【MySQL】史上最全的MySQL高性能优化总结
【1】深入理解MySQL索引底层数据结构与算法
1. 为什么不使用二叉树、红黑树、B树来作为索引?
2. MyISAM 与 Innodb存储引擎有什么区别?
3. MySQL 的索引按照功能分类可以分几种?
4. MySQL 的的聚集索引与非聚集索引是什么?
5. 为什么建议 InnoDB表必须建主键?
6. 为什么推荐使用整型的自增主键?为什么不用UUID?
7. 为什么非主键索引的叶子节点存储的是主键值?
8. 联合索引的底层存储结构长什么样?
【2】Explain详解与索引最佳实践
1. 使用Explain各个字段的含义
2. SQL的优化法则
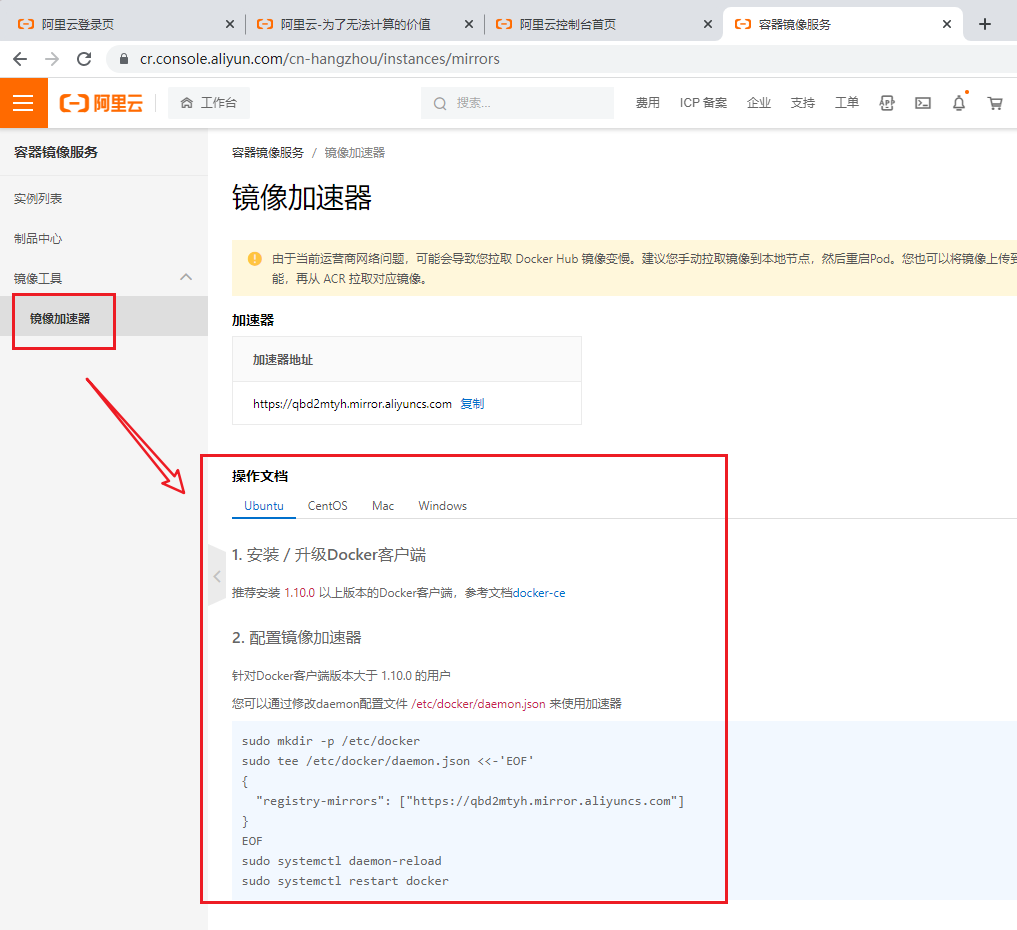
【3】SQL底层执行原理详解
图解MySQL架构
【4】MySQL索引优化实战(上)
1. 联合索引第一个字段用范围不会走索引怎么优化?
2. 什么是索引下推?
3. 为什么like KK% 会走索引?为什么范围查找(大于号)没有用索引下推优化?
4. trace工具的使用
5. Order by与Group by优化
6. 单路排序与双路排序
7. 索引设计原则
【5】MySQL索引优化实战(下)
1. 分页查询怎么优化?
2. MySQL的NLJ与BNL
3. 被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 NLJ 呢?
4. 关联SQL优化
5. count查询优化
【6】深入理解MySQL事务隔离级别与锁机制
1. 事务的ACID
2. 四种隔离级别
3. MySQL中各种锁的分类
4. 各个事务隔离级别所发生的问题-案例分析
5. MySQL锁优化建议
【7】深入理解MVCC与BufferPoll缓存机制
1. undo日志版本链与read view机制详解
2. Innodb引擎SQL执行的BufferPool缓存机制
本人之前写过许多关于MySQL性能优化的文章,在这里会将它们做一个大串讲~
这里主要是讲解MySQL底层数据结构,索引优化,事务及其相关特性,MVCC机制,BufferPool缓存机制等内容。
【1】深入理解MySQL索引底层数据结构与算法
【MySQL】深入理解MySQL索引底层数据结构与算法_面向鸿蒙编程的博客-CSDN博客_图灵mysql 内存架构![]() https://blog.csdn.net/weixin_43715214/article/details/127080931
