同门的学妹做语义分割,于是打算稍微研究一下,最后的成果就是这篇文章,包括使用数据集进行测试,以及每一个部分的代码,还有一些思考改动和经验。
充分吸收本文知识你需要有pytorch的基础
U-net
U-Net:深度学习中的图像分割之星
当我们谈论图像处理中的深度学习,大多数人会立即想到卷积神经网络(CNN)和其在图像分类中的优异性能。但是,深度学习不仅仅可以进行图像分类,还有很多其他应用,其中之一就是图像分割。U-Net就是这一应用中的明星。
- 什么是图像分割?
图像分割的目的是将图像分割成若干个有意义的部分,并对每一个部分进行标注。与图像分类不同的是,图像分类的目的是给整张图像一个标签,而图像分割要给图像中的每一个像素一个标签。
- pytroch Unet复现
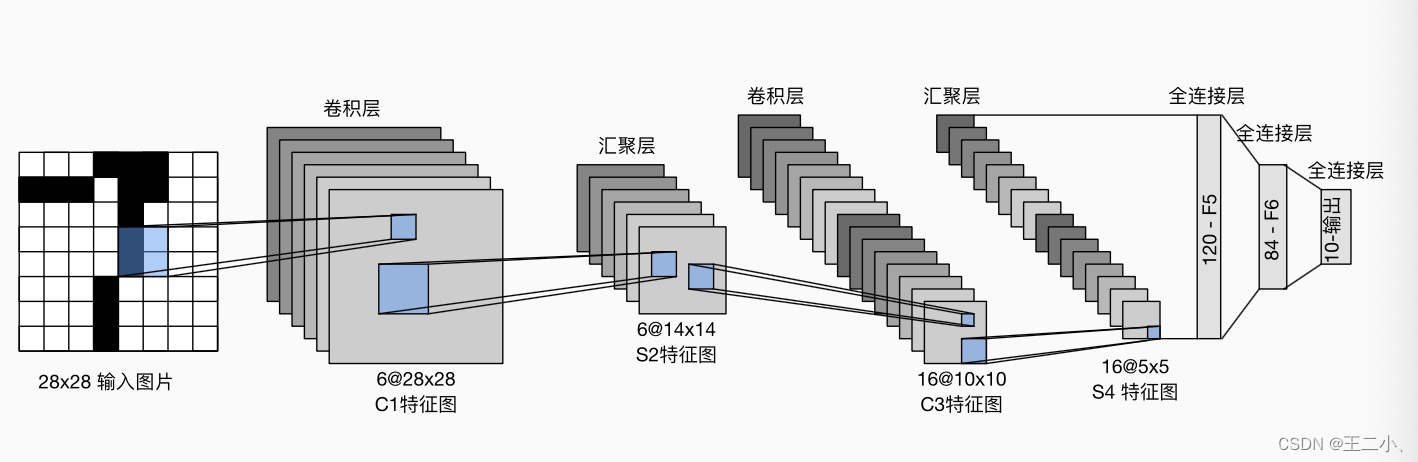
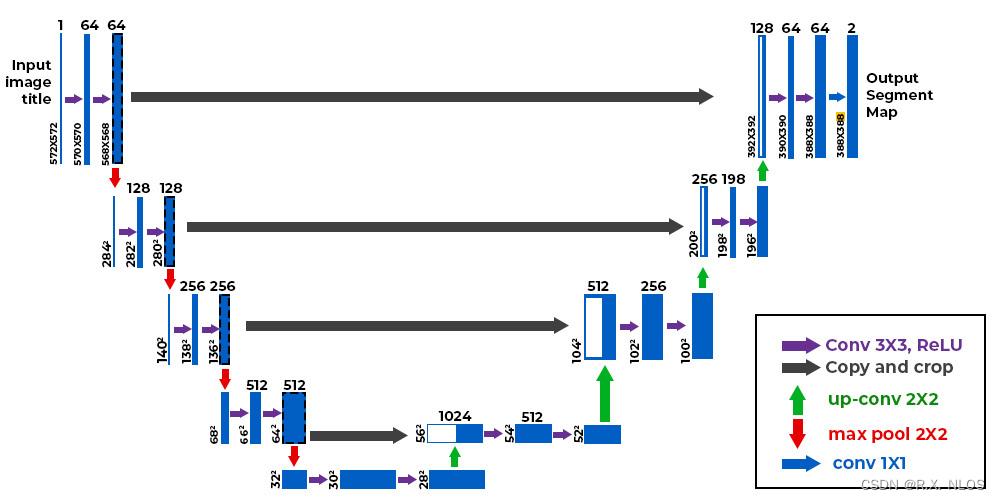
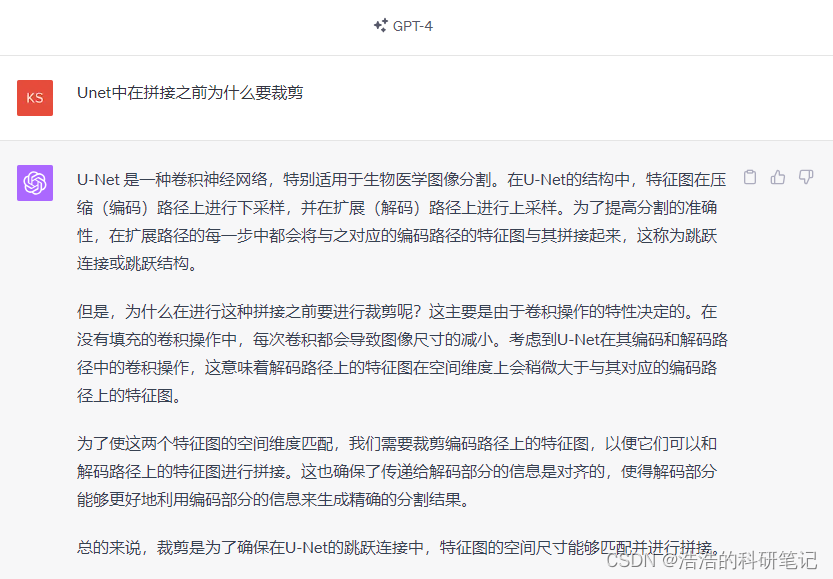
接下来我们就要用pytorch来实现图像分割的效果,下面是Unet的官网网络结构模型,实际上数据变化维度不是很清晰,之后我们对其进行一下优化让我们看起来更明白,下面是原论文的图。
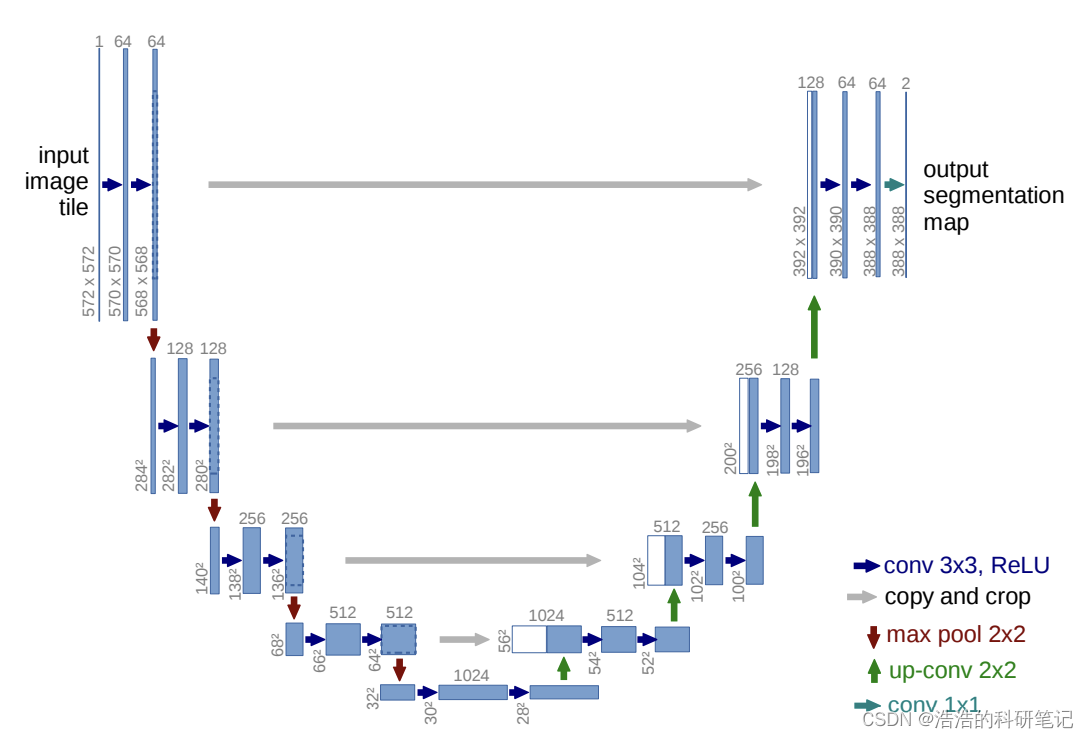
例如在与U的右侧拼接的时候他写的是copy(复制) and crop(裁剪) 数据维度具体是如何变小的裁剪有什么规则吗。这个问题我问了一下ChatGPT4,回答说是卷积让图片变小了,为了匹配尺寸,那这样裁剪不就损失信息了吗,572-570就少了两圈,这也不是减少参数量啊,好鸡肋。
还有为什么最后输出的图片为什么尺寸为什么不能等于原图,我们自己的数据集的标签大小和输入的图的大小似乎应该是一样的。如果大小不一致那预处理起来岂不是很不方便。
总之ChatGPT的回答还是参数选择问题,可能还是由于深度学习的弱解释性,导致了当我们追问超参数时无法得到一个确切的答复,既然没有什么特殊意义,我们就开始改造成更容易理解的样子。

所以凭借自己的理解我对这个图进行了一下改造改造成了易于理解的样子。
改动如下
- 首先将原文中3×3的卷积核填充为0的卷积层改成1保证在经过该类卷积层的时候输出图片的大小不变
- 第二发现在最后输出的时候原作者用了一个卷积核大小为1×1的卷积层,这也看不出来他有什么实际意义,也给他替换成3×3填充为1的,效果也没啥影响,不搞特立独行。
假设输入是一个3×512×512的图片输出也是3×512×512,中间每降一层样本点数量减半这样才符合我们实际的应用。
复现结果代码如下
import torch
class Conv(torch.nn.Module):
def __init__(self,inchannel,outchannel):
super(Conv, self).__init__()
self.feature = torch.nn.Sequential(
torch.nn.Conv2d(inchannel,outchannel,3,1,1),
torch.nn.BatchNorm2d(outchannel),
torch.nn.ReLU(),
torch.nn.Conv2d(outchannel,outchannel,3,1,1),
torch.nn.BatchNorm2d(outchannel),
