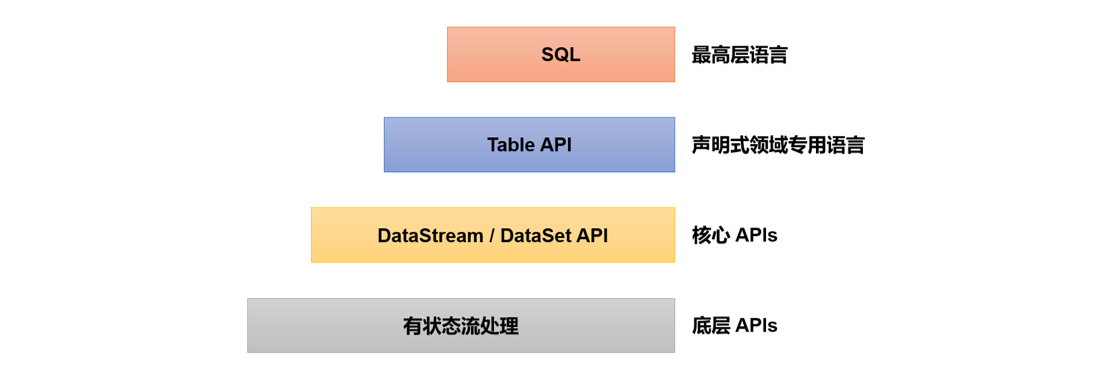
Table API和SQL是最上层的API,在Flink中这两种API被集成在一起,SQL执行的对象也是Flink中的表(Table),所以我们一般会认为它们是一体的。Flink是批流统一的处理框架,无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用Table API或者SQL来实现;这两种API对于一张表执行相同的查询操作,得到的结果是完全一样的。
需要说明的是,Table API和SQL最初并不完善,在Flink 1.9版本合并阿里巴巴内部版本Blink之后发生了非常大的改变,此后也一直处在快速开发和完善的过程中,直到Flink 1.12版本才基本上做到了功能上的完善。而即使是在目前最新的1.17版本中,Table API和SQL也依然不算稳定,接口用法还在不停调整和更新。所以这部分希望大家重在理解原理和基本用法,具体的API调用可以随时关注官网的更新变化。
SQL API 是基于 SQL 标准的 Apache Calcite 框架实现的,可通过纯 SQL 来开发和运行一个Flink 任务。
11.1 Flink SQL
11.1 sql-client准备
这里主要使用yarn-session模式,用sql client进行操作
11.1.1 基于yarn-session模式
1)启动Flink
[root@hadoop102 bin]# ./yarn-session.sh -d


2)启动Flink的sql-client
[root@hadoop102 bin]# ./sql-client.sh embedded -s yarn-session
11.1.2 常用的配置
1)结果显示模式
#默认table,还可以设置为tableau、changelog
SET sql-client.execution.result-mode=tableau;
2)执行环境
SET execution.runtime-mode=streaming; #默认streaming,也可以设置batch
3)默认并行度
SET parallelism.default=1;
5)设置状态TTL
SET table.exec.state.ttl=1000;
6)通过sql文件初始化
(1)创建sql文件
vim conf/sql-client-init.sql
SET sql-client.execution.result-mode=tableau;
CREATE DATABASE mydatabase;
(2)启动时,指定sql文件
/opt/module/flink-1.17.0/bin/sql-client.sh embedded -s yarn-session -i conf/sql-client-init.sql
11.2 流处理中的表
关系型表/SQL与流处理对比:
| 关系型表/SQL | 流处理 | |
|---|---|---|
| 处理的数据对象 | 字段元组的有界集合 | 字段元组的无限序列 |
| 查询(Query)对数据的访问 | 可以访问到完整的数据输入 | 无法访问到所有数据,必须“持续”等待流式输入 |
| 查询终止条件 | 生成固定大小的结果集后终止 | 永不停止,根据持续收到的数据不断更新查询结果 |
可以看到,其实关系型表和SQL,主要就是针对批处理设计的,这和流处理有着天生的隔阂。接下来我们就来深入探讨一下流处理中表的概念。
11.2.1 动态表和持续查询
流处理面对的数据是连续不断的,这导致了流处理中的“表”跟我们熟悉的关系型数据库中的表完全不同;而基于表执行的查询操作,也就有了新的含义。
1)动态表(Dynamic Tables)
当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的SQL查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为“动态表”(Dynamic Tables)。
