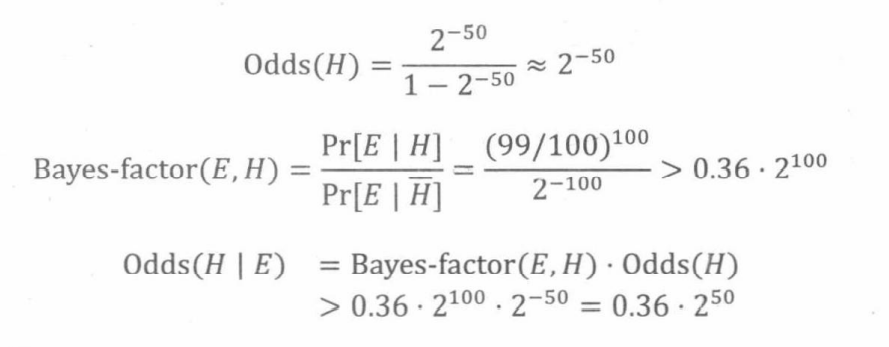字符串在整整个开发的过程中,使用频率相对来说是较高的。
在此总结几个字符串的常用操作, 字符串的操作,转换后即生成为新字符串
【长度统计
切片:
【
根据索引进行切片str[开始索引:结束索引:步长]
根据指定标识符进行切片str.split(‘标识符’,切割次数),返回一个数组,如果标识符不存在,则将整个字符串返回一个数组,且元素只有一个
】
替换:replace ,当替换次数为空时,替换次数默认为全部替换
ste.replace(‘旧元素’,‘新元素’,‘替换次数’)
将字符串的’o’进行替换

将字符串中‘o’第一次出现的位置替换为大写的Y,即为替换一次

查找
【
1、根据索引查找元素 :str[索引] 打印出来的为字符串中指定索引的字符
2、根据字符查找索引:str.index(‘字符’),次数输出位字符所以的索引值
ps:根据字符查找索引时,如果输入的多个连贯字符,则返回的索引为第一个字符的索引

3、系统中还给出find(’字符‘,’步长‘),默认从左侧查找,默认步长为1,返回最所在的索引值
rfind(’字符‘,’步长‘)方法,从右侧查找,默认步长为1,返回字符所在的索引值

】
ps:字符查找本人习惯用.index()函数,不过还是推荐使用find()或者rfind()详见下边总结
统计:count(),个人习惯用法是:判断某个字符出现的次数,根据次数进行字符串切割
print(str.data.count('o'))