torch.nn.ReLU())
def forward(self,x):
return self.feature(x)
class UNet(torch.nn.Module):
def __init__(self,inchannel,outchannel):
super(UNet, self).__init__()
self.conv1 = Conv(inchannel,64)
self.conv2 = Conv(64,128)
self.conv3 = Conv(128,256)
self.conv4 = Conv(256,512)
self.conv5 = Conv(512,1024)
self.pool = torch.nn.MaxPool2d(2)
self.up1 = torch.nn.ConvTranspose2d(1024,512,2,2)
self.conv6 = Conv(1024,512)
self.up2 = torch.nn.ConvTranspose2d(512,256,2,2)
self.conv7 = Conv(512,256)
self.up3 = torch.nn.ConvTranspose2d(256,128,2,2)
self.conv8 = Conv(256,128)
self.up4 = torch.nn.ConvTranspose2d(128,64,2,2)
self.conv9 = Conv(128,64)
self.conv10 = torch.nn.Conv2d(64,outchannel,3,1,1)
def forward(self,x):
xc1 = self.conv1(x)
xp1 = self.pool(xc1)
xc2 = self.conv2(xp1)
xp2 = self.pool(xc2)
xc3 = self.conv3(xp2)
xp3 = self.pool(xc3)
xc4 = self.conv4(xp3)
xp4 = self.pool(xc4)
xc5 = self.conv5(xp4)
xu1 = self.up1(xc5)
xm1 = torch.cat([xc4,xu1],dim=1)
xc6 = self.conv6(xm1)
xu2 = self.up2(xc6)
xm2 = torch.cat([xc3,xu2],dim=1)
xc7 = self.conv7(xm2)
xu3 = self.up3(xc7)
xm3 = torch.cat([xc2,xu3],dim=1)
xc8 = self.conv8(xm3)
xu4 = self.up4(xc8)
xm4 = torch.cat([xc1,xu4],dim=1)
xc9 = self.conv9(xm4)
xc10 = self.conv10(xc9)
return xc10
if __name__ == "__main__":
input = torch.randn((1,3,512,512))
# model = Conv(3,3)
model = UNet(3,1)
output = model(input)
print(output.shape)
这段代码实现了一个基于 PyTorch 的 U-Net 神经网络架构代码分为两个主要部分,首先是 Conv 类,用于定义 U-Net 中的卷积块。然后是 UNet 类,用于构建整个 U-Net 网络。