https://blog.csdn.net/weixin_43715214/article/details/127080931
1. 为什么不使用二叉树、红黑树、B树来作为索引?
一层表示一次IO,红黑树保证了平衡性,但是当数据量达到了千万级别,红黑树会达到将近24层
B树和B+树最大的区别就是,B+树的非叶子节点不存储data,只存储索引(指针),可以放更多的索引!
2. MyISAM 与 Innodb存储引擎有什么区别?
MyISAM 用的是非聚集索引方式,数据和索引落在不同的两个文件上。InnoDB 是聚集索引方式,数据和索引都存储在同一个文件。
MyISAM管理非事务表,提供高速存储和检索以及全文搜索能力,如果再应用中执行大量select操作,应该选择MyISAM。
InnoDB用于事务处理,具有ACID事务支持等特性,如果在应用中执行大量insert和update操作,应该选择InnoDB。
3. MySQL 的索引按照功能分类可以分几种?
普通索引、唯一索引、主键索引、全局索引(基本不用)
4. MySQL 的的聚集索引与非聚集索引是什么?
InnoDB的主键索引就是聚集索引。在InnoDB中只有主键索引是聚集索引,其它都是非聚集的!!!
聚集索引最主要的优势就是查询快。如果要查询完整的数据行,使用非聚集索引往往需要回表才能实现,而使用聚集索引则能一步到位。
一张表只能有一个聚集索引,但可以有多个非聚集索引。
非聚集索引我们一般也称为二级索引或者辅助索引。使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。
5. 为什么建议 InnoDB表必须建主键?
ibd 文件必须要用一棵B+树来组织!如果我们没有指定,那么这个动作将会由MySQL来完成,所以不推荐!
6. 为什么推荐使用整型的自增主键?为什么不用UUID?
整形比字符串(UUID)省空间
整形判断大小比字符串(UUID)效率要高(字符串是比较ASCALL码)
如果我们设计的主键它不是自增的话,那我们插入下一个节点的时候,那这棵B+树很可能需要频繁的做平衡和节点分裂,非常浪费性能!!!
7. 为什么非主键索引的叶子节点存储的是主键值?
非主键索引(二级索引)没有必要放一整张表的数据,因为主键索引里面已经放了。找到主键索引然后再做一次“回表”操作就行了!
8. 联合索引的底层存储结构长什么样?

