论文信息
- 标题: PlainUSR: Chasing Faster ConvNet for Efficient Super-Resolution
- 作者: Yan Wang, Yusen Li, Gang Wang, Xiaoguang Liu
- 发表时间: 2024年
- 会议/期刊: 亚洲计算机视觉会议(ACCV 2024)
- 研究背景: 超分辨率(Super-Resolution, SR)任务近年来受到广泛关注,尤其是在实时性能和高效计算方面的挑战。现有方法通常在性能和计算效率之间进行权衡,但仍难以实现低延迟和高质量的图像重建[4][5][21]。
- 链接:https://openaccess.thecvf.com/content/ACCV2024/papers/Wang_PlainUSR_Chasing_Faster_ConvNet_for_Efficient_Super-Resolution_ACCV_2024_paper.pdf
创新点
PlainUSR提出了一种高效的卷积网络框架,通过以下三大模块的改进实现了超分辨率任务的加速和性能优化:
- 卷积模块: 使用重参数化技术,将轻量但较慢的MobileNetV3卷积块替换为更重但更快的普通卷积块,从而在内存访问和计算之间实现平衡[4][5][24]。
- 注意力模块: 引入基于区域重要性的局部注意力机制(Local Importance-based Attention, LIA),通过区域重要性图和门控机制实现高阶信息交互,同时保持低延迟[4][5][21]。
- 主干网络: 提出了一种简化的U-Net结构,采用通道级的分离和连接操作,进一步优化网络的计算效率和性能[4][5][24]。
这些创新点旨在解决现有方法在实时性能和计算效率上的瓶颈,同时保持竞争性的图像重建质量。
方法
PlainUSR的设计包括以下核心步骤:
-
卷积模块优化:
- 使用重参数化技术(Reparameterization Tricks)将MobileNetV3卷积块转化为普通卷积块。
- 这种设计减少了内存访问开销,同时提高了计算速度[4][5][24]。
-
局部注意力机制:
- 通过区域重要性图对输入进行调制,结合门控机制实现信息交互。
- 该方法在保持低延迟的同时,增强了局部和全局信息的整合能力[4][5][21]。
-
主干网络优化:
- 使用简化的U-Net结构,通过通道级分离和连接操作实现高效的特征处理。
- 这种设计进一步减少了计算复杂度,同时提高了网络的扩展性[4][5][24]。
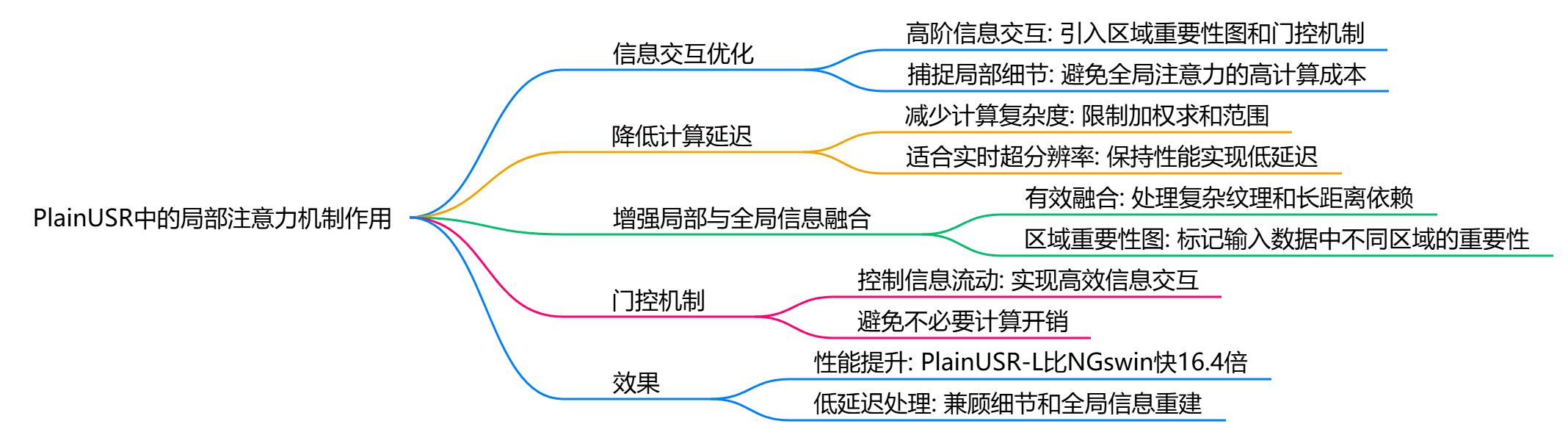
局部注意力机制的作用
-
信息交互优化
局部注意力机制通过引入区域重要性图和门控机制,能够在局部范围内实现高阶信息交互。这种设计使得模型能够更有效地捕捉局部细节,同时避免了传统全局注意力机制可能带来的高计算成本[4][5][6]。 -
降低计算延迟
局部注意力机制的设计重点在于减少计算复杂度。相比全局注意力,局部注意力将加权求和的范围限制在特定窗口内,从而显著降低了计算量。这种方法特别适合实时超分辨率任务,能够在保持性能的同时实现低延迟[3][4][5]。 -
增强局部与全局信息的融合
PlainUSR中的局部注意力机制不仅关注局部细节,还通过区域重要性图实现了局部与全局信息的有效融合。这种融合能够帮助模型在处理复杂纹理和长距离依赖时表现更优[4][5][6]。
PlainUSR中的具体实现
- 区域重要性图: 局部注意力机制通过生成区域重要性图来标记输入数据中不同区域的重要性。这种图能够指导模型将计算资源集中在关键区域,从而提高效率和准确性[4][5][6]。
- 门控机制: 门控机制用于控制信息流动,确保模型能够在局部范围内实现高效的信息交互,同时避免不必要的计算开销[4][5][6]。
效果
PlainUSR在实验中表现出以下显著优势:
- 低延迟: 与最新的NGswin方法相比,PlainUSR-L版本的运行速度快16.4倍,同时保持了竞争性的性能[4][5][10]。
- 高扩展性: 该框架能够适应不同的计算资源需求,适用于多种硬件环境[4][5][21]。
- 性能对比: 在与其他面向低延迟和高质量的超分辨率方法的对比中,PlainUSR展现了卓越的性能和计算效率[4][5][24]。
实验结果表明,PlainUSR在多个基准数据集上均取得了优异的表现,证明了其在实时超分辨率任务中的实用性。
综上所述,PlainUSR通过对卷积模块、注意力机制和主干网络的优化,成功实现了高效的超分辨率任务处理,兼顾了低延迟和高质量的图像重建需求。这项研究为实时超分辨率任务提供了新的解决方案,并具有广泛的应用前景。
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class SoftPooling2D(torch.nn.Module):
def __init__(self, kernel_size, stride=None, padding=0):
super(SoftPooling2D, self).__init__()
self.avgpool = torch.nn.AvgPool2d(kernel_size, stride, padding, count_include_pad=False)
def forward(self, x):
x_exp = torch.exp(x)
x_exp_pool = self.avgpool(x_exp)
x = self.avgpool(x_exp * x)
return x / x_exp_pool
class LocalAttention(nn.Module):
''' attention based on local importance'''
def __init__(self, channels, f=16):
super().__init__()
self.body = nn.Sequential(
# sample importance
nn.Conv2d(channels, f, 1),
SoftPooling2D(7, stride=3),
nn.Conv2d(f, f, kernel_size=3, stride=2, padding=1),
nn.Conv2d(f, channels, 3, padding=1),
# to heatmap
nn.Sigmoid(),
)
self.gate = nn.Sequential(
nn.Sigmoid(),
)
def forward(self, x):
''' forward '''
# interpolate the heat map
g = self.gate(x[:, :1].clone())
w = F.interpolate(self.body(x), (x.size(2), x.size(3)), mode='bilinear', align_corners=False)
return x * w * g # (w + g) #self.gate(x, w)
if __name__ == "__main__":
# 定义输入张量大小(Batch、Channel、Height、Wight)
B, C, H, W = 16, 512, 40, 40
input_tensor = torch.randn(B,C,H,W) # 随机生成输入张量
dim=C
# 创建 LocalAttention实例
block = LocalAttention(channels=dim)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sablock = block.to(device)
print(sablock)
input_tensor = input_tensor.to(device)