这段代码展示了如何使用 PyTorch 构建 U-Net 神经网络架构,用于图像分割任务。U-Net 是一种经典的卷积神经网络结构,广泛应用于医学图像分割、图像处理等领域。
-
Conv 类(卷积块):
Conv类用于定义 U-Net 中的基本卷积块,它包含了两个卷积层、批归一化层和 ReLU 激活函数,用于特征提取。__init__方法:初始化卷积块,接收输入通道数inchannel和输出通道数outchannel,定义了一个包含多个卷积、批归一化和激活函数的序列。forward方法:实现卷积块的前向传播,接收输入数据x,通过序列操作将输入数据传递并加工,最终返回加工后的特征。
-
UNet 类(U-Net 网络):
UNet类定义了 U-Net 网络的结构,它由编码器和解码器部分组成,用于实现图像分割。__init__方法:初始化 U-Net 网络,接收输入通道数inchannel和输出通道数outchannel(例如,用于生成分割掩码)。- 编码器部分:包括
conv1到conv5,每个卷积块后跟一个最大池化层,用于逐渐减小图像尺寸和提取特征。 - 解码器部分:通过反卷积层和卷积块进行特征上采样和融合,最终生成分割结果。
forward方法:实现 U-Net 网络的前向传播,首先通过编码器提取特征,然后通过解码器生成分割结果。
在 if __name__ == "__main__": 部分,进行了以下操作:
- 创建一个随机输入张量
input,形状为(1, 3, 512, 512),表示一个批次大小为 1、通道数为 3、图像大小为 512x512 的输入图像。 - 创建一个 U-Net 模型实例
model,传入输入通道数为 3(RGB 彩色图像通道数)和输出通道数为 1(用于生成分割掩码)。 - 将输入张量传递给模型进行前向传播,生成输出张量
output。 - 打印输出张量的形状,用于检查网络输出的维度。
这里可能不太常见的就是这个层了torch.nn.ConvTranspose2d了torch.nn.ConvTranspose2d是PyTorch中用于实现二维转置卷积(反卷积)操作的类。它用于对输入数据进行上采样(增加分辨率)并生成更大尺寸的特征图。反卷积在图像分割、超分辨率重建等任务中经常被使用。
下面给一个简单的例子,反卷积和卷积层一样也有输出大小的对应公式。当我们设置反卷积的核大小为2步长为2时,可以将图片的宽高都增大二倍,实现一个上采样的过程OK了解到这其实就可以了,不影响复现。
import torch
import torch.nn as nn
# 定义输入数据,批次大小为1,通道数为3,高度和宽度为4
input_data = torch.randn(1, 3, 4, 4)
# 定义反卷积层
transposed_conv = nn.ConvTranspose2d(in_channels=3, out_channels=2, kernel_size=2, stride=2)
# 对输入数据进行反卷积操作
output_data = transposed_conv(input_data)
# 打印输出数据的形状
print("Input shape:", input_data.shape)
print("Output shape:", output_data.shape)
#Input shape: torch.Size([1, 3, 4, 4])
