目录
- 引言
- ZFNet的网络结构
- 可视化反卷积
- 反池化
- 反激活
- 反卷积
- 训练细节
- 特征可视化
- 特征演化
- 特征不变性
- 局部遮挡测试
- 敏感性分析
- 相关性分析
- 消融实验
- 宽度影响
- 深度影响
- 迁移学习能力
- 有效性分析
- 总结
引言
纽约大学ZFNet,2013年ImageNet图像分类竞赛冠军模型。对AlexNet进行改进的基础上,提出了一系列可视化卷积神经网络中间层特征的方法,并巧妙设置了对照消融实验,从各个角度分析卷积神经网络各层提取的特征及对变换的敏感性。
论文:Visualizing and Understanding Convolutional Networks(可视化并理解卷基神经网络)
课程主页:ZFNet深度学习图像分类算法(反卷积可视化可解释性分析)
在这篇论文中,它提出了一种非常巧妙的可视化卷积神经网络中间层特征的方法和技巧,使用该技巧,可以打破卷积神经网络黑箱子。
- 知道中间每一个神经元到底是在提取什么样的特征
- 利用这些可视化的技巧和利用这些特征,可以改进之前的网络
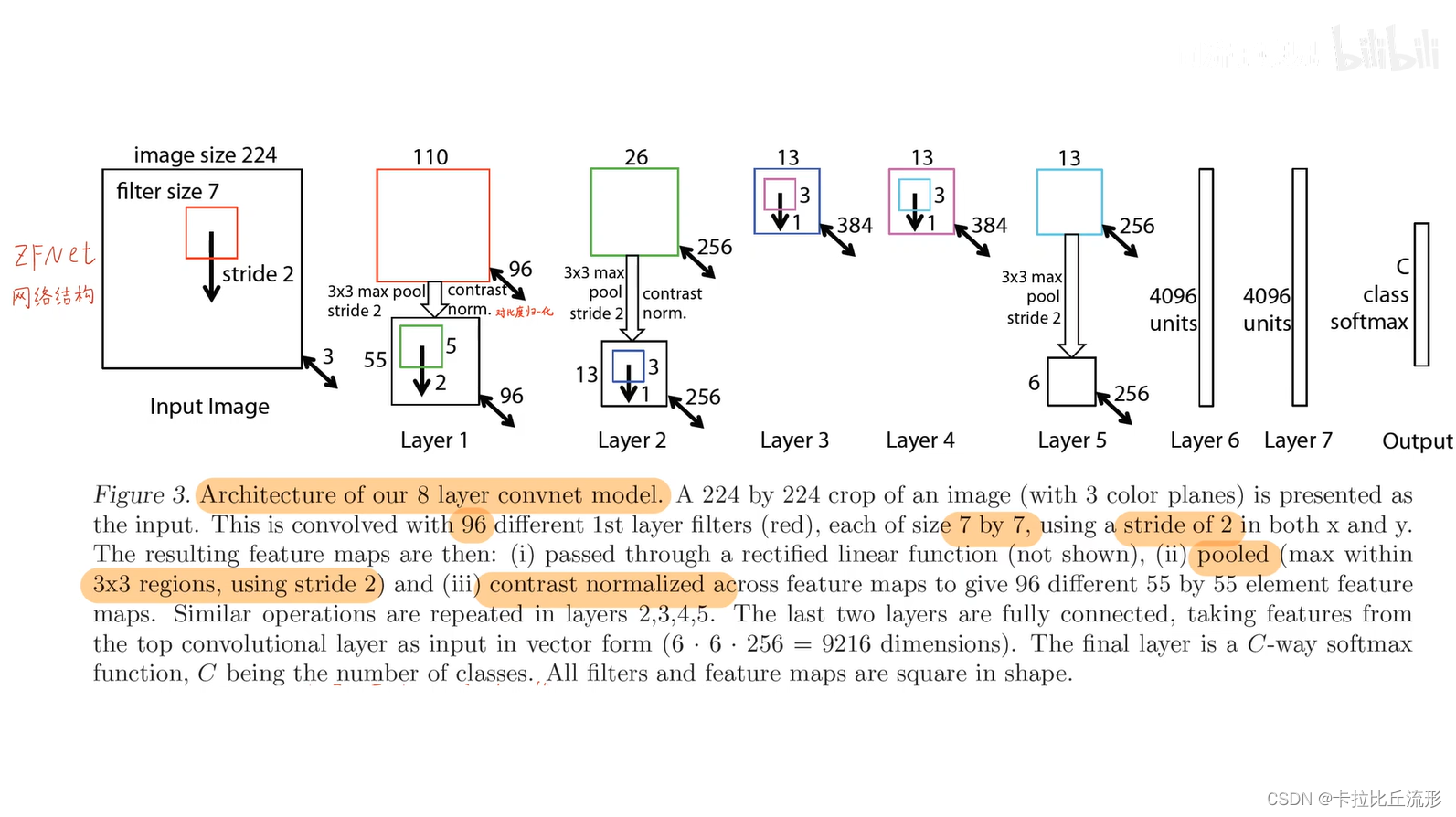
ZFNet的网络结构
在AlexNet的基础上进行了一些修改:
- 网络结构类似于 AlexNet,有两点不同,一是将 3,4,5 层的变成了全连接,二是卷积核的大小减小。
图像预处理和训练过程中的参数设置也和 AlexNet很像。
AlexNet 用了1500万张图像,ZFNet 用了 130 万张图像。 - AlexNet 在第一层中使用了大小为 11×11 的滤波器,而ZF使用的滤波器大小为 7x7,整体处理速度也有所减慢。做此修改的原因是,对于输入数据说,第一层卷积层有助于保留大量的原始象素信息。11×11 的滤波器漏掉了大量相关信息,特别是因为这是第一层卷积层。
- 随着网络增大,使用的滤波器数量增多。
- 利用 ReLU 的激活函数,将交叉熵代价函数作为误差函数,使用批处理随机梯度下降进行训练。