动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。我们所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是“静态表”;而动态表则完全不同,它里面的数据会随时间变化。
2)持续查询(Continuous Query)
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的SQL查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作“持续查询”(Continuous Query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。
由于每次数据到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个“快照”(snapshot),当作有限数据集进行批处理;流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了“持续查询”。

持续查询的步骤如下:
(1)流(stream)被转换为动态表(dynamic table);
(2)对动态表进行持续查询(continuous query),生成新的动态表;
(3)生成的动态表被转换成流。
这样,只要API将流和动态表的转换封装起来,我们就可以直接在数据流上执行SQL查询,用处理表的方式来做流处理了。
11.2.2 将流转换成动态表
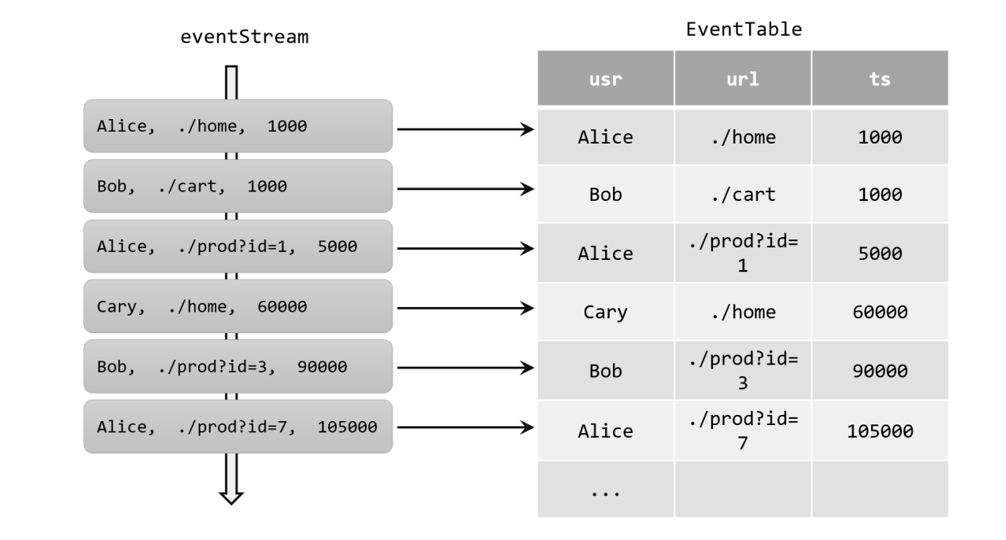
如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(Insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加;所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。
例如,当用户点击事件到来时,就对应着动态表中的一次插入(Insert)操作,每条数据就是表中的一行;随着插入更多的点击事件,得到的动态表将不断增长。
11.2.3 用SQL持续查询
1)更新(Update)查询
我们在代码中定义了一个SQL查询。
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");
当原始动态表不停地插入新的数据时,查询得到的urlCountTable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成DataStream,必须调用**toChangelogStream()**方法。

2)追加(Append)查询
上面的例子中,查询过程用到了分组聚合,结果表中就会产生更新操作。如果我们执行一个简单的条件查询,结果表中就会像原始表EventTable一样,只有插入(Insert)操作了。
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Cary'");
这样的持续查询,就被称为追加查询(Append Query),它定义的结果表的更新日志(changelog)流中只有INSERT操作。
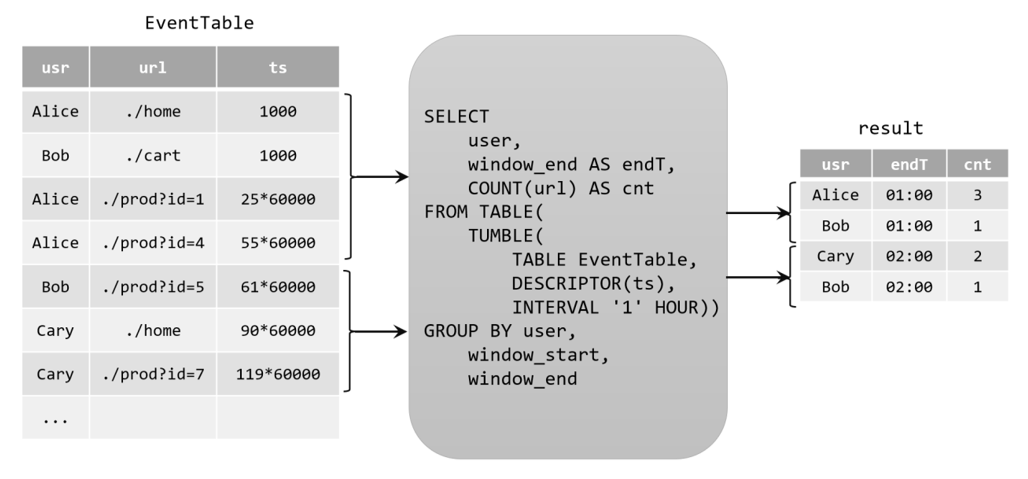
由于窗口的统计结果是一次性写入结果表的,所以结果表的更新日志流中只会包含插入INSERT操作,而没有更新UPDATE操作。所以这里的持续查询,依然是一个追加(Append)查询。结果表result如果转换成DataStream,可以直接调用toDataStream()方法。
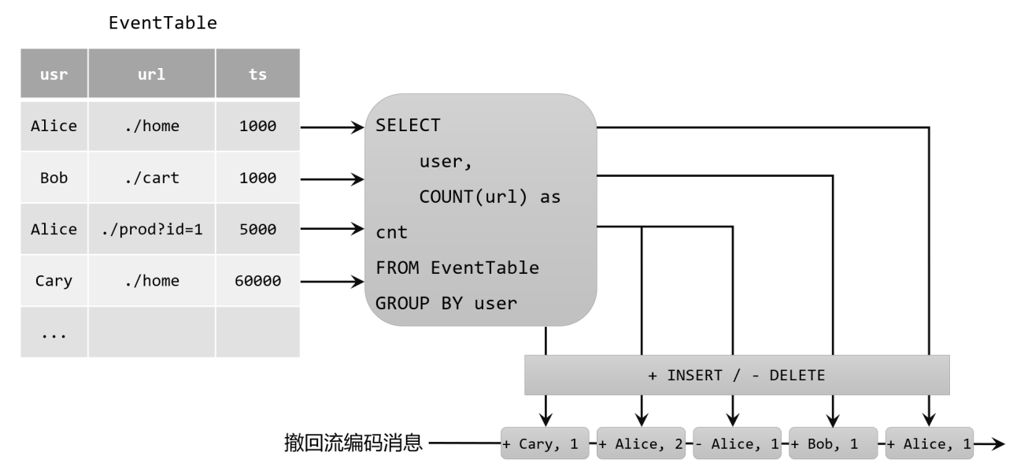
11.2.4 将动态表转换为流
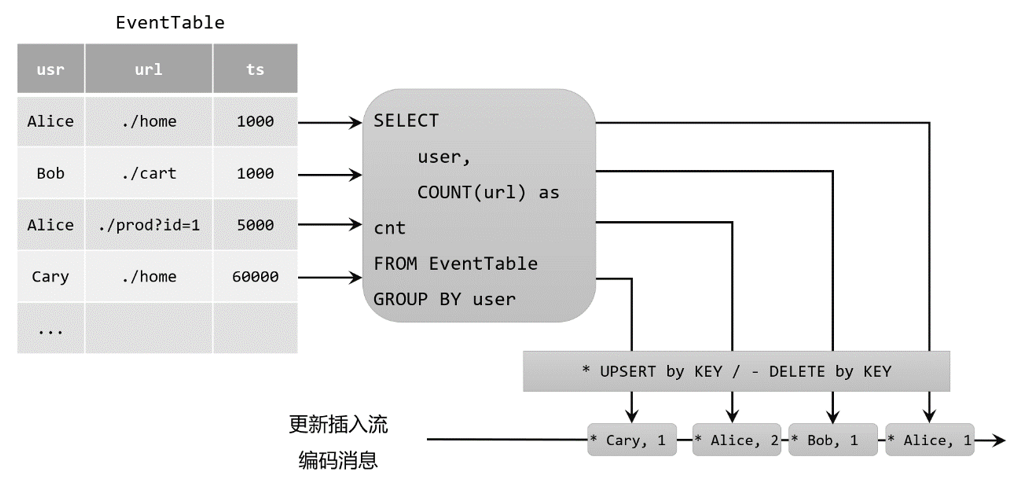
与关系型数据库中的表一样,动态表也可以通过插入(Insert)、更新(Update)和删除(Delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作.
