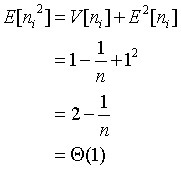目录
摘要:
1 绪论
2 问题定义
3 SBAG模型
3.1社交机器人检测
3.2 机器人感知图神经网络
3.2.1基于GCN的用户发布
3.2.2 基于GAT的用户交互
3.2.3文本编码器
3.2.4 输出层
3.3 训练
4 实验
4.1 数据集
4.2 实验设置
4.3 基线
4.4 实验结果
4.4.1 谣言检测分析
4.4.2 早期发现的分析
4.5 消融研究
4.6 社交bot检测技术分析
4.7 社交机器人行为分析
4.8 案例研究
5 相关工作
6 结论
论文链接:https://aclanthology.org/2022.coling-1.580.pdf
摘要:
背景:早期谣言检测是防止谣言广泛传播的一项关键挑战任务。社会学研究表明,早期社会机器人的行为已成为谣言广泛传播的主要原因。但是,当前的模型并未明确区分真正的用户和社交机器人,并且它们未能及时识别谣言。因此,本文旨在通过对社交机器人行为进行早期谣言检测,并提出了一种社交机器人感知图神经网络SBAG。
模型介绍:SBAG首先预先训练一个多层感知网络来捕获社交机器人特征;然后通过嵌入特征来构建多个图神经网络来建模帖子的早期传播,进一步用于检测谣言。在三个基准数据集上进行的广泛实验表明,SBAG对基线进行了显着改进,并且还可以在3小时内识别谣言,同时保持90% 以上的准确性。
1 绪论
谣言被定义为发布时未经验证的信息 (Qazvinian等人,2011; Zubiaga等人,2018; Lu等人,2022)。在社交媒体上大量传播的恶意谣言,已经成为误导公众、引发社会恐慌的威胁。有必要在早期对谣言进行揭穿,以防止谣言广泛传播。
社会学研究 (Shao et al.,2018a) 表明,在谣言传播过程中存在着社交机器人,这些机器人在谣言的早期特别活跃,会通过回复和提及影响真实用户,加速传播 (Shao et al.,2018b; Beskow和Carley,2018;feng等人,2022)。
目前的模型(Ma等,2016;Chen等,2018;Song等,2019;Zhou等,2019;Xia等,2020;Han等,2021)主要关注帖子内容或传播顺序。这些方法以时间顺序对帖子进行建模,并通过GRU,LSTM和CNN提取文本特征以进行谣言检测。其他方法 (Liu和Wu,2018; Yuan等人,2020) 通过用用户传播结构对用户特征或可信度建模来解释早期谣言检测。然而,他们没有明确区分真正的用户和社交机器人,因此社交机器人的参与将导致从内容和传播结构中捕获的功能失败。
为此,本文提出了一种用于早期谣言检测的社交机器人感知图神经网络 (SBAG) 模型。该模型由两部分组成: 社交机器人检测 (SD) 和机器人感知图谣言检测 (BAG)。