- 使用一台 GTX 580 GPU 训练了 12 天。
- 开发可视化技术 “解卷积网络”(Deconvolutional Network),有助于检查不同的特征激活和其对输入空间关系。名字之所以称为“deconvnet”,是因为它将特征映射到像素(与卷积层恰好相反)。
可视化反卷积
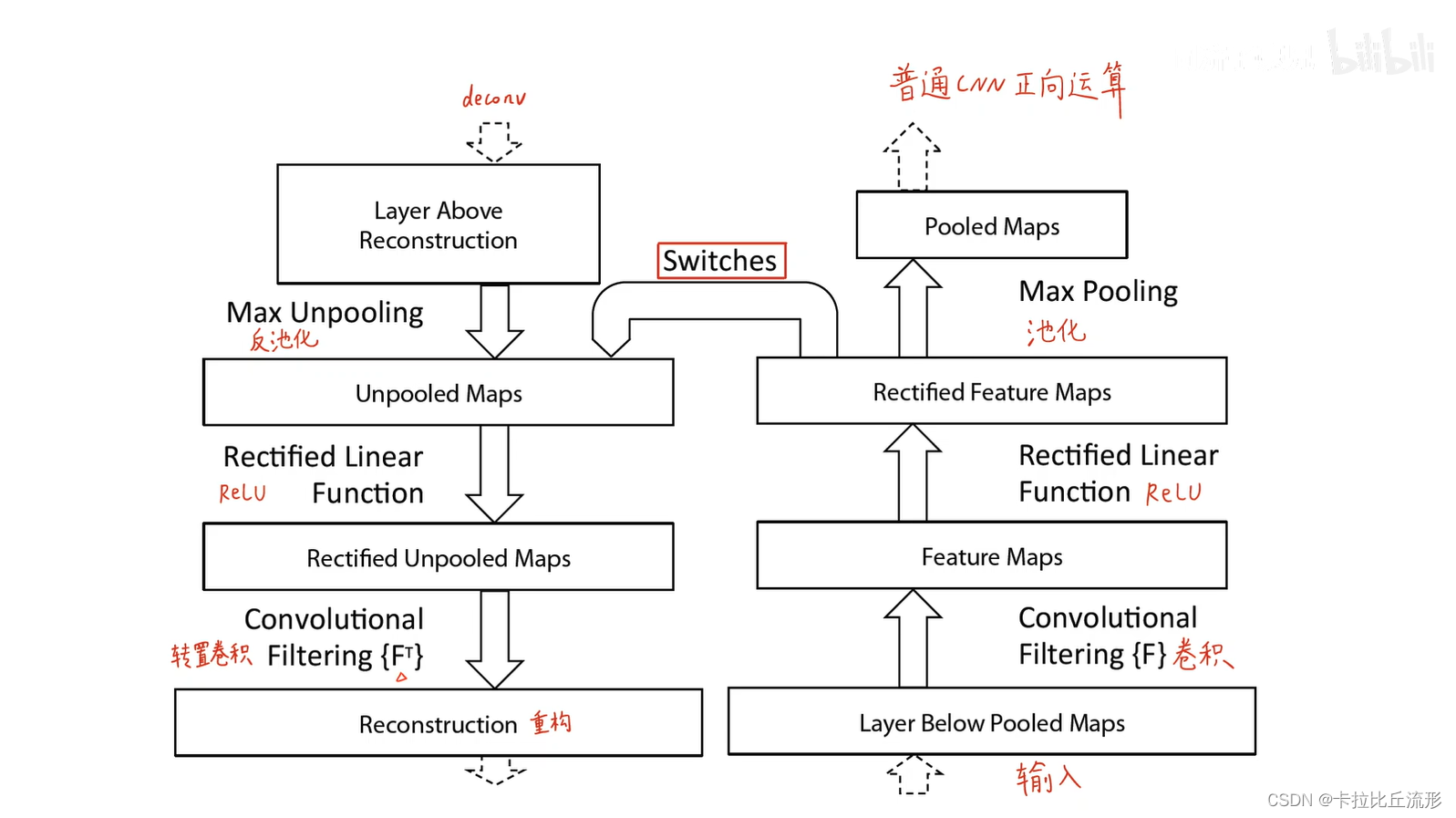
我们知道输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而又是我们需要将图像恢复到原来的尺寸以便进行进一步的计算,整个扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。
反卷积是上采样的一种方式,反卷积也叫转置卷积。
反卷积可视化:
- 一个卷积层加一个对应的反卷积层;
- 输入是 feature map,输出是图像像素;