【2】Explain详解与索引最佳实践
【MySQL】Explain详解与索引最佳实践_面向鸿蒙编程的博客-CSDN博客![]() https://blog.csdn.net/weixin_43715214/article/details/127131144
https://blog.csdn.net/weixin_43715214/article/details/127131144
1. 使用Explain各个字段的含义
explain关键字一共有9个字段,我们需要了解它们的含义!
2. SQL的优化法则
(1)最左前缀法则
(2)尽量不要在索引列上做任何操作
(3)存储引擎不能使用索引中范围条件右边的列
(4)尽量使用覆盖索引,减少 select * 语句
(5)使用不等于(!= 或者 <>),not in,not exists 的时候无法使用索引
(6)is null,is not null 一般情况下也无法使用索引
(7)like以通配符开头('$abc...'),索引失效会变成全表扫描操作
(8)字符串不加单引号索引失效
(9)范围太大查询,不走索引
【3】SQL底层执行原理详解
【MySQL】SQL底层执行原理详解_面向鸿蒙编程的博客-CSDN博客_图灵mysql![]() https://blog.csdn.net/weixin_43715214/article/details/127190252
https://blog.csdn.net/weixin_43715214/article/details/127190252
图解MySQL架构

【4】MySQL索引优化实战(上)
【MySQL】MySQL索引优化实战(上)_面向鸿蒙编程的博客-CSDN博客![]() https://blog.csdn.net/weixin_43715214/article/details/127293804
https://blog.csdn.net/weixin_43715214/article/details/127293804
1. 联合索引第一个字段用范围不会走索引怎么优化?
方法一:使用强制走索引,force index(idx_name_age_position),但是一般会更慢
方法二:覆盖索引(推荐!)
2. 什么是索引下推?
SELECT * FROM employees
WHERE name like 'LiLei%' AND age = 22 AND position ='manager';这个查询在联合索引里匹配到名字是 'LiLei' 开头的索引之后,同时还会在索引里过滤age和position这两个字段,拿着过滤完剩下的索引对应的主键id,再回表查整行数据。
索引下推的目的就是减少回表次数!!!
3. 为什么like KK% 会走索引?为什么范围查找(大于号)没有用索引下推优化?
-- ALL
EXPLAIN SELECT * FROM employees
WHERE name > 'LiLei' AND age = 22 AND position ='manager';
-- range (不管数据量大小都会走索引)
EXPLAIN SELECT * FROM employees
WHERE name like 'LiLei%' AND age = 22 AND position ='manager';
EXPLAIN SELECT * FROM employees_copy
WHERE name like 'LiLei%' AND age = 22 AND position ='manager';估计应该是MySQL认为范围查找过滤的结果集过大,like KK% 在绝大多数情况来看,过滤后的结果集比较小,所以这里MySQL选择给 like KK% 用了索引下推优化(不管数据量是大还是小!)
4. trace工具的使用
第一阶段:SQL准备阶段,格式化sql
第二阶段:SQL优化阶段
第三阶段:SQL执行阶段
5. Order by与Group by优化
我们要看order by后面的字段是否走索引,看的是Extra的值是否含有Using filesort,有则不走索引。
如果order by的条件不在索引列上,就会产生Using filesort。能用覆盖索引尽量用覆盖索引!!!
6. 单路排序与双路排序
双路排序在8.0.20的版本后面基本被废弃了!
7. 索引设计原则
- 代码先行,索引后上
- 联合索引尽量覆盖条件
- 不要在小基数字段上建立索引
- 长字符串我们可以采用前缀索引
- where与order by冲突时优先where
【5】MySQL索引优化实战(下)
【MySQL】MySQL索引优化实战(下)_面向鸿蒙编程的博客-CSDN博客![]() https://blog.csdn.net/weixin_43715214/article/details/127544276
https://blog.csdn.net/weixin_43715214/article/details/127544276
1. 分页查询怎么优化?
关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录。
-- 0.051s
select * from employees e
inner join
(select id from employees order by name limit 90000,5) ed
on e.id = ed.id;2. MySQL的NLJ与BNL
NLJ 嵌套循环连接

BNL 基于块的嵌套循环连接

3. 被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 NLJ 呢?
SQL不走索引
如果是 NLJ,那么扫描行数为 100 * 10000 = 100万次,这个是磁盘扫描。
如果是 BNL,那么它会有10000+100次的磁盘扫描,100万次的内存过滤。
很显然,用BNL磁盘扫描次数少很多,相比于磁盘扫描,BNL的内存计算会快得多!
因此MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法;如果有索引一般选择 NLJ 算法,有索引的情况下 NLJ 算法比 BNL算法性能更高。
4. 关联SQL优化
- 被驱动表的关联字段(尽量)一定要加索引。
- 小表驱动大表
5. count查询优化
当字段有索引时
count(*)≈count(1)>count(字段)>count(主键 id)当字段无索引
count(*)≈count(1)>count(主键 id)>count(字段)【6】深入理解MySQL事务隔离级别与锁机制
【MySQL】深入理解MySQL事务隔离级别与锁机制_面向鸿蒙编程的博客-CSDN博客_图灵 mysql![]() https://blog.csdn.net/weixin_43715214/article/details/127594907
https://blog.csdn.net/weixin_43715214/article/details/127594907
1. 事务的ACID
原子性、一致性、隔离性、持久性。
2. 四种隔离级别

3. MySQL中各种锁的分类
乐观锁 和 悲观锁;读锁、写锁、意向锁;表锁 和 行锁
4. 各个事务隔离级别所发生的问题-案例分析
5. MySQL锁优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的SQL尽量放在事务最后执行
- 尽可能低级别事务隔离
【7】深入理解MVCC与BufferPoll缓存机制
【MySQL】深入理解MVCC与BufferPoll缓存机制_面向鸿蒙编程的博客-CSDN博客_mysql mvcc和buffer![]() https://blog.csdn.net/weixin_43715214/article/details/127672669
https://blog.csdn.net/weixin_43715214/article/details/127672669
1. undo日志版本链与read view机制详解
undo日志版本链
undo日志版本链是指一行数据被多个事务依次修改过后,在每个事务修改完后,MySQL会保留修改前的数据undo回滚日志,并且用两个隐藏字段 trx_id 和 roll_pointer 把这些undo日志串联起来形成一个历史记录版本链。

read view机制

MVCC机制的实现就是通过read-view机制与undo版本链比对机制,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。
2. Innodb引擎SQL执行的BufferPool缓存机制