第一个模型:是根据大量的bot用户和真实用户样本进行预训练的,以提取特征以计算每个用户的bot可能性。
第二个模型:将SD传输到机器人感知图神经网络,该网络由基于GNN的用户发布 (GUP),基于GAT的用户交互 (GUI) 和文本编码器组件组成。
介绍:对于GUP,以SD计算的bot可能性涉及聚合过程。对于GUI,bot可能性也被集成到用户-用户注意力权重的计算中。文本编码器利用卷积神经网络 (CNN) 来捕获文本特征。通过这种方式,我们考虑了用户发布功能,用户交互功能和文本功能,以进行早期谣言检测。代码将是开放的sourced(GitHub - sky-star-moon/SBAG: Social Bot-Aware Graph Neural Network for Early Rumor Detection)。我们的主要贡献总结如下:
根据社会学研究的观察,我们考虑了社交机器人的行为,并基于十二个数据集训练了社交机器人检测模型。结果证明了与社会学研究的一致性,机器人在早期非常活跃。
我们提出了一种名为SBAG的早期谣言检测方法,该方法通过结合社交机器人检测来实现早期谣言检测。结果表明,SBAG可以达到93% 以上的准确率,并在3小时内发现90% 谣言。
2 问题定义
假设一组帖子和一组用户
。每个帖子 r对应一个发布者和多个用户重新发布它。
用户发布图: 被构造来表示发布者-帖子关系,其中
是所有发布者和源帖子的集合,
是边的集合,边
指示用户
发布
;
用户交互图: 被构造为表示用户-用户关系,其中
是所有用户的集合,
是边的集合,边
表示用户
回复用户
。
由于我们的动机是通过整合社交机器人的影响来揭穿谣言,因此我们的目标是分别学习两个用于社交机器人检测和谣言检测的分类器:
对于社交机器人检测任务,学习分类器来识别用户u是机器人用户还是真实用户。
对于谣言检测任务,学习了一个分类器来预测每个贴子 r的类。
3 SBAG模型
SBAG模型的框架如图1所示,该模型由两个主要部分组成,即 § 3.1中提到的社交机器人检测 (SD) 和 § 3.2中提到的机器人感知图谣言检测 (BAG)。我们将详细介绍每个模块。
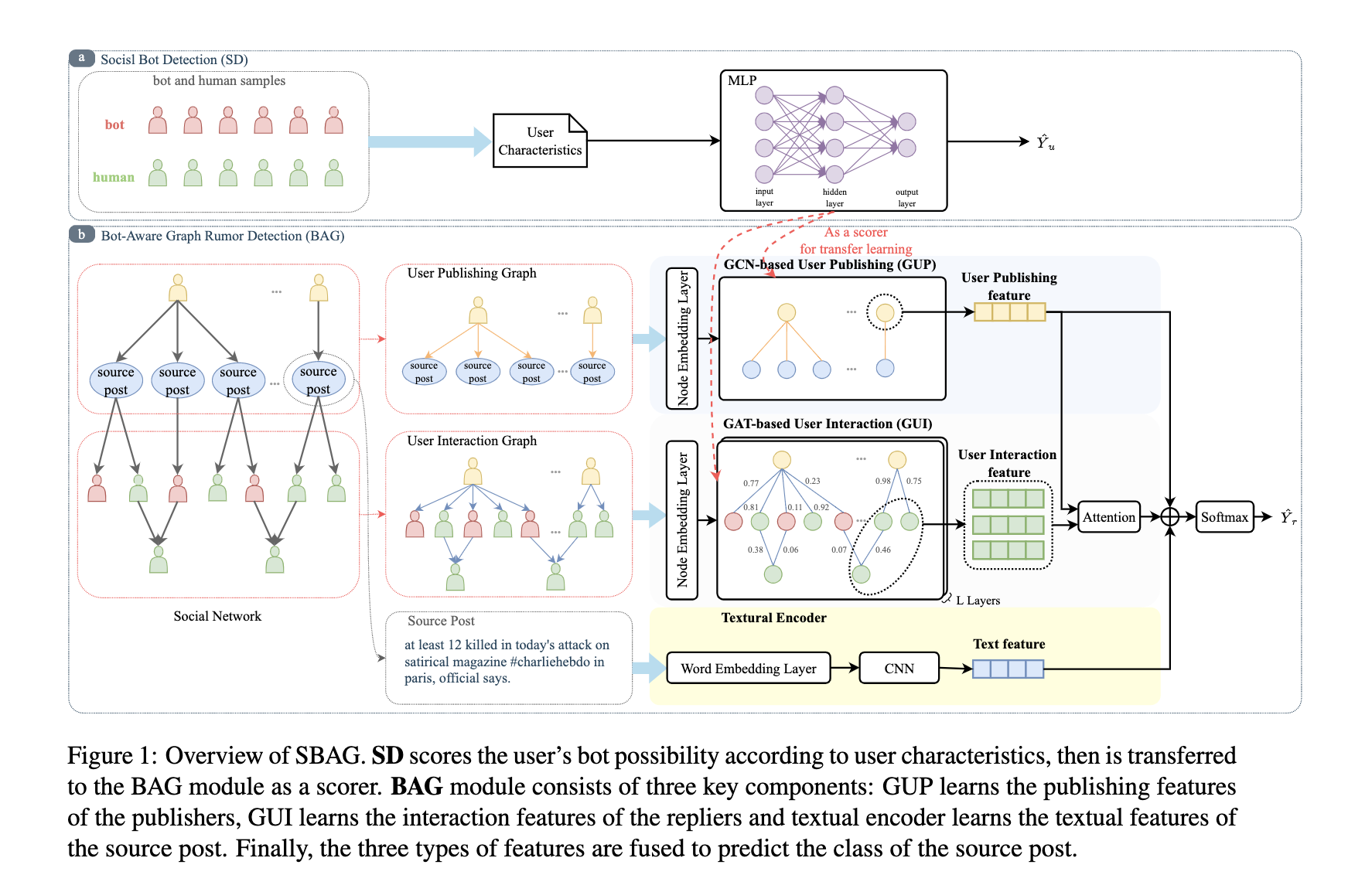
(SD根据用户特征对用户的bot可能性进行评分,然后作为记分员转移到BAG模块。BAG模块由三个关键组件组成: GUP学习发布者的发布功能,GUI学习复制者的交互功能,文本编码器学习源帖子的文本功能。最后,将三种类型的特征融合在一起,以预测源帖子的类别。)
3.1社交机器人检测
为了将机器人行为信息整合到模型中,我们首先在十二个数据集上预先训练SD模块,以了解真实用户和机器人用户的功能。然后,我们将该模块作为机器人可能性记分器转移到BAG,这有助于捕获机器人行为的传播模式。
