写在最前面的话
哈喽,宝子们,今天给大家带来的是MySql数据库的聚合查询。在前面CRUD章节我们学习了表达式查询,表达式查询是针对列和列之间进行运算的,那么如果想在行和行之间进行运算,那么就需要用到聚合查询。聚合查询除了包含聚合函数外(count,sum,avg,max,min),还包含group by 和 having 语句。接下来让我们一起进入学习吧,感谢大家的支持!喜欢的话可以三连哦~~~

目录
一、聚合函数
1、COUNT([DISTINCT]expr)
2、SUM([DISTINCT]expr)
3、AVG([DISTINCT]expr)
4、MAX([DISTINCT]expr)
5、MIN([DISTINCT]expr)
二、GROUP BY子句
三、HAVING子句
一、聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
| COUNT([DISTINCT]expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT]expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT]expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT]expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT]expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
插入测试表
为了大家更好的学习聚合函数,我们在学习前先创建一张测试表并插入数据,下面的学习案例都通过这张表举例子:
--创建考试成绩表
CREATE TABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
-- 插入测试数据
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);1、COUNT([DISTINCT]expr)
把数据表中的数据数量进行汇总,返回汇总的结果。
语法:
select count(表达式) from 表名;--表达式可为*或列名学习案例
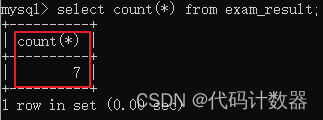
*:
select count(*) from exam_result;--使用*执行上述SQL语句后,运行结果如下图所示:
列名:
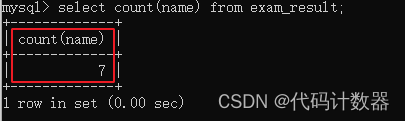
select count(name) from exam_result;--使用列名执行上述SQL语句后,运行结果如下图所示:
拓展知识:大家会发现使用列名与使用*号达到的效果是一样的,但其实如果当前列为NULL,使用列名就不会计算进去,而使用*号就会。
当插入一条name为NULL的数据,再次运行结果如下图所示:

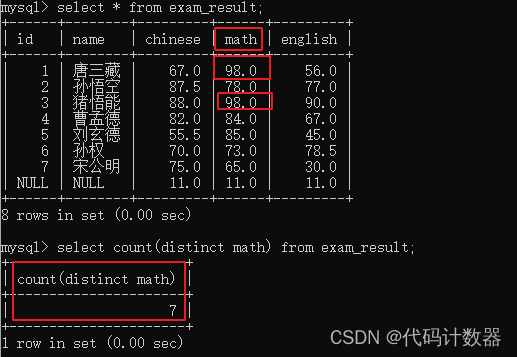
distinct:
select count(distinct name) from exam_result;--使用distinct去重执行上述SQL语句后,运行结果如下图所示:
2、SUM([DISTINCT]expr)
把这一列的若干行进行求和(算术运算),只能针对数字类型使用。
语法:
select sum(表达式) from 表名;--表达式为列名学习案例
---计算所有同学的语文成绩
select sum(chinese) from exam_result;--如果数据中有null会被排除掉---计算所有科目的总成绩
select sum(chinese+math+english) from exam_result;--如果数据中有null会被排除掉
3、AVG([DISTINCT]expr)
把这一列的若干行进行平均值运算(算术运算),只能针对数字类型使用。
语法:
select avg(表达式) from 表名;--表达式为列名学习案例
---计算数学成绩的平均值
select avg(math) from exam_result;---计算所有科目总成绩的平均值
select avg(chinese+math+english) from exam_result;
4、MAX([DISTINCT]expr)
把这一列的若干行进行求最大值(算术运算),只能针对数字类型使用。
语法:
select max(表达式) from 表名;--表达式为列名学习案例
---计算英语成绩的最大值
select max(exglish) from exam_result;---计算所有科目总成绩的最大值
select max(chinese+math+english) from exam_result;
5、MIN([DISTINCT]expr)
把这一列的若干行进行求最小值(算术运算),只能针对数字类型使用。
语法:
select min(表达式) from 表名;--表达式为列名学习案例
---计算数学成绩的最小值
select min(math) from exam_result;---计算所有科目总成绩的最小值
select min(chinese+math+english) from exam_result;
二、GROUP BY子句
插入测试表
为了大家更好的学习group by,我们在学习前先创建一张测试表并插入数据,下面的学习案例都通过这张表举例子:
---创建员工表
create table emp(
id int primary key auto_increment,
name varchar(20),
role varchar(20),
salary int);
---插入数据
insert into emp values(null,'张三','程序员',1688);
insert into emp values(null,'李四','程序员',1888);
insert into emp values(null,'王五','程序员',1988);
insert into emp values(null,'赵六','产品经理',168);
insert into emp values(null,'田七','产品经理',188);
insert into emp values(null,'周八','老板',8888);group by是针对指定的列进行分组,把这一列中值相同的行分到一组中再分别使用聚合函数。
语法:
select 列名,聚合函数 from 表名 group by 列名;学习案例
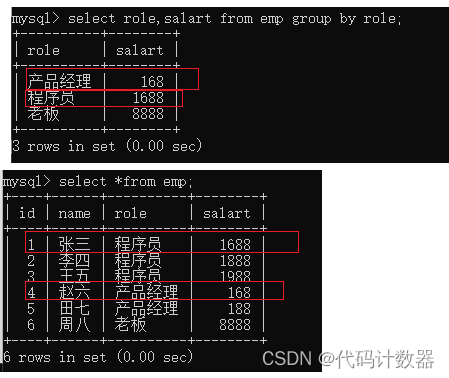
---计算不同职务的平均工资
select role,avg(salary) from emp group by role;--先分组,再算平均值执行上述SQL语句后,运行结果如下图所示:
拓展知识:如果只分组不使用聚合函数可能无法得到准确数据,会得到每组的第一条记录(如下图所示)。

三、HAVING子句
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where语句,而需要用having。
语法:
select 列名,聚合函数 from 表名 group by 列名;学习案例:
使用group by的时候还可以搭配其它条件,但是需要区分清楚该条件是在分组前的条件还是分组后的条件。
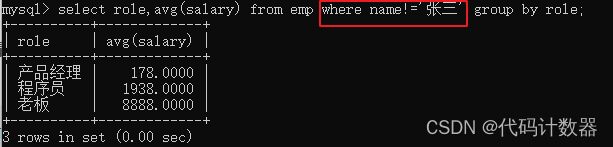
---查询每个岗位的平均工资,但是排除张三(分组之前)
select role,avg(salary) from emp where name!='张三' group by role; ---先进行where筛选,再根据role分组,最后使用avg算平均执行上述SQL语句后,运行结果如下图所示:
---查询每个岗位的平均工资,但排除平均工资超过2k的结果(分组之后)
select role,avg(salary) from emp group by role having avg(salary)<2000;执行上述SQL语句后,运行结果如下图所示:
拓展知识:在group by中可以一条sql语句完成上述两者的条件筛选。
---查询每个岗位的平均工资,但是排除张三并保留平均值<2k的结果
select role,avg(salary) from emp where name!='张三' group by role having avg(salary)<2000;执行上述SQL语句后,运行结果如下图所示:


希望各位读者阅读后都能有所收获,如果喜欢本篇博客的可以点赞+关注+收藏!!!同时也欢迎各位大神如果在阅读过程中发现文章有错误也可私信指正错误,我们下一篇博客再见~~~