在Flink中,Table API和SQL支持三种编码方式:
-
仅追加(Append-only)流
仅通过插入(Insert)更改来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据,其实就是动态表中新增的每一行。
-
撤回(Retract)流
撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。
具体的编码规则是:INSERT插入操作编码为add消息;DELETE删除操作编码为retract消息;而UPDATE更新操作则编码为被更改行的retract消息,和更新后行(新行)的add消息。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。
-
更新插入(Upsert)流
更新插入流中只包含两种类型的消息:更新插入(upsert)消息和删除(delete)消息。
所谓的“upsert”其实是“update”和“insert”的合成词,所以对于更新插入流来说,INSERT插入操作和UPDATE更新操作,统一被编码为upsert消息;而DELETE删除操作则被编码为delete消息。
需要注意的是,在代码里将动态表转换为DataStream时,只支持仅追加(append-only)和撤回(retract)流,我们调用toChangelogStream()得到的其实就是撤回流。而连接到外部系统时,则可以支持不同的编码方法,这取决于外部系统本身的特性。
11.3 时间属性
基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在Table API和SQL中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。
所以所谓的时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的DDL里直接定义为一个字段,也可以在DataStream转换成表时定义。一旦定义了时间属性,它就可以作为一个普通字段引用,并且可以在基于时间的操作中使用。
时间属性的数据类型必须为TIMESTAMP,它的行为类似于常规时间戳,可以直接访问并且进行计算。
按照时间语义的不同,可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。
11.3.1 事件时间
事件时间属性可以在创建表DDL中定义,增加一个字段,通过WATERMARK语句来定义事件时间属性。具体定义方式如下:
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...
);
这里我们把ts字段定义为事件时间属性,而且基于ts设置了5秒的水位线延迟。
时间戳类型必须是 TIMESTAMP 或者TIMESTAMP_LTZ 类型。但是时间戳一般都是秒或者是毫秒(BIGINT 类型),这种情况可以通过如下方式转换:
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
11.3.2 处理时间
在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。
在创建表的DDL(CREATE TABLE语句)中,可以增加一个额外的字段,通过调用系统内置的PROCTIME()函数来指定当前的处理时间属性。
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);
11.4 DDL(Data Definition Language)数据定义
11.4.1 数据库
1)创建数据库
(1)语法
CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name
[COMMENT database_comment]
WITH (key1=val1, key2=val2, ...)