在预训练阶段,我们使用多层感知器 (MLP) 作为骨干网。形式上,让表示用户特征,例如用户名的长度,关注者的数量等。然后将c归一化并馈送到模块中。流程如下:
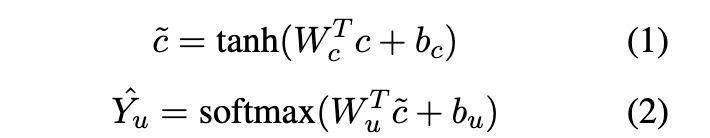
是用户别的预测概率分布。
SD模块将在 [0,1] 内计算用户的机器人可能性,以指示用户显示社交机器人行为的程度。
3.2 机器人感知图神经网络
3.2.1基于GCN的用户发布
由于用户发布图是一个最多只有一跳的二部图,因此它具有很好的局部性。我们设计了一个基于GCN的用户发布组件。形式上,让
表示用户节点的初始嵌入,
表示源帖子节点的初始嵌入,其中m和n分别是发布者节点和源post节点的数量,d是embedding维度。
我们基于Gp构造邻接矩阵,其中元素
表示用户
发布后
,然后我们规范化矩阵 “
”,其中
和
是对角矩阵。
为了将用户早期的bot possibility纳入到组件中,我们构成了一个bot可能性矩阵 ﹐ 其中
的第i行的每个元素都是publisher
的bot可能性 ﹐ 并将其视为偏差。最后,将聚合特征与初始特征相加,以获得发布功能。公式如下:
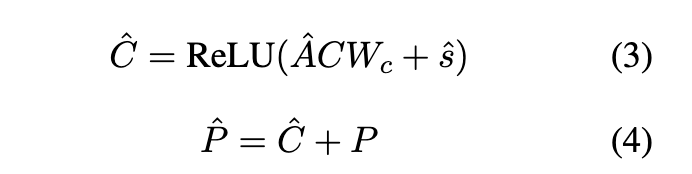
3.2.2 基于GAT的用户交互
在用户交互图中,考虑到邻居节点对target节点的重要性不同,我们设计了基于GAT的用户交互组件。
令 表示第l层的节点特征。用户节点在图形中的嵌入被初始化为
![]()
根据正态分布的嵌入层,d是节点嵌入的维度。参考多头注意机制,层l+1处的节点特征更新如下:
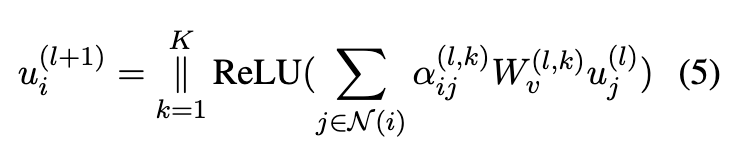
其中 || 表示串联操作。N (i) 是节点i及其直接邻居的集合。是第k个头部中第l层的邻居节点j对目标节点i的注意权重,
是可学习的变换矩阵。
特别地,最后一层 (表示为第L层) 中的输出嵌入是来自K个磁头的特征的平均值,而不是串联。公式如下:、
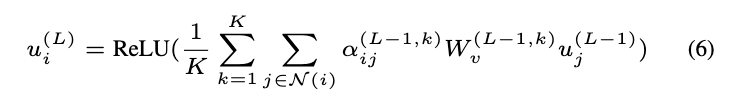
为了捕捉机器人行为的传播模式,我们将机器人可能性引入注意力权重。具体地说,我们利用 § 3.1中定义的SD为边
的两个节点生成bot可能性
和
,并将它们的平均值作为边缘权重
,则
计算如下:
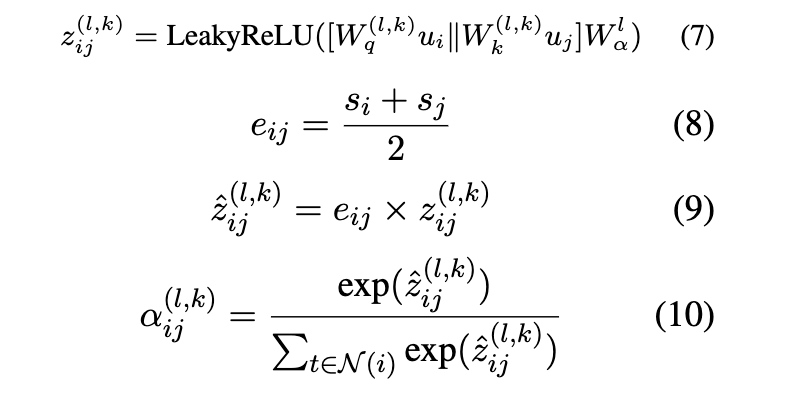
通过L图注意层,获得所有用户节点的动作特征![]() 。
。
接下来,对于一个具有一个发布者和a个复制者的源post r,发布者的特征是,复制者的特征是从
获得的,表示为
。为了区分复制者对发布者的重要性,我们计算注意力权重,然后将来自
的特征汇总到交互特征
中:
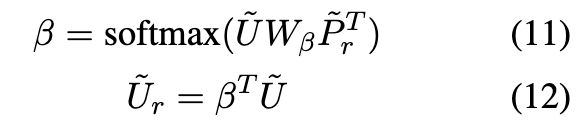
其中 β 是注意力权重的向量.