判断:判断类返回结果为True或者为False
1、是否为数字,isdigit()
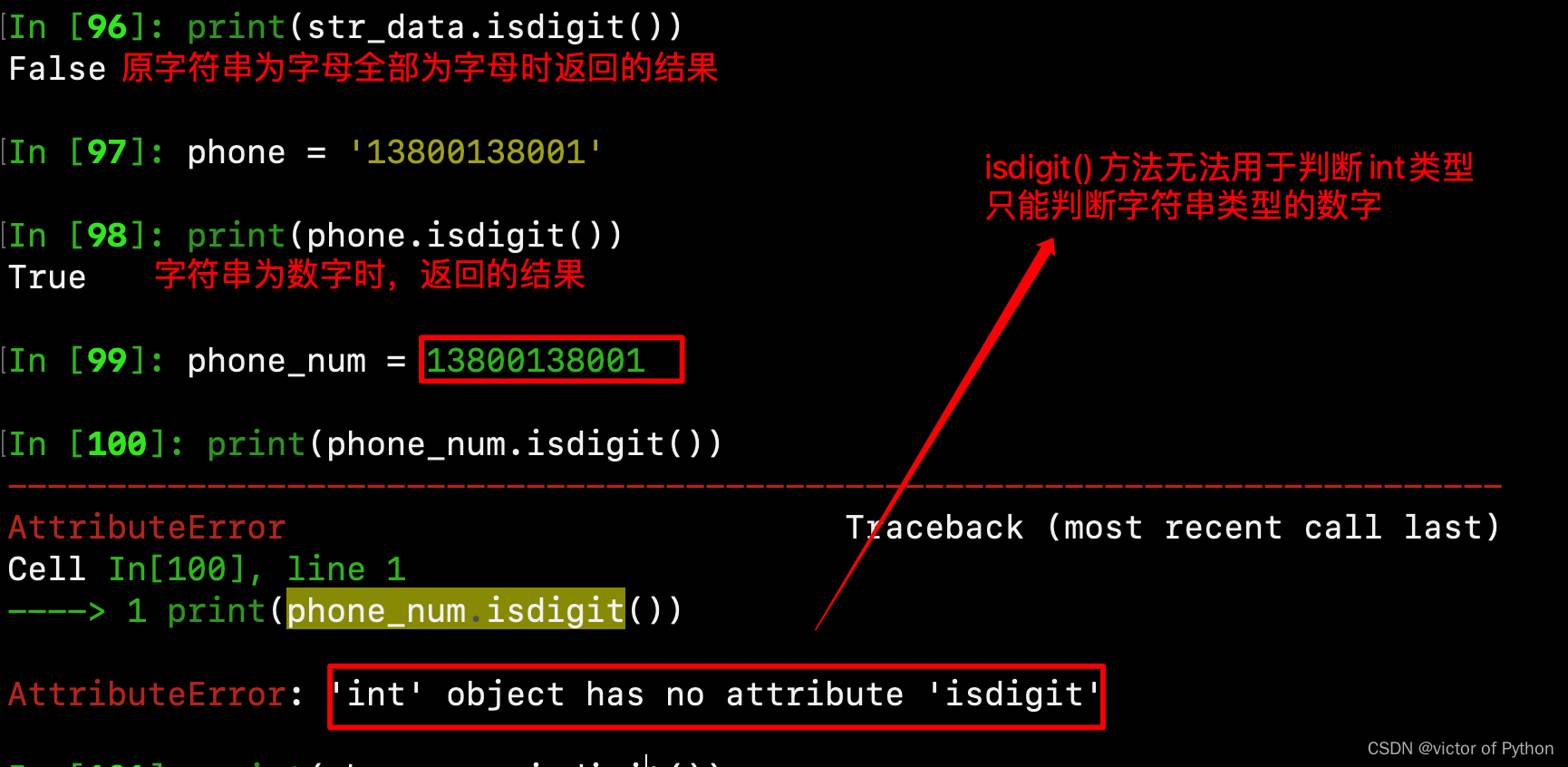
2、是否为字符,isalpha()即为【a-z,A-Z】

3、是否为字母或数字或者为字母和数字的组合:isalnum()即为【a-z,A-Z,0-9】



4、判断是否以某个字符开始或者结束startswith(‘字符’),endstwih(‘字符’)


ps:以上判断方法仅用于简单的判断,较为复杂的判断使用正则表达式
全部转为大写upper()

全部转为小写lower()

首字母转为大写capitalize()

