本文来自公众号“AI大道理”
ResNet、DenseNet 等复杂的多分支网络可以增强模型的表征能力,使得训练效果更好。但是多分支的结构在推理的时候效率严重不足。
看起来二则不可兼得。
能否两全其美?
RepVGG通过结构重参数化的方法,在训练的时候使用多分支结构,而在推理的时候多分支结构融合成单路结构,即保证了训练的效果,也提高了推理速度。

1、RepVGG网络结构
ResNet:一个主分支+一个恒等映射分支。
RepVGG:一个主分支+一个 1x1 conv 分支+一个恒等映射分支。
RepVGG 训练的 block 可以表示为:y=x+g(x)+f(x)
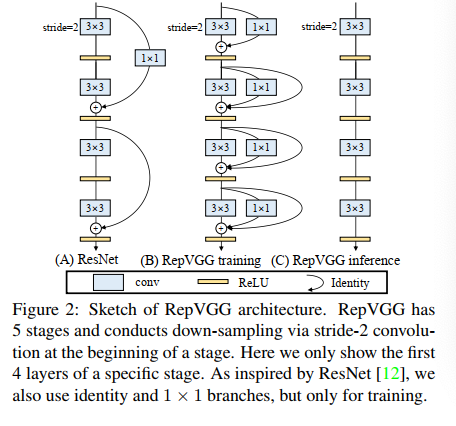
多分支训练:
移除 RepVGG-B0 的恒等映射分支/1x1 conv 分支,来看训练模型的效果:
-
两个分支都移除后,训练模型准确度跌到 72.39%
-
使用 1x1 分支升到 73.15%
-
使用恒等映射升到 74.79%
-
使用 3 个分支升到 75.14%
可见多分支网络结构对模型性能的提升是明显的,在训练阶段采用多分支网络结构是必要的。
单路推理:
更快。推理的时候恒等映射分支计算最快,1*1卷积其次,3*3卷积最慢。
因此,其他两个计算完毕要等待3*3卷积计算。而变为单路推理,明显更快。
更省内存。单路推理只占用一倍的内存,而多路要占用多倍。
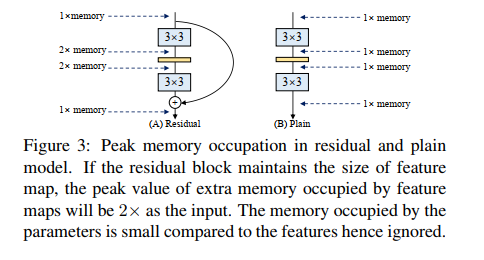
更加灵活。单路剪枝方便,而多路困难。

2、结构重参数化
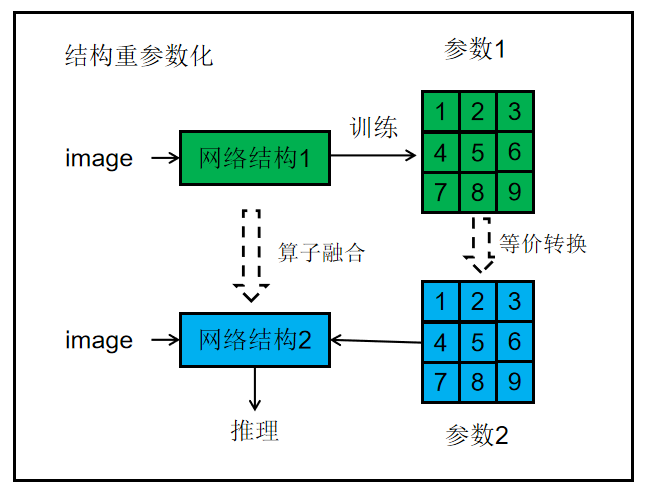
结构重参数化就是训练和推理使用不同的结构,但是用同一套参数量。
灵魂的拷问:一般是网络训练出来的参数在推理的时候直接带入同样的网络进行一次计算,从而得出一个推理结果的,怎么能用一套参数带入不同网络呢?
那么结构重参数化是如何实现的呢?
RepVGG将 3 分支网络等价转换,简化成单分支网络。
步骤1:
恒等映射分支可以被看做卷积核为1*1的单位1卷积。

经过这种变换后,就能得到:
-
1 个 3x3 kernel
-
2 个 1x1 kernel
-
3 个 bias vectors

步骤2:
先对卷积 “吸BN”(即将 conv+bn 转换成一个带 bias 的 conv)。
将1*1卷积核边缘补 0,成3*3卷积核。



步骤3:
将三个卷积以中心点为基准相加,将 3 个卷积合并为 1 个。
将 2 个 1x1 kernels 和 1 个 3x3 kernels 相加(边缘补 0),就能得到最终的 3x3 kernel。
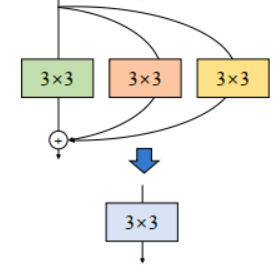
总体过程:
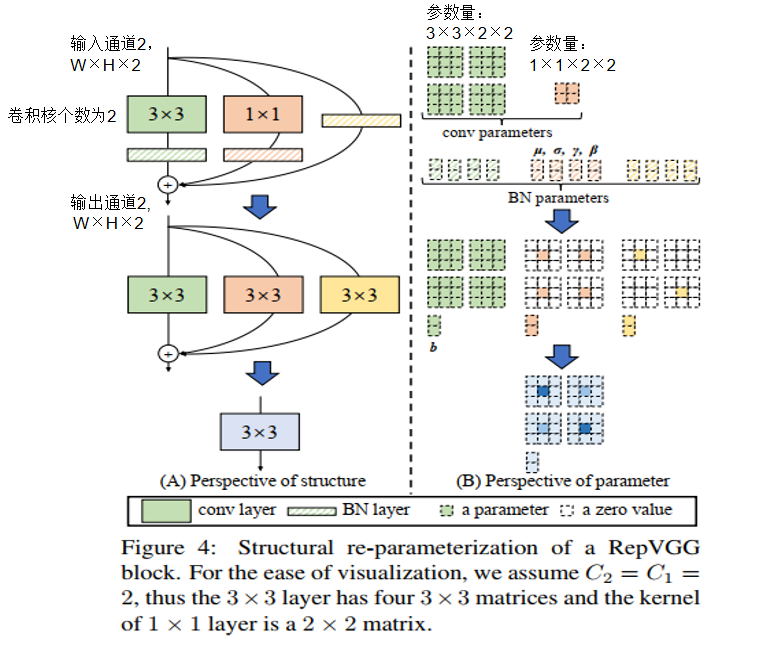
结构重参数之后参数减少了,推理变快了。
灵魂的回答:
结构重参数化的实质:训练时的结构对应一组参数,推理时我们想要的结构对应另一组参数;只要能把前者的参数等价转换为后者,就可以将前者的结构等价转换为后者。
3、总结
RepVGG 是为 GPU 和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。
重参数结构的分支融合和吸 BN 操作,显著放大了权重参数分布的标准差。
而异常的权重分布又会产生了过大的网络激活层数值分布,从而进一步导致该层量化损失过大,因此模型精度损失严重。
这也是RepVGG 的推理模型很难使用后量化方法的原因。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————
投稿吧 | 留言吧