3.2.3文本编码器
帖子文本的语义特征对于谣言检测也很重要。对于此组件,我们使用与SMAN和GLAN等基线模型一致的CNN来编码源代码。
每个源帖子都可以表示为单词嵌入序列![]() 。在CNN中,通过卷积运算从X获得的特征图的一个特征如下:
。在CNN中,通过卷积运算从X获得的特征图的一个特征如下:
![]()
其中是大小为 ω 的卷积核,F是Frobenius内积。特征图可以表示为h =
![]() 。然后,我们从特征图h中提取最大值,以获得 “
。然后,我们从特征图h中提取最大值,以获得 “”
我们利用不同核大小 ω 的d个滤波器,其中 ω ∈ {3,4,5} 来获得各种特征。最后,将每个滤波器的输出串联起来,以获得文本特征。
3.2.4 输出层
假设源帖子r的文本特征为 ,publisher的发布特征为
,聚合交互特征为
。我们将来自不同类型的源帖子的特征 (即 ̃ pr,̃ ur和 ̃ xr) 连接起来,以获得源帖子的最终特征。最后,将最终特征馈送到完全连接的层中以预测类:
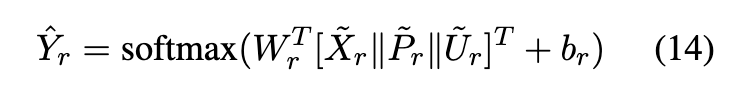
∈ {rumor,non-rumor} 或 “
∈ {non-rumor,f alse rumor,true rumor,unverified rumor} 是预测的类分布。
3.3 训练
我们应用交叉熵损失来优化社交bot检测任务和谣言检测任务。损失函数如下:
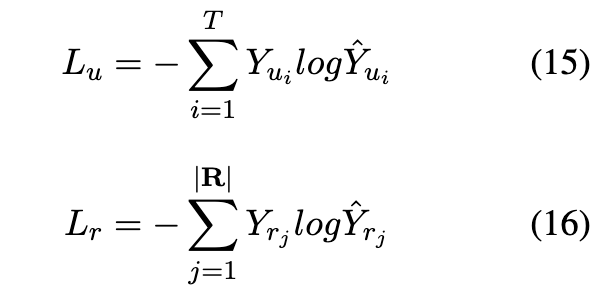
其中,Lu为社交bot检测任务的交叉熵损失,和
分别为第i个用户的groundtruth和预测标签,T为社交bot检测数据集的大小。Lr为谣言检测任务的交叉熵损失,Yrj和
分别为第j个源帖的地面真相和预测标签 | R | 为谣言检测数据集的大小。
4 实验
4.1 数据集
对于谣言检测任务,我们在三个基准数据集上进行实验: Twitter15 (马等人,2017) 、Twitter16 (马等人,2017) 和Weibo16 (马等人,2016)。三个数据集的统计信息显示在Tab1.
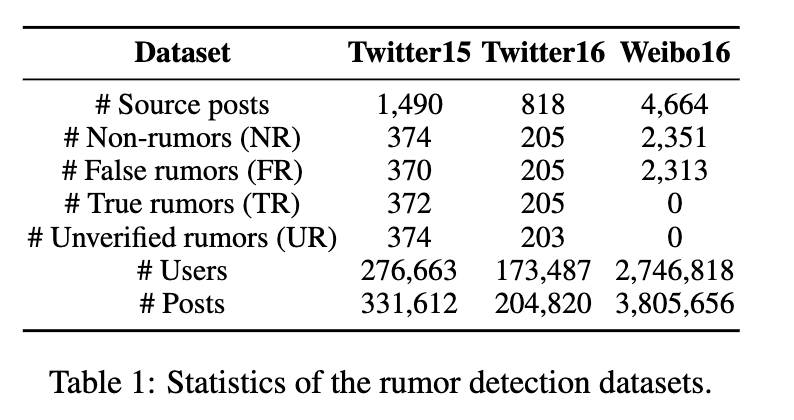
为了公平比较,我们选择与基线工作中相同的拆分数据集的方式 (Yuan等,2020),选择10% 的样本作为验证集,其余样本以3:1的比例拆分为训练集和测试集。
对于社交bot检测任务,我们选择Bot Repository(botometer.osome.iu.edu/bot-repository)提供的12个数据集,数据集的统计显示在Tab2.数据集按8:1:1比例分为训练集,测试集和验证集

4.2 实验设置
对于SD模块,由于Twitter15和Twitter16不涉及用户特征,因此我们利用Twitter API根据用户id抓取用户特征。三个数据集的用户特征选择并不完全相同。详细信息显示在Tab3.