】
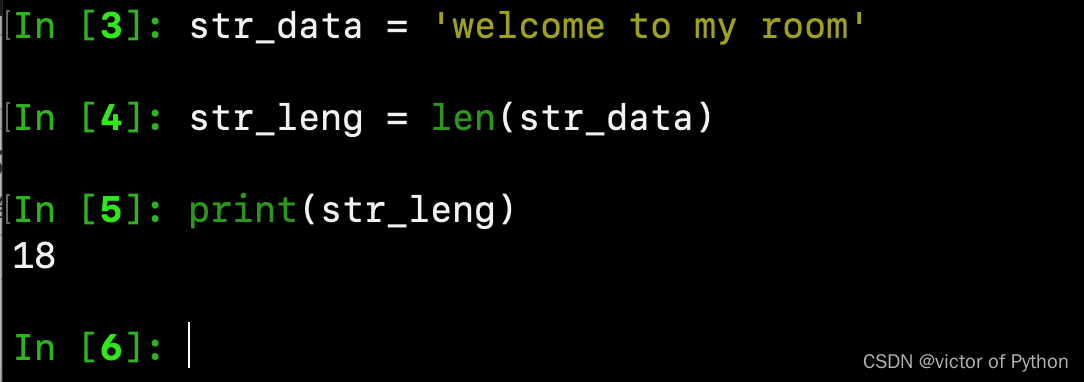
例子:str_data = 'welcome to my room
1、统计字符换的长度。
str_leng = len(str_data)
print(str_leng)
用ipython的运行结果如图
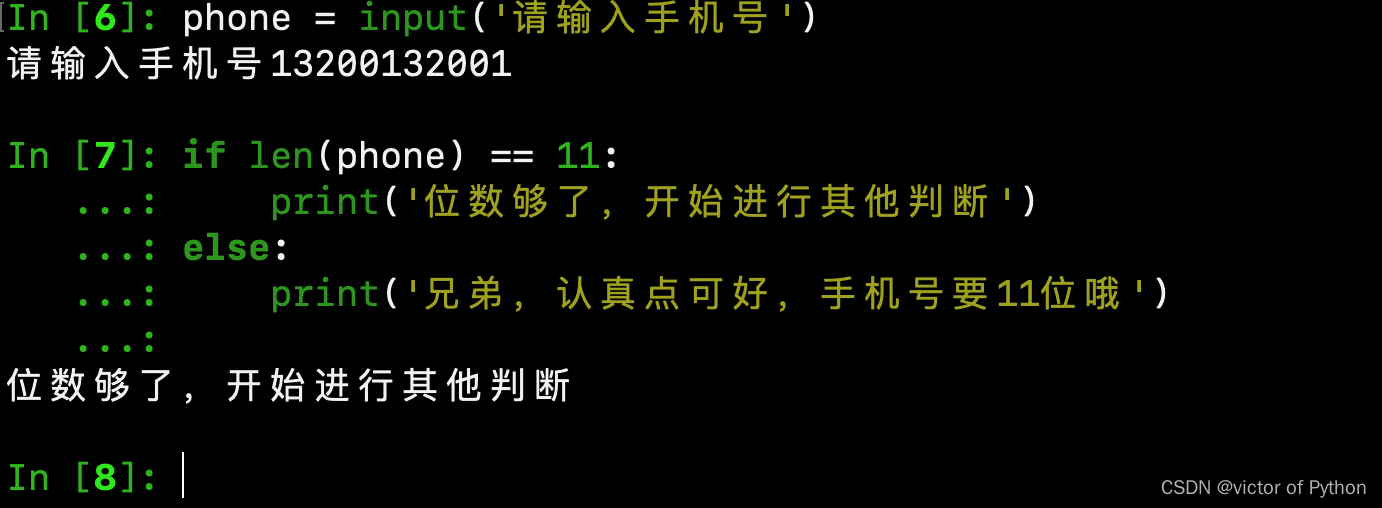
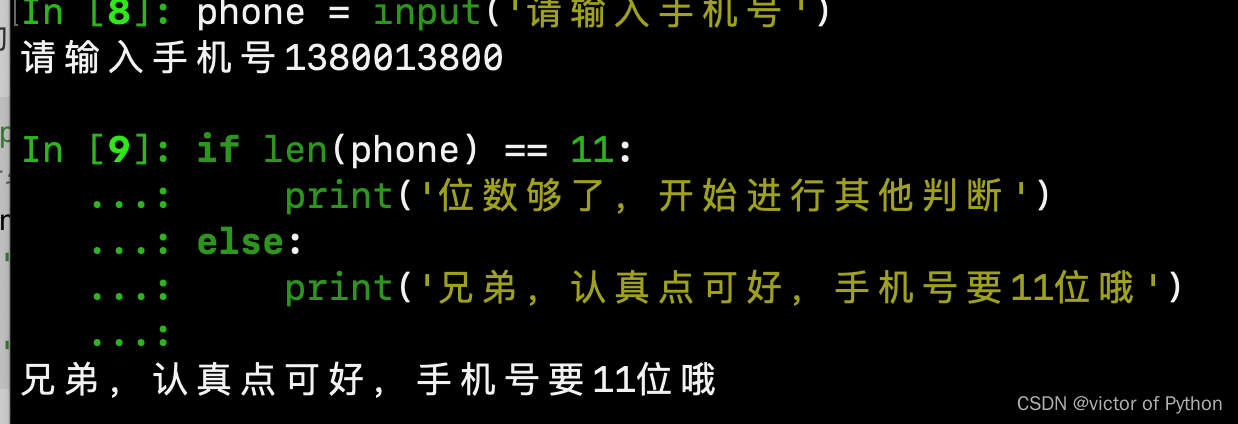
统计字符串的长度有什么作用呢?举例子,判断手机号的长度是否为11位(仅仅是其中一个案列哦,后期判断手机号是可以通过正则表达式或者其他库来进行验证的)
phone = input('请输入手机号')
# 通过input输入的内容均为字符串
if len(phone) == 11:
print('位数够了,开始进行其他判断')
else:
print('兄弟,认真点可好,手机号要11位哦')
2、字符串的切片,可以使用str[开始索引:结束索引:步长],也可以使用split
只获取以上字符串的welcome
1、使用str[开始索引:结束索引:步长]方式,注意:切取的最后一位是结束索引-1。
new_str = str_data[0:8:1] #完整写法
print(new_str)
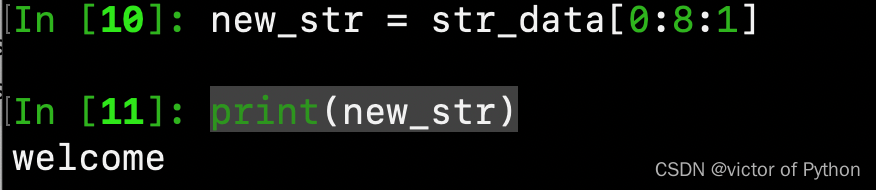
以上方法可以简写为:
new_str2 = str_data[:8]
print(new_str2)

