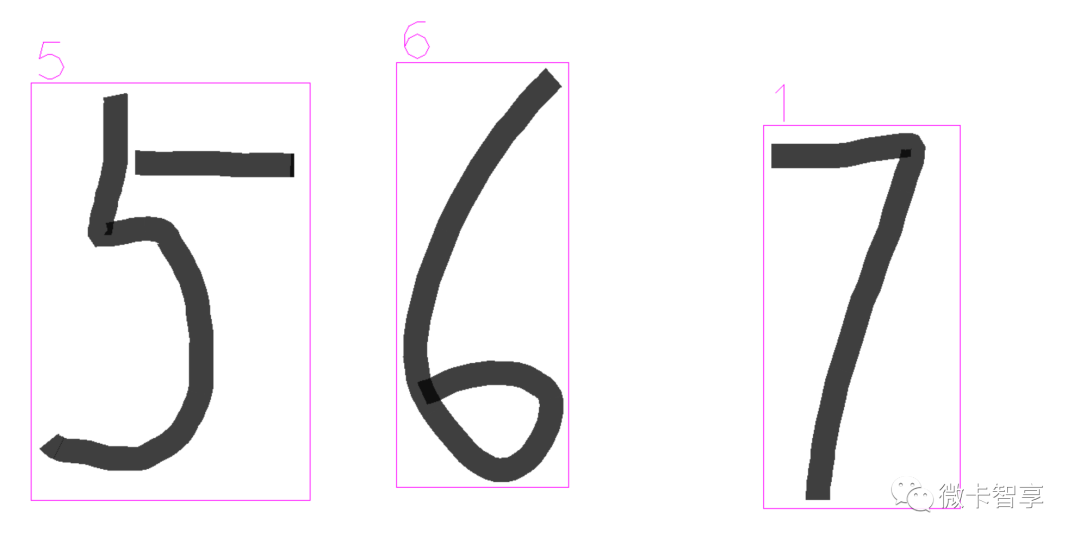
使用膨胀处理
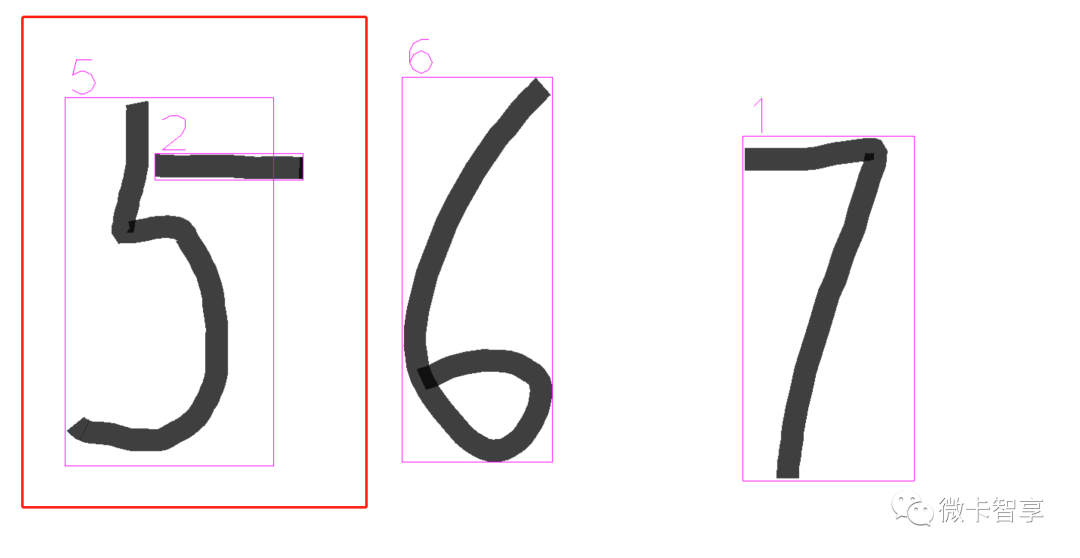
未使用膨胀,多识别了一个轮廓
03
轮廓排序
如果直接使用查出轮廓输出,在图片中显示识别的数字是没问题,不过输出的顺序就会有问题,像刚才上面的这个图,5,6,7三个数字,如果直接查找 轮廓,按contours的序号来排序的话,顺序是7,5,6

如果是按顺序输出文本,明明我手写的是567,输了同的结果确是756,这样会有问题,所以这里就需要将查找出的轮廓进行排序,排序的方式就是按从左到右,从上到下的顺序。
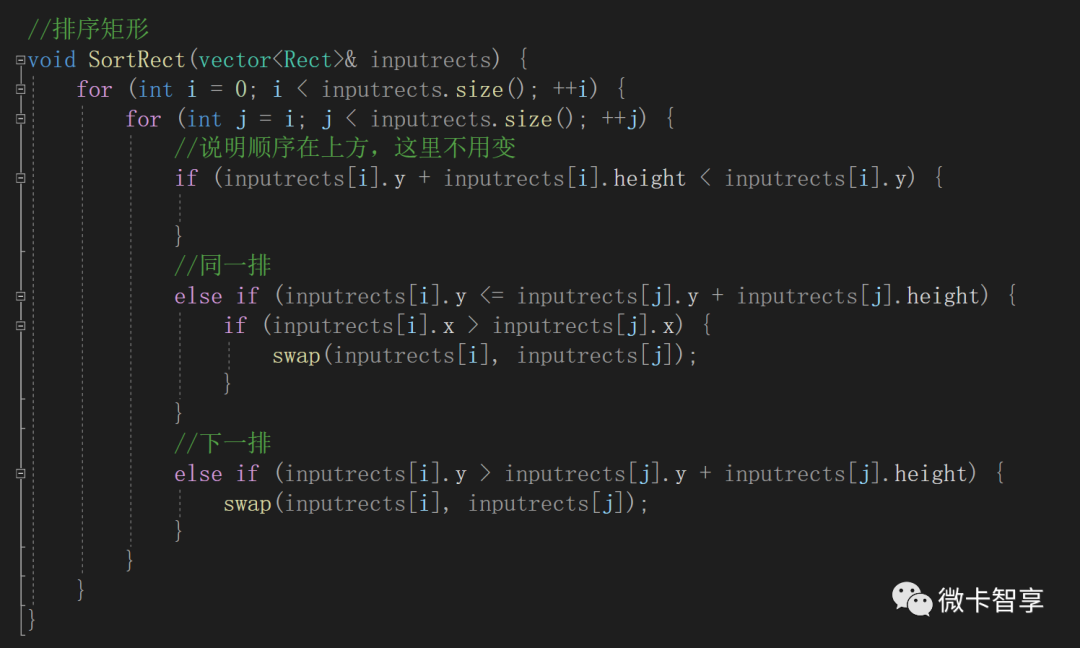
轮廓排序的方法
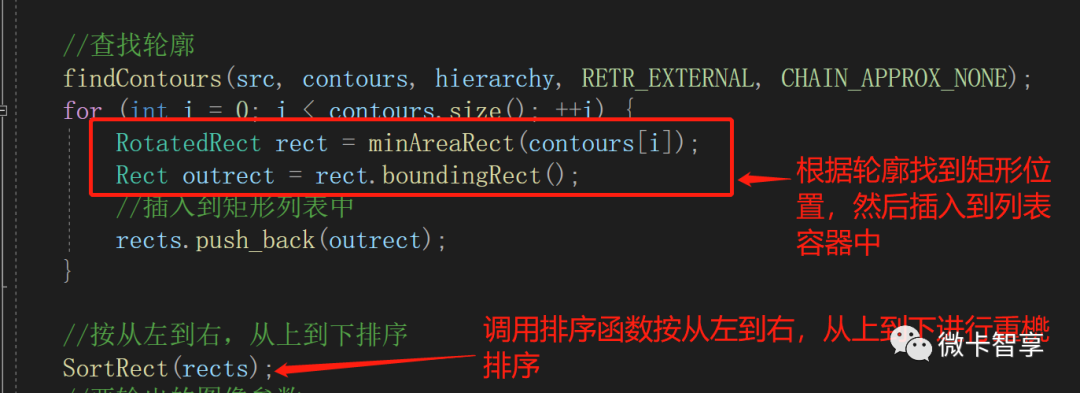
04
缩放图片到28X28