对于BAG模块,节点嵌入d的维数为100,多头注意K的头部数为8,图注意网络层数为2,卷积核大小为 {3,4,5}。利用具有1e-3学习率和1e-6权重衰减系数的Adam优化器。此外,批量大小设置为16,epoch设置为20。与现有工作类似 (Liu和Wu,2018; Yuan等,2019,2020),我们也采用准确性,精确度,召回率和F1得分作为评估指标。
4.3 基线
为了评估SBAG的性能,我们将SBAG与以下方法进行了比较:
DTR (Zhao et al.,2015) 是一种基于决策树的排名方法,它搜索查询短语,对有争议的帖子进行聚类,然后对聚类结果进行排名;
DTC (Castillo等人,2011) 是一种决策树模型,它使用帖子的手工特征来检测谣言;
RFC (Kwon等人,2017) 是一个随机森林分类器,用于学习帖子的用户、语言和结构特征以进行谣言检测;
SVM-RBF (Yang et al., 2012)是一种带有RBF核的SVM模型,基于帖子的统计特征对谣言进行分类;
Svm-ts (马等人,2015) 是一种线性SVM模型,它使用动态序列-时间结构来捕获随时间变化的社会背景特征。
cPTK (马等人,2017) 是一种SVM模型,它使用基于树的内核来评估传播树结构的相似性。
GRU (马等人,2016) 利用RNN来学习时间顺序后的文本特征,以检测谣言。
RvNN (马等人,2018) 将源帖子及其转帖建模为对话树,并采用递归神经网络来学习其支持模式。
PPC (Liu和Wu,2018) 采用RNN和CNN对基于用户特征的序列进行建模,用于早期谣言检测;
GLAN (Yuan等,2019) 将帖子和用户建模为异质图,并通过从图神经网络中提取的局部语义特征和全局结构特征来识别谣言;
SMAN (Yuan et al.,2020) 通过结构感知的多头注意网络,联合优化谣言检测任务和用户可信度预测任务,用于早期谣言检测。
4.4 实验结果
4.4.1 谣言检测分析
表4和表5显示了Twitter15、Twitter16和weibo16上的谣言检测结果。SBAG在三个数据集上分别实现了93.8% 、94.6% 和95.7% 的准确性,并优于基线模型的最佳运行。
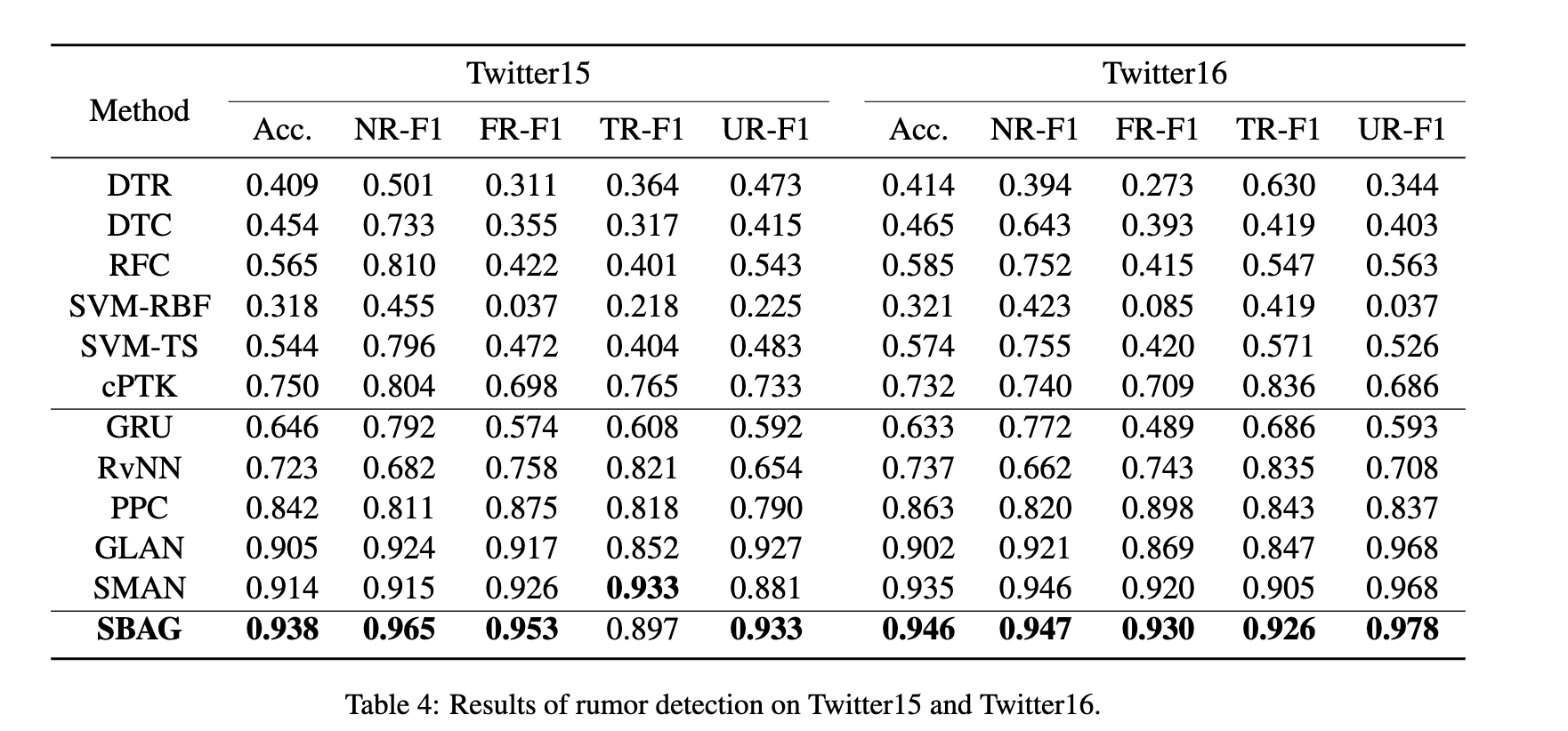