以上方法默认的开始索引为0,步长为1
下面,还是使用这种方法,做如下要求,截取该字符串的前10位,要求每隔1个字符串截=取一个
分析:截取前10位,开始索引为0,结束索引为10+1,即为11,每隔1个字符串截取一个,步长为2
new_str3 = str_data[0:11:2]
print(new_str3)

ps:步长个人的理解为:两个相邻字符的索引相减。如果步长为正数,则是从左向右开始截取,如果步长为负数,则是从右向左截取。
new_str4 = str_data[0:8:-2]
print(new_str4)
new_str5 = str_data[11:8:-2]
print(new_str5)

print(str_data[11])
print(str_data[8])
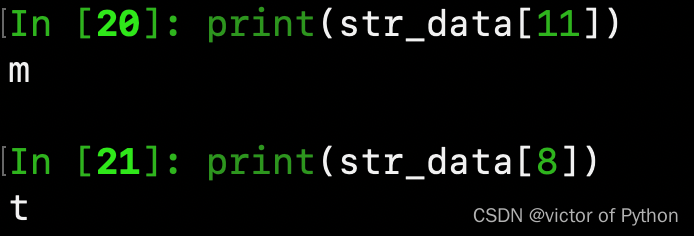
ps:步长为负数索引时,截取的字符串也为原字符串的反转,如下,我们将截取字符串的room,并做反转
new_str6 = str_data[-1:-5:-1]
print(new_str6)

尝试一下其他方式 突如其来的想法
1、截取任意字符,任意长度
思路:查找开始字符的索引,查找结束字符的索引,根据步长进行截图
例子:截取字符串中‘e’第一次出现的位置,至第一次‘r’出现的位置,以步长为1进行截取
ps:查找字符的索引用:str.index(‘字符’)
# 首先查找e第一次出现的位置
str_e = str_data.index('e')
print(str_e)

