文章目录
- 第六章 行为型模式(11种)
- 6.1 观察者模式
- 6.1.1 观察者模式介绍
- 6.1.2 观察者模式原理
- 6.1.3 观察者模式实现
- 6.1.4 观察者模式应用实例
- 6.1.5 观察者模式总结
- 6.2 模板方法模式
- 6.2.1 模板方法模式介绍
- 6.2.2 模板方法模式原理
- 6.2.3 模板方法模式实现
- 6.2.4 模板方法模式应用实例
- 6.2.5 模板方法模式总结
- 6.3 策略模式
- 6.3.1 策略模式概述
- 6.3.2 策略模式原理
- 6.3.3 策略模式实现
- 6.3.4 策略模式应用实例
- 6.3.5 策略模式总结
- 6.4 职责链模式
- 6.4.1 职责链模式介绍
- 6.4.2 职责链模式原理
- 6.4.3 职责链模式实现
- 6.4.4 职责链模式应用实例
- 6.4.5 职责链模式总结
- 6.5 状态模式
- 6.5.1 状态模式介绍
- 6.5.2 状态模式结构
- 6.5.3 状态模式实现
- 6.5.4 状态模式应用实例
- 6.5.5 状态模式总结
- 6.6 迭代器模式
- 6.6.1 迭代器模式介绍
- 6.6.2 迭代器模式原理
- 6.6.3 迭代器模式实现
- 6.6.4 迭代器模式应用实例
- 6.6.5 迭代器模式总结
- 6.7 访问者模式
- 6.7.1 访问者模式介绍
- 6.7.2 访问者模式原理
- 6.7.3 访问者模式实现
- 6.7.4 访问者模式总结
- 6.8 备忘录模式
- 6.8.1 备忘录模式介绍
- 6.8.2 备忘录模式原理
- 6.8.3 备忘录模式实现
- 6.8.4 备忘录模式应用实例
- 6.8.5 备忘录模式总结
- 6.9 命令模式
- 6.9.1 命令模式介绍
- 6.9.2 命令模式原理
- 6.9.3 命令模式实现
- 6.9.4 命令模式总结
- 7.0 解释器模式
- 7.0.1 解释器模式介绍
- 7.02 解释器模式原理
- 7.0.3 解释器模式实现
- 7.0.4 解释器模式总结
- 7.1 中介者模式
- 7.1.1 中介者模式介绍
- 7.1.2 中介者模式原理
- 7.1.3 中介者模式实现
- 7.1.4 中介者模式应用实例
- 7.1.5 中介者模式总结
- 第七章 开源实战
- 7.1 剖析Spring框架中用到的经典设计模式
- 7.1.1 Spring中工厂模式的应用
- 7.1.1.1 Spring中的Bean组件
- 7.1.1.2 Spring中的BeanFactory
- 7.1.1.3 Spring中的FactoryBean
- 7.1.2 Spring中观察者模式的应用
- 7.1.2.1 观察者模式与发布订阅模式的异同
- 7.1.2.2 Spring中的观察者模式
- 7.1.2.3 事件监听案例
- 7.1.2.4 事件机制工作流程
- 7.1.3 结合设计模式自定义SpringIOC
- 7.1.3.1 Spring IOC核心组件
- 7.1.3.2 IOC流程图
- 7.1.3.3 自定义SpringIOC
- 1) 创建与Bean相关的pojo类
- 2) 创建注册表相关的类
- 3) 创建解析器相关的类
- 4) 创建IOC容器相关的类
第六章 行为型模式(11种)
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。
行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分派行为,后者采用组合或聚合在对象间分配行为。由于组合关系或聚合关系比继承关系耦合度低,满足“合成复用原则”,所以对象行为模式比类行为模式具有更大的灵活性。
行为型模式分为:
- 观察者模式
- 模板方法模式
- 策略模式
- 职责链模式
- 状态模式
- 命令模式
- 中介者模式
- 迭代器模式
- 访问者模式
- 备忘录模式
- 解释器模式
以上 11 种行为型模式,除了模板方法模式和解释器模式是类行为型模式,其他的全部属于对象行为型模式。
6.1 观察者模式
6.1.1 观察者模式介绍
观察者模式的应用场景非常广泛,小到代码层面的解耦,大到架构层面的系统解耦,再或者 一些产品的设计思路,都有这种模式的影子.
现在我们常说的基于事件驱动的架构,其实也是观察者模式的一种最佳实践。当我们观察某一个对象时,对象传递出的每一个行为都被看成是一个事件,观察者通过处理每一个事件来完成自身的操作处理。
生活中也有许多观察者模式的应用,比如 汽车与红绿灯的关系,‘红灯停,绿灯行’,在这个过程中交通信号灯是汽车的观察目标,而汽车是观察者.

观察者模式(observer pattern)的原始定义是:定义对象之间的一对多依赖关系,这样当一个对象改变状态时,它的所有依赖项都会自动得到通知和更新。
解释一下上面的定义: 观察者模式它是用于建立一种对象与对象之间的依赖关系,一个对象发生改变时将自动通知其他对象,其他对象将相应的作出反应.
在观察者模式中发生改变的对象称为观察目标,而被通知的对象称为观察者,一个观察目标可以应对多个观察者,而且这些观察者之间可以没有任何相互联系,可以根据需要增加和删除观察者,使得系统更易于扩展.
观察者模式的别名有发布-订阅(Publish/Subscribe)模式,模型-视图(Model-View)模式、源-监听(Source-Listener) 模式等
6.1.2 观察者模式原理
观察者模式结构中通常包括: 观察目标和观察者两个继承层次结构.

在观察者模式中有如下角色:
- Subject:抽象主题(抽象被观察者),抽象主题角色把所有观察者对象保存在一个集合里,每个主题都可以有任意数量的观察者,抽象主题提供一个接口,可以增加和删除观察者对象。
- ConcreteSubject:具体主题(具体被观察者),该角色将有关状态存入具体观察者对象,在具体主题的内部状态发生改变时,给所有注册过的观察者发送通知。
- Observer:抽象观察者,是观察者的抽象类,它定义了一个更新接口,使得在得到主题更改通知时更新自己。
- ConcrereObserver:具体观察者,实现抽象观察者定义的更新接口,以便在得到主题更改通知时更新自身的状态。在具体观察者中维护一个指向具体目标对象的引用,它存储具体观察者的有关状态,这些状态需要与具体目标保持一致.
6.1.3 观察者模式实现
- 观察者
/**
* 抽象观察者
* @author spikeCong
* @date 2022/10/11
**/
public interface Observer {
//update方法: 为不同观察者的更新(响应)行为定义相同的接口,不同的观察者对该方法有不同的实现
public void update();
}
/**
* 具体观察者
* @author spikeCong
* @date 2022/10/11
**/
public class ConcreteObserverOne implements Observer {
@Override
public void update() {
//获取消息通知,执行业务代码
System.out.println("ConcreteObserverOne 得到通知!");
}
}
/**
* 具体观察者
* @author spikeCong
* @date 2022/10/11
**/
public class ConcreteObserverTwo implements Observer {
@Override
public void update() {
//获取消息通知,执行业务代码
System.out.println("ConcreteObserverTwo 得到通知!");
}
}
- 被观察者
/**
* 抽象目标类
* @author spikeCong
* @date 2022/10/11
**/
public interface Subject {
void attach(Observer observer);
void detach(Observer observer);
void notifyObservers();
}
/**
* 具体目标类
* @author spikeCong
* @date 2022/10/11
**/
public class ConcreteSubject implements Subject {
//定义集合,存储所有观察者对象
private ArrayList<Observer> observers = new ArrayList<>();
//注册方法,向观察者集合中增加一个观察者
@Override
public void attach(Observer observer) {
observers.add(observer);
}
//注销方法,用于从观察者集合中删除一个观察者
@Override
public void detach(Observer observer) {
observers.remove(observer);
}
//通知方法
@Override
public void notifyObservers() {
//遍历观察者集合,调用每一个观察者的响应方法
for (Observer obs : observers) {
obs.update();
}
}
}
- 测试类
public class Client {
public static void main(String[] args) {
//创建目标类(被观察者)
ConcreteSubject subject = new ConcreteSubject();
//注册观察者类,可以注册多个
subject.attach(new ConcreteObserverOne());
subject.attach(new ConcreteObserverTwo());
//具体主题的内部状态发生改变时,给所有注册过的观察者发送通知。
subject.notifyObservers();
}
}
6.1.4 观察者模式应用实例
接下来我们使用观察模式,来实现一个买房摇号的程序.摇号结束,需要通过短信告知用户摇号结果,还需要想MQ中保存用户本次摇号的信息.
1 ) 未使用设计模式
/**
* 模拟买房摇号服务
* @author spikeCong
* @date 2022/10/11
**/
public class DrawHouseService {
//摇号抽签
public String lots(String uId){
if(uId.hashCode() % 2 == 0){
return "恭喜ID为: " + uId + " 的用户,在本次摇号中中签! !";
}else{
return "很遗憾,ID为: " + uId + "的用户,您本次未中签! !";
}
}
}
public class LotteryResult {
private String uId; // 用户id
private String msg; // 摇号信息
private Date dataTime; // 业务时间
//get&set.....
}
/**
* 开奖服务接口
* @author spikeCong
* @date 2022/10/11
**/
public interface LotteryService {
//摇号相关业务
public LotteryResult lottery(String uId);
}
/**
* 开奖服务
* @author spikeCong
* @date 2022/10/11
**/
public class LotteryServiceImpl implements LotteryService {
//注入摇号服务
private DrawHouseService houseService = new DrawHouseService();
@Override
public LotteryResult lottery(String uId) {
//摇号
String result = houseService.lots(uId);
//发短信
System.out.println("发送短信通知用户ID为: " + uId + ",您的摇号结果如下: " + result);
//发送MQ消息
System.out.println("记录用户摇号结果(MQ), 用户ID:" + uId + ",摇号结果:" + result);
return new LotteryResult(uId,result,new Date());
}
}
@Test
public void test1(){
LotteryService ls = new LotteryServiceImpl();
String result = ls.lottery("1234567887654322");
System.out.println(result);
}
1 ) 使用观察者模式进行优化
上面的摇号业务中,摇号、发短信、发MQ消息是一个顺序调用的过程,但是除了摇号这个核心功能以外, 发短信与记录信息到MQ的操作都不是主链路的功能,需要单独抽取出来,这样才能保证在后面的开发过程中保证代码的可扩展性和可维护性.

- 事件监听
/**
* 事件监听接口
* @author spikeCong
* @date 2022/10/11
**/
public interface EventListener {
void doEvent(LotteryResult result);
}
/**
* 短信发送事件
* @author spikeCong
* @date 2022/10/11
**/
public class MessageEventListener implements EventListener {
@Override
public void doEvent(LotteryResult result) {
System.out.println("发送短信通知用户ID为: " + result.getuId() +
",您的摇号结果如下: " + result.getMsg());
}
}
/**
* MQ消息发送事件
* @author spikeCong
* @date 2022/10/11
**/
public class MQEventListener implements EventListener {
@Override
public void doEvent(LotteryResult result) {
System.out.println("记录用户摇号结果(MQ), 用户ID:" + result.getuId() +
",摇号结果:" + result.getMsg());
}
}
事件处理
/**
* 事件处理类
* @author spikeCong
* @date 2022/10/11
**/
public class EventManager {
public enum EventType{
MQ,Message
}
//监听器集合
Map<Enum<EventType>, List<EventListener>> listeners = new HashMap<>();
public EventManager(Enum<EventType>... operations) {
for (Enum<EventType> operation : operations) {
this.listeners.put(operation,new ArrayList<>());
}
}
/**
* 订阅
* @param eventType 事件类型
* @param listener 监听
*/
public void subscribe(Enum<EventType> eventType, EventListener listener){
List<EventListener> users = listeners.get(eventType);
users.add(listener);
}
/**
* 取消订阅
* @param eventType 事件类型
* @param listener 监听
*/
public void unsubscribe(Enum<EventType> eventType,EventListener listener){
List<EventListener> users = listeners.get(eventType);
users.remove(listener);
}
/**
* 通知
* @param eventType 事件类型
* @param result 结果
*/
public void notify(Enum<EventType> eventType, LotteryResult result){
List<EventListener> users = listeners.get(eventType);
for (EventListener listener : users) {
listener.doEvent(result);
}
}
}
摇号业务处理
/**
* 开奖服务接口
* @author spikeCong
* @date 2022/10/11
**/
public abstract class LotteryService{
private EventManager eventManager;
public LotteryService(){
//设置事件类型
eventManager = new EventManager(EventManager.EventType.MQ, EventManager.EventType.Message);
//订阅
eventManager.subscribe(EventManager.EventType.Message,new MessageEventListener());
eventManager.subscribe(EventManager.EventType.MQ,new MQEventListener());
}
public LotteryResult lotteryAndMsg(String uId){
LotteryResult result = lottery(uId);
//发送通知
eventManager.notify(EventManager.EventType.Message,result);
eventManager.notify(EventManager.EventType.MQ,result);
return result;
}
public abstract LotteryResult lottery(String uId);
}
/**
* 开奖服务
* @author spikeCong
* @date 2022/10/11
**/
public class LotteryServiceImpl extends LotteryService {
//注入摇号服务
private DrawHouseService houseService = new DrawHouseService();
@Override
public LotteryResult lottery(String uId) {
//摇号
String result = houseService.lots(uId);
return new LotteryResult(uId,result,new Date());
}
}
测试
@Test
public void test2(){
LotteryService ls = new LotteryServiceImpl();
LotteryResult result = ls.lotteryAndMsg("1234567887654322");
System.out.println(result);
}
6.1.5 观察者模式总结
1) 观察者模式的优点
- 降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。
- 被观察者发送通知,所有注册的观察者都会收到信息【可以实现广播机制】
2) 观察者模式的缺点
- 如果观察者非常多的话,那么所有的观察者收到被观察者发送的通知会耗时
- 如果被观察者有循环依赖的话,那么被观察者发送通知会使观察者循环调用,会导致系统崩溃
3 ) 观察者模式常见的使用场景
- 当一个对象状态的改变需要改变其他对象时。比如,商品库存数量发生变化时,需要通知商品详情页、购物车等系统改变数量。
- 一个对象发生改变时只想要发送通知,而不需要知道接收者是谁。比如,订阅微信公众号的文章,发送者通过公众号发送,订阅者并不知道哪些用户订阅了公众号。
- 需要创建一种链式触发机制时。比如,在系统中创建一个触发链,A 对象的行为将影响 B 对象,B 对象的行为将影响 C 对象……这样通过观察者模式能够很好地实现。
- 微博或微信朋友圈发送的场景。这是观察者模式的典型应用场景,一个人发微博或朋友圈,只要是关联的朋友都会收到通知;一旦取消关注,此人以后将不会收到相关通知。
- 需要建立基于事件触发的场景。比如,基于 Java UI 的编程,所有键盘和鼠标事件都由它的侦听器对象和指定函数处理。当用户单击鼠标时,订阅鼠标单击事件的函数将被调用,并将所有上下文数据作为方法参数传递给它。
4 ) JDK 中对观察者模式的支持
JDK中提供了Observable类以及Observer接口,它们构成了JDK对观察者模式的支持.
-
java.util.Observer接口: 该接口中声明了一个方法,它充当抽象观察者,其中声明了一个update方法.void update(Observable o, Object arg); -
java.util.Observable类: 充当观察目标类(被观察类) , 在该类中定义了一个Vector集合来存储观察者对象.下面是它最重要的 3 个方法。- void addObserver(Observer o) 方法:用于将新的观察者对象添加到集合中。
-
void notifyObservers(Object arg) 方法:调用集合中的所有观察者对象的 update方法,通知它们数据发生改变。通常越晚加入集合的观察者越先得到通知。
-
void setChange() 方法:用来设置一个 boolean 类型的内部标志,注明目标对象发生了变化。当它为true时,notifyObservers() 才会通知观察者。
用户可以直接使用Observer接口和Observable类作为观察者模式的抽象层,再自定义具体观察者类和具体观察目标类,使用JDK中提供的这两个类可以更加方便的实现观察者模式.
6.2 模板方法模式
6.2.1 模板方法模式介绍
模板方法模式(template method pattern)原始定义是:在操作中定义算法的框架,将一些步骤推迟到子类中。模板方法让子类在不改变算法结构的情况下重新定义算法的某些步骤。
模板方法中的算法可以理解为广义上的业务逻辑,并不是特指某一个实际的算法.定义中所说的算法的框架就是模板, 包含算法框架的方法就是模板方法.
例如: 我们去医院看病一般要经过以下4个流程:挂号、取号、排队、医生问诊等,其中挂号、 取号 、排队对每个病人是一样的,可以在父类中实现,但是具体医生如何根据病情开药每个人都是不一样的,所以开药这个操作可以延迟到子类中实现。

模板方法模式是一种基于继承的代码复用技术,它是一种类行为模式. 模板方法模式其结构中只存在父类与子类之间的继承关系.
模板方法的作用主要是提高程序的复用性和扩展性:
- 复用指的是,所有的子类可以复用父类中提供的模板方法代码
- 扩展指的是,框架通过模板模式提供功能扩展点,让框架用户可以在不修改框架源码的情况下,基于扩展点定制化框架的功能.
6.2.2 模板方法模式原理
模板方法模式的定位很清楚,就是为了解决算法框架这类特定的问题,同时明确表示需要使用继承的结构。