更详细地说,与传统机器学习模型 (例如svm-rbf,svm-ts和cPTK) 相比,SBAG可以捕获更高级别的帖子表示。此外,SBAG形成了基于文本特征的方法,如GRU和RvNN,证明了社交机器人感知的用户特征在谣言检测中是有效的。此外,与捕获用户传播特征或用户可信度的PPC,GLAN和SMAN相比,SBAG实现了更好的性能。这是因为SBAG有利于探索社交机器人行为的特征。
4.4.2 早期发现的分析
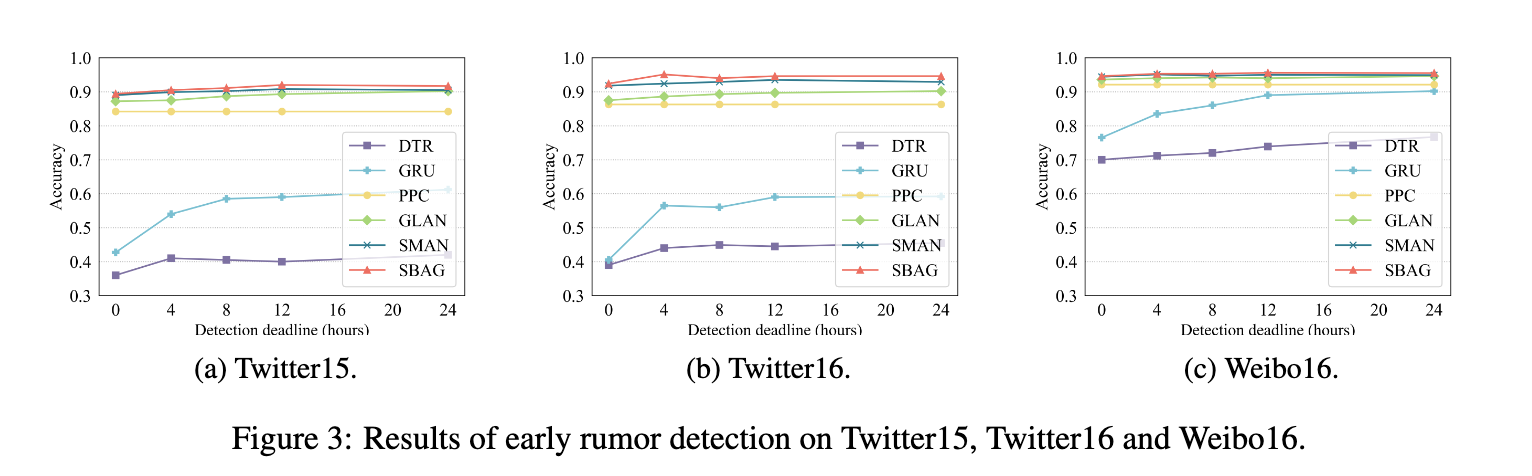
为了评估SBAG的及时性,我们设置了不同的检测截止时间,我们只利用用户在截止日期之前的交互。在图2,Twitter15、Twitter16和weibo16上显示结果。我们可以观察到,在0 ~ 3小时内,SBAG在三个数据集上的准确率都达到了90%以上,并且在早期阶段的结果与考虑所有用户的结果接近,说明SBAG具有较强的早期检测能力。
图3显示了早期检测与Twitter15,Twitter16和weibo16上的几个基线的比较。我们可以看到,SBAG可以更早地揭穿谣言,并保持很高的准确性,甚至超过了SMAN和GLAN等最先进的基线。此外,在24小时内,SBAG可以达到与学习所有用户功能的相似的性能。
4.5 消融研究
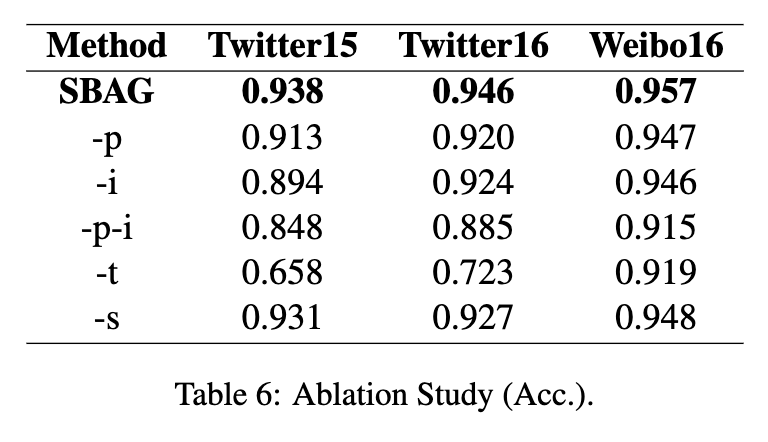
为了证明不同特征的有效性,我们还进行了消融研究,实验结果如下:
(1) -p:剔除GUP后,模型通过文本特征和交互特征预测谣言,不考虑发布者特征。
(2) -i: 去除GUI,模型通过文本特征和发布特征预测谣言,没有交互特征。
(3) -p-i: 这意味着我们丢弃了提到 (1) 和 (2) 的两个组件,并仅通过文本特征检测谣言;
(4) -t: 删除文本编码器,该模型通过发布者特征和交互特征预测谣言,没有文本特征。
(5) -s: 在没有预先训练的记分员的情况下,我们对机器人的可能性进行随机评分。
如表6所示,我们可以观察到SBAG的每个组件都是必不可少的。具体来说,-p和-i在三个数据集上的表现比原始模型差,这表明发布功能和交互功能对于谣言检测具有重要意义。-p- i急剧下降,这表明仅通过文本特征检测谣言是次优的。此外,-t的性能也显著下降。这是因为源帖子的文本特征对于检测谣言至关重要。-p-i和-t的结果表明,用户特征和文本特征具有互补关系。-s的性能表明,社交机器人检测对谣言检测是有益的。
