一、 ODPS 基本面-F10
1、什么是ODPS?
1、开发数据处理服务(Open Data Processing Service,简称ODPS),2016年后更名MaxComputer。ODPS是一种由阿里云自主研发,针对TB/PB级数据、实时性要求不高的分布式处理服务。主要服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务。
2、odps向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。该技术已经在阿里巴巴集团内部得到大规模应用,例如:大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等。
3、ODPS能够彻底无极限解决大数据存储与运算瓶颈,使我们专心于数据分析和挖掘,最大化发挥数据价值。且能够开箱即用,用户无需关心集群的搭建和运维,仅需简单的几步操作,即可开始数据的分析和挖掘任务。ODPS的多层次数据存储和访问安全机制保护数据不丢失、不泄露、不被窃取。此外ODPS实行按量付费,最大化降低数据使用成本,帮助用户解决数据烦恼,轻松实现大数据。
2、ODPS更新迭代
在2022年世界互联网大会乌镇峰会期间,2022年“世界互联网领先科技成果”发布。
ODPS:数据驱动而生的超大规模多场景融合的大数据计算平台项目入选。
ODPS是阿里云自研的一体化大数据计算平台和数据仓库产品,为数字化转型提供多功能、低成本、高性能、稳定、安全、开放和易用的整套产品方案,
提供实时离线一体、流批一体、湖仓一体、大数据+AI一体的多场景能力。

3、2022年11月新发布的阿里云ODPS技术突破主要体现在以下三方面:
一、是在数据底座的可靠性上,ODPS支撑EB级数据容量,全球化部署的能力,以及兼容级别的可靠性和安全性。
二、是在智能计算的规模和利用率上,ODPS对计算引擎和存储引擎进行深度优化,基于多基线保障的调度能力和自动化运维能力,实现10万级服务器、十余个数据中心、每天千万级计算任务作业的高性能数据计算。
三、是通过一体化架构与丰富的计算引擎支撑关系型数据、非结构化数据、机器智能等一系列场景;创新性地提出了数据湖和数据仓库一体化的架构,为科研创新提供坚实的算力基座。
4、集群能力
ODPS从2013年单集群突破5000台进行单独并行计算以来,目前,最高可支持超过10万台服务器进行并行计算,单日最大数据处理能力达到2.79EB,ODPS同时拥有海内外300多项技术专利。
采用比MapReduce框架更加灵活的计算模型。ODPS存储多份拷贝,所有计算在沙箱中运行。ODPS以Java SDK方式提供服务基于表的数据存储,用户不必关心文件存储格式,基于SQL的数据处理使得用户不必关心分布式技术细节。ODPS支持多用户协同分析数据,多种权限管理方式和灵活的数据访问控制策略。
5、ODPS分层
- 接入层:以RESTful API方式提供服务,用户及数据应用通过Http/Https与接入层建立链接上传数据及提交数据分析作业;
- 逻辑层:ODPS的核心控制层,负责用户认证、签权、作业分发、Meta管理以及存储计算集群管理;