# 查找r第一次出现的位置
str_r = str_data.index('r')
print(str_r)

new_str7 = str_data[1:15:1] # 步长为1时,可以不用写,系统默认的步长为1,可以写成:new_str7 = str_data[1:15]
print(new_str7)
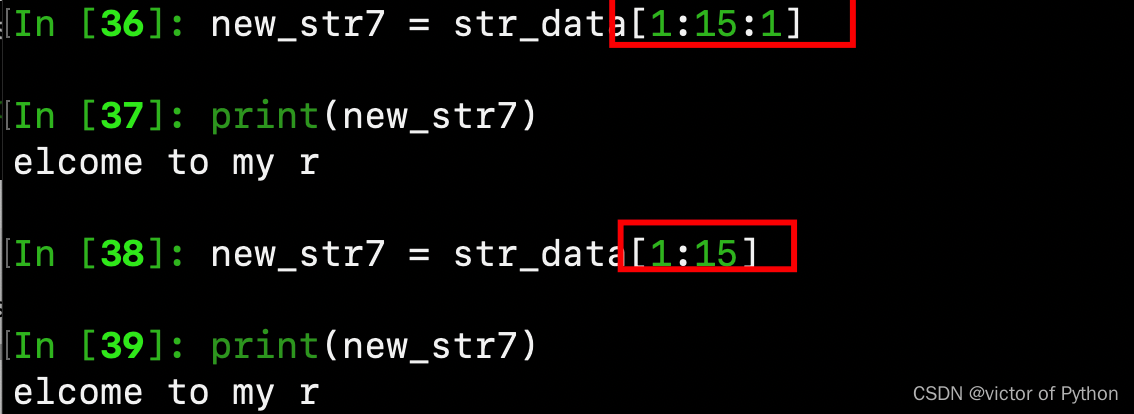
扩展1:截取以上字符串中的room,将按照逆序输出
思路:通过查看字符串得知,room为字符串的最后一位,即开始索引为len(str_data)-1
,再统计room的长度为len(‘room’),即结束索引为len(str_data)-len(‘room’)-1,逆序时,步长为-1,由此得出:
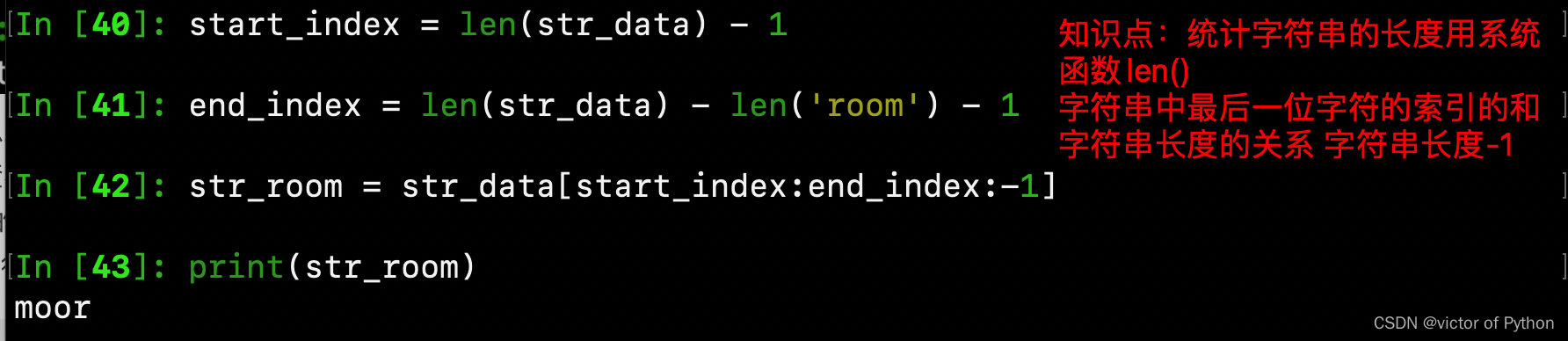
start_index = len(str_data) - 1
end_index = len(str_data) - len('room') - 1
str_room = str_data[start_index:end_index:-1]
print(str_room)
2、用split进行字符串切片 通过指定分隔符对字符串进行切片
str.split(str=“”, num=string.count(str)).
参数
str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。
str_split_01 = str_data.split()