- 过程包括反池化操作、relu 和反卷积过程。
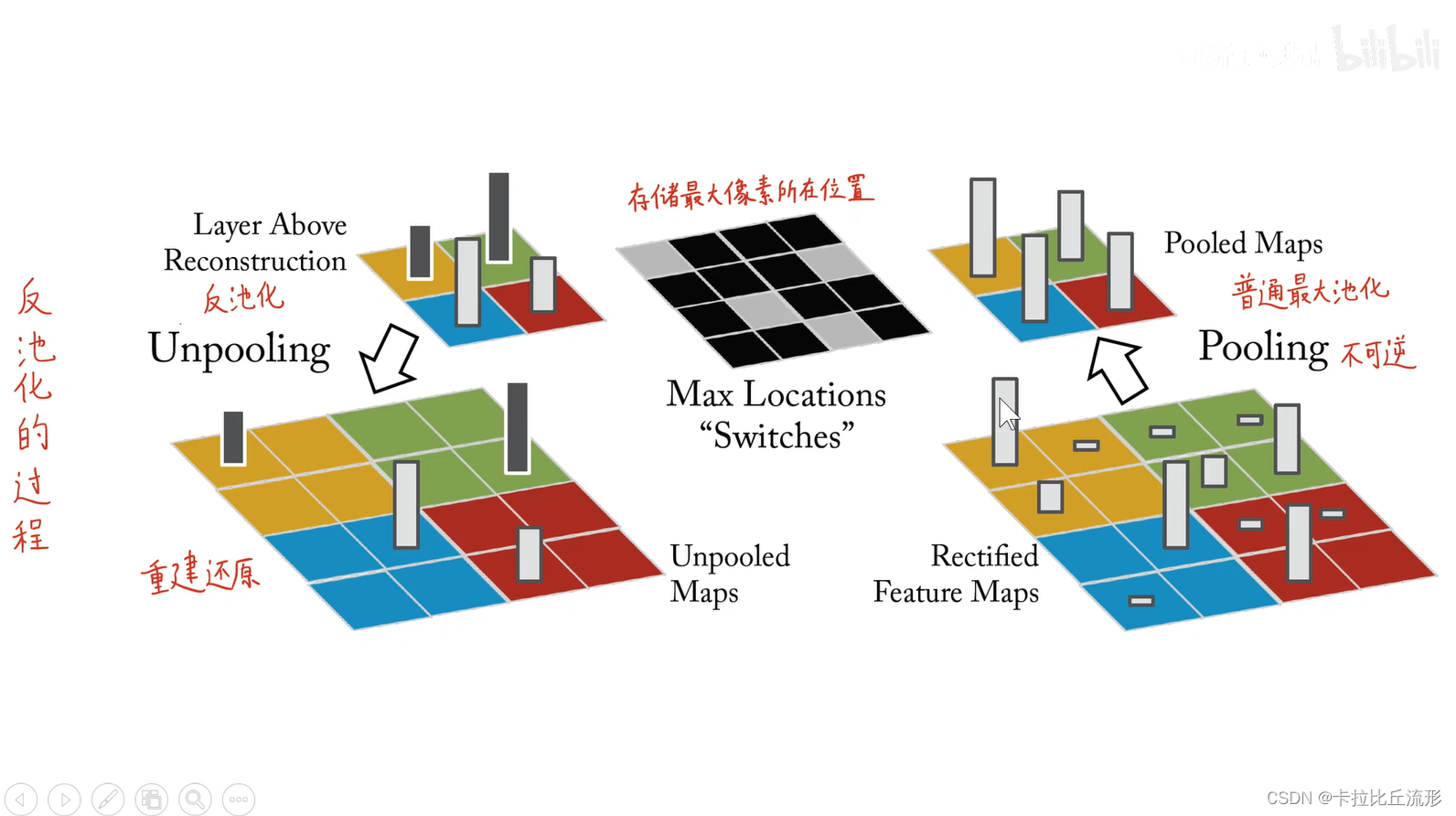
反池化
- 正向池化,以最大池化为例,是把每一个池化窗口里面最大的这个值挑出来
- 反池化的时候,就把每一个池化窗口按照对应的位置派遣回去
严格意义上的反池化是无法实现的。作者采用近似的实现,在训练过程中记录每一个池化操作的一个 z × z z×z z×z 的区域内输入的最大值的位置,这样在反池化的时候,就将最大值返回到其应该在的位置,其他位置的值补 0。
反激活
仍然使用ReLU激活函数
反卷积
使用的是原来正向卷积核的转置(也就是行列互换)
- 转置卷积没有需要学习的参数,是一个完全无监督的过程。

训练细节
特征可视化


彩色图是能够使得灰色图在卷积核中激活最大的九张图片
特征演化

第 1 层、第 2 层、第 3 层、第 4 层和第 5 层的五层的六个卷积核
- 每一行表示一个卷积核