(2)案例
CREATE DATABASE db_flink;
2)查询数据库
(1)查询所有数据库
SHOW DATABASES
(2)查询当前数据库
SHOW CURRENT DATABASE
3)修改数据库
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
4)删除数据库
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
RESTRICT:删除非空数据库会触发异常。默认启用
CASCADE:删除非空数据库也会删除所有相关的表和函数。
DROP DATABASE db_flink2;
5)切换当前数据库
USE database_name;
11.4.2 表
1)创建表
(1)语法
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
{ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] | AS select_query ]
① physical_column_definition
物理列是数据库中所说的常规列。其定义了物理介质中存储的数据中字段的名称、类型和顺序。其他类型的列可以在物理列之间声明,但不会影响最终的物理列的读取。
② metadata_column_definition
元数据列是 SQL 标准的扩展,允许访问数据源本身具有的一些元数据。元数据列由 METADATA 关键字标识。例如,我们可以使用元数据列从Kafka记录中读取和写入时间戳,用于基于时间的操作(这个时间戳不是数据中的某个时间戳字段,而是数据写入 Kafka 时,Kafka 引擎给这条数据打上的时间戳标记)。connector和format文档列出了每个组件可用的元数据字段。
CREATE TABLE MyTable ( `user_id` BIGINT, `name` STRING, `record_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka' ... );如果自定义的列名称和 Connector 中定义 metadata 字段的名称一样, FROM xxx 子句可省略
CREATE TABLE MyTable ( `user_id` BIGINT, `name` STRING, `timestamp` TIMESTAMP_LTZ(3) METADATA ) WITH ( 'connector' = 'kafka' ... );如果自定义列的数据类型和 Connector 中定义的 metadata 字段的数据类型不一致,程序运行时会自动 cast强转,但是这要求两种数据类型是可以强转的。 CREATE TABLE MyTable ( `user_id` BIGINT, `name` STRING, -- 将时间戳强转为 BIGINT `timestamp` BIGINT METADATA ) WITH ( 'connector' = 'kafka' ... ); 默认情况下,Flink SQL planner 认为 metadata 列可以读取和写入。然而,在许多情况下,外部系统提供的只读元数据字段比可写字段多。因此,可以使用VIRTUAL关键字排除元数据列的持久化(表示只读)。 CREATE TABLE MyTable ( `timestamp` BIGINT METADATA, `offset` BIGINT METADATA VIRTUAL, `user_id` BIGINT, `name` STRING, ) WITH ( 'connector' = 'kafka' ... );
③ computed_column_definition
计算列是使用语法column_name AS computed_column_expression生成的虚拟列。
计算列就是拿已有的一些列经过一些自定义的运算生成的新列,在物理上并不存储在表中,只能读不能写。列的数据类型从给定的表达式自动派生,无需手动声明。CREATE TABLE MyTable ( `user_id` BIGINT, `price` DOUBLE, `quantity` DOUBLE, `cost` AS price * quanitity ) WITH ( 'connector' = 'kafka' ... );
④ 定义Watermark
Flink SQL 提供了几种 WATERMARK 生产策略:
**严格升序:**WATERMARK FOR rowtime_column AS rowtime_column。
Flink 任务认为时间戳只会越来越大,也不存在相等的情况,只要相等或者小于之前的,就认为是迟到的数据。
**递增:**WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘0.001’ SECOND 。
一般基本不用这种方式。如果设置此类,则允许有相同的时间戳出现。
有界无序: WATERMARK FOR rowtime_column AS rowtime_column – INTERVAL ‘string’ timeUnit 。
此类策略就可以用于设置最大乱序时间,假如设置为 WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘5’ SECOND ,则生成的是运行 5s 延迟的Watermark。一般都用这种 Watermark 生成策略,此类 Watermark 生成策略通常用于有数据乱序的场景中,而对应到实际的场景中,数据都是会存在乱序的,所以基本都使用此类策略。
⑤ PRIMARY KEY
主键约束表明表中的一列或一组列是唯一的,并且它们不包含NULL值。主键唯一地标识表中的一行,只支持 not enforced。
CREATE TABLE MyTable ( `user_id` BIGINT, `name` STRING, PARYMARY KEY(user_id) not enforced ) WITH ( 'connector' = 'kafka' ... );
⑥ PARTITIONED BY
创建分区表
⑦ with语句
用于创建表的表属性,用于指定外部存储系统的元数据信息。配置属性时,表达式key1=val1的键和值都应该是字符串字面值。如下是Kafka的映射表:
CREATE TABLE KafkaTable (
user_idBIGINT,
nameSTRING,
tsTIMESTAMP(3) METADATA FROM ‘timestamp’
) WITH (
‘connector’ = ‘kafka’,
‘topic’ = ‘user_behavior’,
‘properties.bootstrap.servers’ = ‘localhost:9092’,
‘properties.group.id’ = ‘testGroup’,
‘scan.startup.mode’ = ‘earliest-offset’,
‘format’ = ‘csv’
)
一般 with 中的配置项由 Flink SQL 的 Connector(链接外部存储的连接器) 来定义,每种 Connector 提供的with 配置项都是不同的。
⑧ LIKE
用于基于现有表的定义创建表。此外,用户可以扩展原始表或排除表的某些部分。