4.6 社交bot检测技术分析
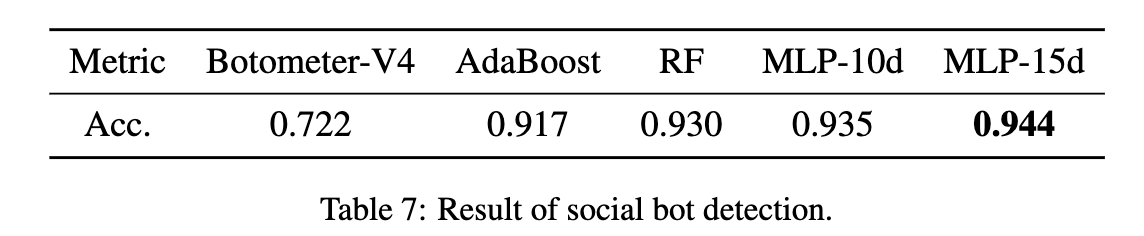
然后,我们将分析预先训练的社交机器人检测模块的性能。如表3中所述,我们分别选择15个和10个用户特征来表示Twitter和微博数据集上的用户。因此,我们预先训练了两个不同维度的社交机器人检测模块,即MLP-15d和MLP-10d。为了进行比较,我们选择基线模型如下:
(1) Botometer-v4 (Sayyadiharikandeh等人,2020) 是一个公共程序,可用于评估Twitter上任何用户的机器人得分。
(2) AdaBoost (Kudugunta and Ferrara,2018) 提取10个用户特征来表示用户,并采用AdaBoost分类器进行bot检测;
(3) RF (Yang等,2020) 是随机森林模型,从用户信息中提取8个原始特征和12个派生特征,并利用随机森林分类器识别用户。
结果显示在表7中,.MLP-15d和MLP-10d的准确性优于基线,这表明它们具有很大的识别用户的能力。MLP-15d优于MLP-10d,因为输入给MLP-15d的用户信息更丰富。MLP模型比Botometer-V4,Ad- aBoost和RF等机器学习模型的性能更好,这表明MLP可以通过较少的功能来学习高质量的用户表示。
4.7 社交机器人行为分析
在Twitter15,Twitter16和Weibo16的测试集中,我们列出了谣言与发布者之间的关系,即每个源帖子类下的机器人行为发布者的比例。
如图4a所示,我们可以观察到,bot可能性计分器将发布非谣言的用户识别为bot的很少。相反,机器人可能性记分者将大多数发布谣言的用户标识为机器人。
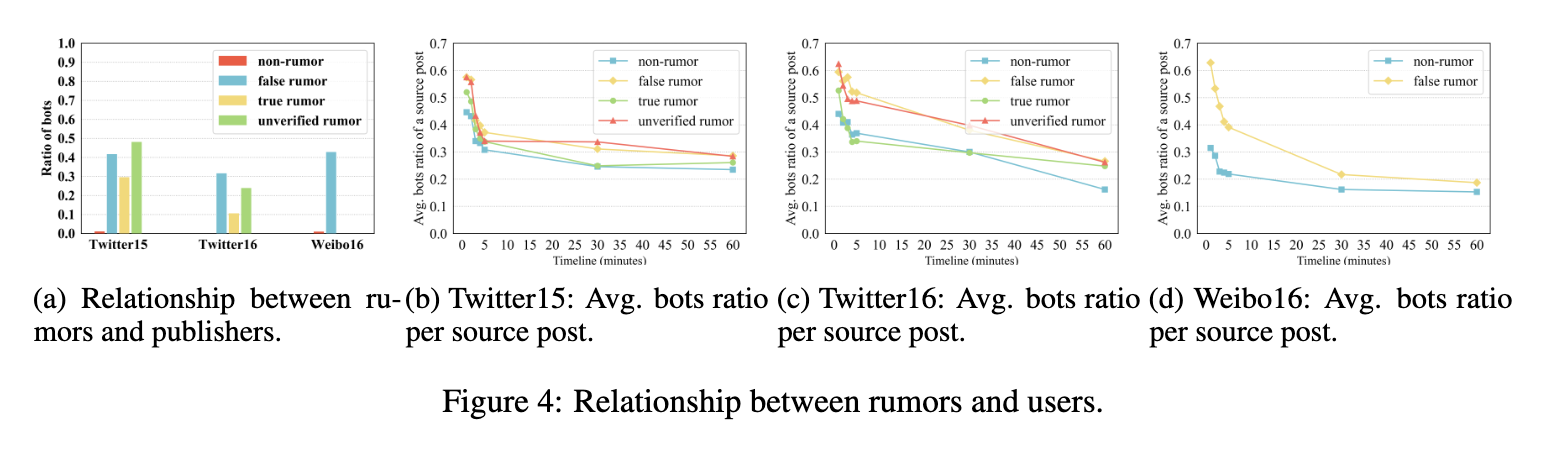
此外,在虚假谣言和未经证实的谣言中,机器人的比例高于真实谣言。
我们还统计了每个源帖子类的源帖子下所有参与者中机器人行为用户的平均比率。如图4b-4d所示,在源帖子发布后的前五分钟内,bot行为比连续期间更加活跃。虚假谣言和未经证实的谣言的机器人行为用户比例高于非谣言和真实谣言。SBAG的结果与社会学研究相结合,也证明了我们的模型具有很强的可解释性。