模板方法(Template Method)模式包含以下主要角色:
- 抽象父类:定义一个算法所包含的所有步骤,并提供一些通用的方法逻辑。
- 具体子类:继承自抽象父类,根据需要重写父类提供的算法步骤中的某些步骤。
抽象类(Abstract Class):负责给出一个算法的轮廓和骨架。它由一个模板方法和若干个基本方法构成。
-
模板方法:定义了算法的骨架,按某种顺序调用其包含的基本方法。
-
基本方法:是实现算法各个步骤的方法,是模板方法的组成部分。基本方法又可以分为三种:
-
抽象方法(Abstract Method) :一个抽象方法由抽象类声明、由其具体子类实现。
-
具体方法(Concrete Method) :一个具体方法由一个抽象类或具体类声明并实现,其子类可以进行覆盖也可以直接继承。
-
钩子方法(Hook Method) :在抽象类中已经实现,包括用于判断的逻辑方法和需要子类重写的空方法两种。
一般钩子方法是用于判断的逻辑方法,这类方法名一般为isXxx,返回值类型为boolean类型。
-
6.2.3 模板方法模式实现
UML类图对应的代码实现
/**
* 抽象父类
* @author spikeCong
* @date 2022/10/12
**/
public abstract class AbstractClassTemplate {
void step1(String key){
System.out.println("在模板类中 -> 执行步骤1");
if(step2(key)){
step3();
}else{
step4();
}
step5();
}
boolean step2(String key){
System.out.println("在模板类中 -> 执行步骤2");
if("x".equals(key)){
return true;
}
return false;
}
abstract void step3();
abstract void step4();
void step5(){
System.out.println("在模板类中 -> 执行步骤5");
}
void run(String key){
step1(key);
}
}
public class ConcreteClassA extends AbstractClassTemplate{
@Override
void step3() {
System.out.println("在子类A中 -> 执行步骤 3");
}
@Override
void step4() {
System.out.println("在子类A中 -> 执行步骤 4");
}
}
public class ConcreteClassB extends AbstractClassTemplate {
@Override
void step3() {
System.out.println("在子类B中 -> 执行步骤 3");
}
@Override
void step4() {
System.out.println("在子类B中 -> 执行步骤 4");
}
}
public class Test01 {
public static void main(String[] args) {
AbstractClassTemplate concreteClassA = new ConcreteClassA();
concreteClassA.run("");
System.out.println("===========");
AbstractClassTemplate concreteClassB = new ConcreteClassB();
concreteClassB.run("x");
}
}
// 输出结果
在模板类中 -> 执行步骤1
在模板类中 -> 执行步骤2
在子类A中 -> 执行步骤 4
在模板类中 -> 执行步骤5
===========
在模板类中 -> 执行步骤1
在模板类中 -> 执行步骤2
在子类B中 -> 执行步骤 3
在模板类中 -> 执行步骤5
6.2.4 模板方法模式应用实例
P2P公司的借款系统中有一个利息计算模块,利息的计算流程是这样的:
- 用户登录系统,登录时需要输入账号密码,如果登录失败(比如用户密码错误),系统需要给出提示
- 如果用户登录成功,则根据用户的借款的类型不同,使用不同的利息计算方式进行计算
- 系统需要显示利息.
/**
* 账户抽象类
* @author spikeCong
* @date 2022/10/12
**/
public abstract class Account {
//step1 具体方法-验证用户信息是否正确
public boolean validate(String account,String password){
System.out.println("账号: " + account + ",密码: " + password);
if(account.equalsIgnoreCase("tom") &&
password.equalsIgnoreCase("123456")){
return true;
}else{
return false;
}
}
//step2 抽象方法-计算利息
public abstract void calculate();
//step3 具体方法-显示利息
public void display(){
System.out.println("显示利息!");
}
//模板方法
public void handle(String account,String password){
if(!validate(account,password)){
System.out.println("账户或密码错误!!");
return;
}
calculate();
display();
}
}
/**
* 借款一个月
* @author spikeCong
* @date 2022/10/12
**/
public class LoanOneMonth extends Account{
@Override
public void calculate() {
System.out.println("借款周期30天,利率为10%!");
}
}
/**
* 借款七天
* @author spikeCong
* @date 2022/10/12
**/
public class LoanSevenDays extends Account{
@Override
public void calculate() {
System.out.println("借款周期7天,无利息!仅收取贷款金额1%的服务费!");
}
@Override
public void display() {
System.out.println("七日内借款无利息!");
}
}
public class Client {
public static void main(String[] args) {
Account a1 = new LoanSevenDays();
a1.handle("tom","12345");
System.out.println("==========================");
Account a2 = new LoanOneMonth();
a2.handle("tom","123456");
}
}
6.2.5 模板方法模式总结
优点:
-
在父类中形式化的定义一个算法,而由它的子类来实现细节处理,在子类实现详细的处理代码时,并不会改变父类算法中步骤的执行顺序.
-
模板方法可以实现一种反向的控制结构,通过子类覆盖父类的钩子方法,来决定某一个特定步骤是否需要执行
-
在模板方法模式中可以通过子类来覆盖父类的基本方法,不同的子类可以提供基本方法的不同实现,更换和增加新的子类很方便,符合单一职责原则和开闭原则.
缺点:
- 对每个不同的实现都需要定义一个子类,这会导致类的个数增加,系统更加庞大,设计也更加抽象。
- 父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致一种反向的控制结构,它提高了代码阅读的难度。
模板方法模式的使用场景一般有:
- 多个类有相同的方法并且逻辑可以共用时;
- 将通用的算法或固定流程设计为模板,在每一个具体的子类中再继续优化算法步骤或流程步骤时;
- 重构超长代码时,发现某一个经常使用的公有方法。
6.3 策略模式
6.3.1 策略模式概述
策略模式(strategy pattern)的原始定义是:定义一系列算法,将每一个算法封装起来,并使它们可以相互替换。策略模式让算法可以独立于使用它的客户端而变化。
其实我们在现实生活中常常遇到实现某种目标存在多种策略可供选择的情况,例如,出行旅游可以乘坐飞机、乘坐火车、骑自行车或自己开私家车等。

在软件开发中,经常会遇到这种情况,开发一个功能可以通过多个算法去实现,我们可以将所有的算法集中在一个类中,在这个类中提供多个方法,每个方法对应一个算法, 或者我们也可以将这些算法都封装在一个统一的方法中,使用if…else…等条件判断语句进行选择.但是这两种方式都存在硬编码的问题,后期需要增加算法就需要修改源代码,这会导致代码的维护变得困难.
比如网购,你可以选择工商银行、农业银行、建设银行等等,但是它们提供的算法都是一致的,就是帮你付款。

在软件开发中也会遇到相似的情况,当实现某一个功能存在多种算法或者策略,我们可以根据环境或者条件的不同选择不同的算法或者策略来完成该功能。
6.3.2 策略模式原理
在策略模式中可以定义一些独立的类来封装不同的算法,每一个类封装一种具体的算法,在这里每一个封装算法的类都可以被称为一种策略,为了保证这些策略在使用时具有一致性,一般会提供一个抽象的策略类来做算法的声明.而每种算法对应一个具体的策略类.

策略模式的主要角色如下:
- 抽象策略(Strategy)类:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
- 具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现或行为。
- 环境或上下文(Context)类:是使用算法的角色, 持有一个策略类的引用,最终给客户端调用。
6.3.3 策略模式实现
策略模式的本质是通过Context类来作为中心控制单元,对不同的策略进行调度分配。
/**
* 抽象策略类
* @author spikeCong
* @date 2022/10/13
**/
public interface Strategy {
void algorithm();
}
public class ConcreteStrategyA implements Strategy {
@Override
public void algorithm() {
System.out.println("执行策略A");
}
}
public class ConcreteStrategyB implements Strategy {
@Override
public void algorithm() {
System.out.println("执行策略B");
}
}
/**
* 环境类
* @author spikeCong
* @date 2022/10/13
**/
public class Context {
//维持一个对抽象策略类的引用
private Strategy strategy;
public Context(Strategy strategy) {
this.strategy = strategy;
}
//调用策略类中的算法
public void algorithm(){
strategy.algorithm();
}
}
public class Client {
public static void main(String[] args) {
Strategy strategyA = new ConcreteStrategyA();
Context context = new Context(strategyA); //可以在运行时指定类型,通过配置文件+反射机制实现
context.algorithm();
}
}
6.3.4 策略模式应用实例
面试问题: 如何用设计模式消除代码中的if-else
物流行业中,通常会涉及到EDI报文(XML格式文件)传输和回执接收,每发送一份EDI报文,后续都会收到与之关联的回执(标识该数据在第三方系统中的流转状态)。
这里列举几种回执类型:MT1101、MT2101、MT4101、MT8104,系统在收到不同的回执报文后,会执行对应的业务逻辑处理。我们就业回执处理为演示案例
1 ) 不使用设计模式
- 回执类
/**
* 回执信息
* @author spikeCong
* @date 2022/10/13
**/
public class Receipt {
private String message; //回执信息
private String type; //回执类型(MT1101、MT2101、MT4101、MT8104)
public Receipt() {
}
public Receipt(String message, String type) {
this.message = message;
this.type = type;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
}
- 回执生成器
public class ReceiptBuilder {
public static List<Receipt> genReceiptList(){
//模拟回执信息
List<Receipt> receiptList = new ArrayList<>();
receiptList.add(new Receipt("MT1101回执","MT1011"));
receiptList.add(new Receipt("MT2101回执","MT2101"));
receiptList.add(new Receipt("MT4101回执","MT4101"));
receiptList.add(new Receipt("MT8104回执","MT8104"));
//......
return receiptList;
}
}
- 客户端
public class Client {
public static void main(String[] args) {
List<Receipt> receiptList = ReceiptBuilder.genReceiptList();
//循环判断
for (Receipt receipt : receiptList) {
if("MT1011".equals(receipt.getType())){
System.out.println("接收到MT1011回执!");
System.out.println("解析回执内容");
System.out.println("执行业务逻辑A"+"\n");
}else if("MT2101".equals(receipt.getType())){
System.out.println("接收到MT2101回执!");
System.out.println("解析回执内容");
System.out.println("执行业务逻辑B"+"\n");
}else if("MT4101".equals(receipt.getType())) {
System.out.println("接收到MT4101回执!");
System.out.println("解析回执内容");
System.out.println("执行业务逻辑C"+"\n");
}else if("MT8104".equals(receipt.getType())) {
System.out.println("接收到MT8104回执!");
System.out.println("解析回执内容");
System.out.println("执行业务逻辑D");
}
//......
}
}
}
2 ) 使用策略模式进行优化
通过策略模式, 将所有的if-else分支的业务逻辑抽取为各种策略类,让客户端去依赖策略接口,保证具体策略类的改变不影响客户端.
- 策略接口
/**
* 回执处理策略接口
* @author spikeCong
* @date 2022/10/13
**/
public interface ReceiptHandleStrategy {
void handleReceipt(Receipt receipt);
}
- 具体策略类
public class Mt1011ReceiptHandleStrategy implements ReceiptHandleStrategy {
@Override
public void handleReceipt(Receipt receipt) {
System.out.println("解析报文MT1011: " + receipt.getMessage());
}
}
public class Mt2101ReceiptHandleStrategy implements ReceiptHandleStrategy {
@Override
public void handleReceipt(Receipt receipt) {
System.out.println("解析报文MT2101: " + receipt.getMessage());
}
}
......
- 策略上下文类(策略接口的持有者)
/**
* 上下文类,持有策略接口
* @author spikeCong
* @date 2022/10/13
**/
public class ReceiptStrategyContext {
private ReceiptHandleStrategy receiptHandleStrategy;
public void setReceiptHandleStrategy(ReceiptHandleStrategy receiptHandleStrategy) {
this.receiptHandleStrategy = receiptHandleStrategy;
}
//调用策略类中的方法
public void handleReceipt(Receipt receipt){
if(receipt != null){
receiptHandleStrategy.handleReceipt(receipt);
}
}
}
- 策略工厂
public class ReceiptHandleStrategyFactory {
public ReceiptHandleStrategyFactory() {
}
//使用Map集合存储策略信息,彻底消除if...else
private static Map<String,ReceiptHandleStrategy> strategyMap;
//初始化具体策略,保存到map集合
public static void init(){
strategyMap = new HashMap<>();
strategyMap.put("MT1011",new Mt1011ReceiptHandleStrategy());
strategyMap.put("MT2101",new Mt2101ReceiptHandleStrategy());
}
//根据回执类型获取对应策略类对象
public static ReceiptHandleStrategy getReceiptHandleStrategy(String receiptType){
return strategyMap.get(receiptType);
}
}
- 客户端
public class Client {
public static void main(String[] args) {
//模拟回执
List<Receipt> receiptList = ReceiptBuilder.genReceiptList();
//策略上下文
ReceiptStrategyContext context = new ReceiptStrategyContext();
//策略模式将策略的 定义、创建、使用这三部分进行了解耦
for (Receipt receipt : receiptList) {
//获取置策略
ReceiptHandleStrategyFactory.init();
ReceiptHandleStrategy strategy = ReceiptHandleStrategyFactory.getReceiptHandleStrategy(receipt.getType());
//设置策略
context.setReceiptHandleStrategy(strategy);
//执行策略
context.handleReceipt(receipt);
}
}
}
经过上面的改造,我们已经消除了if-else的结构,每当新来了一种回执,只需要添加新的回执处理策略,并修改ReceiptHandleStrategyFactory中的Map集合。如果要使得程序符合开闭原则,则需要调整ReceiptHandleStrategyFactory中处理策略的获取方式,通过反射的方式,获取指定包下的所有IReceiptHandleStrategy实现类,然后放到字典Map中去.
6.3.5 策略模式总结
1) 策略模式优点:
-
策略类之间可以自由切换
由于策略类都实现同一个接口,所以使它们之间可以自由切换。
-
易于扩展
增加一个新的策略只需要添加一个具体的策略类即可,基本不需要改变原有的代码,符合“开闭原则“
-
避免使用多重条件选择语句(if else),充分体现面向对象设计思想。
2) 策略模式缺点:
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。
- 策略模式将造成产生很多策略类,可以通过使用享元模式在一定程度上减少对象的数量。
3) 策略模式使用场景
-
一个系统需要动态地在几种算法中选择一种时,可将每个算法封装到策略类中。
策略模式最大的作用在于分离使用算法的逻辑和算法自身实现的逻辑,这样就意味着当我们想要优化算法自身的实现逻辑时就变得非常便捷,一方面可以采用最新的算法实现逻辑,另一方面可以直接弃用旧算法而采用新算法。使用策略模式能够很方便地进行替换。
-
一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
在实际开发中,有许多算法可以实现某一功能,如查找、排序等,通过 if-else 等条件判断语句来进行选择非常方便。但是这就会带来一个问题:当在这个算法类中封装了大量查找算法时,该类的代码就会变得非常复杂,维护也会突然就变得非常困难。虽然策略模式看上去比较笨重,但实际上在每一次新增策略时都通过新增类来进行隔离,短期虽然不如直接写 if-else 来得效率高,但长期来看,维护单一的简单类耗费的时间其实远远低于维护一个超大的复杂类。
-
系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
如果我们不希望客户知道复杂的、与算法相关的数据结构,在具体策略类中封装算法与相关数据结构,可以提高算法的保密性与安全性.
设计原则和思想其实比设计模式更加的普适和重要,掌握了代码的设计原则和思想,我们自然而然的就可以使用到设计模式,还有可能自己创建出一种新的设计模式.
6.4 职责链模式
6.4.1 职责链模式介绍
职责链模式(chain of responsibility pattern) 定义: 避免将一个请求的发送者与接收者耦合在一起,让多个对象都有机会处理请求.将接收请求的对象连接成一条链,并且沿着这条链传递请求,直到有一个对象能够处理它为止.
在职责链模式中,多个处理器(也就是刚刚定义中说的“接收对象”)依次处理同一个请 求。一个请求先经过 A 处理器处理,然后再把请求传递给 B 处理器,B 处理器处理完后再 传递给 C 处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职 责,所以叫作职责链模式。

6.4.2 职责链模式原理
职责链模式结构

职责链模式主要包含以下角色:
- 抽象处理者(Handler)角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接(链上的每个处理者都有一个成员变量来保存对于下一处理者的引用,比如上图中的successor) 。
- 具体处理者(Concrete Handler)角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
- 客户类(Client)角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
6.4.3 职责链模式实现
责任链模式的实现非常简单,每一个具体的处理类都会保存在它之后的下一个处理类。当处理完成后,就会调用设置好的下一个处理类,直到最后一个处理类不再设置下一个处理类,这时处理链条全部完成。
public class RequestData {
private String data;
public RequestData(String data) {
this.data = data;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
}
/**
* 抽象处理者类
* @author spikeCong
* @date 2022/10/14
**/
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor){
this.successor = successor;
}
public abstract void handle(RequestData requestData);
}
public class HandlerA extends Handler {
@Override
public void handle(RequestData requestData) {
System.out.println("HandlerA 执行代码逻辑! 处理: " + requestData.getData());
requestData.setData(requestData.getData().replace("A",""));
if(successor != null){
successor.handle(requestData);
}else{
System.out.println("执行中止!");
}
}
}
public class HandlerB extends Handler {
@Override
public void handle(RequestData requestData) {
System.out.println("HandlerB 执行代码逻辑! 处理: " + requestData.getData());
requestData.setData(requestData.getData().replace("B",""));
if(successor != null){
successor.handle(requestData);
}else{
System.out.println("执行中止!");
}
}
}
public class HandlerC extends Handler {
@Override
public void handle(RequestData requestData) {
System.out.println("HandlerC 执行代码逻辑! 处理: " + requestData.getData());
requestData.setData(requestData.getData());
if(successor != null){
successor.handle(requestData);
}else{
System.out.println("执行中止!");
}
}
}
public class Client {
public static void main(String[] args) {
Handler h1 = new HandlerA();
Handler h2 = new HandlerB();
Handler h3 = new HandlerC();
h1.setSuccessor(h2);
h2.setSuccessor(h3);
RequestData requestData = new RequestData("请求数据ABCDE");
h1.handle(requestData);
}
}
6.4.4 职责链模式应用实例
接下来我们模拟有一个双11期间,业务系统审批的流程,临近双十一公司会有陆续有一些新的需求上线,为了保证线上系统的稳定,我们对上线的审批流畅做了严格的控制.审批的过程会有不同级别的负责人加入进行审批(平常系统上线只需三级负责人审批即可,双十一前后需要二级或一级审核人参与审批),接下来我们就使用职责链模式来设计一下此功能.