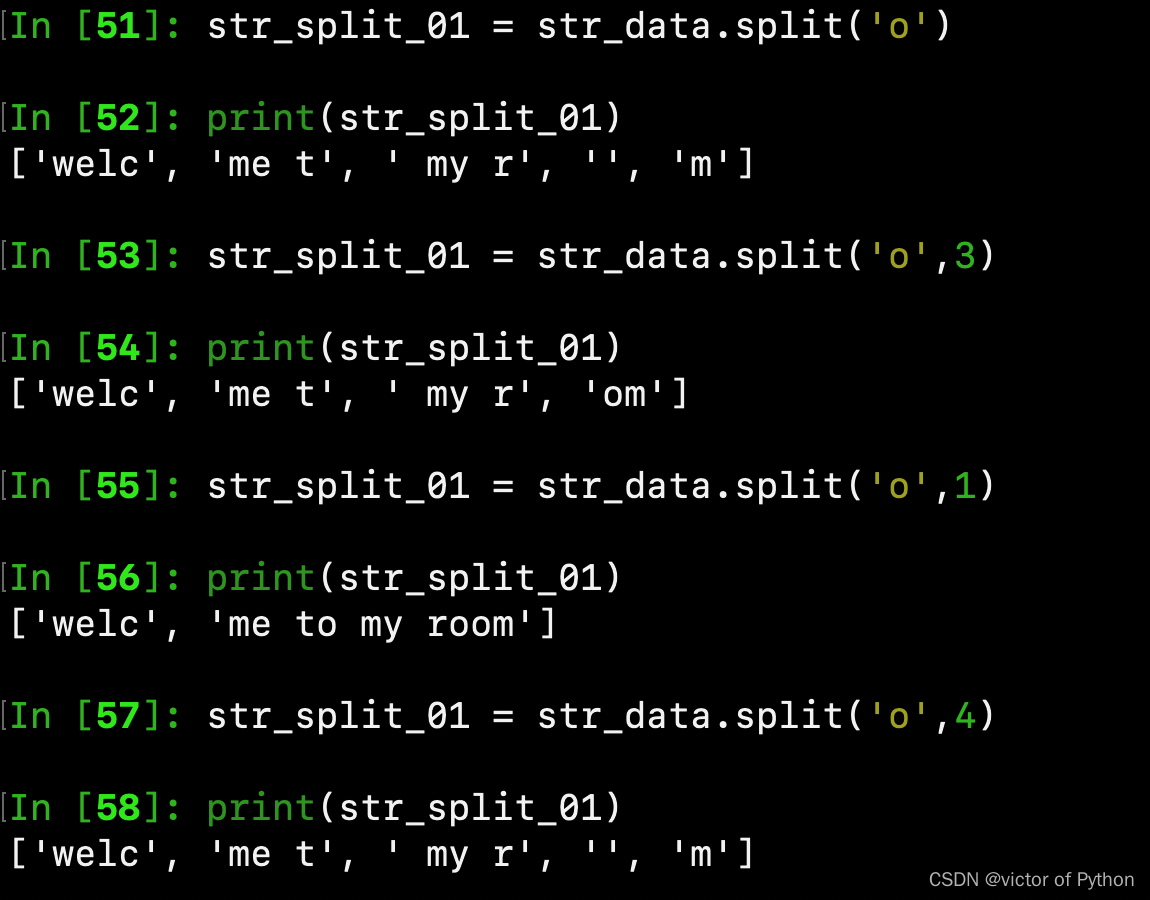
ps: split()的主要是以某种字符为标识进行切割,第二个参数为切割几次
举例:
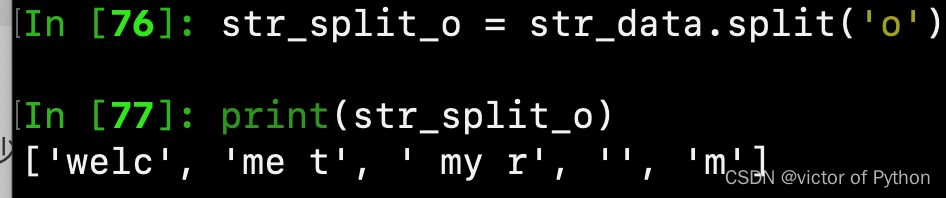
第一:str_data字符串,以‘o’为切割标识进行切割,切割次数为系统默认,则,字符串中有多少个‘o’就进行多少次的切割,切割后返回一个列表
str_split_o = str_data.split('o')
print(str_split_o)
第二:字符串依旧以’o’为切割标志,切割次数为1次,如下
str_split_o_one = str.data.split('o',1)
print(str_split_o_one)