可以使用该子句重用(可能还会覆盖)某些连接器属性,或者向外部定义的表添加水印。CREATE TABLE Orders ( `user` BIGINT, product STRING, order_time TIMESTAMP(3) ) WITH ( 'connector' = 'kafka', 'scan.startup.mode' = 'earliest-offset' ); CREATE TABLE Orders_with_watermark ( -- Add watermark definition WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND ) WITH ( -- Overwrite the startup-mode 'scan.startup.mode' = 'latest-offset' ) LIKE Orders;
⑨ AS select_statement(CTAS)
在一个create-table-as-select (CTAS)语句中,还可以通过查询的结果创建和填充表。CTAS是使用单个命令创建数据并向表中插入数据的最简单、最快速的方法。
CREATE TABLE my_ctas_table WITH ( 'connector' = 'kafka', ... ) AS SELECT id, name, age FROM source_table WHERE mod(id, 10) = 0;注意:CTAS有以下限制:
-暂不支持创建临时表。
-目前还不支持指定显式列。
-还不支持指定显式水印。
-目前还不支持创建分区表。
-目前还不支持指定主键约束。
(2)简单建表示例CREATE TABLE test( id INT, ts BIGINT, vc INT ) WITH ( 'connector' = 'print' ); CREATE TABLE test1 ( `value` STRING ) LIKE test;
2)查看表
(1)查看所有表
SHOW TABLES [ ( FROM | IN ) [catalog_name.]database_name ] [ [NOT] LIKE <sql_like_pattern> ]
如果没有指定数据库,则从当前数据库返回表。
LIKE子句中sql pattern的语法与MySQL方言的语法相同:
- %匹配任意数量的字符,甚至零字符,\%匹配一个'%'字符。
- _只匹配一个字符,\_只匹配一个'_'字符
(2)查看表信息
{ DESCRIBE | DESC } [catalog_name.][db_name.]table_name
3)修改表
(1)修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
(2)修改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
4)删除表
DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
11.5 查询
11.5.0 DataGen & Print
1)创建数据生成器源表
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'datagen',
'rows-per-second'='1',
'fields.id.kind'='random',
'fields.id.min'='1',
'fields.id.max'='10',
'fields.ts.kind'='sequence',
'fields.ts.start'='1',
'fields.ts.end'='1000000',
'fields.vc.kind'='random',
'fields.vc.min'='1',
'fields.vc.max'='100'
);
CREATE TABLE sink (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);
2)查询源表
select * from source
3)插入sink表并查询
INSERT INTO sink select * from source;
select * from sink;
11.5.1 With子句
WITH提供了一种编写辅助语句的方法,以便在较大的查询中使用。这些语句通常被称为公共表表达式(Common Table Expression, CTE),可以认为它们定义了仅为一个查询而存在的临时视图。
1)语法
WITH <with_item_definition> [ , ... ]
SELECT ... FROM ...;
<with_item_defintion>:
with_item_name (column_name[, ...n]) AS ( <select_query> )
2)案例
WITH source_with_total AS (
SELECT id, vc+10 AS total
FROM source
)
SELECT id, SUM(total)
FROM source_with_total
GROUP BY id;
11.5.2 SELECT & WHERE 子句
1)语法
SELECT select_list FROM table_expression [ WHERE boolean_expression ]
2)案例
SELECT * FROM source
SELECT id, vc + 10 FROM source
-- 自定义 Source 的数据
SELECT id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price)
SELECT vc + 10 FROM source WHERE id >10
11.5.3 SELECT DISTINCT 子句
用作根据 key 进行数据去重
SELECT DISTINCT vc FROM source
对于流查询,计算查询结果所需的状态可能无限增长。状态大小取决于不同行数。可以设置适当的状态生存时间(TTL)的查询配置,以防止状态过大。但是,这可能会影响查询结果的正确性。如某个 key 的数据过期从状态中删除了,那么下次再来这么一个 key,由于在状态中找不到,就又会输出一遍。
11.5.4 分组聚合
SQL中一般所说的聚合我们都很熟悉,主要是通过内置的一些聚合函数来实现的,比如SUM()、MAX()、MIN()、AVG()以及COUNT()。它们的特点是对多条输入数据进行计算,得到一个唯一的值,属于“多对一”的转换。比如我们可以通过下面的代码计算输入数据的个数:
select COUNT(*) from source;
而更多的情况下,我们可以通过GROUP BY子句来指定分组的键(key),从而对数据按照某个字段做一个分组统计。
SELECT vc, COUNT(*) as cnt FROM source GROUP BY vc;
这种聚合方式,就叫作“分组聚合”(group aggregation)。想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream)或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成DataStream打印输出,需要调用toChangelogStream()。