1) 不使用设计模式
/**
* 审核信息
* @author spikeCong
* @date 2022/10/14
**/
public class AuthInfo {
private String code;
private String info ="";
public AuthInfo(String code, String... infos) {
this.code = code;
for (String str : infos) {
info = this.info.concat(str +" ");
}
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public String getInfo() {
return info;
}
public void setInfo(String info) {
this.info = info;
}
@Override
public String toString() {
return "AuthInfo{" +
"code='" + code + '\'' +
", info='" + info + '\'' +
'}';
}
}
/**
* 模拟审核服务
* @author spikeCong
* @date 2022/10/14
**/
public class AuthService {
//审批信息 审批人Id+申请单Id
private static Map<String,Date> authMap = new HashMap<String, Date>();
/**
* 审核流程
* @param uId 审核人id
* @param orderId 审核单id
*/
public static void auth(String uId, String orderId){
System.out.println("进入审批流程,审批人ID: " + uId);
authMap.put(uId.concat(orderId),new Date());
}
//查询审核结果
public static Date queryAuthInfo(String uId, String orderId){
return authMap.get(uId.concat(orderId)); //key=审核人id+审核单子id
}
}
public class AuthController {
//审核接口
public AuthInfo doAuth(String name, String orderId, Date authDate) throws ParseException {
//三级审批
Date date = null;
//查询是否存在审核信息,查询条件: 审核人ID+订单ID,返回Map集合中的Date
date = AuthService.queryAuthInfo("1000013", orderId);
//如果为空,封装AuthInfo信息(待审核)返回
if(date == null){
return new AuthInfo("0001","单号: "+orderId,"状态: 等待三级审批负责人进行审批");
}
//二级审批
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 时间格式化
//二级审核人主要审核双十一之前, 11-01 ~ 11-10号的请求,所以要对传入的审核时间进行判断
//审核时间 大于 2022-11-01 并且 小于 2022-11-10,Date1.after(Date2),当Date1大于Date2时,返回TRUE,Date1.before(Date2),当Date1小于Date2时,返回TRUE
if(authDate.after(f.parse("2022-11-01 00:00:00")) && authDate.before(f.parse("2022-11-10 00:00:00"))){
//条件成立,查询二级审核的审核信息
date = AuthService.queryAuthInfo("1000012",orderId);
//如果为空,还是待二级审核人审核状态
if(date == null){
return new AuthInfo("0001","单号: "+orderId,"状态: 等待二级审批负责人进行审批");
}
}
//一级审批
//审核范围是在11-11日 ~ 11-31日
if(authDate.after(f.parse("2022-11-11 00:00:00")) && authDate.before(f.parse("2022-11-31 00:00:00"))){
date = AuthService.queryAuthInfo("1000011",orderId);
if(date == null){
return new AuthInfo("0001","单号: "+orderId,"状态: 等待一级审批负责人进行审批");
}
}
return new AuthInfo("0001","单号: "+orderId,"申请人:"+ name +", 状态: 审批完成!");
}
}
public class Client {
public static void main(String[] args) throws ParseException {
AuthController controller = new AuthController();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = sdf.parse("2022-11-12 00:00:00");
//设置申请流程
//三级审核
//1.调用doAuth方法,模拟发送申请人相关信息
AuthInfo info1 = controller.doAuth("研发小周", "100001000010000", date);
System.out.println("当前审核状态: " + info1.getInfo());
/**
* 2.模拟进行审核操作, 虚拟审核人ID: 1000013
* 调用auth() 方法进行审核操作, 就是向Map中添加一个 审核人ID和申请单ID
*/
AuthService.auth("1000013", "100001000010000");
System.out.println("三级负责人审批完成,审批人: 王工");
System.out.println("===========================================================================");
//二级审核
//1.调用doAuth方法,模拟发送申请人相关信息
AuthInfo info2 = controller.doAuth("研发小周", "100001000010000", date);
System.out.println("当前审核状态: " + info2.getInfo());
/**
* 2.模拟进行审核操作, 虚拟审核人ID: 1000012
* 调用auth() 方法进行审核操作, 就是向Map中添加一个 审核人ID和申请单ID
*/
AuthService.auth("1000012", "100001000010000");
System.out.println("二级负责人审批完成,审批人: 张经理");
System.out.println("===========================================================================");
//一级审核
//1.调用doAuth方法,模拟发送申请人相关信息
AuthInfo info3 = controller.doAuth("研发小周", "100001000010000", date);
System.out.println("当前审核状态: " + info3.getInfo());
/**
* 2.模拟进行审核操作, 虚拟审核人ID: 1000012
* 调用auth() 方法进行审核操作, 就是向Map中添加一个 审核人ID和申请单ID
*/
AuthService.auth("1000011", "100001000010000");
System.out.println("一级负责人审批完成,审批人: 罗总");
}
}
2 ) 职责链模式重构代码
下图是为当前业务设计的责任链结构,统一抽象类AuthLink 下 有三个子类,将三个子类的执行通过编排,模拟出一条链路,这个链路就是业务中的责任链.

/**
* 抽象审核链类
*/
public abstract class AuthLink {
protected Logger logger = LoggerFactory.getLogger(AuthLink.class);
protected SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
protected String levelUserId; //审核人ID
protected String levelUserName; //审核人姓名
protected AuthLink next; //持有下一个处理类的引用
public AuthLink(String levelUserId, String levelUserName) {
this.levelUserId = levelUserId;
this.levelUserName = levelUserName;
}
//获取下一个处理类
public AuthLink getNext() {
return next;
}
//责任链中添加处理类
public AuthLink appendNext(AuthLink next) {
this.next = next;
return this;
}
//抽象审核方法
public abstract AuthInfo doAuth(String uId, String orderId, Date authDate);
}
/*
* 一级负责人
*/
public class Level1AuthLink extends AuthLink {
private Date beginDate = f.parse("2020-11-11 00:00:00");
private Date endDate = f.parse("2020-11-31 23:59:59");
public Level1AuthLink(String levelUserId, String levelUserName) throws ParseException {
super(levelUserId, levelUserName);
}
@Override
public AuthInfo doAuth(String uId, String orderId, Date authDate) {
Date date = AuthService.queryAuthInfo(levelUserId, orderId);
if (null == date) {
return new AuthInfo("0001", "单号:", orderId, " 状态:待一级审批负责人 ", levelUserName);
}
AuthLink next = super.getNext();
if (null == next) {
return new AuthInfo("0000", "单号:", orderId, " 状态:一级审批完成", " 时间:", f.format(date), " 审批人:", levelUserName);
}
if (authDate.before(beginDate) || authDate.after(endDate)) {
return new AuthInfo("0000", "单号:", orderId, " 状态:一级审批完成", " 时间:", f.format(date), " 审批人:", levelUserName);
}
return next.doAuth(uId, orderId, authDate);
}
}
/**
* 二级负责人
*/
public class Level2AuthLink extends AuthLink {
private Date beginDate = f.parse("2020-11-11 00:00:00");
private Date endDate = f.parse("2020-11-31 23:59:59");
public Level2AuthLink(String levelUserId, String levelUserName) throws ParseException {
super(levelUserId, levelUserName);
}
public AuthInfo doAuth(String uId, String orderId, Date authDate) {
Date date = AuthService.queryAuthInfo(levelUserId, orderId);
if (null == date) {
return new AuthInfo("0001", "单号:", orderId, " 状态:待二级审批负责人 ", levelUserName);
}
AuthLink next = super.getNext();
if (null == next) {
return new AuthInfo("0000", "单号:", orderId, " 状态:二级审批完成", " 时间:", f.format(date), " 审批人:", levelUserName);
}
if (authDate.before(beginDate) || authDate.after(endDate) ) {
return new AuthInfo("0000", "单号:", orderId, " 状态:二级审批完成", " 时间:", f.format(date), " 审批人:", levelUserName);
}
return next.doAuth(uId, orderId, authDate);
}
}
/**
* 三级负责人
*/
public class Level3AuthLink extends AuthLink {
public Level3AuthLink(String levelUserId, String levelUserName) {
super(levelUserId, levelUserName);
}
public AuthInfo doAuth(String uId, String orderId, Date authDate) {
Date date = AuthService.queryAuthInfo(levelUserId, orderId);
if (null == date) {
return new AuthInfo("0001", "单号:", orderId, " 状态:待三级审批负责人 ", levelUserName);
}
AuthLink next = super.getNext();
if (null == next) {
return new AuthInfo("0000", "单号:", orderId, " 状态:三级审批完成", " 时间:", f.format(date), " 审批人:", levelUserName);
}
return next.doAuth(uId, orderId, authDate);
}
}
测试
public class Client {
private Logger logger = LoggerFactory.getLogger(ApiTest.class);
@Test
public void test_AuthLink() throws ParseException {
AuthLink authLink = new Level3AuthLink("1000013", "王工")
.appendNext(new Level2AuthLink("1000012", "张经理")
.appendNext(new Level1AuthLink("1000011", "段总")));
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date currentDate = f.parse("2020-11-18 23:49:46");
logger.info("测试结果:{}", JSON.toJSONString(authLink.doAuth("研发牛马", "1000998004813441", currentDate)));
// 模拟三级负责人审批
AuthService.auth("1000013", "1000998004813441");
logger.info("测试结果:{}", "模拟三级负责人审批,王工");
logger.info("测试结果:{}", JSON.toJSONString(authLink.doAuth("研发牛马", "1000998004813441", currentDate)));
// 模拟二级负责人审批
AuthService.auth("1000012", "1000998004813441");
logger.info("测试结果:{}", "模拟二级负责人审批,张经理");
logger.info("测试结果:{}", JSON.toJSONString(authLink.doAuth("研发牛马", "1000998004813441", currentDate)));
// 模拟一级负责人审批
AuthService.auth("1000011", "1000998004813441");
logger.info("测试结果:{}", "模拟一级负责人审批,段总");
logger.info("测试结果:{}", JSON.toJSONString(authLink.doAuth("研发牛马", "1000998004813441", currentDate)));
}
}
从上面的代码结果看,我们的责任链已经生效,按照责任链的结构一层一层审批.当工作流程发生变化,可以动态地改变链内的成员或者修改它们的次序,也可动态地新增或者删除责任。并且每个类只需要处理自己该处理的工作,不能处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
6.4.5 职责链模式总结
1) 职责链模式的优点:
-
降低了对象之间的耦合度
该模式降低了请求发送者和接收者的耦合度。
-
增强了系统的可扩展性
可以根据需要增加新的请求处理类,满足开闭原则。
-
增强了给对象指派职责的灵活性
当工作流程发生变化,可以动态地改变链内的成员或者修改它们的次序,也可动态地新增或者删除责任。
-
责任链简化了对象之间的连接
一个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
-
责任分担
每个类只需要处理自己该处理的工作,不能处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
2) 职责链模式的缺点:
- 不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
- 对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
3) 使用场景分析
责任链模式常见的使用场景有以下几种情况。
- 在运行时需要动态使用多个关联对象来处理同一次请求时。比如,请假流程、员工入职流程、编译打包发布上线流程等。
- 不想让使用者知道具体的处理逻辑时。比如,做权限校验的登录拦截器。
- 需要动态更换处理对象时。比如,工单处理系统、网关 API 过滤规则系统等。
- 职责链模式常被用在框架开发中,用来实现框架的过滤器、拦截器功能,让框架的使用者在不修改源码的情况下,添加新的过滤拦截功能.
6.5 状态模式
6.5.1 状态模式介绍
自然界很多事物都有多种状态,而且不同状态下会具有不同的行为,这些状态在特定条件下还会发生相互转换,比如水

在软件系统中,有些对象也像水一样具有多种状态,这些状态在某些情况下能够相互转换,而且对象在不同状态下也将具有不同的行为.
状态模式(state pattern)的定义: 允许一个对象在其内部状态改变时改变它的行为. 对象看起来似乎修改了它的类.
状态模式就是用于解决系统中复杂对象的状态转换以及不同状态下行为的封装问题. 状态模式将一个对象的状态从该对象中分离出来,封装到专门的状态类中(用类来表示状态) ,使得对象状态可以灵活变化.
6.5.2 状态模式结构
状态模式结构图:

从这个 UML 图中,我们能看出状态模式包含的关键角色有三个。
-
上下文信息类(Context):实际上就是存储当前状态的类,对外提供更新状态的操作。在该类中维护着一个抽象状态接口State实例,这个实例定义当前状态.
-
抽象状态类(State):可以是一个接口或抽象类,用于定义声明状态更新的操作方法有哪些,具体实现由子类完成。
-
具体状态类(StateA 等):实现抽象状态类定义的方法,根据具体的场景来指定对应状态改变后的代码实现逻辑。
6.5.3 状态模式实现
代码示例
/**
* 抽象状态接口
* @author spikeCong
* @date 2022/10/17
**/
public interface State {
//声明抽象方法,不同具体状态类可以有不同实现
void handle(Context context);
}
/**
* 上下文类
* @author spikeCong
* @date 2022/10/17
**/
public class Context {
private State currentState; //维持一个对状态对象的引用
public Context() {
this.currentState = null;
}
public State getCurrentState() {
return currentState;
}
public void setCurrentState(State currentState) {
this.currentState = currentState;
}
@Override
public String toString() {
return "Context{" +
"currentState=" + currentState +
'}';
}
}
public class ConcreteStateA implements State {
@Override
public void handle(Context context) {
System.out.println("进入状态模式A......");
context.setCurrentState(this);
}
@Override
public String toString() {
return "当前状态: ConcreteStateA";
}
}
public class ConcreteStateB implements State{
@Override
public void handle(Context context) {
System.out.println("进入状态模式B......");
context.setCurrentState(this);
}
@Override
public String toString() {
return "当前状态: ConcreteStateB";
}
}
public class Client {
public static void main(String[] args) {
Context context = new Context();
State state1 = new ConcreteStateA();
state1.handle(context);
System.out.println(context.getCurrentState().toString());
System.out.println("========================");
State state2 = new ConcreteStateB();
state2.handle(context);
System.out.println(context.getCurrentState().toString());
}
}
6.5.4 状态模式应用实例
模拟交通信号灯的状态转换. 交通信号灯一般包括了红、黄、绿3种颜色状态,不同状态之间的切换逻辑为: 红灯只能切换为黄灯,黄灯可以切换为绿灯或红灯,绿灯只能切换为黄灯.

1) 不使用设计模式
/**
* 交通灯类
* 红灯(禁行) ,黄灯(警示),绿灯(通行) 三种状态.
* @author spikeCong
* @date 2022/10/17
**/
public class TrafficLight {
//初始状态红灯
private String state = "红";
//切换为绿灯(通行)状态
public void switchToGreen(){
if("绿".equals(state)){//当前是绿灯
System.out.println("当前为绿灯状态,无需切换!");
}else if("红".equals(state)){
System.out.println("红灯不能切换为绿灯!");
}else if("黄".equals(state)){
state = "绿";
System.out.println("绿灯亮起...时长: 60秒");
}
}
//切换为黄灯(警示)状态
public void switchToYellow(){
if("黄".equals(state)){//当前是黄灯
System.out.println("当前为黄灯状态,无需切换!");
}else if("红".equals(state) || "绿".equals(state)){
state = "黄";
System.out.println("黄灯亮起...时长:10秒");
}
}
//切换为黄灯(警示)状态
public void switchToRed(){
if("红".equals(state)){//当前是绿灯
System.out.println("当前为红灯状态,无需切换!");
}else if("绿".equals(state)){
System.out.println("绿灯不能切换为红灯!");
}else if("黄".equals(state)){
state = "红";
System.out.println("红灯亮起...时长: 90秒");
}
}
}
问题: 状态切换的操作全部在一个类中,如果有很多的交通灯进行联动,这个程序的逻辑就会变得非常复杂,难以维护.
2) 使用状态模式,将交通灯的切换逻辑组织起来,把跟状态有关的内容从交通灯类里抽离出来,使用类来表示不同的状态.
/**
* 交通灯类
* 红灯(禁行) ,黄灯(警示),绿灯(通行) 三种状态.
* @author spikeCong
* @date 2022/10/17
**/
public class TrafficLight {
//初始状态红灯
State state = new Red();
public void setState(State state) {
this.state = state;
}
//切换为绿灯状态
public void switchToGreen(){
state.switchToGreen(this);
}
//切换为黄灯状态
public void switchToYellow(){
state.switchToYellow(this);
}
//切换为红灯状态
public void switchToRed(){
state.switchToRed(this);
}
}
/**
* 交通灯状态接口
* @author spikeCong
* @date 2022/10/17
**/
public interface State {
void switchToGreen(TrafficLight trafficLight); //切换为绿灯
void switchToYellow(TrafficLight trafficLight); //切换为黄灯
void switchToRed(TrafficLight trafficLight); //切换为红灯
}
/**
* 红灯状态类
* @author spikeCong
* @date 2022/10/17
**/
public class Red implements State {
@Override
public void switchToGreen(TrafficLight trafficLight) {
System.out.println("红灯不能切换为绿灯!");
}
@Override
public void switchToYellow(TrafficLight trafficLight) {
System.out.println("黄灯亮起...时长:10秒!");
}
@Override
public void switchToRed(TrafficLight trafficLight) {
System.out.println("已是红灯状态无须再切换!");
}
}
/**
* 绿灯状态类
* @author spikeCong
* @date 2022/10/17
**/
public class Green implements State {
@Override
public void switchToGreen(TrafficLight trafficLight) {
System.out.println("已是绿灯无须切换!");
}
@Override
public void switchToYellow(TrafficLight trafficLight) {
System.out.println("黄灯亮起...时长:10秒!");
}
@Override
public void switchToRed(TrafficLight trafficLight) {
System.out.println("绿灯不能切换为红灯!");
}
}
/**
* 黄灯状态类
* @author spikeCong
* @date 2022/10/17
**/
public class Yellow implements State {
@Override
public void switchToGreen(TrafficLight trafficLight) {
System.out.println("绿灯亮起...时长:60秒!");
}
@Override
public void switchToYellow(TrafficLight trafficLight) {
System.out.println("已是黄灯无须切换!");
}
@Override
public void switchToRed(TrafficLight trafficLight) {
System.out.println("红灯亮起...时长:90秒!");
}
}
public class Client {
public static void main(String[] args) {
TrafficLight trafficLight = new TrafficLight();
trafficLight.switchToYellow();
trafficLight.switchToGreen();
trafficLight.switchToRed();
}
}
通过代码重构,将"状态" 接口化、模块化,最终将它们从臃肿的交通类中抽了出来, 消除了原来TrafficLight类中的if…else,代码看起来干净而优雅.
6.5.5 状态模式总结
1) 状态模式的优点:
- 将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。
- 允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。
2) 状态模式的缺点:
- 状态模式的使用必然会增加系统类和对象的个数。
- 状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。
- 状态模式对"开闭原则"的支持并不太好 (添加新的状态类需要修改那些负责状态转换的源代码)。
3) 状态模式常见的使用场景:
- 对象根据自身状态的变化来进行不同行为的操作时, 比如,购物订单状态。
- 对象需要根据自身变量的当前值改变行为,不期望使用大量 if-else 语句时, 比如,商品库存状态。
- 对于某些确定的状态和行为,不想使用重复代码时, 比如,某一个会员当天的购物浏览记录。
6.6 迭代器模式
6.6.1 迭代器模式介绍
迭代器模式是我们学习一个设计时很少用到的、但编码实现时却经常使用到的行为型设计模式。在绝大多数编程语言中,迭代器已经成为一个基础的类库,直接用来遍历集合对象。在平时开发中,我们更多的是直接使用它,很少会从零去实现一个迭代器。
迭代器模式(Iterator pattern)又叫游标(Cursor)模式,它的原始定义是:迭代器提供一种对容器对象中的各个元素进行访问的方法,而又不需要暴露该对象的内部细节。