- 每一列表示训练过程中不同的轮次:第 1 轮、第 2 轮、第5轮、第10轮、第20轮、第30轮、第40轮和第64轮收敛
- 那底层的卷积核,很快就收敛了
- 高层的卷积核,它要多轮之后才能收敛
- 突变:能够使卷积核最大激活的图片变了
- 第三组第三个:提取眼睛信息;第四个:提取脸的信息
特征不变性
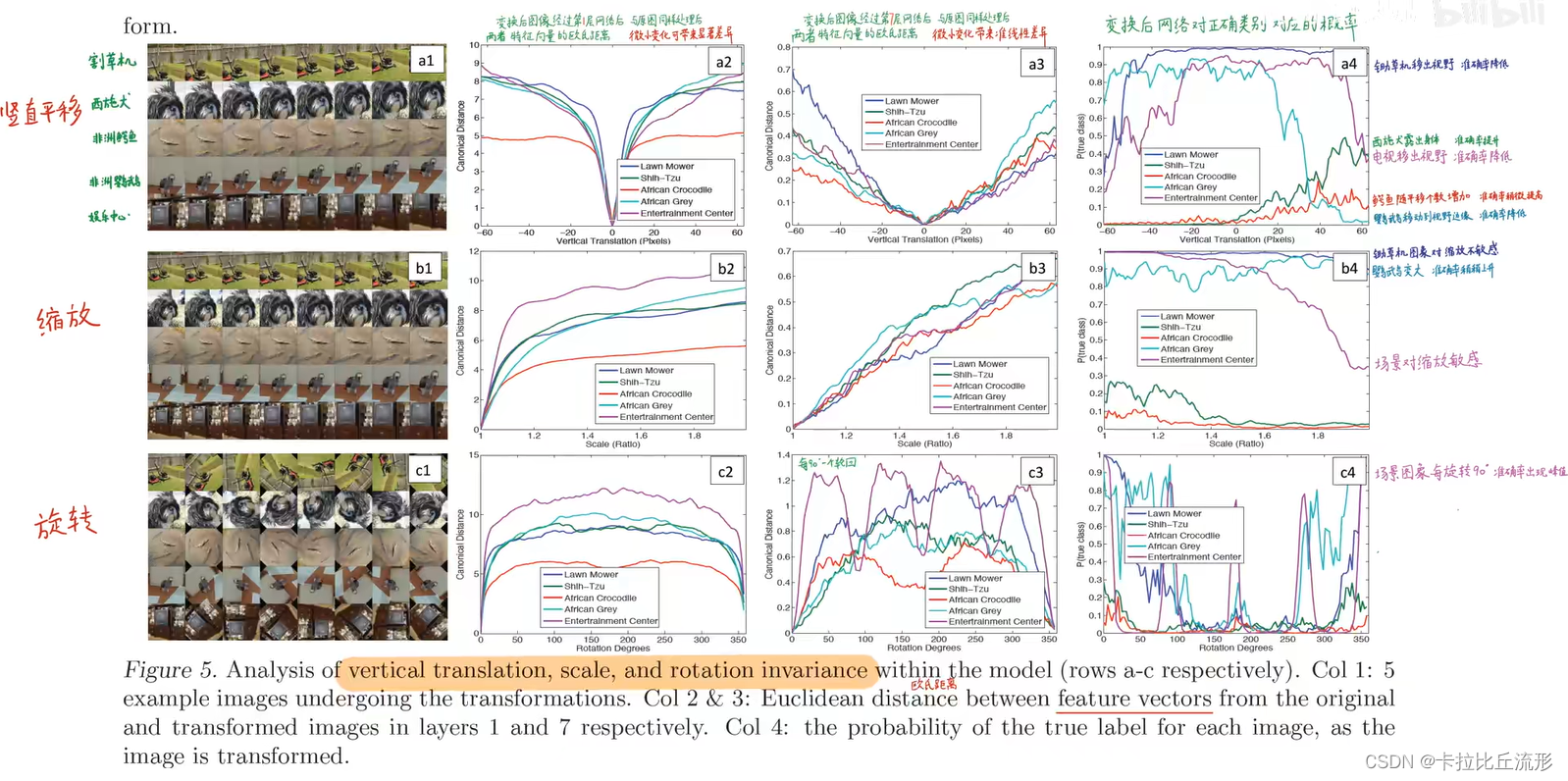
平移
深蓝紫 - 除草机:随着除草机进入和移出视野,它的概率先升高后变得很低。
深蓝色 - 吸食犬:随着吸食犬不断露出身体,它的概率也会变高
缩放
娱乐中心对缩放非常敏感
除草机和鹦鹉,在图像中始终出现,所以缩放对它们的影响是不大的。
旋转
每旋转90度,就有一个尖峰,准确率就会出现一个峰值,说明它每旋转90度就出现了一个对称性,网络能捕获同样的特征

局部遮挡测试
敏感性分析
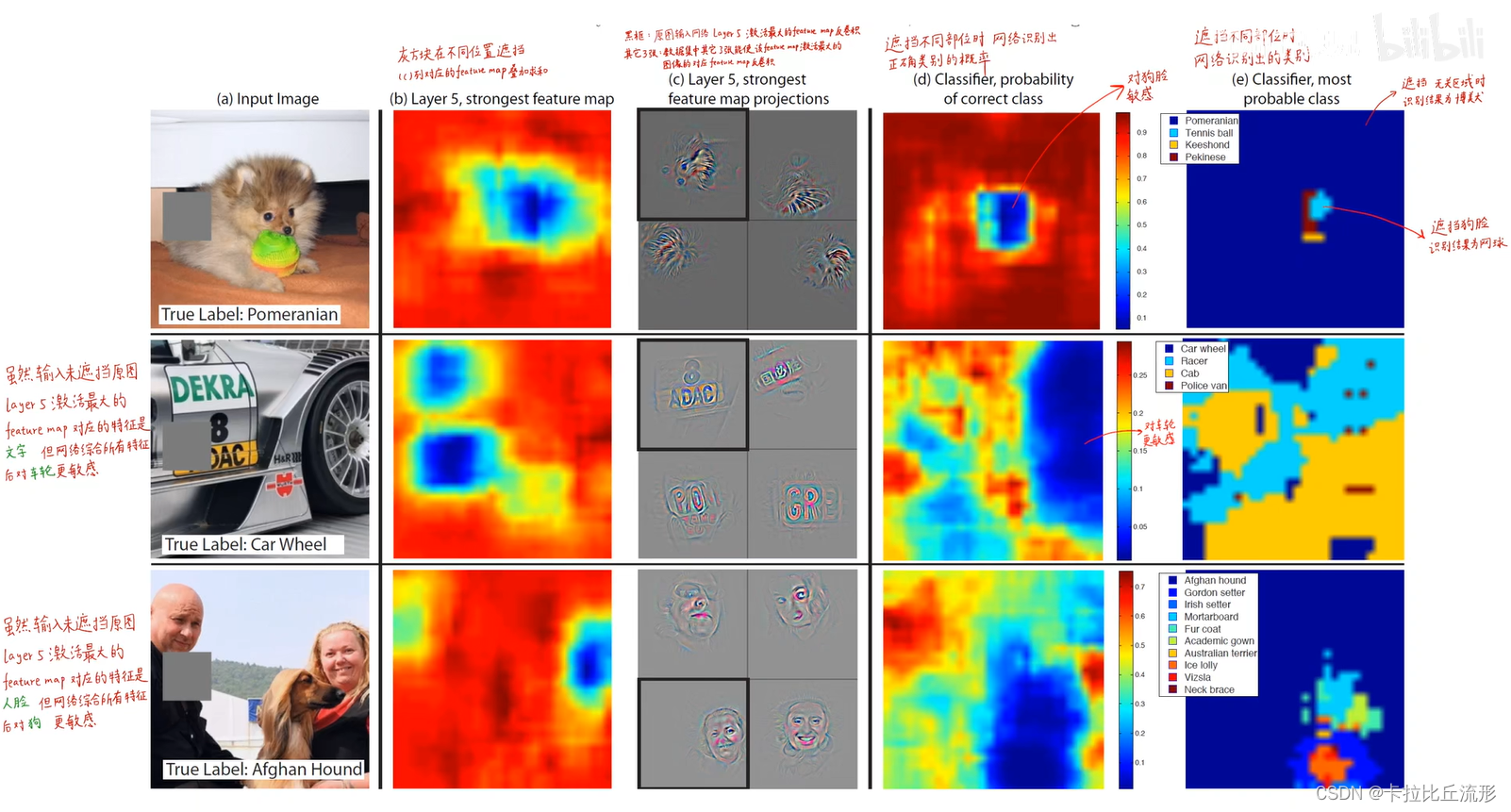
通过一系列特别巧妙的对照实验表明了这个神经网络对遮挡的敏感性