分组聚合既是SQL原生的聚合查询,也是流处理中的聚合操作,这是实际应用中最常见的聚合方式。当然,使用的聚合函数一般都是系统内置的,如果希望实现特殊需求也可以进行自定义。
1)group聚合案例
CREATE TABLE source1 (
dim STRING,
user_id BIGINT,
price BIGINT,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.dim.length' = '1',
'fields.user_id.min' = '1',
'fields.user_id.max' = '100000',
'fields.price.min' = '1',
'fields.price.max' = '100000'
);
CREATE TABLE sink1 (
dim STRING,
pv BIGINT,
sum_price BIGINT,
max_price BIGINT,
min_price BIGINT,
uv BIGINT,
window_start bigint
) WITH (
'connector' = 'print'
);
insert into sink1
select dim,
count(*) as pv,
sum(price) as sum_price,
max(price) as max_price,
min(price) as min_price,
-- 计算 uv 数
count(distinct user_id) as uv,
cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint) as window_start
from source1
group by
dim,
-- UNIX_TIMESTAMP得到秒的时间戳,将秒级别时间戳 / 60 转化为 1min,
cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint)
2)多维分析
Group 聚合也支持 Grouping sets 、Rollup 、Cube,如下案例是Grouping sets:
SELECT
supplier_id
, rating
, product_id
, COUNT(*)
FROM (
VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
)
-- 供应商id、产品id、评级
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS(
(supplier_id, product_id, rating),
(supplier_id, product_id),
(supplier_id, rating),
(supplier_id),
(product_id, rating),
(product_id),
(rating),
()
);
11.5.5 分组窗口聚合
从1.13版本开始,分组窗口聚合已经标记为过时,鼓励使用更强大、更有效的窗口TVF聚合,在这里简单做个介绍。
直接把窗口自身作为分组key放在GROUP BY之后的,所以也叫“分组窗口聚合”。SQL查询的分组窗口是通过 GROUP BY 子句定义的。类似于使用常规 GROUP BY 语句的查询,窗口分组语句的 GROUP BY 子句中带有一个窗口函数为每个分组计算出一个结果。
SQL中只支持基于时间的窗口,不支持基于元素个数的窗口。
| 分组窗口函数 | 描述 |
|---|---|
| TUMBLE(time_attr, interval) | 定义一个滚动窗口。滚动窗口把行分配到有固定持续时间( interval )的不重叠的连续窗口。比如,5 分钟的滚动窗口以 5 分钟为间隔对行进行分组。滚动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。 |
| HOP(time_attr, interval, interval) | 定义一个跳跃的时间窗口(在 Table API 中称为滑动窗口)。滑动窗口有一个固定的持续时间( 第二个 interval 参数 )以及一个滑动的间隔(第一个 interval 参数 )。若滑动间隔小于窗口的持续时间,滑动窗口则会出现重叠;因此,行将会被分配到多个窗口中。比如,一个大小为 15 分组的滑动窗口,其滑动间隔为 5 分钟,将会把每一行数据分配到 3 个 15 分钟的窗口中。滑动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。 |
| SESSION(time_attr, interval) | 定义一个会话时间窗口。会话时间窗口没有一个固定的持续时间,但是它们的边界会根据 interval 所定义的不活跃时间所确定;即一个会话时间窗口在定义的间隔时间内没有时间出现,该窗口会被关闭。例如时间窗口的间隔时间是 30 分钟,当其不活跃的时间达到30分钟后,若观测到新的记录,则会启动一个新的会话时间窗口(否则该行数据会被添加到当前的窗口),且若在 30 分钟内没有观测到新纪录,这个窗口将会被关闭。会话时间窗口可以使用事件时间(批处理、流处理)或处理时间(流处理)。 |

1)准备数据
CREATE TABLE ws (
id INT,
vc INT,
pt AS PROCTIME(), --处理时间
et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
WATERMARK FOR et AS et - INTERVAL '5' SECOND --watermark
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.id.min' = '1',
'fields.id.max' = '3',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);
2)滚动窗口示例(时间属性字段,窗口长度)
select
id,
TUMBLE_START(et, INTERVAL '5' SECOND) wstart,
TUMBLE_END(et, INTERVAL '5' SECOND) wend,
sum(vc) sumVc
from ws
group by id, TUMBLE(et, INTERVAL '5' SECOND);
3)滑动窗口(时间属性字段,滑动步长,窗口长度)
select
id,
HOP_START(pt, INTERVAL '3' SECOND,INTERVAL '5' SECOND) wstart,
HOP_END(pt, INTERVAL '3' SECOND,INTERVAL '5' SECOND) wend,
sum(vc) sumVc
from ws
group by id, HOP(et, INTERVAL '3' SECOND,INTERVAL '5' SECOND);
4)会话窗口(时间属性字段,会话间隔)
select
id,
SESSION_START(et, INTERVAL '5' SECOND) wstart,