在软件系统中,容器对象拥有两个职责: 一是存储数据,而是遍历数据.从依赖性上看,前者是聚合对象的基本职责.而后者是可变化的,又是可分离的.因此可以将遍历数据的行为从容器中抽取出来,封装到迭代器对象中,由迭代器来提供遍历数据的行为,这将简化聚合对象的设计,更加符合单一职责原则
6.6.2 迭代器模式原理
迭代器模式结构图

迭代器模式主要包含以下角色:
- 抽象集合(Aggregate)角色:用于存储和管理元素对象, 定义存储、添加、删除集合元素的功能,并且声明了一个createIterator()方法用于创建迭代器对象。
- 具体集合(ConcreteAggregate)角色:实现抽象集合类,返回一个具体迭代器的实例。
- 抽象迭代器(Iterator)角色:定义访问和遍历聚合元素的接口,通常包含 hasNext()、next() 等方法。
- hasNext()函数用于判断集合中是否还有下一个元素
- next() 函数用于将游标后移一位元素
- currentItem() 函数,用来返回当前游标指向的元素
- 具体迭代器(Concretelterator)角色:实现抽象迭代器接口中所定义的方法,完成对集合对象的遍历,同时记录遍历的当前位置。
6.6.3 迭代器模式实现
/**
* 迭代器接口
* @author spikeCong
* @date 2022/10/18
**/
public interface Iterator<E> {
//判断集合中是否有下一个元素
boolean hasNext();
//将游标后移一位元素
void next();
//返回当前游标指定的元素
E currentItem();
}
/**
* 具体迭代器
* @author spikeCong
* @date 2022/10/18
**/
public class ConcreteIterator<E> implements Iterator<E>{
private int cursor; //游标
private ArrayList<E> arrayList; //容器
public ConcreteIterator(ArrayList<E> arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
}
@Override
public boolean hasNext() {
return cursor != arrayList.size();
}
@Override
public void next() {
cursor++;
}
@Override
public E currentItem() {
if(cursor >= arrayList.size()){
throw new NoSuchElementException();
}
return arrayList.get(cursor);
}
}
public class Test01 {
public static void main(String[] args) {
ArrayList<String> names = new ArrayList<>();
names.add("lisi");
names.add("zhangsan");
names.add("wangwu");
Iterator<String> iterator = new ConcreteIterator(names);
while(iterator.hasNext()){
System.out.println(iterator.currentItem());
iterator.next();
}
/**
* 使用ArrayList集合中的iterator()方法获取迭代器
* 将创建迭代器的方法放入集合容器中,这样做的好处是对客户端封装了迭代器的实现细节.
*/
java.util.Iterator<String> iterator1 = names.iterator();
while(iterator1.hasNext()){
System.out.println(iterator1.next());
iterator.next();
}
}
}
6.6.4 迭代器模式应用实例
为了帮助你更好地理解迭代器模式,下面我们还是通过一个简单的例子给大家演示一下
/**
* 抽象迭代器 IteratorIterator
* @author spikeCong
* @date 2022/10/18
**/
public interface IteratorIterator<E> {
void reset(); //重置为第一个元素
E next(); //获取下一个元素
E currentItem(); //检索当前元素
boolean hasNext(); //判断是否还有下一个元素存在
}
/**
* 抽象集合 ListList
* @author spikeCong
* @date 2022/10/18
**/
public interface ListList<E> {
//获取迭代器对象的抽象方法(面向接口编程)
IteratorIterator<E> Iterator();
}
/**
* 主题类
* @author spikeCong
* @date 2022/10/18
**/
public class Topic {
private String name;
public Topic(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
/**
* 具体迭代器
* @author spikeCong
* @date 2022/10/18
**/
public class TopicIterator implements IteratorIterator<Topic> {
//Topic数组
private Topic[] topics;
//记录存储位置
private int position;
public TopicIterator(Topic[] topics) {
this.topics = topics;
position = 0;
}
@Override
public void reset() {
position = 0;
}
@Override
public Topic next() {
return topics[position++];
}
@Override
public Topic currentItem() {
return topics[position];
}
@Override
public boolean hasNext() {
if(position >= topics.length){
return false;
}
return true;
}
}
/**
* 具体集合类
* @author spikeCong
* @date 2022/10/18
**/
public class TopicList implements ListList<Topic> {
private Topic[] topics;
public TopicList(Topic[] topics) {
this.topics = topics;
}
@Override
public IteratorIterator<Topic> Iterator() {
return new TopicIterator(topics);
}
}
public class Client {
public static void main(String[] args) {
Topic[] topics = new Topic[4];
topics[0] = new Topic("topic1");
topics[1] = new Topic("topic2");
topics[2] = new Topic("topic3");
topics[3] = new Topic("topic4");
TopicList topicList = new TopicList(topics);
IteratorIterator<Topic> iterator = topicList.Iterator();
while(iterator.hasNext()){
Topic t = iterator.next();
System.out.println(t.getName());
}
}
}
6.6.5 迭代器模式总结
1) 迭代器的优点:
- 迭代器模式支持以不同方式遍历一个集合对象,在同一个集合对象上可以定义多种遍历方式. 在迭代器模式中只需要用一个不同的迭代器来替换原有的迭代器,即可改变遍历算法,也可以自己定义迭代器的子类以支持新的遍历方式.
- 迭代器简化了集合类。由于引入了迭代器,在原有的集合对象中不需要再自行提供数据遍历等方法,这样可以简化集合类的设计。
- 在迭代器模式中,由于引入了抽象层,增加新的集合类和迭代器类都很方便,无须修改原有代码,满足 “基于接口编程而非实现” 和 “开闭原则” 的要求。
2) 迭代器的缺点:
- 由于迭代器模式将存储数据和遍历数据的职责分离,增加了类的个数,这在一定程度上增加了系统的复杂性。
- 抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展.`
3) 使用场景
-
减少程序中重复的遍历代码
对于放入一个集合容器中的多个对象来说,访问必然涉及遍历算法。如果我们不将遍历算法封装到容器里(比如,List、Set、Map 等),那么就需要使用容器的人自行去实现遍历算法,这样容易造成很多重复的循环和条件判断语句出现,不利于代码的复用和扩展,同时还会暴露不同容器的内部结构。而使用迭代器模式是将遍历算法作为容器对象自身的一种“属性方法”来使用,能够有效地避免写很多重复的代码,同时又不会暴露内部结构。
-
当需要为遍历不同的集合结构提供一个统一的接口时或者当访问一个集合对象的内容而无须暴露其内部细节的表示时。
迭代器模式把对不同集合类的访问逻辑抽象出来,这样在不用暴露集合内部结构的情况下,可以隐藏不同集合遍历需要使用的算法,同时还能够对外提供更为简便的访问算法接口。
6.7 访问者模式
6.7.1 访问者模式介绍
访问者模式在实际开发中使用的非常少,因为它比较难以实现并且应用该模式肯能会导致代码的可读性变差,可维护性变差,在没有特别必要的情况下,不建议使用访问者模式.
访问者模式(Visitor Pattern) 的原始定义是:允许在运行时将一个或多个操作应用于一组对象,将操作与对象结构分离。
这个定义会比较抽象,但是我们依然能看出两个关键点:
-
一个是: 运行时使用一组对象的一个或多个操作,比如,对不同类型的文件(.pdf、.xml、.properties)进行扫描;
-
另一个是: 分离对象的操作和对象本身的结构,比如,扫描多个文件夹下的多个文件,对于文件来说,扫描是额外的业务操作,如果在每个文件对象上都加一个扫描操作,太过于冗余,而扫描操作具有统一性,非常适合访问者模式。
访问者模式主要解决的是数据与算法的耦合问题, 尤其是在数据结构比较稳定,而算法多变的情况下.为了不污染数据本身,访问者会将多种算法独立归档,并在访问数据时根据数据类型自动切换到对应的算法,实现数据的自动响应机制,并确保算法的自由扩展.
6.7.2 访问者模式原理

访问者模式包含以下主要角色:
- 抽象访问者(Visitor)角色:可以是接口或者抽象类,定义了一系列操作方法,用来处理所有数据元素,通常为同名的访问方法,并以数据元素类作为入参来确定那个重载方法被调用.
- 具体访问者(ConcreteVisitor)角色:访问者接口的实现类,可以有多个实现,每个访问者都需要实现所有数据元素类型的访问重载方法.
- 抽象元素(Element)角色:被访问的数据元素接口,定义了一个接受访问者的方法(
accept),其意义是指,每一个元素都要可以被访问者访问。 - 具体元素(ConcreteElement)角色: 具体数据元素实现类,提供接受访问方法的具体实现,而这个具体的实现,通常情况下是使用访问者提供的访问该元素类的方法,其accept实现方法中调用访问者并将自己 “this” 传回。
- 对象结构(Object Structure)角色:包含所有可能被访问的数据对象的容器,可以提供数据对象的迭代功能,可以是任意类型的数据结构.
- 客户端 ( Client ) : 使用容器并初始化其中各类数据元素,并选择合适的访问者处理容器中的所有数据对象.
6.7.3 访问者模式实现
我们以超市购物为例,假设超市中的三类商品: 水果,糖果,酒水进行售卖. 我们可以忽略每种商品的计价方法,因为最终结账时由收银员统一集中处理,在商品类中添加计价方法是不合理的设计.我们先来定义糖果类和酒类、水果类.
/**
* 抽象商品父类
* @author spikeCong
* @date 2022/10/18
**/
public abstract class Product {
private String name; //商品名
private LocalDate producedDate; // 生产日期
private double price; //单品价格
public Product(String name, LocalDate producedDate, double price) {
this.name = name;
this.producedDate = producedDate;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public LocalDate getProducedDate() {
return producedDate;
}
public void setProducedDate(LocalDate producedDate) {
this.producedDate = producedDate;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
/**
* 糖果类
* @author spikeCong
* @date 2022/10/18
**/
public class Candy extends Product{
public Candy(String name, LocalDate producedDate, double price) {
super(name, producedDate, price);
}
}
/**
* 酒水类
* @author spikeCong
* @date 2022/10/18
**/
public class Wine extends Product{
public Wine(String name, LocalDate producedDate, double price) {
super(name, producedDate, price);
}
}
/**
* 水果类
* @author spikeCong
* @date 2022/10/18
**/
public class Fruit extends Product{
//重量
private float weight;
public Fruit(String name, LocalDate producedDate, double price, float weight) {
super(name, producedDate, price);
this.weight = weight;
}
public float getWeight() {
return weight;
}
public void setWeight(float weight) {
this.weight = weight;
}
}
访问者接口
- 收银员就类似于访问者,访问用户选择的商品,我们假设根据生产日期进行打折,过期商品不能够出售. 注意这种计价策略不适用于酒类,作为收银员要对不同商品应用不同的计价方法.
/**
* 访问者接口-根据入参不同调用对应的重载方法
* @author spikeCong
* @date 2022/10/18
**/
public interface Visitor {
public void visit(Candy candy); //糖果重载方法
public void visit(Wine wine); //酒类重载方法
public void visit(Fruit fruit); //水果重载方法
}
具体访问者
- 创建计价业务类,对三类商品进行折扣计价,折扣计价访问者的三个重载方法分别实现了3类商品的计价方法,体现了visit() 方法的多态性.
/**
* 折扣计价访问者类
* @author spikeCong
* @date 2022/10/18
**/
public class DiscountVisitor implements Visitor {
private LocalDate billDate;
public DiscountVisitor(LocalDate billDate) {
this.billDate = billDate;
System.out.println("结算日期: " + billDate);
}
@Override
public void visit(Candy candy) {
System.out.println("糖果: " + candy.getName());
//获取产品生产天数
long days = billDate.toEpochDay() - candy.getProducedDate().toEpochDay();
if(days > 180){
System.out.println("超过半年的糖果,请勿食用!");
}else{
double rate = 0.9;
double discountPrice = candy.getPrice() * rate;
System.out.println("糖果打折后的价格"+NumberFormat.getCurrencyInstance().format(discountPrice));
}
}
@Override
public void visit(Wine wine) {
System.out.println("酒类: " + wine.getName()+",无折扣价格!");
System.out.println("原价: "+NumberFormat.getCurrencyInstance().format(wine.getPrice()));
}
@Override
public void visit(Fruit fruit) {
System.out.println("水果: " + fruit.getName());
//获取产品生产天数
long days = billDate.toEpochDay() - fruit.getProducedDate().toEpochDay();
double rate = 0;
if(days > 7){
System.out.println("超过七天的水果,请勿食用!");
}else if(days > 3){
rate = 0.5;
}else{
rate = 1;
}
double discountPrice = fruit.getPrice() * fruit.getWeight() * rate;
System.out.println("水果价格: "+NumberFormat.getCurrencyInstance().format(discountPrice));
}
public static void main(String[] args) {
LocalDate billDate = LocalDate.now();
Candy candy = new Candy("徐福记",LocalDate.of(2022,10,1),10.0);
System.out.println("糖果: " + candy.getName());
double rate = 0.0;
long days = billDate.toEpochDay() - candy.getProducedDate().toEpochDay();
System.out.println(days);
if(days > 180){
System.out.println("超过半年的糖果,请勿食用!");
}else{
rate = 0.9;
double discountPrice = candy.getPrice() * rate;
System.out.println("打折后的价格"+NumberFormat.getCurrencyInstance().format(discountPrice));
}
}
}
客户端
public class Client {
public static void main(String[] args) {
//德芙巧克力,生产日期2002-5-1 ,原价 10元
Candy candy = new Candy("德芙巧克力",LocalDate.of(2022,5,1),10.0);
Visitor visitor = new DiscountVisitor(LocalDate.of(2022,10,11));
visitor.visit(candy);
}
}
上面的代码虽然可以完成当前的需求,但是设想一下这样一个场景: 由于访问者的重载方法只能对当个的具体商品进行计价,如果顾客选择了多件商品来结账时,就可能会引起重载方法的派发问题(到底该由谁来计算的问题).
首先我们定义一个接待访问者的类 Acceptable,其中定义了一个accept(Visitor visitor)方法, 只要是visitor的子类都可以接收.
/**
* 接待者接口(抽象元素角色)
* @author spikeCong
* @date 2022/10/18
**/
public interface Acceptable {
//接收所有的Visitor访问者的子类实现类
public void accept(Visitor visitor);
}
/**
* 糖果类
* @author spikeCong
* @date 2022/10/18
**/
public class Candy extends Product implements Acceptable{
public Candy(String name, LocalDate producedDate, double price) {
super(name, producedDate, price);
}
@Override
public void accept(Visitor visitor) {
//accept实现方法中调用访问者并将自己 "this" 传回。this是一个明确的身份,不存在任何泛型
visitor.visit(this);
}
}
//酒水与水果类同样实现Acceptable接口,重写accept方法
测试
public class Client {
public static void main(String[] args) {
// //德芙巧克力,生产日期2002-5-1 ,原价 10元
Candy candy = new Candy("德芙巧克力",LocalDate.of(2022,5,1),10.0);
Visitor visitor = new DiscountVisitor(LocalDate.of(2022,10,11));
visitor.visit(candy);
//模拟添加多个商品的操作
List<Acceptable> products = Arrays.asList(
new Candy("金丝猴奶糖",LocalDate.of(2022,6,10),10.00),
new Wine("衡水老白干",LocalDate.of(2020,6,10),100.00),
new Fruit("草莓",LocalDate.of(2022,10,12),50.00,1)
);
Visitor visitor = new DiscountVisitor(LocalDate.of(2022,10,17));
for (Acceptable product : products) {
product.accept(visitor);
}
}
}
代码编写到此出,就可以应对计价方式或者业务逻辑的变化了,访问者模式成功地将数据资源(需实现接待者接口)与数据算法 (需实现访问者接口)分离开来。重载方法的使用让多样化的算法自成体系,多态化的访问者接口保证了系统算法的可扩展性,数据则保持相对固定,最终形成⼀个算法类对应⼀套数据。
6.7.4 访问者模式总结
1) 访问者模式优点:
-
扩展性好
在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能。
-
复用性好
通过访问者来定义整个对象结构通用的功能,从而提高复用程度。
-
分离无关行为
通过访问者来分离无关的行为,把相关的行为封装在一起,构成一个访问者,这样每一个访问者的功能都比较单一。
2) 访问者模式缺点:
-
对象结构变化很困难
在访问者模式中,每增加一个新的元素类,都要在每一个具体访问者类中增加相应的具体操作,这违背了“开闭原则”。
-
违反了依赖倒置原则
访问者模式依赖了具体类,而没有依赖抽象类。
3) 使用场景
-
当对象的数据结构相对稳定,而操作却经常变化的时候。 比如,上面例子中路由器本身的内部构造(也就是数据结构)不会怎么变化,但是在不同操作系统下的操作可能会经常变化,比如,发送数据、接收数据等。
-
需要将数据结构与不常用的操作进行分离的时候。 比如,扫描文件内容这个动作通常不是文件常用的操作,但是对于文件夹和文件来说,和数据结构本身没有太大关系(树形结构的遍历操作),扫描是一个额外的动作,如果给每个文件都添加一个扫描操作会太过于重复,这时采用访问者模式是非常合适的,能够很好分离文件自身的遍历操作和外部的扫描操作。
-
需要在运行时动态决定使用哪些对象和方法的时候。 比如,对于监控系统来说,很多时候需要监控运行时的程序状态,但大多数时候又无法预知对象编译时的状态和参数,这时使用访问者模式就可以动态增加监控行为。
6.8 备忘录模式
6.8.1 备忘录模式介绍
备忘录模式提供了一种对象状态的撤销实现机制,当系统中某一个对象需要恢复到某一历史状态时可以使用备忘录模式进行设计.