# 执行前向传播
output = sablock(input_tensor)
# 打印输入和输出的形状
print(f"Input: {input_tensor.shape}")
print(f"Output: {output.shape}")
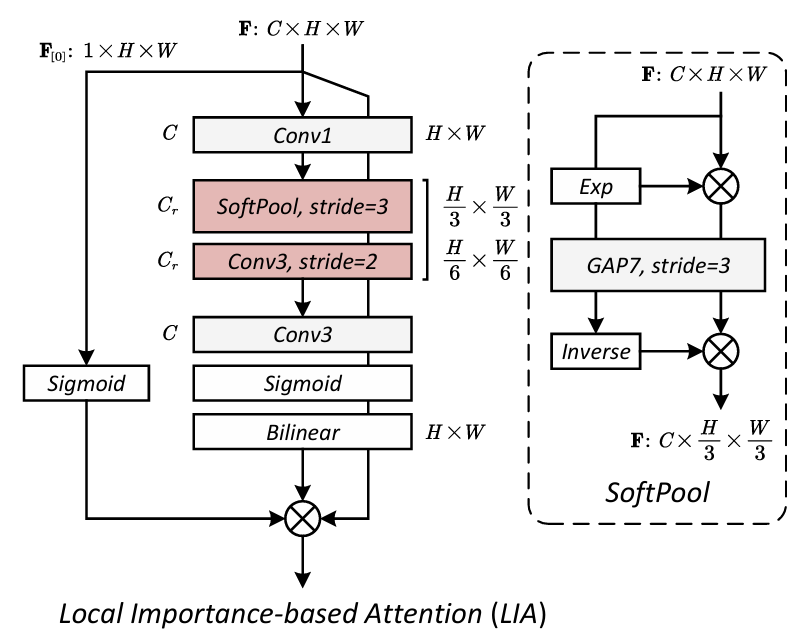
代码详解:LocalAttention 模块
1. 模块功能概述
LocalAttention 是一种基于局部重要性加权的注意力机制,通过以下步骤增强特征图中关键区域:
- 重要性采样:通过卷积和软池化提取局部重要性特征。
- 权重图生成:通过卷积层生成空间注意力图。
- 门控调节:结合通道维度的门控信号,动态调整特征响应。
2. 代码逐层解析
2.1 SoftPooling2D 类
class SoftPooling2D(torch.nn.Module):
def __init__(self, kernel_size, stride=None, padding=0):
super(SoftPooling2D, self).__init__()
self.avgpool = torch.nn.AvgPool2d(kernel_size, stride, padding, count_include_pad=False)
def forward(self, x):
x_exp = torch.exp(x) # 指数运算增强对比度
x_exp_pool = self.avgpool(x_exp) # 对指数结果平均池化
x = self.avgpool(x_exp * x) # 对加权特征平均池化
return x / x_exp_pool # 归一化输出
-
功能:软池化,替代传统最大/平均池化,保留更多信息。
-
优势:通过指数运算放大显著特征,池化后归一化,保留相对重要性。
2.2 LocalAttention 类
初始化方法 __init__
def __init__(self, channels, f=16):
super().__init__()
self.body = nn.Sequential(
nn.Conv2d(channels, f, 1), # 通道压缩到 f (默认16)
SoftPooling2D(7, stride=3), # 7x7 池化,步长3
nn.Conv2d(f, f, kernel_size=3, stride=2, padding=1), # 下采样
nn.Conv2d(f, channels, 3, padding=1), # 恢复通道数
nn.Sigmoid() # 生成 [0,1] 权重图
)
self.gate = nn.Sequential(
nn.Sigmoid() # 门控信号
)
前向传播 forward
def forward(self, x):
g = self.gate(x[:, :1].clone()) # 取第1个通道生成门控信号
w = F.interpolate(
self.body(x), # 生成低分辨率权重图
(x.size(2), x.size(3)), # 插值到输入尺寸
mode='bilinear', align_corners=False
)
return x * w * g # 特征加权
LocalAttention 通过局部重要性采样和门控机制实现特征自适应增强,其设计兼顾计算效率与灵活性。改进空间包括优化门控信号生成、增强数值稳定性等。该模块可嵌入 CNN 或 Transformer 中,提升模型对关键区域的感知能力。








![线代[12]|《高等几何》陈绍菱(1984.9)(文末有对三大空间的分析及一个合格数学系毕业生的要求)](https://i-blog.csdnimg.cn/direct/c3824a02d3094a648f7adf08f2cb137f.jpeg#pic_center)