SESSION_END(et, INTERVAL '5' SECOND) wend,
sum(vc) sumVc
from ws
group by id, SESSION(et, INTERVAL '5' SECOND);
11.5.6 窗口表值函数(TVF)聚合
对比GroupWindow,TVF窗口更有效和强大。包括:
-
提供更多的性能优化手段
-
支持GroupingSets语法
-
可以在window聚合中使用TopN
-
提供累积窗口
对于窗口表值函数,窗口本身返回的是就是一个表,所以窗口会出现在FROM后面,GROUP BY后面的则是窗口新增的字段window_start和window_end
FROM TABLE(
窗口类型(TABLE 表名, DESCRIPTOR(时间字段),INTERVAL时间…)
)
GROUP BY [window_start,][window_end,] --可选
1)滚动窗口
SELECT
window_start,
window_end,
id , SUM(vc)
sumVC
FROM TABLE(
TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS))
GROUP BY window_start, window_end, id;
2)滑动窗口
要求: 窗口长度=滑动步长的整数倍(底层会优化成多个小滚动窗口)
SELECT window_start, window_end, id , SUM(vc) sumVC
FROM TABLE(
HOP(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS , INTERVAL '10' SECONDS))
GROUP BY window_start, window_end, id;
3)累积窗口

累积窗口会在一定的统计周期内进行累积计算。累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。所谓的最大窗口长度其实就是我们所说的“统计周期”,最终目的就是统计这段时间内的数据。
其实就是固定窗口间隔内提前触发的的滚动窗口 ,其实就是 Tumble Window + early-fire 的一个事件时间的版本。例如,从每日零点到当前这一分钟绘制累积 UV,其中 10:00 时的 UV 表示从 00:00 到 10:00 的 UV 总数。
累积窗口可以认为是首先开一个最大窗口大小的滚动窗口,然后根据用户设置的触发的时间间隔将这个滚动窗口拆分为多个窗口,这些窗口具有相同的窗口起点和不同的窗口终点。
注意: 窗口最大长度 = 累积步长的整数倍
SELECT
window_start,
window_end,
id ,
SUM(vc) sumVC
FROM TABLE(
CUMULATE(TABLE ws, DESCRIPTOR(et), INTERVAL '2' SECONDS , INTERVAL '6' SECONDS))
GROUP BY window_start, window_end, id;
4)grouping sets多维分析
SELECT
window_start,
window_end,
id ,
SUM(vc) sumVC
FROM TABLE(
TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS))
GROUP BY window_start, window_end,
rollup( (id) )
-- cube( (id) )
-- grouping sets( (id),() )
;
11.5.7 Over聚合
OVER聚合为一系列有序行的每个输入行计算一个聚合值。与GROUP BY聚合相比,OVER聚合不会将每个组的结果行数减少为一行。相反,OVER聚合为每个输入行生成一个聚合值。
可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义Over windows。
1)语法
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, ...]]
ORDER BY time_col
range_definition),
...
FROM ...
ORDER BY:必须是时间戳列(事件时间、处理时间),只能升序
PARTITION BY:标识了聚合窗口的聚合粒度
range_definition:这个标识聚合窗口的聚合数据范围,在 Flink 中有两种指定数据范围的方式。第一种为按照行数聚合,第二种为按照时间区间聚合
2)案例
(1)按照时间区间聚合
统计每个传感器前10秒到现在收到的水位数据条数。
SELECT
id,
et,
vc,
count(vc) OVER (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
) AS cnt
FROM ws
也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口,可以多次使用:
SELECT
id,
et,
vc,
count(vc) OVER w AS cnt,
sum(vc) OVER w AS sumVC
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
)
(2)按照行数聚合
统计每个传感器前5条到现在数据的平均水位
SELECT
id,
et,
vc,
avg(vc) OVER (
PARTITION BY id
ORDER BY et
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
) AS avgVC
FROM ws
也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口:
SELECT
id,
et,
vc,
avg(vc) OVER w AS avgVC,
count(vc) OVER w AS cnt
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
)
11.5.8 特殊语法 —— TOP-N
目前在Flink SQL中没有能够直接调用的TOP-N函数,而是提供了稍微复杂些的变通实现方法,是固定写法,特殊支持的over用法。
1)语法
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]
ROW_NUMBER() :标识 TopN 排序子句
PARTITION BY col1[, col2...] :标识分区字段,代表按照这个 col 字段作为分区粒度对数据进行排序取 topN,比如下述案例中的 partition by key ,就是根据需求中的搜索关键词(key)做为分区
ORDER BY col1 [asc|desc][, col2 [asc|desc]...] :标识 TopN 的排序规则,是按照哪些字段、顺序或逆序进行排序,可以不是时间字段,也可以降序(TopN特殊支持)
WHERE rownum <= N :这个子句是一定需要的,只有加上了这个子句,Flink 才能将其识别为一个TopN 的查询,其中 N 代表 TopN 的条目数
[AND conditions] :其他的限制条件也可以加上