很多软件都提供了撤销(Undo)操作,如 Word、记事本、Photoshop、IDEA等软件在编辑时按 Ctrl+Z 组合键时能撤销当前操作,使文档恢复到之前的状态;还有在 浏览器 中的后退键、数据库事务管理中的回滚操作、玩游戏时的中间结果存档功能、数据库与操作系统的备份操作、棋类游戏中的悔棋功能等都属于这类。
备忘录模式(memento pattern)定义: 在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态.
6.8.2 备忘录模式原理

备忘录模式的主要角色如下:
- 发起人(Originator)角色:状态需要被记录的元对象类, 记录当前时刻的内部状态信息,提供创建备忘录和恢复备忘录数据的功能,实现其他业务功能,它可以访问备忘录里的所有信息。
- 备忘录(Memento)角色:负责存储发起人的内部状态,在需要的时候提供这些内部状态给发起人。
- 看护人(Caretaker)角色:对备忘录进行管理,提供保存与获取备忘录的功能,但其不能对备忘录的内容进行访问与修改。
6.8.3 备忘录模式实现
下面我们再来看看 UML 对应的代码实现。首先,我们创建原始对象 Originator,对象中有四个属性,分别是 state 用于显示当前对象状态,id、name、phone 用来模拟业务属性,并添加 get、set 方法、create() 方法用于创建备份对象,restore(memento) 用于恢复对象状态。
/**
* 发起人类
* @author spikeCong
* @date 2022/10/19
**/
public class Originator {
private String state = "原始对象";
private String id;
private String name;
private String phone;
public Originator() {
}
//创建备忘录对象
public Memento create(){
return new Memento(id,name,phone);
}
//恢复对象状态
public void restore(Memento m){
this.state = m.getState();
this.id = m.getId();
this.name = m.getName();
this.phone = m.getPhone();
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "Originator{" +
"state='" + state + '\'' +
", id='" + id + '\'' +
", name='" + name + '\'' +
", phone='" + phone + '\'' +
'}';
}
}
/**
* 备忘录对象
* 访问权限为: 默认,也就是同包下可见(保证只有发起者类可以访问备忘录类)
* @author spikeCong
* @date 2022/10/19
**/
class Memento {
private String state = "从备份对象恢复为原始对象";
private String id;
private String name;
private String phone;
public Memento() {
}
public Memento(String id, String name, String phone) {
this.id = id;
this.name = name;
this.phone = phone;
}
//get、set、toString......
}
/**
* 负责人类-保存备忘录对象
* @author spikeCong
* @date 2022/10/19
**/
public class Caretaker {
private Memento memento;
public Memento getMemento() {
return memento;
}
public void setMemento(Memento memento) {
this.memento = memento;
}
}
public class Client {
public static void main(String[] args) {
//创建发起人对象
Originator originator = new Originator();
originator.setId("1");
originator.setName("spike");
originator.setPhone("13512341234");
System.out.println("=============" + originator);
//创建负责人对象,并保存备忘录对象
Caretaker caretaker = new Caretaker();
caretaker.setMemento(originator.create());
//修改
originator.setName("update");
System.out.println("=============" + originator);
//从负责人对象中获取备忘录对象,实现撤销
originator.restore(caretaker.getMemento());
System.out.println("=============" + originator);
}
}
6.8.4 备忘录模式应用实例
设计一个收集水果和获取金钱数的掷骰子游戏,游戏规则如下
- 游戏玩家通过扔骰子来决定下一个状态
- 当点数为1,玩家金钱增加
- 当点数为2,玩家金钱减少
- 当点数为6,玩家会得到水果
- 当钱消耗到一定程度,就恢复到初始状态
- Memento类: 表示玩家的状态
/**
* Memento 表示状态
* @author spikeCong
* @date 2022/10/19
**/
public class Memento {
int money; //所持金钱
ArrayList fruits; //获得的水果
//构造函数
Memento(int money) {
this.money = money;
this.fruits = new ArrayList();
}
//获取当前玩家所有的金钱
int getMoney() {
return money;
}
//获取当前玩家所有的水果
List getFruits() {
return (List)fruits.clone();
}
//添加水果
void addFruit(String fruit){
fruits.add(fruit);
}
}
- Player玩家类,只要玩家的金币还够,就会一直进行游戏,在该类中会设置一个createMemento方法,其作用是保存当前玩家状态.还会包含一个restore撤销方法,相当于复活操作.
package com.mashibing.memento.example02;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* @author spikeCong
* @date 2022/10/19
**/
public class Player {
private int money; //所持金钱
private List<String> fruits = new ArrayList(); //获得的水果
private Random random = new Random(); //随机数对象
private static String[] fruitsName={ //表示水果种类的数组
"苹果","葡萄","香蕉","橘子"
};
//构造方法
public Player(int money) {
this.money = money;
}
//获取当前所持有的金钱
public int getMoney() {
return money;
}
//获取一个水果
public String getFruit() {
String prefix = "";
if (random.nextBoolean()) {
prefix = "好吃的";
}
//从数组中获取水果
String f = fruitsName[random.nextInt(fruitsName.length)];
return prefix + f;
}
//掷骰子游戏
public void yacht(){
int dice = random.nextInt(6) + 1; //掷骰子
if(dice == 1){
money += 100;
System.out.println("所持有的金钱增加了..");
}else if(dice == 2){
money /= 2;
System.out.println("所持有的金钱减半..");
}else if(dice == 6){ //获取水果
String fruit = getFruit();
System.out.println("获得了水果: " + fruit);
fruits.add(fruit);
}else{
//骰子结果为3、4、5
System.out.println("无效数字,继续投掷");
}
}
//拍摄快照
public Memento createMemento(){
Memento memento = new Memento(money);
for (String fruit : fruits) {
if(fruit.startsWith("好吃的")){
memento.addFruit(fruit);
}
}
return memento;
}
//撤销方法
public void restore(Memento memento){
this.money = memento.money;
this.fruits = memento.getFruits();
}
@Override
public String toString() {
return "Player{" +
"money=" + money +
", fruits=" + fruits +
'}';
}
}
- 测试: 由于引入了备忘录模式,可以保存某个时间点的玩家状态,这样就可以对玩家进行复活操作.
public class MainApp {
public static void main(String[] args) throws InterruptedException {
Player player = new Player(100); //最初所持的金钱数
Memento memento = player.createMemento(); //保存最初状态
for (int i = 0; i < 100; i++) {
//显示扔骰子的次数
System.out.println("=====" + i);
//显示当前状态
System.out.println("当前状态: " + player);
//开启游戏
player.yacht();
System.out.println("所持有的金钱为: " + player.getMoney() + " 元");
//决定如何操作Memento
if(player.getMoney() > memento.getMoney()){
System.out.println("赚到金币,保存当前状态,继续游戏!");
memento = player.createMemento();
}else if(player.getMoney() < memento.getMoney() / 2){
System.out.println("所持金币不多了,将游戏恢复到初始状态!");
player.restore(memento);
}
Thread.sleep(1000);
System.out.println("");
}
}
}
6.8.5 备忘录模式总结
1 ) 备忘录模式的优点
- 提供了一种状态恢复的实现机制,使得用户可以方便的回到一个特定的历史步骤,当新的状态无效或者存在问题的时候,可以使用暂时存储起来的备忘录将状态复原.
- 备忘录实现了对信息的封装,一个备忘录对象是一种发起者对象状态的表示,不会被其他代码所改动.备忘录保存了发起者的状态,采用集合来存储备忘录可以实现多次撤销的操作
2 ) 备忘录模式的缺点
- 资源消耗过大,如果需要保存的发起者类的成员变量比较多, 就不可避免的需要占用大量的存储空间,每保存一次对象的状态,都需要消耗一定系统资源
3) 备忘录模式使用场景
- 需要保存一个对象在某一时刻的状态时,可以使用备忘录模式.
- 不希望外界直接访问对象内部状态时.
6.9 命令模式
6.9.1 命令模式介绍
命令模式(command pattern)的定义: 命令模式将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不 同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等 (附加控制)功能。
命令模式的核心是将指令信息封装成一个对象,并将此对象作为参数发送给接收方去执行,达到使命令的请求与执行方解耦,双方只通过传递各种命令对象来完成任务.
在实际的开发中,如果你用到的编程语言并不支持用函数作为参数来传递,那么就可以借助命令模式将函数封装为对象来使用。
我们知道,C 语 言支持函数指针,我们可以把函数当作变量传递来传递去。但是,在大部分编程语言中,函 数没法儿作为参数传递给其他函数,也没法儿赋值给变量。借助命令模式,我们可以将函数 封装成对象。具体来说就是,设计一个包含这个函数的类,实例化一个对象传来传去,这样 就可以实现把函数像对象一样使用。
6.9.2 命令模式原理

命令模式包含以下主要角色:
- 抽象命令类(Command)角色: 定义命令的接口,声明执行的方法。
- 具体命令(Concrete Command)角色:具体的命令,实现命令接口;通常会持有接收者,并调用接收者的功能来完成命令要执行的操作。
- 实现者/接收者(Receiver)角色: 接收者,真正执行命令的对象。任何类都可能成为一个接收者,只要它能够实现命令要求实现的相应功能。
- 调用者/请求者(Invoker)角色: 要求命令对象执行请求,通常会持有命令对象,可以持有很多的命令对象。这个是客户端真正触发命令并要求命令执行相应操作的地方,也就是说相当于使用命令对象的入口。
6.9.3 命令模式实现
模拟酒店后厨的出餐流程,来对命令模式进行一个演示,命令模式角色的角色与案例中角色的对应关系如下:
- 服务员: 即调用者角色,由她来发起命令.
- 厨师: 接收者,真正执行命令的对象.
- 订单: 命令中包含订单
/**
* 订单类
* @author spikeCong
* @date 2022/10/19
**/
public class Order {
private int diningTable; //餐桌号码
//存储菜名与份数
private Map<String,Integer> foodMenu = new HashMap<>();
public int getDiningTable() {
return diningTable;
}
public void setDiningTable(int diningTable) {
this.diningTable = diningTable;
}
public Map<String, Integer> getFoodMenu() {
return foodMenu;
}
public void setFoodDic(Map<String, Integer> foodMenu) {
this.foodMenu = foodMenu;
}
}
/**
* 厨师类 -> Receiver角色
* @author spikeCong
* @date 2022/10/19
**/
public class Chef {
public void makeFood(int num,String foodName){
System.out.println(num + "份," + foodName);
}
}
/**
* 抽象命令接口
* @author spikeCong
* @date 2022/10/19
**/
public interface Command {
void execute(); //只需要定义一个统一的执行方法
}
/**
* 具体命令
* @author spikeCong
* @date 2022/10/19
**/
public class OrderCommand implements Command {
//持有接收者对象
private Chef receiver;
private Order order;
public OrderCommand(Chef receiver, Order order) {
this.receiver = receiver;
this.order = order;
}
@Override
public void execute() {
System.out.println(order.getDiningTable() + "桌的订单: ");
Set<String> keys = order.getFoodMenu().keySet();
for (String key : keys) {
receiver.makeFood(order.getFoodMenu().get(key),key);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(order.getDiningTable() + "桌的菜已上齐.");
}
}
/**
* 服务员-> Invoker调用者
* @author spikeCong
* @date 2022/10/19
**/
public class Waiter {
//可以持有很多的命令对象
private ArrayList<Command> commands;
public Waiter() {
commands = new ArrayList();
}
public Waiter(ArrayList<Command> commands) {
this.commands = commands;
}
public void setCommands(Command command) {
commands.add(command);
}
//发出命令 ,指挥厨师工作
public void orderUp(){
System.out.println("服务员: 叮咚,有新的订单,请厨师开始制作......");
for (Command cmd : commands) {
if(cmd != null){
cmd.execute();
}
}
}
}
public class Client {
public static void main(String[] args) {
Order order1 = new Order();
order1.setDiningTable(1);
order1.getFoodMenu().put("鲍鱼炒饭",1);
order1.getFoodMenu().put("茅台迎宾",1);
Order order2 = new Order();
order2.setDiningTable(3);
order2.getFoodMenu().put("海参炒面",1);
order2.getFoodMenu().put("五粮液",1);
//创建接收者
Chef receiver = new Chef();
//将订单和接收者封装成命令对象
OrderCommand cmd1 = new OrderCommand(receiver,order1);
OrderCommand cmd2 = new OrderCommand(receiver,order2);
//创建调用者
Waiter invoke = new Waiter();
invoke.setCommands(cmd1);
invoke.setCommands(cmd2);
//将订单发送到后厨
invoke.orderUp();
}
}
6.9.4 命令模式总结
1) 命令模式优点:
- 降低系统的耦合度。命令模式能将调用操作的对象与实现该操作的对象解耦。
- 增加或删除命令非常方便。采用命令模式增加与删除命令不会影响其他类,它满足“开闭原则”,对扩展比较灵活。
- 可以实现宏命令。命令模式可以与组合模式结合,将多个命令装配成一个组合命令,即宏命令。
2) 命令模式缺点:
- 使用命令模式可能会导致某些系统有过多的具体命令类。
- 系统结构更加复杂。
3) 使用场景
- 系统需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。
- 系统需要在不同的时间指定请求、将请求排队和执行请求。
- 系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作。
7.0 解释器模式
7.0.1 解释器模式介绍
解释器模式使用频率不算高,通常用来描述如何构建一个简单“语言”的语法解释器。它只在一些非常特定的领域被用到,比如编译器、规则引擎、正则表达式、SQL 解析等。不过,了解它的实现原理同样很重要,能帮助你思考如何通过更简洁的规则来表示复杂的逻辑。
解释器模式(Interpreter pattern)的原始定义是:用于定义语言的语法规则表示,并提供解释器来处理句子中的语法。
我们通过一个例子给大家解释一下解释器模式
- 假设我们设计一个软件用来进行加减计算。我们第一想法就是使用工具类,提供对应的加法和减法的工具方法。
//用于两个整数相加的方法
public static int add(int a , int b){
return a + b;
}
//用于三个整数相加的方法
public static int add(int a , int b,int c){
return a + b + c;
}
public static int add(Integer ... arr){
int sum = 0;
for(Integer num : arr){
sum += num;
}
return sum;
}
+ -
上面的形式比较单一、有限,如果形式变化非常多,这就不符合要求,因为加法和减法运算,两个运算符与数值可以有无限种组合方式。比如: 5-3+2-1, 10-5+20…
文法规则和抽象语法树
解释器模式描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子.
在上面提到的加法/减法解释器中,每一个输入表达式(比如:2+3+4-5) 都包含了3个语言单位,可以使用下面的文法规则定义:
文法是用于描述语言的语法结构的形式规则。
expression ::= value | plus | minus
plus ::= expression ‘+’ expression
minus ::= expression ‘-’ expression
value ::= integer
注意: 这里的符号“::=”表示“定义为”的意思,竖线 | 表示或,左右的其中一个,引号内为字符本身,引号外为语法。
上面规则描述为 :
表达式可以是一个值,也可以是plus或者minus运算,而plus和minus又是由表达式结合运算符构成,值的类型为整型数。
抽象语法树:
在解释器模式中还可以通过一种称为抽象语法树的图形方式来直观的表示语言的构成,每一棵抽象语法树对应一个语言实例,例如加法/减法表达式语言中的语句 " 1+ 2 + 3 - 4 + 1" 可以通过下面的抽象语法树表示