相关性分析

- 不同狗的图片,遮住相同部位,探究遮挡对不同类别的影响。表格说明了遮挡相同部位对不同狗的影响是接近的。
- 随机遮挡对第 5 层影响较大,第 7 层影响较小,网络越到深层,他提越提取的是语义特征
消融实验
宽度影响

测试:2012年的图像分类数据
- a模型是原始ZFNet模型
- b模型在a基础上,把3、4、5层卷积核增加到512、1024和512
- 将6个模型集成在一起,效果不错,超过AlexNet,模型错误率是亚军的一半
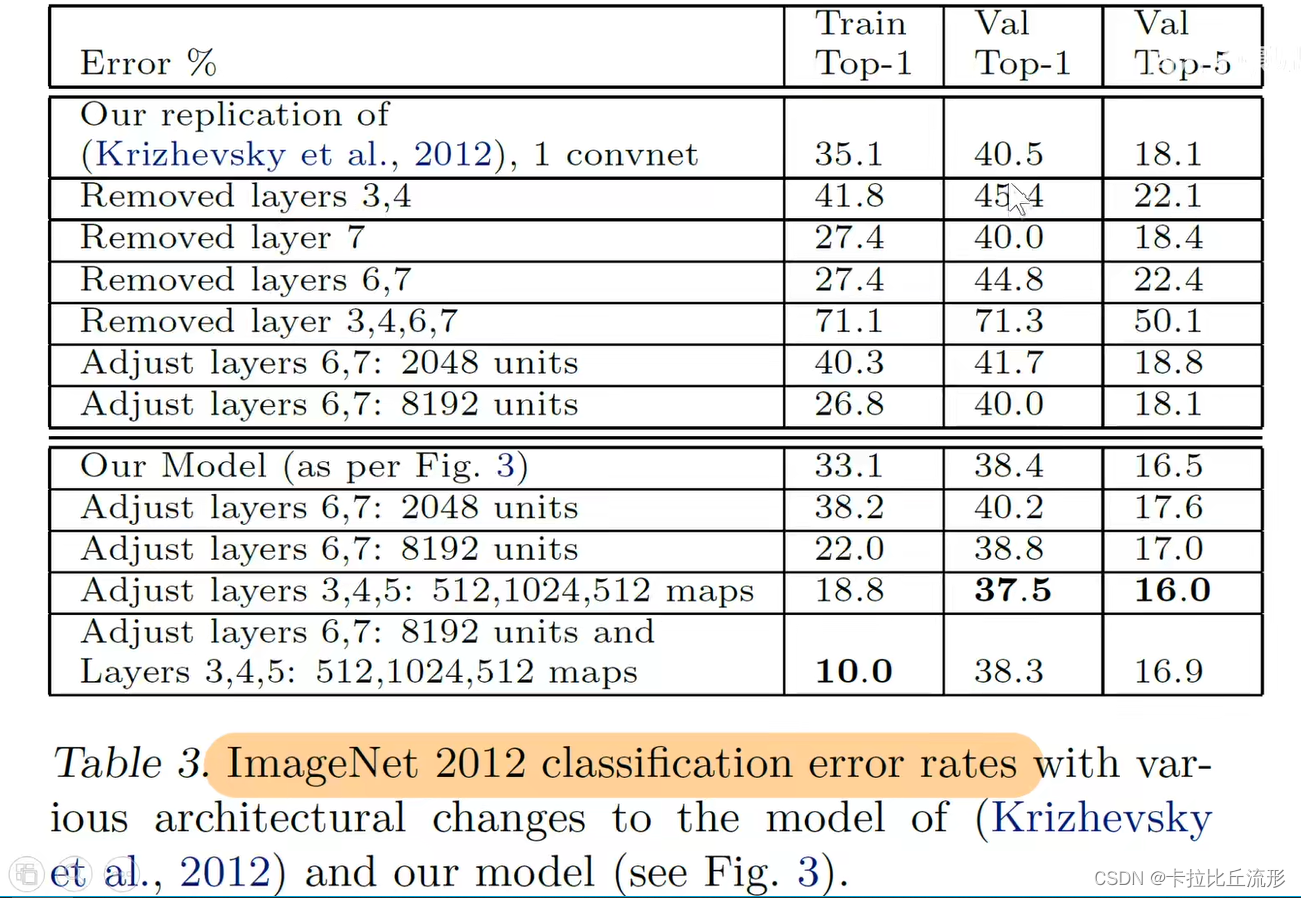
深度影响
去除某些层
- 去除这个两个卷积层,影响不是特别大
- 去掉全连接层,影响也不是特别大
- 既去掉卷积层又去掉全连接层,影响非常大
结论:网络的深度非常重要
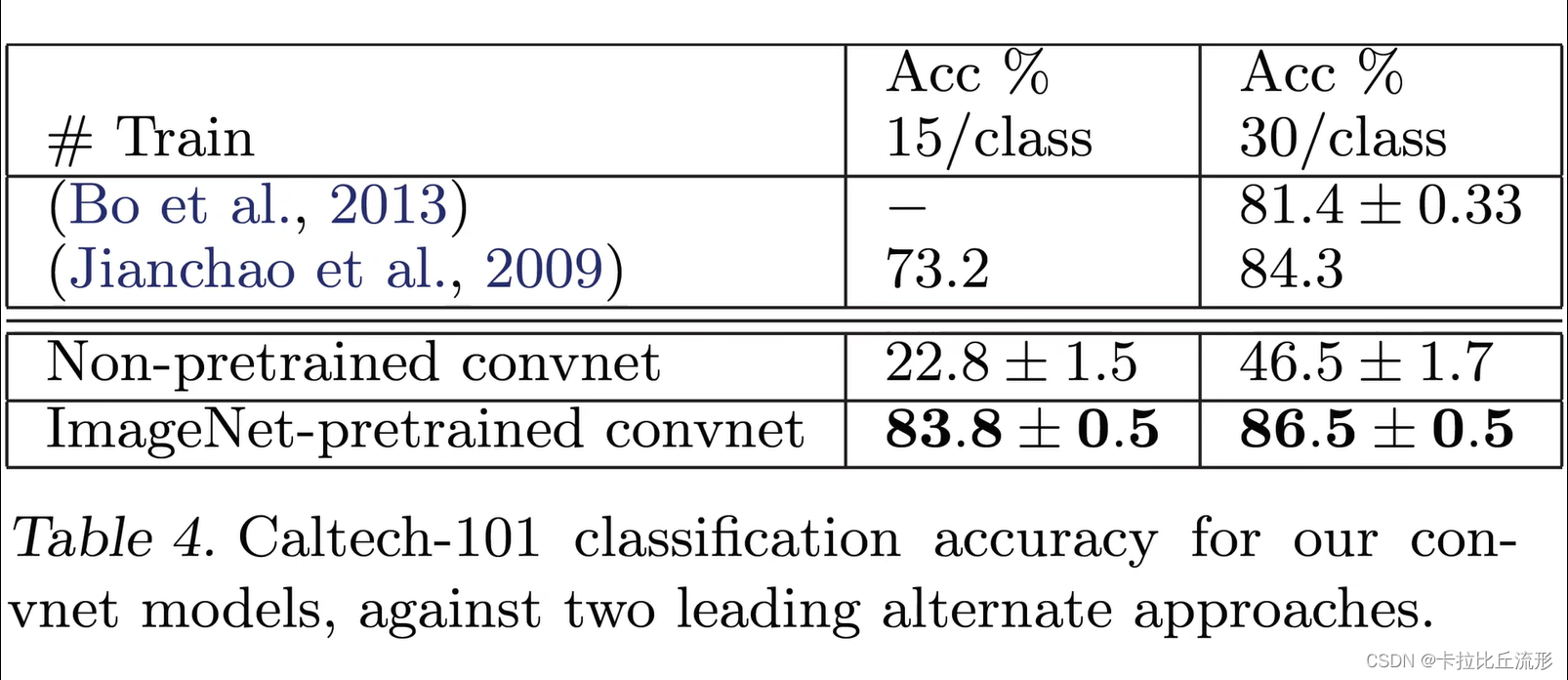
迁移学习能力
对于Caltech-101数据集:
- 保留这个模型之前的部分,只改动这个最后的softmax分类层。然后在Caltech-101上重新训练我们新加的softmax分类层。效果是非常不错的,是比原有的模型效果要好很多的
- 只保留网络的结构。不要原来的参数完全随机初始化,然后再开后,他给101数据上重新训练这个网络,我们会发现效果是不太好的
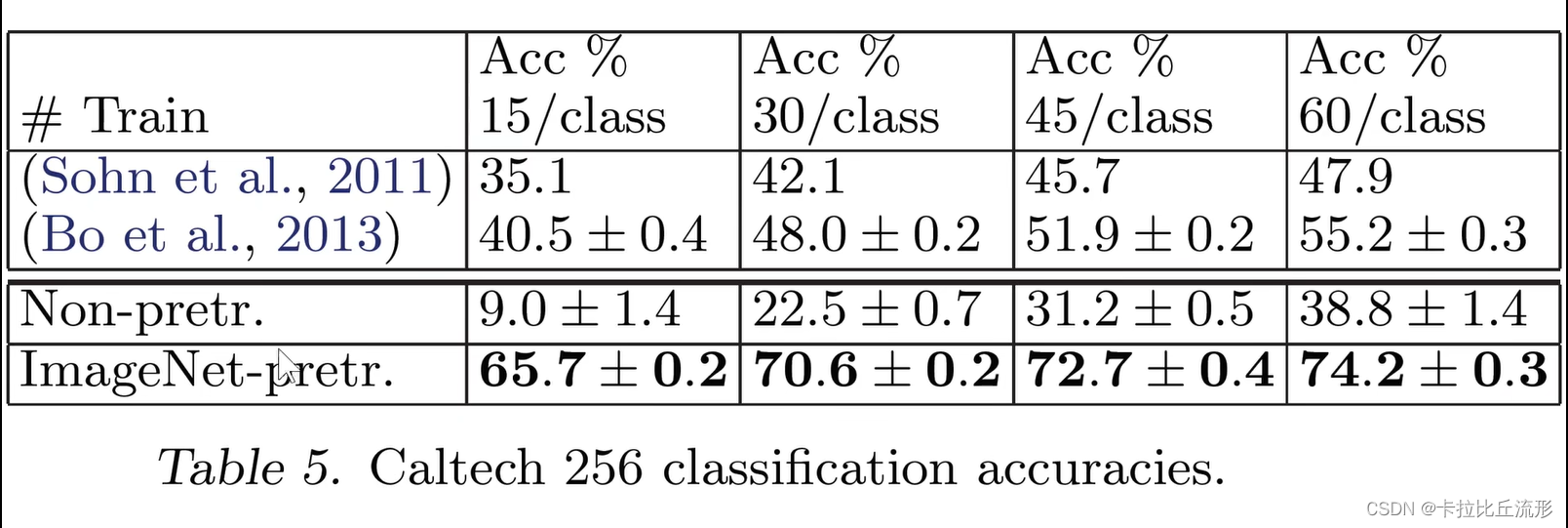
对于Caltech-256数据集:
类似
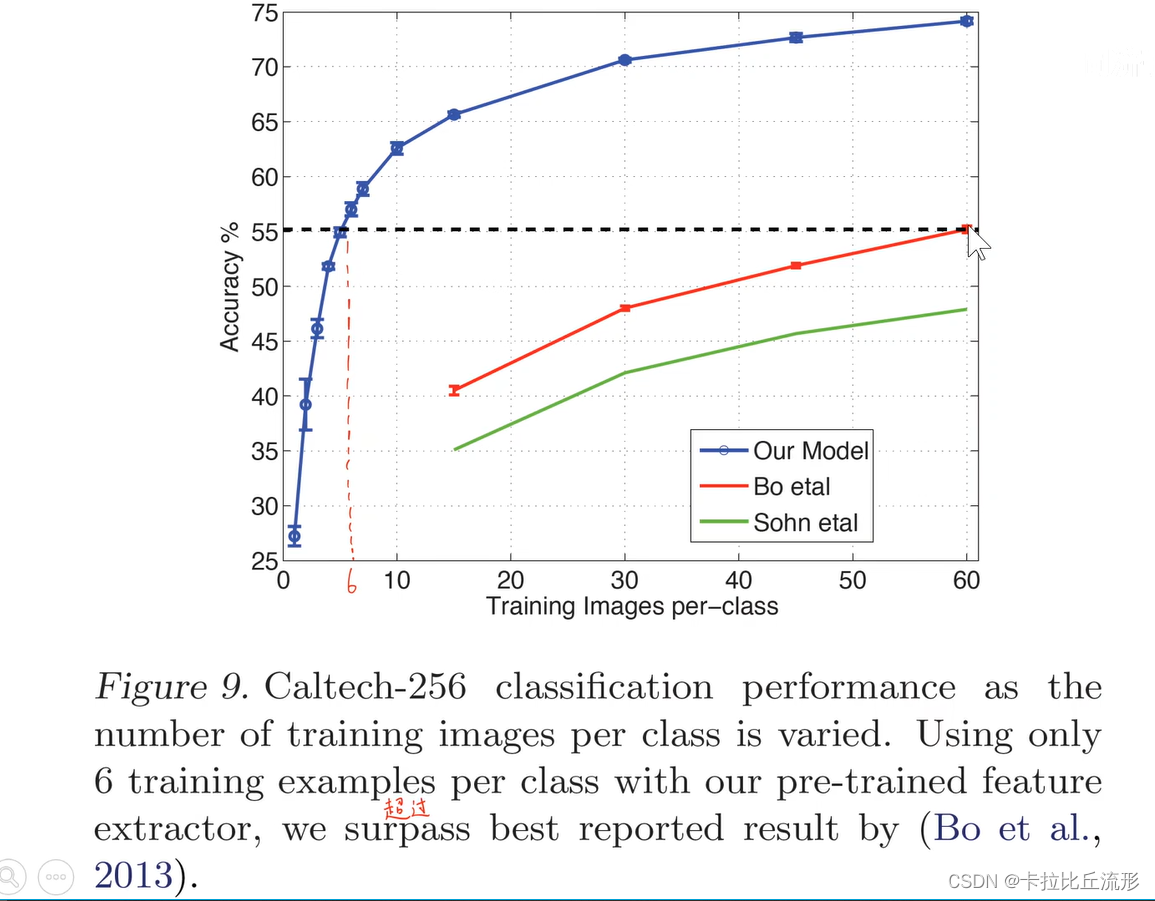
在Caltech-256,只需要每一个类别只用六张图片训练。训练好处的模型就能够达到原来最佳的这个数据上模型的精度。
使用迁移学习,我们可以使用很少量的数据就可以达到非常好的性能。

对于和ImageNet差别比较大的数据集,效果会差些。
有效性分析

模型越深越有分类有效性。
总结
本次学习了ZFNet,它是在AlexNet之后新的改进,它主要提出了一种反卷积的思想,使用一个多层的反卷积网络来可视化训练过程中特征的演化及发现潜在的问题。
- 发现学习到的特征远不是无法解释的,而是特征间存在层次性,层数越深,特征不变性越强,类别的判别能力越强;
- 通过可视化模型中间层,在 alexnet 基础上进一步提升了分类效果;
- 遮挡实验表明分类时模型和局部块的特征高度相关;
- 预训练模型可以在其他数据集上fine-tuning得到很好的结果。
- 模型越深越有分类有效性




![[leetcode.4]寻找两个正序数组的中位数 多思考边界](https://img-blog.csdnimg.cn/94684add626840faa7f3c46171f29689.png)
![[附源码]Nodejs计算机毕业设计基于与协同过滤算法的竞赛项目管理Express(程序+LW)](https://img-blog.csdnimg.cn/ff6fa8fe6cb34ea2a44400ef165d5bd0.png)