ps:切割后得到的元素个数为切割次数+1,如上,切割一次,得到了两个元素
个人理解的split()的用法应该是常用如长字符串以某种符号进行切割时使用。
总结:
1.统计长度len(str)
2.统计次数str.count(‘string’)
3.查找字符所在位置
str.index(‘string’),
str.find(‘string’,‘startindex’,‘endindex’),str.rfind(‘string’,‘startindex’,‘endindex’)
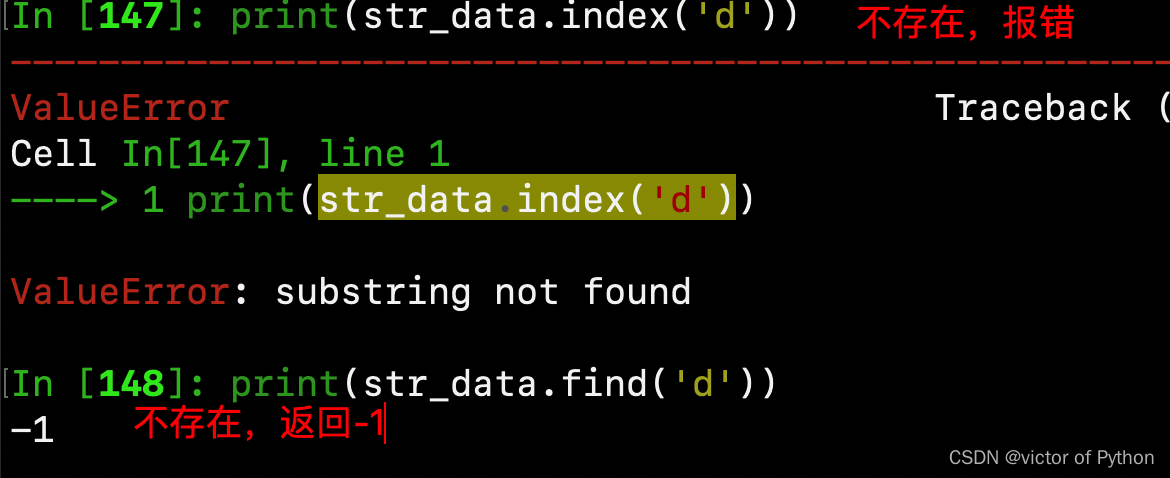
区别为:find()/rfind()查找不到时返回-1,index()查找不到时返回错误
4.判断类:
是否为数字isdigit()
是否为字母isalpha()
是否为数字或者字母或者数字和字母的组合isalnum()
是否为某个字符开始:startswith()
是否为某个字符结束:endswith()
5.切片
str[start,end,step],staert 默认为0,step默认为1,当step位负数是,则为字符串反转
str.split(‘str’,count) 系统默认为空格,换行符为切割对象,默认次数为全部切割
6.遍历
for str in string:
print(str)
暂时总结这么多,有想到的再来做补充