7.02 解释器模式原理

解释器模式包含以下主要角色。
- 抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
- 终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。上例中的value 是终结符表达式.
- 非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。上例中的 plus , minus 都是非终结符表达式
- 环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
- 客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
7.0.3 解释器模式实现
为了更好的给大家解释一下解释器模式, 我们来定义了一个进行加减乘除计算的“语言”,语法规则如下:
- 运算符只包含加、减、乘、除,并且没有优先级的概念;
- 表达式中,先书写数字,后书写运算符,空格隔开;
我们举个例子来解释一下上面的语法规则:
- 比如
“ 9 5 7 3 - + * ”这样一个表达式,我们按照上面的语法规则来处理,取出数字“9、5”和“-”运算符,计算得到 4,于是表达式就变成了“ 4 7 3 + * ”。然后,我们再取出“4 7”和“ + ”运算符,计算得到 11,表达式就变成了“ 11 3 * ”。最后,我们取出“ 11 3”和“ * ”运算符,最终得到的结果就是 33。
代码示例:
- 用户按照上 面的规则书写表达式,传递给 interpret() 函数,就可以得到最终的计算结果。
/**
* 表达式解释器类
* @author spikeCong
* @date 2022/10/20
**/
public class ExpressionInterpreter {
//Deque双向队列,可以从队列的两端增加或者删除元素
private Deque<Long> numbers = new LinkedList<>();
//接收表达式进行解析
public long interpret(String expression){
String[] elements = expression.split(" ");
int length = elements.length;
//获取表达式中的数字
for (int i = 0; i < (length+1)/2; ++i) {
//在 Deque的尾部添加元素
numbers.addLast(Long.parseLong(elements[i]));
}
//获取表达式中的符号
for (int i = (length+1)/2; i < length; ++i) {
String operator = elements[i];
//符号必须是 + - * / 否则抛出异常
boolean isValid = "+".equals(operator) || "-".equals(operator)
|| "*".equals(operator) || "/".equals(operator);
if (!isValid) {
throw new RuntimeException("Expression is invalid: " + expression);
}
//pollFirst()方法, 移除Deque中的第一个元素,并返回被移除的值
long number1 = numbers.pollFirst(); //数字
long number2 = numbers.pollFirst();
long result = 0; //运算结果
//对number1和number2进行运算
if (operator.equals("+")) {
result = number1 + number2;
} else if (operator.equals("-")) {
result = number1 - number2;
} else if (operator.equals("*")) {
result = number1 * number2;
} else if (operator.equals("/")) {
result = number1 / number2;
}
//将运算结果添加到集合头部
numbers.addFirst(result);
}
//运算完成numbers中应该保存着运算结果,否则是无效表达式
if (numbers.size() != 1) {
throw new RuntimeException("Expression is invalid: " + expression);
}
//移除Deque的第一个元素,并返回
return numbers.pop();
}
}
代码重构
上面代码的所有的解析逻辑都耦合在一个函数中,这样显然是不合适的。这 个时候,我们就要考虑拆分代码,将解析逻辑拆分到独立的小类中, 前面定义的语法规则有两类表达式,一类是数字,一类是运算符,运算符又包括加减乘除。 利用解释器模式,我们把解析的工作拆分到以下五个类:plu,sub,mul,div
- NumExpression
- PluExpression
- SubExpression
- MulExpression
- DivExpression
/**
* 表达式接口
* @author spikeCong
* @date 2022/10/20
**/
public interface Expression {
long interpret();
}
/**
* 数字表达式
* @author spikeCong
* @date 2022/10/20
**/
public class NumExpression implements Expression {
private long number;
public NumExpression(long number) {
this.number = number;
}
public NumExpression(String number) {
this.number = Long.parseLong(number);
}
@Override
public long interpret() {
return this.number;
}
}
/**
* 加法运算
* @author spikeCong
* @date 2022/10/20
**/
public class PluExpression implements Expression{
private Expression exp1;
private Expression exp2;
public PluExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() + exp2.interpret();
}
}
/**
* 减法运算
* @author spikeCong
* @date 2022/10/20
**/
public class SubExpression implements Expression {
private Expression exp1;
private Expression exp2;
public SubExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() - exp2.interpret();
}
}
/**
* 乘法运算
* @author spikeCong
* @date 2022/10/20
**/
public class MulExpression implements Expression {
private Expression exp1;
private Expression exp2;
public MulExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() * exp2.interpret();
}
}
/**
* 除法
* @author spikeCong
* @date 2022/10/20
**/
public class DivExpression implements Expression {
private Expression exp1;
private Expression exp2;
public DivExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() / exp2.interpret();
}
}
//测试
public class Test01 {
public static void main(String[] args) {
ExpressionInterpreter e = new ExpressionInterpreter();
long result = e.interpret("6 2 3 2 4 / - + *");
System.out.println(result);
}
}
7.0.4 解释器模式总结
1) 解释器优点
-
易于改变和扩展文法
因为在解释器模式中使用类来表示语言的文法规则的,因此就可以通过继承等机制改变或者扩展文法.每一个文法规则都可以表示为一个类,因此我们可以快速的实现一个迷你的语言
-
实现文法比较容易
在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂
-
增加新的解释表达式比较方便
如果用户需要增加新的解释表达式,只需要对应增加一个新的表达式类就可以了.原有的表达式类不需要修改,符合开闭原则
2) 解释器缺点
-
对于复杂文法难以维护
在解释器中一条规则至少要定义一个类,因此一个语言中如果有太多的文法规则,就会使类的个数急剧增加,当值系统的维护难以管理.
-
执行效率低
在解释器模式中大量的使用了循环和递归调用,所有复杂的句子执行起来,整个过程也是非常的繁琐
3) 使用场景
- 当语言的文法比较简单,并且执行效率不是关键问题.
- 当问题重复出现,且可以用一种简单的语言来进行表达
- 当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象的语法树的时候
7.1 中介者模式
7.1.1 中介者模式介绍
提到中介模式,有一个比较经典的例子就是航空管制。 为了让飞机在飞行的时候互不干扰,每架飞机都需要知道其他飞机每时每刻的位置,这就需要时刻跟其他飞机通信。飞机通信形成的通信网络就会无比复杂。这个时候,我们通过引 入“塔台”这样一个中介,让每架飞机只跟塔台来通信,发送自己的位置给塔台,由塔台来 负责每架飞机的航线调度。这样就大大简化了通信网络。

中介模式(mediator pattern)的定义: 定义一个单独的(中介)对象,来封装一组对象之间的交互,将这组对象之间的交互委派给予中介对象交互,来避免对象之间的交互.
中介者对象就是用于处理对象与对象之间的直接交互,封装了多个对象之间的交互细节。中介模式的设计跟中间层很像,通过引入中介这个中间层,将一组对象之间的交互关系从多对多的网状关系转换为一对多的星状关系.原来一个对象要跟N个对象交互,现在只需要跟一个中介对象交互,从而最小化对象之间的交互关系,降低代码的复杂度,提高代码的可读性和可维护性.
7.1.2 中介者模式原理

中介者模式包含以下主要角色:
-
抽象中介者(Mediator)角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
-
具体中介者(ConcreteMediator)角色:实现中介者接口,定义一个 List 来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。
-
抽象同事类(Colleague)角色:定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。
-
具体同事类(Concrete Colleague)角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。
7.1.3 中介者模式实现
代码示例
/**
* 抽象中介者
* @author spikeCong
* @date 2022/10/20
**/
public interface Mediator {
void apply(String key);
}
/**
* 具体中介者
* @author spikeCong
* @date 2022/10/20
**/
public class MediatorImpl implements Mediator {
@Override
public void apply(String key) {
System.out.println("最终中介者执行操作,key为: " + key);
}
}
/**
* 抽象同事类
* @author spikeCong
* @date 2022/10/20
**/
public abstract class Colleague {
private Mediator mediator;
public Colleague(Mediator mediator) {
this.mediator = mediator;
}
public Mediator getMediator() {
return mediator;
}
public abstract void exec(String key);
}
/**
* 具体同事类
* @author spikeCong
* @date 2022/10/20
**/
public class ConcreteColleagueA extends Colleague {
public ConcreteColleagueA(Mediator mediator) {
super(mediator);
}
@Override
public void exec(String key) {
System.out.println("====在组件A中,通过中介者执行!");
getMediator().apply(key);
}
}
public class ConcreteColleagueB extends Colleague {
public ConcreteColleagueB(Mediator mediator) {
super(mediator);
}
@Override
public void exec(String key) {
System.out.println("====在组件B中,通过中介者执行!");
getMediator().apply(key);
}
}
public class Client {
public static void main(String[] args) {
//创建中介者
MediatorImpl mediator = new MediatorImpl();
//创建同事对象
Colleague c1 = new ConcreteColleagueA(mediator);
c1.exec("key-A");
Colleague c2 = new ConcreteColleagueB(mediator);
c2.exec("key-B");
}
}
====在组件A中,通过中介者执行!
最终中介者执行操作,key为: key-A
====在组件B中,通过中介者执行!
最终中介者执行操作,key为: key-B
7.1.4 中介者模式应用实例
【例】租房
现在租房基本都是通过房屋中介,房主将房屋托管给房屋中介,而租房者从房屋中介获取房屋信息。房屋中介充当租房者与房屋所有者之间的中介者。
/**
* 抽象中介者
* @author spikeCong
* @date 2022/10/20
**/
public abstract class Mediator {
//申明一个联络方法
public abstract void contact(String message,Person person);
}
/**
* 抽象同事类
* @author spikeCong
* @date 2022/10/20
**/
public abstract class Person {
protected String name;
protected Mediator mediator;
public Person(String name, Mediator mediator) {
this.name = name;
this.mediator = mediator;
}
}
/**
* 中介机构
* @author spikeCong
* @date 2022/10/20
**/
public class MediatorStructure extends Mediator {
//中介要知晓房主和租房者的信息
private HouseOwner houseOwner;
private Tenant tenant;
public HouseOwner getHouseOwner() {
return houseOwner;
}
public void setHouseOwner(HouseOwner houseOwner) {
this.houseOwner = houseOwner;
}
public Tenant getTenant() {
return tenant;
}
public void setTenant(Tenant tenant) {
this.tenant = tenant;
}
@Override
public void contact(String message, Person person) {
if(person == houseOwner){ //如果是房主,则租房者获得信息
tenant.getMessage(message);
}else { //如果是租房者则获取房主信息
houseOwner.getMessage(message);
}
}
}
/**
* 具体同事类-房屋拥有者
* @author spikeCong
* @date 2022/10/20
**/
public class HouseOwner extends Person{
public HouseOwner(String name, Mediator mediator) {
super(name, mediator);
}
//与中介者联系
public void contact(String message){
mediator.contact(message,this);
}
//获取信息
public void getMessage(String message){
System.out.println("房主" + name + "获取到的信息: " + message);
}
}
/**
* 具体同事类-承租人
* @author spikeCong
* @date 2022/10/20
**/
public class Tenant extends Person{
public Tenant(String name, Mediator mediator) {
super(name, mediator);
}
//与中介者联系
public void contact(String message){
mediator.contact(message,this);
}
//获取信息
public void getMessage(String message){
System.out.println("租房者" + name + "获取到的信息: " + message);
}
}
public class Client {
public static void main(String[] args) {
//一个房主 一个租房者 一个中介机构
MediatorStructure mediator = new MediatorStructure();
//房主和租房者只需要知道中介机构即可
HouseOwner houseOwner = new HouseOwner("路飞", mediator);
Tenant tenant = new Tenant("娜美", mediator);
//中介收集房租和租房者信息
mediator.setHouseOwner(houseOwner);
mediator.setTenant(tenant);
tenant.contact("需要一个两室一厅的房子,一家人住");
houseOwner.contact("出租一套两室一厅带电梯,月租5000");
}
}
7.1.5 中介者模式总结
1) 中介者模式的优点
- 中介者模式简化了对象之间的交互,他用中介者和同事的一对多代替了原来的同事之间的多对多的交互,一对多关系更好理解 易于维护和扩展,将原本难以理解的网状结构转换成习相对简单的星型结构.
- 可以将各个同事就对象进行解耦.中介者有利于各个同事之间的松耦合,可以独立的改变或者复用每一个同事或者中介者,增加新的中介者类和新的同事类都比较方便,更符合开闭原则
- 可以减少子类生成,中介者将原本分布与多个对象的行为集中在了一起,改变这些行为只需要生成新的中介者的子类即可,使得同事类可以被重用,无需直接对同事类进行扩展.
2) 中介者模式的缺点
- 在具体中介者类中包含了大量同事之间的交互细节,可能会导致中介者类变得非常的复杂,使得系统不好维护.
3) 中介者模式使用场景
- 系统中对象之间存在复杂的引用关系,系统结构混乱且难以理解.
- 一个对象由于引用了其他的很多对象并且直接和这些对象进行通信,导致难以复用该对象.
- 想要通过一个中间类来封装多个类中的行为,而又不想生成太多的子类,此时可以通过引用中介者类来实现,在中介者类中定义对象的交互的公共行为,如果需要改变行为则可以在增加新的中介类.
第七章 开源实战
7.1 剖析Spring框架中用到的经典设计模式
7.1.1 Spring中工厂模式的应用
Spring的设计理念
- Spring是面向Bean的编程(BOP:Bean Oriented Programming),Bean在Spring中才是真正的主角。Bean在Spring中作用就像Object对OOP的意义一样,没有对象的概念就像没有面向对象编程,Spring中没有Bean也就没有Spring存在的意义。Spring提供了IoC 容器通过配置文件或者注解的方式来管理对象之间的依赖关系。
- 控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则,可以用来减低代码之间的耦合度。其中最常见的方式叫做依赖注入(Dependency Injection,简称DI),还有一种方式叫“依赖查找”(Dependency Lookup)。通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体,将其所依赖的对象的引用传递给它。
7.1.1.1 Spring中的Bean组件
Bean组件定义在Spring的org.springframework.beans包下,解决了以下几个问题:
这个包下的所有类主要解决了三件事:
- Bean的定义
- Bean的创建
- Bean的解析
Spring Bean的创建是典型的工厂模式,它的顶级接口是BeanFactory。