#Output shape: torch.Size([1, 2, 7, 7])
项目实战DRIVE血管语义分割
接下来我们使用Unet来分割一下DIRIVE数据集
DRIVE数据集介绍
先介绍一下DRIVE数据集
DRIVE数据集主要用于血管分割任务,其中的图像由用于血管定位的手动标记进行了标注。这个数据集的目的是促进与视网膜图像分析、血管分割和疾病诊断相关的计算机视觉算法的发展。
数据集下载之后,打开文件目录如下,这里我把trainning文件夹的名字换成了train
这里的文件夹分为三种一种是images保存的原来的图像

mask保存的是掩码标签
1st_manual 2nd_manual 里面保存的都是血管标签,我么要做的是血管分类任务。所以就是用Image文件夹里面的图像做训练数据,1st_manual里面的图片做标签
数据集读取
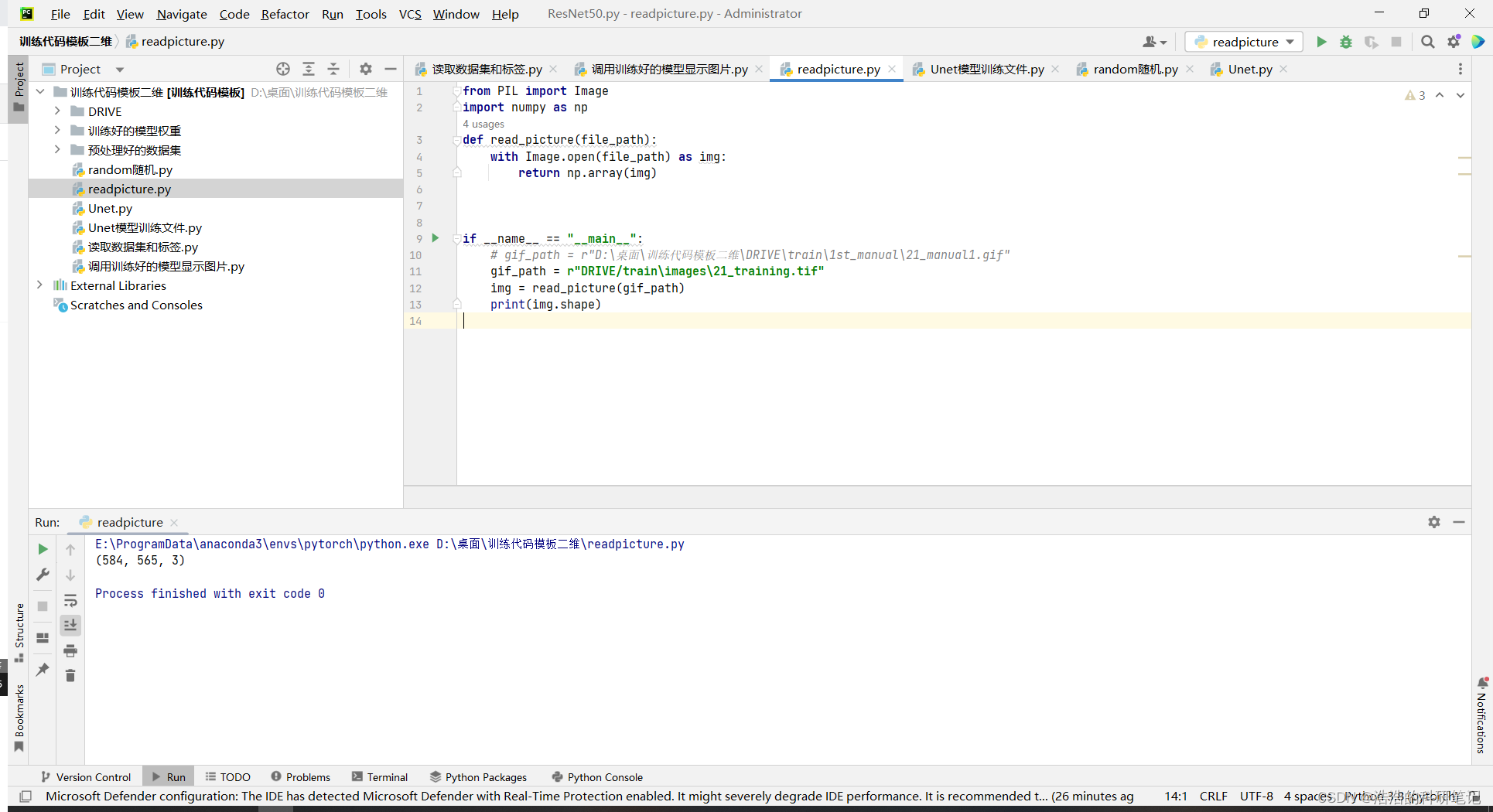
因为数据集里的标签和图片的格式是gif和tif所以不能用opencv直接读取,为了读取数据读取代码如下,文件命名为readpicture
from PIL import Image
import numpy as np
def read_picture(file_path):
with Image.open(file_path) as img:
return np.array(img)
if __name__ == "__main__":
gif_path = r"DRIVE/train\images\21_training.tif" #改成自己的路径
img = read_picture(gif_path)
print(img.shape)
数据集构建代码
该代码需要在3.9以上的python环境下运行要不然会报错
import numpy as np
import os
from readpicture import read_picture
import cv2
for name in ['train','test']:
picture_path = rf"DRIVE\{name}\images"
label_path = fr"DRIVE\{name}\1st_manual"
picturenames=os.listdir(picture_path)
labelnames=os.listdir(label_path)
data = []
label = []
for d,l in zip(picturenames,labelnames):
dp = os.path.join(picture_path,d)
lp = os.path.join(label_path,l)
p = cv2.resize(read_picture(dp),(512,512)).transpose(2,0,1)
l = cv2.resize(read_picture(lp),(512,512)).reshape(1,512,512)
p = (p - np.min(p)) / (np.max(p)-np.min(p))
l = (l - np.min(l)) / (np.max(l)-np.min(l))
data.append(p)
label.append(l)
dataset = np.array([i for i in zip(data,label)])
