在性能分析中,前端的性能工具,我们只需要关注几条曲线就够了:TPS、响应时间和错误率。这是我经常强调的。
但是关注 TPS 到底应该关注什么内容,如何判断趋势,判断了趋势之后,又该如何做出调整,调整之后如何定位原因,这才是我们关注 TPS 的一系列动作。
今天,我们就通过一个实际的案例来解析什么叫 TPS 的趋势分析。
案例描述
这是一个案例,用一个 2C4G 的 Docker 容器做服务器。结构简单至极,如下所示:
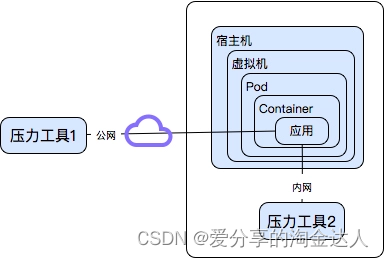
当用个人电脑(上图中压力工具 1)测试云端服务器时,达到 200 多 TPS。但是当用云端同网段压力机(上图中压力工具 2)测试时,TPS 只有 30 多,并且内网压力机资源比本地压力机要高出很多,服务器资源也没有用完。
在这样的问题面前,我通常都会有一堆的问题要问。
1、现象是什么?
2、脚本是什么?
3、数据是什么?
4、架构是什么?
5、用了哪些监控工具?
6、看了哪些计数器?
在分析之前,这些问题都是需要收集的信息,而实际上在分析的过程中,我们会发现各种数据的缺失,特别是远程分析的时候,对方总是不知道应该给出什么数据。
我们针对这个案例实际说明一下。
这个案例的现象是 TPS 低,资源用不上。
下面是一





![[附源码]Python计算机毕业设计Django学生社团信息管理系统](https://img-blog.csdnimg.cn/52a210cd643942c58408ca19aec48f11.png)