BeanFactory有三个子类:ListableBeanFactory、HierarchicalBeanFactory和AutowireCapableBeanFactory。目的是为了区分Spring内部对象处理和转化的数据限制。
但是从图中可以发现最终的默认实现类是DefaultListableBeanFactory,它实现了所有的接口
7.1.1.2 Spring中的BeanFactory
Spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得Bean对象
BeanFactory,以Factory结尾,表示它是一个工厂(接口), 它负责生产和管理bean的一个工厂。在Spring中,BeanFactory是工厂的顶层接口,也是IOC容器的核心接口,因此BeanFactory中定义了管理Bean的通用方法,如 getBean 和 containsBean 等.
它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dgpmFSNk-1671282983699)(C:\Users\86187\AppData\Roaming\Typora\typora-user-images\image-20221025193939157.png)]
BeanFactory只是个接口,并不是IOC容器的具体实现,所以Spring容器给出了很多种实现,如 DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,其中XmlBeanFactory就是常用的一个,该实现将以XML方式描述组成应用的对象及对象间的依赖关系。
1) BeanFactory源码解析
public interface BeanFactory {
/**
对FactoryBean的转移定义,因为如果使用bean的名字来检索FactoryBean得到的是对象是工厂生成的对象,
如果想得到工厂本身就需要转移
*/
String FACTORY_BEAN_PREFIX = "&";
//根据Bean的名字 获取IOC容器中对应的实例
Object getBean(String var1) throws BeansException;
//根据Bean的名字和class类型得到bean实例,增加了类型安全验证机制
<T> T getBean(String var1, Class<T> var2) throws BeansException;
Object getBean(String var1, Object... var2) throws BeansException;
<T> T getBean(Class<T> var1) throws BeansException;
<T> T getBean(Class<T> var1, Object... var2) throws BeansException;
<T> ObjectProvider<T> getBeanProvider(Class<T> var1);
<T> ObjectProvider<T> getBeanProvider(ResolvableType var1);
//查看Bean容器中是否存在对应的实例,存在返回true 否则返回false
boolean containsBean(String var1);
//根据Bean的名字 判断这个bean是不是单例
boolean isSingleton(String var1) throws NoSuchBeanDefinitionException;
boolean isPrototype(String var1) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String var1, ResolvableType var2) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String var1, Class<?> var2) throws NoSuchBeanDefinitionException;
//得到bean实例的class类型
@Nullable
Class<?> getType(String var1) throws NoSuchBeanDefinitionException;
@Nullable
Class<?> getType(String var1, boolean var2) throws NoSuchBeanDefinitionException;
//得到bean的别名
String[] getAliases(String var1);
}
BeanFactory的使用场景
- 从IOC容器中获取Bean(Name or Type)
- 检索IOC容器中是否包含了指定的对象
- 判断Bean是否为单例
2) BeanFactory的使用
public class User {
private int id;
private String name;
private Friends friends;
public User() {
}
public User(Friends friends) {
this.friends = friends;
}
//get set......
}
public class Friends {
private List<String> names;
public Friends() {
}
public List<String> getNames() {
return names;
}
public void setNames(List<String> names) {
this.names = names;
}
}
配置文件
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.2.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.2.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc-4.2.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task-4.2.xsd">
<bean id="User" class="com.example.factory.User">
<property name="friends" ref="UserFriends" />
</bean>
<bean id="UserFriends" class="com.example.factory.Friends">
<property name="names">
<list>
<value>"LiLi"</value>
<value>"LuLu"</value>
</list>
</property>
</bean>
</beans>
测试
public class SpringFactoryTest {
public static void main(String[] args) {
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("bean.xml");
User user = ctx.getBean("User", User.class);
List<String> names = user.getFriends().getNames();
for (String name : names) {
System.out.println("FriendName: " + name);
}
ctx.close();
}
}
7.1.1.3 Spring中的FactoryBean
首先FactoryBean是一个Bean,但又不仅仅是一个Bean,这样听起来矛盾,但为啥又这样说呢?其实在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个FactoryBean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂方法模式和修饰器模式类似
1) 为什么需要FactoryBean?
- 在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,则需要在中提供大量的配置信息。配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。Spring为此提供了一个
org.springframework.bean.factory.FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。FactoryBean接口对于Spring框架来说占用重要的地位,Spring自身就提供了70多个FactoryBean的实现。它们隐藏了实例化一些复杂Bean的细节,给上层应用带来了便利。 - 由于第三方库不能直接注册到spring容器,于是可以实现
org.springframework.bean.factory.FactoryBean接口,然后给出自己对象的实例化代码即可。
2 ) FactoryBean的使用特点
-
当用户使用容器本身时,可以使用转义字符"&"来得到FactoryBean本身,以区别通过FactoryBean产生的实例对象和FactoryBean对象本身。
-
在BeanFactory中通过如下代码定义了该转义字符:
StringFACTORY_BEAN_PREFIX = "&"; -
举例
如果MyObject是一个FactoryBean,则使用&MyObject得到的是MyObject对象,而不是MyObject产生出来的对象。
3) FactoryBean的代码示例
@Configuration
@ComponentScan("com.example.factory_bean")
public class AppConfig {
}
@Component("studentBean")
public class StudentBean implements FactoryBean {
//返回工厂中的实例
@Override
public Object getObject() throws Exception {
//这里并不一定要返回MyBean自身的实例,可以是其他任何对象的实例。
return new TeacherBean();
}
//该方法返回的类型是在IOC容器中getBean所匹配的类型
@Override
public Class<?> getObjectType() {
return StudentBean.class;
}
public void study(){
System.out.println("学生学习......");
}
}
public class TeacherBean {
public void teach(){
System.out.println("老师教书......");
}
}
public class Test01 {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
//StudentBean studentBean = (StudentBean)context.getBean("studentBean");
//加上&符号,返回工厂中的实例
// StudentBean studentBean = (StudentBean)context.getBean("&studentBean");
// studentBean.study();
TeacherBean teacherBean = (TeacherBean) context.getBean("studentBean");
teacherBean.teach();
}
}
3) FactoryBean源码分析
public interface FactoryBean<T> {
String OBJECT_TYPE_ATTRIBUTE = "factoryBeanObjectType";
/**
getObject()方法: 会返回该FactoryBean生产的对象实例,我们需要实现该方法,以给出自己的对象实例化逻辑
这个方法也是FactoryBean的核心.
*/
@Nullable
T getObject() throws Exception;
/**
getObjectType()方法: 仅返回getObject() 方法所返回的对象类型,如果预先无法确定,返回NULL,
这个方法返回类型是在IOC容器中getBean所匹配的类型
*/
@Nullable
Class<?> getObjectType();
//该方法的结果用于表明 工厂方法getObject() 所生产的 对象是否要以单例形式存储在容器中如果以单例存在就返回true,否则返回false
default boolean isSingleton() {
return true;
}
}
FactoryBean表现的是一个工厂的职责,如果一个BeanA 是实现FactoryBean接口,那么A就是变成了一个工厂,根据A的名称获取到的实际上是工厂调用getObject()方法返回的对象,而不是对象本身,如果想获取工厂对象本身,需要在名称前面加上 '&'符号
- getObject(‘name’) 返回的是工厂中工厂方法生产的实例
- getObject(‘&name’) 返回的是工厂本身实例
使用场景
- FactoryBean的最为经典的使用场景,就是用来创建AOP代理对象,这个对象在Spring中就是 ProxyFactoryBean
BeanFactory与FactoryBean区别
- 他们两个都是工厂,但是FactoryBean本质还是一个Bean,也归BeanFactory管理
- BeanFactory是Spring容器的顶层接口,FactoryBean更类似于用户自定义的工厂接口
BeanFactory和ApplicationContext的区别
- BeanFactory是Spring容器的顶层接口,而ApplicationContext应用上下文类 他是BeanFactory的子类,他是Spring中更高级的容器,提供了更多的功能
- 国际化
- 访问资源
- 载入多个上下文
- 消息发送 响应机制
- 两者的装载bean的时机不同
- BeanFactory: 在系统启动的时候不会去实例化bean,只有从容器中拿bean的时候才会去实例化(懒加载)
- 优点: 应用启动的时候占用的资源比较少,对资源的使用要求比较高的应用 ,比较有优势
- ApplicationContext:在启动的时候就把所有的Bean全部实例化.
- lazy-init= true 可以使bean延时实例化
- 优点: 所有的Bean在启动的时候就加载,系统运行的速度快,还可以及时的发现系统中配置的问题.
- BeanFactory: 在系统启动的时候不会去实例化bean,只有从容器中拿bean的时候才会去实例化(懒加载)
7.1.2 Spring中观察者模式的应用
7.1.2.1 观察者模式与发布订阅模式的异同
观察者模式它是用于建立一种对象与对象之间的依赖关系,一个对象发生改变时将自动通知其他对象,其他对象将相应的作出反应.
在观察者模式中发生改变的对象称为观察目标,而被通知的对象称为观察者,一个观察目标可以应对多个观察者,而且这些观察者之间可以没有任何相互联系,可以根据需要增加和删除观察者,使得系统更易于扩展.
观察者模式的别名有发布-订阅(Publish/Subscribe)模式, 我们来看一下观察者模式与发布订阅模式结构上的区别
- 在设计模式结构上,发布订阅模式继承自观察者模式,是观察者模式的一种实现的变体。
- 在设计模式意图上,两者关注点不同,一个关心数据源,一个关心的是事件消息。

观察者模式里,只有两个角色 —— 观察者 + 被观察者; 而发布订阅模式里,却不仅仅只有发布者和订阅者两个角色,还有一个管理并执行消息队列的 “经纪人Broker”
观察者和被观察者,是松耦合的关系;发布者和订阅者,则完全不存在耦合
-
观察者模式:数据源直接通知订阅者发生改变。
-
发布订阅模式:数据源告诉第三方(事件通道)发生了改变,第三方再通知订阅者发生了改变。
7.1.2.2 Spring中的观察者模式
Spring 基于观察者模式,实现了自身的事件机制也就是事件驱动模型,事件驱动模型通常也被理解成观察者或者发布/订阅模型。
spring事件模型提供如下几个角色
- ApplicationEvent
- ApplicationListener
- ApplicationEventPublisher
- ApplicationEventMulticaster
1) 事件:ApplicationEvent
-
是所有事件对象的父类。ApplicationEvent 继承自 jdk 的 EventObject, 所有的事件都需要继承 ApplicationEvent, 并且通过 source 得到事件源。
public abstract class ApplicationEvent extends EventObject { private static final long serialVersionUID = 7099057708183571937L; private final long timestamp = System.currentTimeMillis(); public ApplicationEvent(Object source) { super(source); } public final long getTimestamp() { return this.timestamp; } } -
Spring 也为我们提供了很多内置事件:
-
ContextRefreshEvent,当ApplicationContext容器初始化完成或者被刷新的时候,就会发布该事件。
-
ContextStartedEvent,当ApplicationContext启动的时候发布事件.
-
ContextStoppedEvent,当ApplicationContext容器停止的时候发布事件.
-
RequestHandledEvent,只能用于DispatcherServlet的web应用,Spring处理用户请求结束后,系统会触发该事件。
-

2) 事件监听:ApplicationListener
-
ApplicationListener(应用程序事件监听器) 继承自jdk的EventListener,所有的监听器都要实现这个接口,这个接口只有一个onApplicationEvent()方法,该方法接受一个ApplicationEvent或其子类对象作为参数
-
在方法体中,可以通过不同对Event类的判断来进行相应的处理.当事件触发时所有的监听器都会收到消息,如果你需要对监听器的接收顺序有要求,可是实现该接口的一个实现SmartApplicationListener,通过这个接口可以指定监听器接收事件的顺序.
@FunctionalInterface public interface ApplicationListener<E extends ApplicationEvent> extends EventListener { void onApplicationEvent(E var1); } -
实现了ApplicationListener接口之后,需要实现方法onApplicationEvent(),在容器将所有的Bean都初始化完成之后,就会执行该方法。
3) 事件源:ApplicationEventPublisher
-
事件的发布者,封装了事件发布功能方法接口,是Applicationcontext接口的超类
事件机制的实现需要三个部分,事件源,事件,事件监听器,在上面介绍的ApplicationEvent就相当于事件,ApplicationListener相当于事件监听器,这里的事件源说的就是ApplicationEventPublisher.
public interface ApplicationEventPublisher { default void publishEvent(ApplicationEvent event) { this.publishEvent((Object)event); } //调用publishEvent方法,传入一个ApplicationEvent的实现类对象作为参数,每当ApplicationContext发布ApplicationEvent时,所有的ApplicationListener就会被自动的触发. void publishEvent(Object var1); } -
我们常用的ApplicationContext都继承了AbstractApplicationContext,像我们平时常见ClassPathXmlApplicationContext、XmlWebApplicationContex也都是继承了它,AbstractApplicationcontext是ApplicationContext接口的抽象实现类,在该类中实现了publishEvent方法:
protected void publishEvent(Object event, @Nullable ResolvableType eventType) { Assert.notNull(event, "Event must not be null"); if (this.earlyApplicationEvents != null) { this.earlyApplicationEvents.add(applicationEvent); } else { //事件发布委托给applicationEventMulticaster this.getApplicationEventMulticaster().multicastEvent((ApplicationEvent)applicationEvent, eventType); } }在这个方法中,我们看到了一个getApplicationEventMulticaster().这就要牵扯到另一个类ApplicationEventMulticaster.
4) 事件管理:ApplicationEventMulticaster
-
用于事件监听器的注册和事件的广播。监听器的注册就是通过它来实现的,它的作用是把 Applicationcontext 发布的 Event 广播给它的监听器列表。
public interface ApplicationEventMulticaster { //添加事件监听器 void addApplicationListener(ApplicationListener<?> var1); //添加事件监听器,使用容器中的bean void addApplicationListenerBean(String var1); //移除事件监听器 void removeApplicationListener(ApplicationListener<?> var1); void removeApplicationListenerBean(String var1); //移除所有 void removeAllListeners(); //发布事件 void multicastEvent(ApplicationEvent var1); void multicastEvent(ApplicationEvent var1, @Nullable ResolvableType var2); } -
在AbstractApplicationcontext中有一个applicationEventMulticaster的成员变量,提供了监听器Listener的注册方法.
public abstract class AbstractApplicationContext extends DefaultResourceLoader implements ConfigurableApplicationContext, DisposableBean { private ApplicationEventMulticaster applicationEventMulticaster; protected void registerListeners() { // Register statically specified listeners first. for (ApplicationListener<?> listener : getApplicationListeners()) { getApplicationEventMulticaster().addApplicationListener(listener); } // Do not initialize FactoryBeans here: We need to leave all regular beans // uninitialized to let post-processors apply to them! String[] listenerBeanNames = getBeanNamesForType(ApplicationListener.class, true, false); for (String lisName : listenerBeanNames) { getApplicationEventMulticaster().addApplicationListenerBean(lisName); } } }
7.1.2.3 事件监听案例
实现一个需求:当调用一个类的方法完成时,该类发布事件,事件监听器监听该类的事件并执行的自己的方法逻辑
假设这个类是Request、发布的事件是ReuqestEvent、事件监听者是ReuqestListener。当调用Request的doRequest方法时,发布事件。
代码如下
/**
* 定义事件
* @author spikeCong
* @date 2022/10/24
**/
public class RequestEvent extends ApplicationEvent {
public RequestEvent(Object source) {
super(source);
}
}
/**
* 发布事件
* @author spikeCong
* @date 2022/10/24
**/
@Component
public class Request {
@Autowired
private ApplicationContext applicationContext;
public void doRequest(){
System.out.println("调用Request类的doRequest方法发送一个请求......");
applicationContext.publishEvent(new RequestEvent(this));
}
}
/**
* 监听事件
* @author spikeCong
* @date 2022/10/24
**/
@Component
public class RequestListener implements ApplicationListener<RequestEvent> {
@Override
public void onApplicationEvent(RequestEvent requestEvent) {
System.out.println("监听到RequestEvent事件,执行本方法");
}
}
public class SpringEventTest {
public static void main(String[] args) {
ApplicationContext context =
new AnnotationConfigApplicationContext("com.mashibing.pubsub");
Request request = (Request) context.getBean("request");
//调用方法发布事件
request.doRequest();
}
}
//打印日志
调用Request类的doRequest方法发送一个请求......
监听到RequestEvent事件,执行本方法
7.1.2.4 事件机制工作流程
上面代码的执行流程

-
监听器什么时候注册到IOC容器
注册的开始逻辑是在AbstractApplicationContext类的refresh方法,该方法包含了整个IOC容器初始化所有方法。其中有一个registerListeners()方法就是注册系统监听者(spring自带的)和自定义监听器的。
public void refresh() throws BeansException, IllegalStateException { //BeanFactory准备工作完成后进行的后置处理工作 this.postProcessBeanFactory(beanFactory); //执行BeanFactoryPostProcessor的方法; this.invokeBeanFactoryPostProcessors(beanFactory); //注册BeanPostProcessor(Bean的后置处理器),在创建bean的前后等执行 this.registerBeanPostProcessors(beanFactory); //初始化MessageSource组件(做国际化功能;消息绑定,消息解析); this.initMessageSource(); //初始化事件派发器 this.initApplicationEventMulticaster(); 子类重写这个方法,在容器刷新的时候可以自定义逻辑;如创建Tomcat,Jetty等WEB服务器 this.onRefresh(); //注册应用的监听器。就是注册实现了ApplicationListener接口的监听器bean,这些监听器是注册到ApplicationEventMulticaster中的 this.registerListeners(); //初始化所有剩下的非懒加载的单例bean this.finishBeanFactoryInitialization(beanFactory); //完成context的刷新 this.finishRefresh(); }看registerListeners的关键方法体,其中的两个方法
addApplicationListener和addApplicationListenerBean,从方法可以看出是添加监听者。protected void registerListeners() { Iterator var1 = this.getApplicationListeners().iterator(); while(var1.hasNext()) { ApplicationListener<?> listener = (ApplicationListener)var1.next(); this.getApplicationEventMulticaster().addApplicationListener(listener); } String[] listenerBeanNames = this.getBeanNamesForType(ApplicationListener.class, true, false); String[] var7 = listenerBeanNames; int var3 = listenerBeanNames.length; for(int var4 = 0; var4 < var3; ++var4) { String listenerBeanName = var7[var4]; this.getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName); } }那么最后将监听者放到哪里了呢?就是ApplicationEventMulticaster接口的子类

该接口主要两个职责,维护ApplicationListener相关类和发布事件。
实现在默认实现类AbstractApplicationEventMulticaster,
最后将Listener放到了内部类ListenerRetriever两个set集合中private class ListenerRetriever { public final Set<ApplicationListener<?>> applicationListeners = new LinkedHashSet(); public final Set<String> applicationListenerBeans = new LinkedHashSet(); }
ListenerRetriever被称为监听器注册表。
-
Spring如何发布的事件并通知监听者
这个注意的有两个方法
1) publishEvent方法
AbstractApplicationContext实现了ApplicationEventPublisher接口的publishEvent方法
protected void publishEvent(Object event, @Nullable ResolvableType eventType) { Assert.notNull(event, "Event must not be null"); Object applicationEvent; //尝试转换为ApplicationEvent或者PayloadApplicationEvent,如果是PayloadApplicationEvent则获取eventType if (event instanceof ApplicationEvent) { applicationEvent = (ApplicationEvent)event; } else { applicationEvent = new PayloadApplicationEvent(this, event); if (eventType == null) { eventType = ((PayloadApplicationEvent)applicationEvent).getResolvableType(); } } if (this.earlyApplicationEvents != null) { //判断earlyApplicationEvents是否为空(也就是早期事件还没有被发布-说明广播器还没有实例化好),如果不为空则将当前事件放入集合 this.earlyApplicationEvents.add(applicationEvent); } else { //否则获取ApplicationEventMulticaster调用其multicastEvent将事件广播出去。本文这里获取到的广播器实例是SimpleApplicationEventMulticaster。 this.getApplicationEventMulticaster().multicastEvent((ApplicationEvent)applicationEvent, eventType); } //将事件交给父类处理 if (this.parent != null) { if (this.parent instanceof AbstractApplicationContext) { ((AbstractApplicationContext)this.parent).publishEvent(event, eventType); } else { this.parent.publishEvent(event); } } }2) multicastEvent方法
继续进入到
multicastEvent方法,该方法有两种方式调用invokeListener,通过线程池和直接调用,进一步说就是通过异步和同步两种方式调用.public void multicastEvent(ApplicationEvent event, @Nullable ResolvableType eventType) { //解析事件类型 ResolvableType type = eventType != null ? eventType : this.resolveDefaultEventType(event); //获取执行器 Executor executor = this.getTaskExecutor(); // 获取合适的ApplicationListener,循环调用监听器的onApplicationEvent方法 Iterator var5 = this.getApplicationListeners(event, type).iterator(); while(var5.hasNext()) { ApplicationListener<?> listener = (ApplicationListener)var5.next(); if (executor != null) { //如果executor不为null,则交给executor去调用监听器 executor.execute(() -> { this.invokeListener(listener, event); }); } else { //否则,使用当前主线程直接调用监听器; this.invokeListener(listener, event); } } }3) invokeListener方法
// 该方法增加了错误处理逻辑,然后调用doInvokeListener protected void invokeListener(ApplicationListener<?> listener, ApplicationEvent event) { ErrorHandler errorHandler = this.getErrorHandler(); if (errorHandler != null) { try { this.doInvokeListener(listener, event); } catch (Throwable var5) { errorHandler.handleError(var5); } } else { this.doInvokeListener(listener, event); } } private void doInvokeListener(ApplicationListener listener, ApplicationEvent event) { //直接调用了listener接口的onApplicationEvent方法 listener.onApplicationEvent(event); }
7.1.3 结合设计模式自定义SpringIOC
7.1.3.1 Spring IOC核心组件
1) BeanFactory
BeanFactory作为最顶层的一个接口,定义了IoC容器的基本功能规范
从类图中我们可以发现最终的默认实现类是DefaultListableBeanFactory,它实现了所有的接口。那么为何要定义这么多层次的接口呢?
每个接口都有它的使用场合,主要是为了区分在Spring内部操作过程中对象的传递和转化,对对象的数据访问所做的限制。
例如,
- ListableBeanFactory接口表示这些Bean可列表化。
- HierarchicalBeanFactory表示这些Bean 是有继承关系的,也就是每个 Bean 可能有父 Bean
- AutowireCapableBeanFactory 接口定义Bean的自动装配规则。
这三个接口共同定义了Bean的集合、Bean之间的关系及Bean行为。
在BeanFactory里只对IoC容器的基本行为做了定义,根本不关心你的Bean是如何定义及怎样加载的。正如我们只关心能从工厂里得到什么产品,不关心工厂是怎么生产这些产品的。
2 ) ApplicationContext
BeanFactory有一个很重要的子接口,就是ApplicationContext接口,该接口主要来规范容器中的bean对象是非延时加载,即在创建容器对象的时候就对象bean进行初始化,并存储到一个容器中。
//延时加载
BeanFactory factory = new XmlBeanFactory(new ClassPathResource("bean.xml"));
//立即加载
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("bean.xml");
User user = context.getBean("user", User.class);
ApplicationContext 的子类主要包含两个方面:
-
ConfigurableApplicationContext 表示该 Context 是可修改的,也就是在构建 Context 中用户可以动态添加或修改已有的配置信息
-
WebApplicationContext 顾名思义,就是为 web 准备的 Context 他可以直接访问到 ServletContext,通常情况下,这个接口使用少
要知道工厂是如何产生对象的,我们需要看具体的IoC容器实现,Spring提供了许多IoC容器实现,比如:
- ClasspathXmlApplicationContext : 根据类路径加载xml配置文件,并创建IOC容器对象。
- FileSystemXmlApplicationContext :根据系统路径加载xml配置文件,并创建IOC容器对象。
- AnnotationConfigApplicationContext :加载注解类配置,并创建IOC容器。