# 改成自己的路径
np.save(f"预处理好的数据集/{name}dataset",dataset)
运行好了之后会生成两个文件一个训练集一个测试集

模型训练
之后导入数据集和模型进行训练
首先分部分介绍代码然后给完整代码
- 首先导入必要的库
import numpy as np
import torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, Dataset
from Unet import UNet
import copy
- 加载训练集和测试集
路径改成自己的
traindata = np.load("预处理好的数据集/traindataset.npy", allow_pickle=True)
testdata = np.load("预处理好的数据集/testdataset.npy", allow_pickle=True)
- 自定义数据集类
class Dataset(Dataset):
def __init__(self, data):
self.len = len(data)
self.x_data = torch.from_numpy(np.array(list(map(lambda x: x[0], data)), dtype=np.float32))
self.y_data = torch.from_numpy(np.array(list(map(lambda x: x[1], data)))).float()
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
- 创建数据集加载器
Train_dataset = Dataset(traindata)
Test_dataset = Dataset(testdata)
dataloader = DataLoader(Train_dataset, shuffle=True)
testloader = DataLoader(Test_dataset, shuffle=True)
- 初始化模型和设备选择
#设备是选择GPU还是CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#初始化模型输入通道数为3输出通道数为1
model = UNet(3,1)
#将模型迁移到GPU上
model.to(device)
- 定义训练函数和测试函数
#定义训练集损失列表最后画图用
train_loss = []
#定义训测试集损失列表最后画图用
test_loss = []
# 训练函数
def train():
mloss = []
for data in dataloader:
datavalue, datalabel = data
datavalue, datalabel = datavalue.to(device), datalabel.to(device)
datalabel_pred = model(datavalue)
loss = criterion(datalabel_pred, datalabel)
optimizer.zero_grad()
loss.backward()
optimizer.step()
mloss.append(loss.item())
epoch_train_loss = torch.mean(torch.Tensor(mloss)).item()