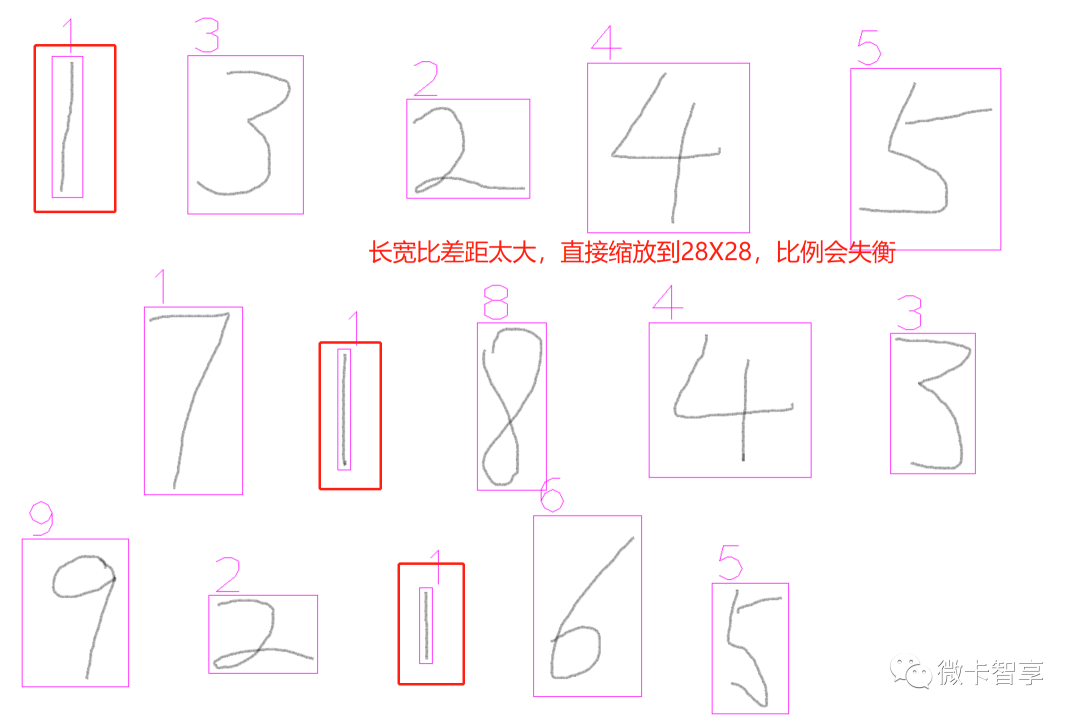
像上中图,特别是数字1查找的轮廓,如果直接缩放直28X28,图像的比例会失衡,所以这里需要对提取的轮廓图像先进行处理。
判断宽高,差额补齐。比如上图中的数字1,宽度比高度差了好多,那我们用现在的高度减去宽度,再除2(除2是让左右两边平均填充上),这样比例就接近正方形了,缩放时比例不会失衡。填充使用的函数copyMakeBorder。
防止缩放后数字直接贴边了,我们在提取的轮廓四周再填充一个阈值,全部用黑色填充,最后再进行缩放。效果大概如下:
轮廓提取图像
处理前
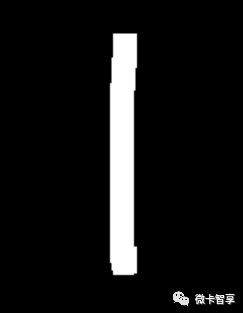
填充后的图像
处理后
05
OpenCV DNN推理
推理时先使用blobFromImage将图像进行预处理,然后再用DNN进行推理,最终返回的结果需要再通过minMaxLoc提取到最大值,判断推理的数字。
上面的步骤后,C++ OpenCV进行手写数字识别就可以完成了,这一系列完结时,会将源码统一放到GitHub中。
完

往期精彩回顾
pyTorch入门(三)——GoogleNet和ResNet训练
pyTorch入门(二)——常用网络层函数及卷积神经网络训练
pyTorch入门(一)——Minist手写数据识别训练全连接网络

![[ 妙用css ]:用css变量解决开发实际问题](https://img-blog.csdnimg.cn/eb9e05db105b4c0eb02406eb800cfa03.jpeg#pic_center)




![[附源码]计算机毕业设计Python个性化名片网站(程序+源码+LW文档)](https://img-blog.csdnimg.cn/eed66868c526481381187f4682a2d9d0.png)