总体来说 ApplicationContext 必须要完成以下几件事:
- 标识一个应用环境
- 利用 BeanFactory 创建 Bean 对象
- 保存对象关系表
- 能够捕获各种事件
3) Bean定义:BeanDefinition
这里的 BeanDefinition 就是我们所说的 Spring 的 Bean,我们自己定义的各个 Bean 其实会转换成一个个 BeanDefinition 存在于 Spring 的 BeanFactory 中
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactory
implements ConfigurableListableBeanFactory, BeanDefinitionRegistry, Serializable {
//DefaultListableBeanFactory 中使用 Map 结构保存所有的 BeanDefinition 信息
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
}
BeanDefinition 中保存了我们的 Bean 信息,比如这个 Bean 指向的是哪个类、是否是单例的、是否懒加载、这个 Bean 依赖了哪些 Bean 等等。
4) BeanDefinitionReader
Bean的解析过程非常复杂,功能被分得很细,因为这里需要被扩展的地方很多,必须保证足够的灵活性,以应对可能的变化。Bean的解析主要就是对Spring配置文件的解析。
这个解析过程主要通过BeanDefinitionReader来完成,看看Spring中BeanDefinitionReader的类结构图,如下图所示。

BeanDefinitionReader接口定义的功能
public interface BeanDefinitionReader {
/*
下面的loadBeanDefinitions都是加载bean定义,从指定的资源中
*/
int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException;
int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException;
int loadBeanDefinitions(String location) throws BeanDefinitionStoreException;
int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException;
}
5) BeanFactory后置处理器
后置处理器是一种拓展机制,贯穿Spring Bean的生命周期
后置处理器分为两类:
BeanFactory后置处理器:BeanFactoryPostProcessor
实现该接口,可以在spring的bean创建之前,修改bean的定义属性

public interface BeanFactoryPostProcessor {
/*
* 该接口只有一个方法postProcessBeanFactory,方法参数是ConfigurableListableBeanFactory,通过该
参数,可以获取BeanDefinition
*/
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}
6) Bean后置处理器:BeanPostProcessor
BeanPostProcessor是Spring IOC容器给我们提供的一个扩展接口
实现该接口,可以在spring容器实例化bean之后,在执行bean的初始化方法前后,添加一些处理逻辑

public interface BeanPostProcessor {
//bean初始化方法调用前被调用
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
//bean初始化方法调用后被调用
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
7.1.3.2 IOC流程图

- 容器环境的初始化(系统、JVM 、解析器、类加载器等等)
- Bean工厂的初始化(IOC容器首先会销毁旧工厂,旧Bean、创建新的工厂)
- 读取:通过BeanDefinitonReader读取我们项目中的配置(application.xml)
- 定义:通过解析xml文件内容,将里面的Bean解析成BeanDefinition(未实例化、未初始化)
- 将解析得到的BeanDefinition,存储到工厂类的Map容器中
- 调用 BeanFactoryPostProcessor 该方法是一种功能增强,可以在这个步骤对已经完成初始化的 BeanFactory 进行属性覆盖,或是修改已经注册到 BeanFactory 的 BeanDefinition
- 通过反射实例化bean对象
- 进入到Bean实例化流程,首先设置对象属性
- 检查Aware相关接口,并设置相关依赖
- 前置处理器,执行BeanPostProcesser的before方法对bean进行扩展
- 检查是否有实现initializingBean 回调接口,如果实现就要回调其中的AftpropertiesSet() 方法,(通过可以完成一些配置的加载)
- 检查是否有配置自定义的init-method ,
- 后置处理器执行BeanPostProcesser 的after方法 --> AOP就是在这个阶段完成的, 在这里判断bean对象是否实现接口,实现就使用JDK代理,否则选择CGLIB
- 对象创建完成,添加到BeanFactory的单例池中
7.1.3.3 自定义SpringIOC
对下面的配置文件进行解析,并自定义SpringIOC, 对涉及到的对象进行管理。
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="courseService" class="com.mashibing.service.impl.CourseServiceImpl">
<property name="courseDao" ref="courseDao"></property>
</bean>
<bean id="courseDao" class="com.mashibing.dao.impl.CourseDaoImpl"></bean>
</beans>
1) 创建与Bean相关的pojo类
- PropertyValue类: 用于封装bean的属性,体现到上面的配置文件就是封装bean标签的子标签property标签数据。
package com.mashibing.framework.beans;
/**
* 该类用来封装bean标签下的property子标签的属性
* 1.name属性
* 2.ref属性
* 3.value属性: 给基本数据类型及string类型数据赋的值
* @author spikeCong
* @date 2022/10/26
**/
public class PropertyValue {
private String name;
private String ref;
private String value;
public PropertyValue() {
}
public PropertyValue(String name, String ref, String value) {
this.name = name;
this.ref = ref;
this.value = value;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getRef() {
return ref;
}
public void setRef(String ref) {
this.ref = ref;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
- MutablePropertyValues类: 一个bean标签可以有多个property子标签,所以再定义一个MutablePropertyValues类,用来存储并管理多个PropertyValue对象。
package com.mashibing.framework.beans;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
/**
* 该类用来存储和遍历多个PropertyValue对象
* @author spikeCong
* @date 2022/10/26
**/
public class MutablePropertyValues implements Iterable<PropertyValue>{
//定义List集合,存储PropertyValue的容器
private final List<PropertyValue> propertyValueList;
//空参构造中 初始化一个list
public MutablePropertyValues() {
this.propertyValueList = new ArrayList<PropertyValue>();
}
//有参构造 接收一个外部传入的list,赋值propertyValueList属性
public MutablePropertyValues(List<PropertyValue> propertyValueList) {
if(propertyValueList == null){
this.propertyValueList = new ArrayList<PropertyValue>();
}else{
this.propertyValueList = propertyValueList;
}
}
//获取当前容器对应的迭代器对象
@Override
public Iterator<PropertyValue> iterator() {
//直接获取List集合中的迭代器
return propertyValueList.iterator();
}
//获取所有的PropertyValue
public PropertyValue[] getPropertyValues(){
//将集合转换为数组并返回
return propertyValueList.toArray(new PropertyValue[0]); //new PropertyValue[0]声明返回的数组类型
}
//根据name属性值获取PropertyValue
public PropertyValue getPropertyValue(String propertyName){
//遍历集合对象
for (PropertyValue propertyValue : propertyValueList) {
if(propertyValue.getName().equals(propertyName)){
return propertyValue;
}
}
return null;
}
//判断集合是否为空,是否存储PropertyValue
public boolean isEmpty(){
return propertyValueList.isEmpty();
}
//向集合中添加
public MutablePropertyValues addPropertyValue(PropertyValue value){
//判断集合中存储的propertyvalue对象.是否重复,重复就进行覆盖
for (int i = 0; i < propertyValueList.size(); i++) {
//获取集合中每一个 PropertyValue
PropertyValue currentPv = propertyValueList.get(i);
//判断当前的pv的name属性 是否与传入的相同,如果相同就覆盖
if(currentPv.getName().equals(value.getName())){
propertyValueList.set(i,value);
return this;
}
}
//没有重复
this.propertyValueList.add(value);
return this; //目的是实现链式编程
}
//判断是否有指定name属性值的对象
public boolean contains(String propertyName){
return getPropertyValue(propertyName) != null;
}
}
- BeanDefinition类: 用来封装bean信息的,主要包含id(即bean对象的名称)、class(需要交由spring管理的类的全类名)及子标签property数据。
/**
* 封装Bean标签数据的类,包括id与class以及子标签的数据
* @author spikeCong
* @date 2022/10/27
**/
public class BeanDefinition {
private String id;
private String className;
private MutablePropertyValues propertyValues;
public BeanDefinition() {
propertyValues = new MutablePropertyValues();
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getClassName() {
return className;
}
public void setClassName(String className) {
this.className = className;
}
public MutablePropertyValues getPropertyValues() {
return propertyValues;
}
public void setPropertyValues(MutablePropertyValues propertyValues) {
this.propertyValues = propertyValues;
}
}
2) 创建注册表相关的类
BeanDefinition对象存取的操作, 其实是在BeanDefinitionRegistry接口中定义的,它被称为是BeanDefinition的注册中心.
//源码
public interface BeanDefinitionRegistry extends AliasRegistry {
void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException;
void removeBeanDefinition(String beanName) throws NoSuchBeanDefinitionException;
BeanDefinition getBeanDefinition(String beanName) throws NoSuchBeanDefinitionException;
boolean containsBeanDefinition(String beanName);
String[] getBeanDefinitionNames();
int getBeanDefinitionCount();
boolean isBeanNameInUse(String beanName);
}
BeanDefinitionRegistry继承结构图如下:

BeanDefinitionRegistry接口的子实现类主要有以下两个:
-
DefaultListableBeanFactory
在该类中定义了如下代码,就是用来注册bean
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256); -
SimpleBeanDefinitionRegistry
在该类中定义了如下代码,就是用来注册bean
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(64);
- 自定义BeanDefinitionRegistry接口定义了注册表的相关操作,定义如下功能:
public interface BeanDefinitionRegistry {
//注册BeanDefinition对象到注册表中
void registerBeanDefinition(String beanName, BeanDefinition beanDefinition);
//从注册表中删除指定名称的BeanDefinition对象
void removeBeanDefinition(String beanName) throws Exception;
//根据名称从注册表中获取BeanDefinition对象
BeanDefinition getBeanDefinition(String beanName) throws Exception;
//判断注册表中是否包含指定名称的BeanDefinition对象
boolean containsBeanDefinition(String beanName);
//获取注册表中BeanDefinition对象的个数
int getBeanDefinitionCount();
//获取注册表中所有的BeanDefinition的名称
String[] getBeanDefinitionNames();
}
- SimpleBeanDefinitionRegistry类, 该类实现了BeanDefinitionRegistry接口,定义了Map集合作为注册表容器。
public class SimpleBeanDefinitionRegistry implements BeanDefinitionRegistry {
private Map<String, BeanDefinition> beanDefinitionMap = new HashMap<String, BeanDefinition>();
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) {
beanDefinitionMap.put(beanName,beanDefinition);
}
@Override
public void removeBeanDefinition(String beanName) throws Exception {
beanDefinitionMap.remove(beanName);
}
@Override
public BeanDefinition getBeanDefinition(String beanName) throws Exception {
return beanDefinitionMap.get(beanName);
}
@Override
public boolean containsBeanDefinition(String beanName) {
return beanDefinitionMap.containsKey(beanName);
}
@Override
public int getBeanDefinitionCount() {
return beanDefinitionMap.size();
}
@Override
public String[] getBeanDefinitionNames() {
return beanDefinitionMap.keySet().toArray(new String[1]);
}
}
3) 创建解析器相关的类
BeanDefinitionReader接口
- BeanDefinitionReader用来解析配置文件并在注册表中注册bean的信息。定义了两个规范:
- 获取注册表的功能,让外界可以通过该对象获取注册表对象
- 加载配置文件,并注册bean数据
/**
* 该类定义解析配置文件规则的接口
* @author spikeCong
* @date 2022/10/28
**/
public interface BeanDefinitionReader {
//获取注册表对象
BeanDefinitionRegistry getRegistry();
//加载配置文件并在注册表中进行注册
void loadBeanDefinitions(String configLocation) throws Exception;
}
XmlBeanDefinitionReader类
- XmlBeanDefinitionReader是专门用来解析xml配置文件的。该类实现BeanDefinitionReader接口并实现接口中的两个功能。
/**
* 该类是对XML文件进行解析的类
* @author spikeCong
* @date 2022/10/28
**/
public class XmlBeanDefinitionReader implements BeanDefinitionReader {
//声明注册表对象(将配置文件与注册表解耦,通过Reader降低耦合性)
private BeanDefinitionRegistry registry;
public XmlBeanDefinitionReader() {
registry = new SimpleBeanDefinitionRegistry();
}
@Override
public BeanDefinitionRegistry getRegistry() {
return registry;
}
//加载配置文件
@Override
public void loadBeanDefinitions(String configLocation) throws Exception {
//使用dom4j解析xml
SAXReader reader = new SAXReader();
//获取配置文件,类路径下
InputStream is = XmlBeanDefinitionReader.class.getClassLoader().getResourceAsStream(configLocation);
//获取document文档对象
Document document = reader.read(is);
Element rootElement = document.getRootElement();
//解析bean标签
parseBean(rootElement);
}
private void parseBean(Element rootElement) {
//获取所有的bean标签
List<Element> elements = rootElement.elements();
//遍历获取每个bean标签的属性值和子标签property
for (Element element : elements) {
String id = element.attributeValue("id");
String className = element.attributeValue("class");
//封装到beanDefinition
BeanDefinition beanDefinition = new BeanDefinition();
beanDefinition.setId(id);
beanDefinition.setClassName(className);
//获取property
List<Element> list = element.elements("property");
MutablePropertyValues mutablePropertyValues = new MutablePropertyValues();
//遍历,封装propertyValue,并保存到mutablePropertyValues
for (Element element1 : list) {
String name = element1.attributeValue("name");
String ref = element1.attributeValue("ref");
String value = element1.attributeValue("value");
PropertyValue propertyValue = new PropertyValue(name,ref,value);
mutablePropertyValues.addPropertyValue(propertyValue);
}
//将mutablePropertyValues封装到beanDefinition
beanDefinition.setPropertyValues(mutablePropertyValues);
System.out.println(beanDefinition);
//将beanDefinition注册到注册表
registry.registerBeanDefinition(id,beanDefinition);
}
}
}
4) 创建IOC容器相关的类
1) BeanFactory接口
在该接口中定义IOC容器的统一规范和获取bean对象的方法。
/**
* IOC容器父接口
* @author spikeCong
* @date 2022/10/28
**/
public interface BeanFactory {
Object getBean(String name)throws Exception;
//泛型方法,传入当前类或者其子类
<T> T getBean(String name ,Class<? extends T> clazz)throws Exception;
}
2) ApplicationContext接口
该接口的所有的子实现类对bean对象的创建都是非延时的,所以在该接口中定义 refresh() 方法,该方法主要完成以下两个功能:
- 加载配置文件。
- 根据注册表中的BeanDefinition对象封装的数据进行bean对象的创建。
/*


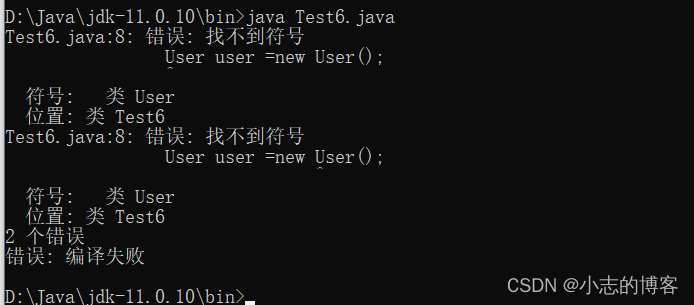



![[附源码]Node.js计算机毕业设计公司办公自动化系统Express](https://img-blog.csdnimg.cn/f5cf70d723ba4b93b0fe037666169b98.png)