train_loss.append(epoch_train_loss)
print("*"*10,epoch,"*"*10)
print('训练集损失:', epoch_train_loss)
test()
# 测试函数
def test():
mloss = []
with torch.no_grad():
for testdata in testloader:
testdatavalue, testdatalabel = testdata
testdatavalue, testdatalabel = testdatavalue.to(device), testdatalabel.to(device)
testdatalabel_pred = model(testdatavalue)
loss = criterion(testdatalabel_pred, testdatalabel)
mloss.append(loss.item())
epoch_test_loss = torch.mean(torch.Tensor(mloss)).item()
test_loss.append(epoch_test_loss)
print('测试集损失',epoch_test_loss)
- 训练过程
bestmodel = None
bestepoch = None
bestloss = np.inf
for epoch in range(1, 101):
train()
if test_loss[epoch-1] < bestloss:
bestloss = test_loss[epoch-1]
bestepoch = epoch
bestmodel = copy.deepcopy(model)
- 保存模型和绘制训练曲线
路径改成自己的
torch.save(model, "训练好的模型权重/lastmodel.pt")
torch.save(bestmodel, "训练好的模型权重/bestmodel.pt")
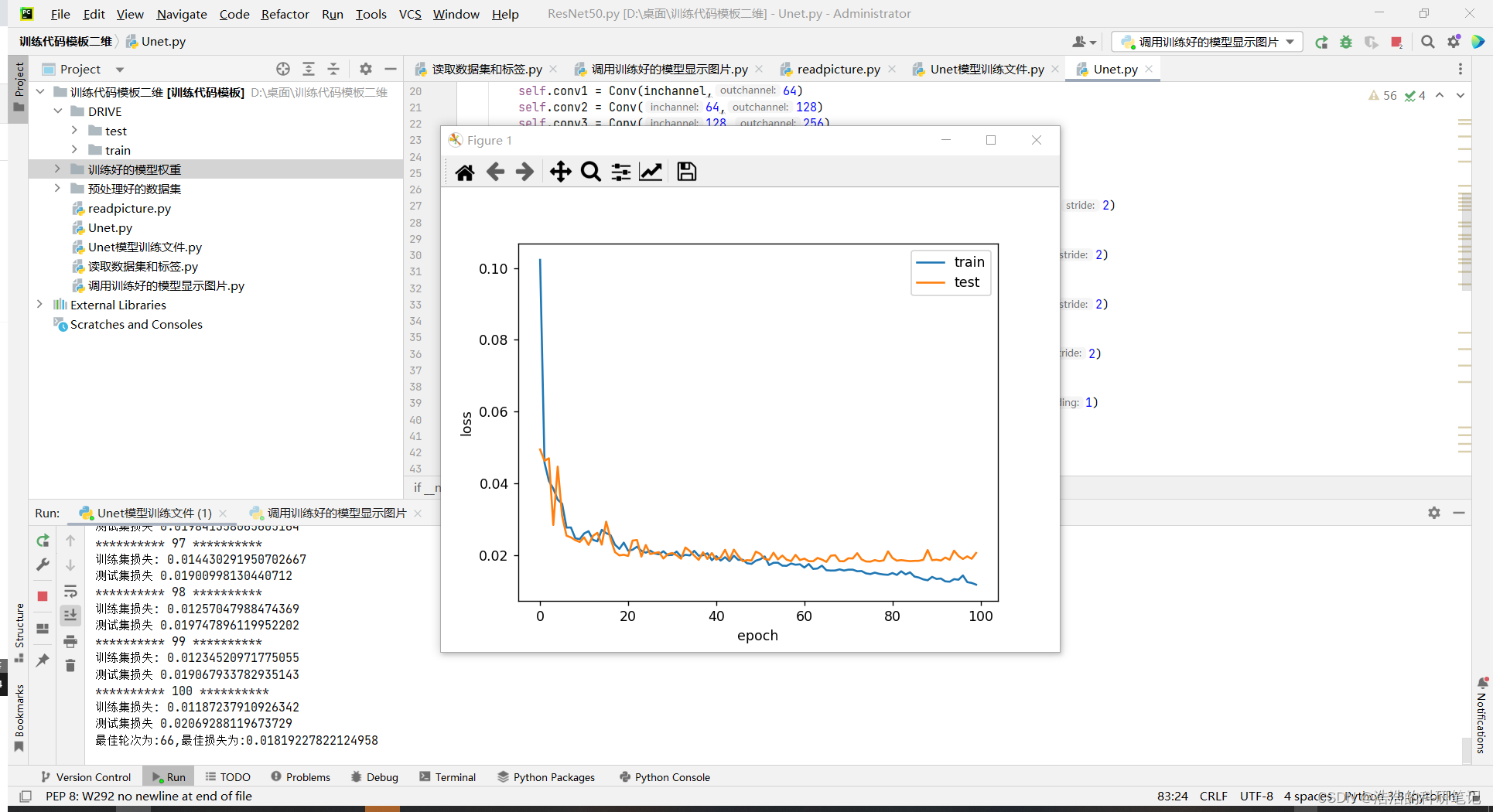
plt.plot(train_loss)
plt.plot(test_loss)
plt.legend(['train', 'test'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
运行结果如下
训练完整代码
import numpy as np
import torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, Dataset
from Unet import UNet
import copy
traindata = np.load("预处理好的数据集/traindataset.npy", allow_pickle=True)
testdata = np.load("预处理好的数据集/testdataset.npy", allow_pickle=True)
# 数据库加载
class Dataset(Dataset):
def __init__(self, data):
self.len = len(data)
self.x_data = torch.from_numpy(np.array(list(map(lambda x: x[0], data)), dtype=np.float32))