- 存储计算层:数据的存储及计算作业运行。该层是由多个集群构成,所有集群挂接到ODPS控制层。数据存储在飞天的盘古上,每个文件分三份存储。控制层将用户提交的计算作业调度不同的集群上。
二、ODPS基本功能
2.1、用户项目空间-Project
项⽬空间是阿⾥云⼤数据集成服务平台最基本的组织对象,是您管理表(Table)、资源(Resource)、⾃定义函数(UDF)、节点(Node)、权限等的基本单元。
项目空间是MaxComputer 的基本组织单元,它类似Oracle的schema或者Mysql中的database。是进行多用户隔离和访问控制的主要边界。一个用户可以同时拥有多个项目空间的权限。通过安全授权建立共享通道,进行数据交换让其可以在一个项目空间中访问另一个项目空间中的对象。

2.2、 表(Table)
表是MaxCompute的数据存储单元。它在逻辑上也是由行和列组成的二维结构,每行代表一条记录,每列表示相同数据类型的一个字段,一条记录可以包含一个或者多个列,各个列的名称和类型构成这张表的Schema。
MaxComputer的表格分为两种类型:外部表及内部表。
内部表的所有数据都被存储在MaxComputer中。表中的列可以是MaxCompute支持的任意数据类型(Bigint、Double、String、 Boolean和Datetime)。MaxCompute中的各种类型计算任务(输入、输出)的操作对象都是表。用户可以创建、删除表以及向表中导入数据。
对于外部表,MaxCompute并不真正持有数据,表格的数据可以存放在OSS中。MaxCompute仅会记录表格中的Meta信息。用户可以通过MaxCompute的外部表机制处理OSS上的非结构化数据,例如:视频、音频、气象、地理信息等。
其主要流程包括:
1、将数据上传至OSS;
2、在RAM产品中授予MaxCompute服务读取OSS数据权限。
3、自定义Extractor:用户读取OSS上特殊格式数据。目前,MaxCompute默认提供CSV格式的Extractor,并提供视频格式数据读取的代码样例。
4、创建外部表;
5、执行SQL作业分析数据;
注意:目前MaxCompute仅支持读取外部数据,即读取OSS数据,不支持向外部写入数据;
2.3、 分区(Partition)
分区表指的是在创建表时指定的分区空间,即指定表内的某几个字段作为分区列。
大多数情况下,用户可以将分区类比为文件系统下的目录。
MaxCompute将分区列每一个值作分区(目录)。用户可以指定多级分区,即将表的多个字段作为表的分区,分区之间正如多级目录的关系。在使用数据时如果指定了需要访问的分区名称,则只会读取相应的分区,避免扫描全表,提高处理效率,降低费用。
create table src (key string, value bigint) partitioned by (pt string);
目前,MaxCompute仅承诺String分区。且目前最多支持六级分区
2.4、 自定义函数(UDF)
我们可以在MaxCompute SQL中使用系统的内建函数完成一定的计算和计数功能。但是当内建函数无法满足要求时,可以使用MaxCompute提供的Java编程接口开发自定义函数UDF,UDF又可以进一步分为标量值函数UDF、自定义聚合函数UDAF和自定义表值函数UDTF三种。