4.8 案例研究
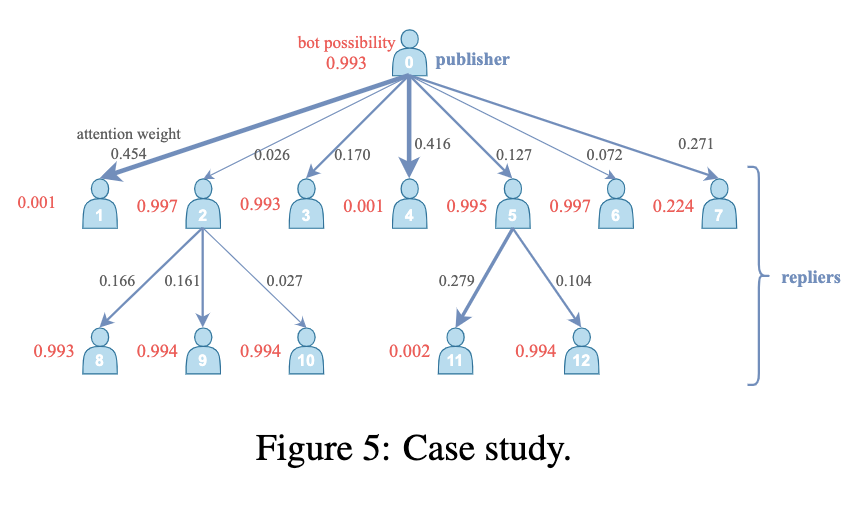
为了演示机器人可能性与注意力权重之间的关系,我们选择了一个经典样本进行可视化。
图5示出了一个发布者和相应的复制者的注意力权重,其中注意力权重由GUI计算。
图5示出了连接到具有较低机器人可能性的用户的边具有较高的注意力权重。这种聚合方式有助于学习更有效的早期传播模式。
5 相关工作
传统的谣言检测方法采用机器学习来根据内容、用户和传播模式的特征对谣言进行分类,例如决策树 (Castillo等人,2011),支持vec- tor马chine(Yang等人,2012; Liu等人,2015;马等人,2015; Wu等人,2015) 、随机森林 (Kwon等人,2013) 等。然而,这些方法涉及特征工程,很难获得高阶特征。
最近的研究利用深度学习方法进行谣言检测。大多数现有的谣言检测方法马使用RNN (马等人,2016; Song等人,2019; Zhou等人,2019),CNN(Yu等人,2017),transformer (Khoo等人,2020; Rao等人,2021) 、GCN(Bian等人,2020; Song等人,2021; Wei等人,2021; Sun等人,2022) 和GAT(Lin等人,2021) 来学习具体内容特征。但是,这些模型并未考虑社交媒体上的社交机器人的参与者发布欺诈性内容,这可能会导致这些欺诈性内容引起训练噪音。
若干研究 (Liu和Wu,2018; Yuan等人,2019; Lu和Li,2020; Yuan等人,2020) 集成了用户特征或用户可信度的特征,以学习源帖子的传播模式。但是,他们没有在早期阶段明确探索独特的用户传播模式,这限制了模型的早期检测能力。
6 结论
在这项工作中,根据社会学研究的观察,我们提出了一种社交机器人感知图神经网络,用于早期谣言检测。
首先,我们在包含bot用户和真实用户的大型数据集上预先训练一个称为SD的bot可能性记分员,然后将SD转移到BAG模块。BAG模块将用户的bot可能性信息纳入到来自不同视图的特征的计算中,从而使该模块能够在早期检测中先验地了解用户。在三个公共数据集上的实验结果表明,SBAG有效地捕获了谣言的早期传播,进一步提高了早期谣言检测的性能。