self.y_data = torch.from_numpy(np.array(list(map(lambda x: x[1], data)))).float()
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# 数据库dataloader
Train_dataset = Dataset(traindata)
Test_dataset = Dataset(testdata)
dataloader = DataLoader(Train_dataset, shuffle=True)
testloader = DataLoader(Test_dataset, shuffle=True)
# 训练设备选择GPU还是CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 模型初始化
model = UNet(3,1)
model.to(device)
# 损失函数选择
# criterion = torch.nn.BCELoss()
criterion = torch.nn.MSELoss()
# criterion = torch.nn.CrossEntropyLoss()
criterion.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01,momentum=0.9)
train_loss = []
test_loss = []
# 训练函数
def train():
mloss = []
for data in dataloader:
datavalue, datalabel = data
datavalue, datalabel = datavalue.to(device), datalabel.to(device)
datalabel_pred = model(datavalue)
loss = criterion(datalabel_pred, datalabel)
optimizer.zero_grad()
loss.backward()
optimizer.step()
mloss.append(loss.item())
epoch_train_loss = torch.mean(torch.Tensor(mloss)).item()
train_loss.append(epoch_train_loss)
print("*"*10,epoch,"*"*10)
print('训练集损失:', epoch_train_loss)
test()
# 测试函数
def test():
mloss = []
with torch.no_grad():
for testdata in testloader:
testdatavalue, testdatalabel = testdata
testdatavalue, testdatalabel = testdatavalue.to(device), testdatalabel.to(device)
testdatalabel_pred = model(testdatavalue)
loss = criterion(testdatalabel_pred, testdatalabel)
mloss.append(loss.item())