应用场景:
一般常见 于数据仓库中-建立 带有 业务属性的函数或 带业务特性的主键。
2.5 、资源(Resource)**
资源是MaxCompute的特有概念。用户如果想使用MaxCompute的自定义函数(UDF)或者MapReduce功能需要依赖资源来完成。
例如用户在编写好UDF后,需要将编译好的jar包以资源的形式上传到ODPS。运行这个UDF时,MaxCompute会自动下载这个Jar包,获取用户代码,运行UDF而无需用户干预。上传Jar包的过程就是在MaxCompute上创建资源的过程。
2.6 、任务(Task)和作业(Job)
任务
任务是ODPS的基本计数单元。SQL以及MapReduce功能都是通过任务完成的。
对于用户提交的大多数任务,特别是计算型任务,MaxCompute会将其进行解析,得出任务的执行计划。
执行计划是由具有依赖关系的多个执行阶段(Stage)构成的。
目前,执行计划逻辑上可以被看作一个有向图,图中的点是各个执行阶段,边是各个执行阶段之间的依赖关系。在同一个执行阶段内,会有多个进程,也称之为Worker,共同完成该执行阶段的计算工作。同一个执行阶段内的不同Worker之间只是处理的数据不同,执行逻辑完成相同。
2.7 、作业(Job)
是由一个或者多个Task以及表示其执行次序关系的工作流(Workflow),工作流是个有向无环图。当一个作业被提交到系统中执行时,该作业就会拥有一个作业实例(Instance)。另一方面,部分MaxCompute任务并不是计算型任务。例如DDL SQL语句,这些任务本质上只需要读取修改MaxCompute的元数据,因此这些任务不能被解析出执行计划。
2.8 、工作流
工作流是一个DAG图(有向无环图),其描述了作业中多个节点之间的逻辑(依赖关系)和规则(运行约束)。
2.9 、节点
节点指通过数据开发界⾯提交发布或者调度API新建接口创建的调度定义信息。
它属于工作流的子对象,也称为任务,是大数据开发平台数据处理和分析过程最基本单元,每个任务对应DAG图中的一个节点,其可以是一个SQL Query、命令和MapReduce程序。
2.10 、业务流程
业务流程包含若⼲节点及其节点相互之间的依赖关系。
参见2.11 中图。
2.11 、依赖关系
依赖关系是描述两个或多个节点/工作流之间的语义连接关系,其中上游节点/工作流运行可以影响下流节点/工作流的运行状态,反之则不成立。
如下图:
以箭头方向来体现上下游节点依赖关系。
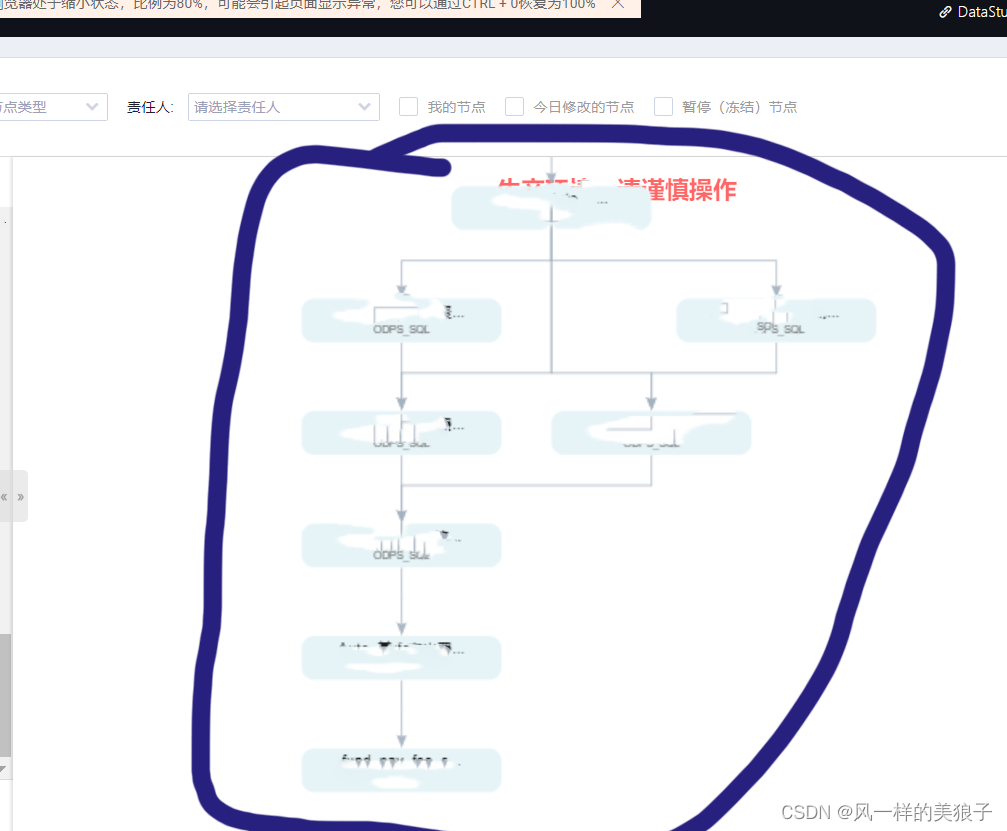
2.12、实例/任务实例
节点需要通过DataWorks调度系统转换成任务实例才能运⾏。
在Datework平台中,节点任务在执行时会被实例化,并以ODPS实例的方式存在。实例会经历未运行、等待时间/等待资源、运行中、成功/失败几个状态。








![[附源码]Python计算机毕业设计Django学生社团信息管理系统](https://img-blog.csdnimg.cn/52a210cd643942c58408ca19aec48f11.png)