epoch_test_loss = torch.mean(torch.Tensor(mloss)).item()
test_loss.append(epoch_test_loss)
print('测试集损失',epoch_test_loss)
bestmodel = None
bestepoch = None
bestloss = np.inf
for epoch in range(1, 101):
train()
if test_loss[epoch-1] < bestloss:
bestloss = test_loss[epoch-1]
bestepoch = epoch
bestmodel = copy.deepcopy(model)
print("最佳轮次为:{},最佳损失为:{}".format(bestepoch, bestloss))
torch.save(model, "训练好的模型权重/lastmodel.pt")
torch.save(bestmodel, "训练好的模型权重/bestmodel.pt")
plt.plot(train_loss)
plt.plot(test_loss)
plt.legend(['train','test'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
使用训练好的模型进行预测
import torch
import numpy as np
import cv2
dataset = np.load('预处理好的数据集/testdataset.npy', allow_pickle=True)
data = dataset[0][0]
label = dataset[0][1]
model = torch.load('训练好的模型权重/bestmodel.pt').cpu()
# model = torch.load('训练好的模型权重/lastmosel.pt').cpu()
output = model(torch.Tensor(data.reshape(1,3,data.shape[-2],data.shape[-1]))).detach().numpy()
cv2.imshow('label',label[0])
cv2.imshow('output',output[0][0])
cv2.waitKey()
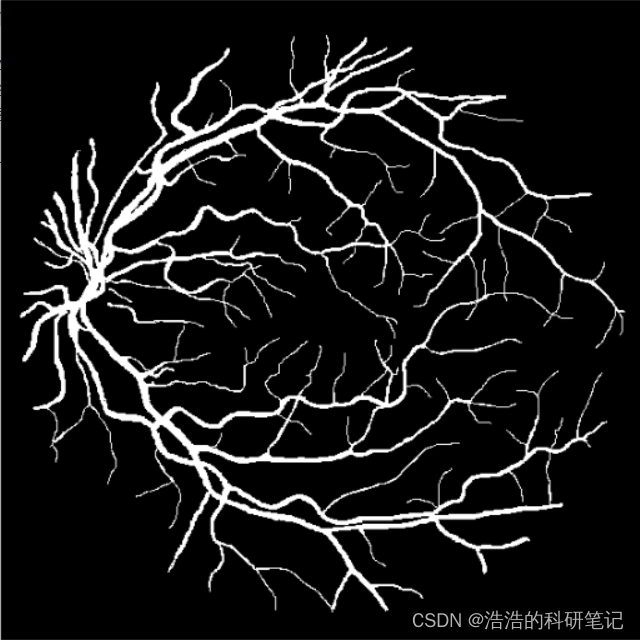
运行结果如下,左侧标签,右侧预测结果
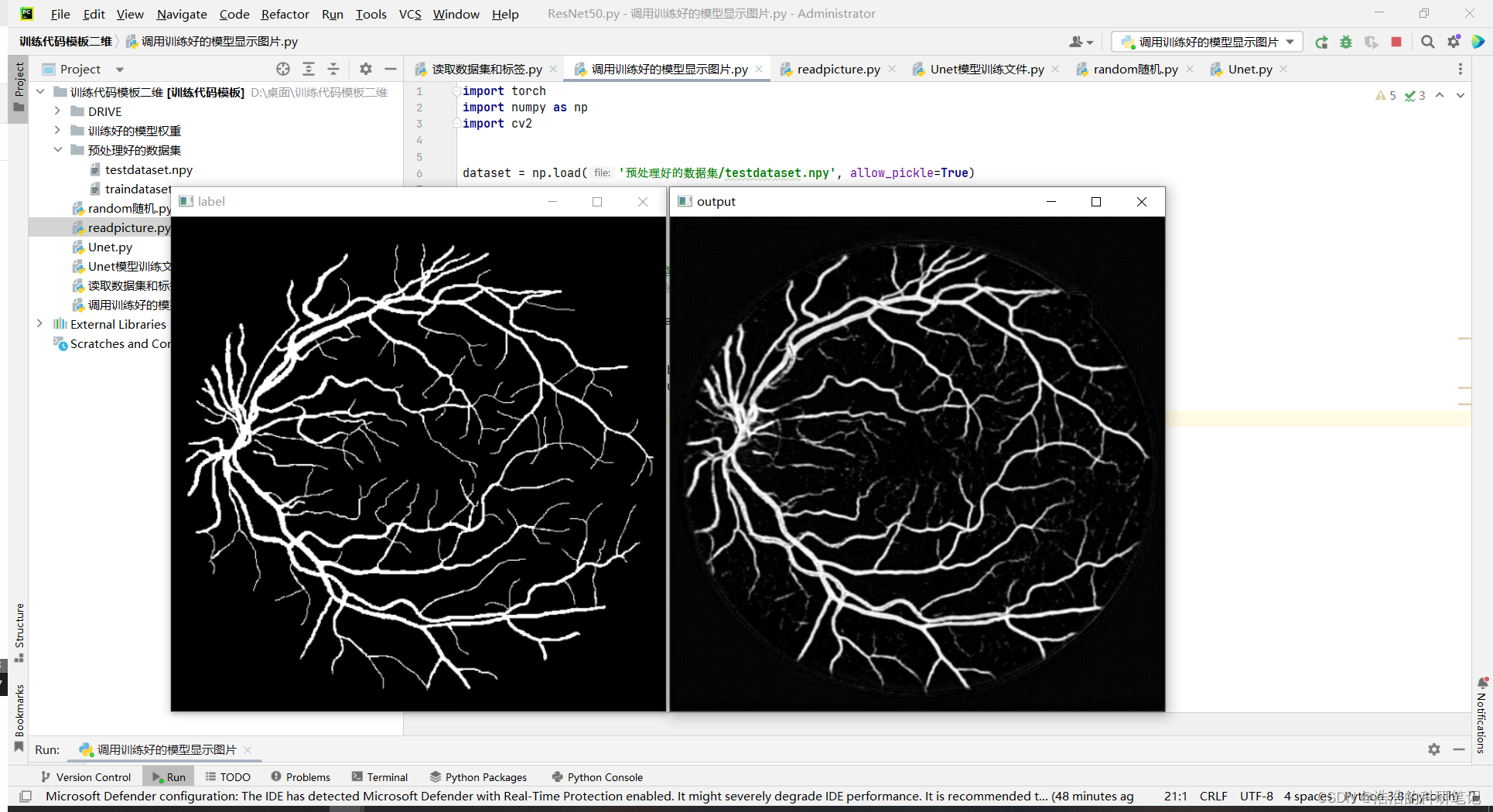
真实标签
预测结果
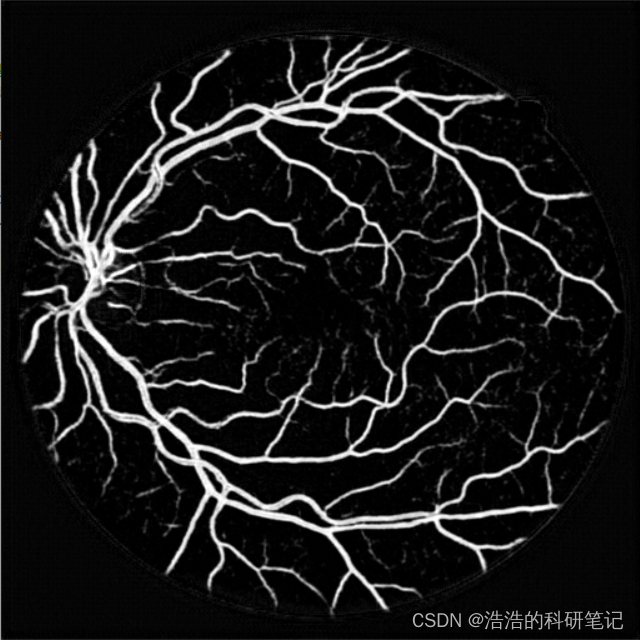
可以看到细节方面还是有些模糊的但是效果已经不错了
结束
总结在实验的过程中我发现这个Unet还是有一些玄学的东西下面就是我都一些经验总结
- 数据必须进行归一化如果不进行归一化训练起来就会梯度爆炸
- 图片大小必须为大于等于32的16的倍数,不然会报维度错误
- 在pytorch的默认损失函数必须用MSE,用其他函数不是不收敛,就是重影或者灰蒙蒙一片
- 训练的时候其实不管训练大小为多少样本比如你训练样本是224×224的其实他最后也能分割512*512的数据
如果你懒了不想找资料和复制的话,完整项目代码(包括数据集)请在公众号浩浩的科研笔记里购买