2)案例
取每个传感器最高的3个水位值
select
id,
et,
vc,
rownum
from
(
select
id,
et,
vc,
row_number() over(
partition by id
order by vc desc
) as rownum
from ws
)
where rownum<=3;
11.5.9 特殊语法 —— Deduplication去重
去重,也即上文介绍到的TopN 中 row_number = 1 的场景,但是这里有一点不一样在于其排序字段一定是时间属性列,可以降序,不能是其他非时间属性的普通列。
在 row_number = 1 时,如果排序字段是普通列 planner 会翻译成 TopN 算子,如果是时间属性列 planner 会翻译成 Deduplication,这两者最终的执行算子是不一样的,Deduplication 相比 TopN 算子专门做了对应的优化,性能会有很大提升。可以从webui看出是翻译成哪种算子。
如果是按照时间属性字段降序,表示取最新一条,会造成不断的更新保存最新的一条。如果是升序,表示取最早的一条,不用去更新,性能更好。
1)语法
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY time_attr [asc|desc]) AS rownum
FROM table_name)
WHERE rownum = 1
2)案例
对每个传感器的水位值去重
select
id,
et,
vc,
rownum
from
(
select
id,
et,
vc,
row_number() over(
partition by id,vc
order by et
) as rownum
from ws
)
where rownum=1;
11.5.10 联结(Join)查询
在标准SQL中,可以将多个表连接合并起来,从中查询出想要的信息;这种操作就是表的联结(Join)。在Flink SQL中,同样支持各种灵活的联结(Join)查询,操作的对象是动态表。
在流处理中,动态表的Join对应着两条数据流的Join操作。Flink SQL中的联结查询大体上也可以分为两类:SQL原生的联结查询方式,和流处理中特有的联结查询
1.常规联结查询
常规联结(Regular Join)是SQL中原生定义的Join方式,是最通用的一类联结操作。它的具体语法与标准SQL的联结完全相同,通过关键字JOIN来联结两个表,后面用关键字ON来指明联结条件。
与标准SQL一致,Flink SQL的常规联结也可以分为内联结(INNER JOIN)和外联结(OUTER JOIN),区别在于结果中是否包含不符合联结条件的行。
Regular Join 包含以下几种(以 L 作为左流中的数据标识, R 作为右流中的数据标识):
- Inner Join(Inner Equal Join):流任务中,只有两条流 Join 到才输出,输出 +[L, R]
- Left Join(Outer Equal Join):流任务中,左流数据到达之后,无论有没有 Join 到右流的数据,都会输出(Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] ),如果右流之后数据到达之后,发现左流之前输出过没有 Join 到的数据,则会发起回撤流,先输出 -[L, null] ,然后输出 +[L, R]
- Right Join(Outer Equal Join):有 Left Join 一样,左表和右表的执行逻辑完全相反
- Full Join(Outer Equal Join):流任务中,左流或者右流的数据到达之后,无论有没有 Join 到另外一条流的数据,都会输出(对右流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[null, R] ;对左流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] )。如果一条流的数据到达之后,发现之前另一条流之前输出过没有 Join 到的数据,则会发起回撤流(左流数据到达为例:回撤 -[null, R] ,输出+[L, R] ,右流数据到达为例:回撤 -[L, null] ,输出 +[L, R]
Regular Join 的注意事项:
Ø 实时 Regular Join 可以不是 等值 join 。等值 join 和 非等值 join 区别在于, 等值 join数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游; 非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,按照非等值条件进行关联
Ø 流的上游是无限的数据,所以要做到关联的话,Flink 会将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会无限增大,因此你需要为 State 配置合适的 TTL,以防止 State 过大。
CREATE TABLE ws1 (
id INT,
vc INT,
pt AS PROCTIME(), --处理时间
et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
WATERMARK FOR et AS et - INTERVAL '0.001' SECOND --watermark
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.id.min' = '3',
'fields.id.max' = '5',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);
1)等值内联结(INNER Equi-JOIN)
内联结用INNER JOIN来定义,会返回两表中符合联接条件的所有行的组合,也就是所谓的笛卡尔积(Cartesian product)。目前仅支持等值联结条件。
SELECT *
FROM ws
INNER JOIN ws1
ON ws.id = ws1.id
2)等值外联结(OUTER Equi-JOIN)
与内联结类似,外联结也会返回符合联结条件的所有行的笛卡尔积;另外,还可以将某一侧表中找不到任何匹配的行也单独返回。Flink SQL支持左外(LEFT JOIN)、右外(RIGHT JOIN)和全外(FULL OUTER JOIN),分别表示会将左侧表、右侧表以及双侧表中没有任何匹配的行返回。
具体用法如下:
SELECT *
FROM ws
LEFT JOIN ws1
ON ws.id = ws1.id
SELECT *
FROM ws
RIGHT JOIN ws1
ON ws.id = ws1.id
SELECT *
FROM ws
FULL OUTER JOIN ws1
ON ws.id = ws.id
这部分知识与标准SQL中是完全一样的。
2.间隔联结查询
我们曾经学习过DataStream API中的双流Join,包括窗口联结(window join)和间隔联结(interval join)。两条流的Join就对应着SQL中两个表的Join,这是流处理中特有的联结方式。目前Flink SQL还不支持窗口联结,而间隔联结则已经实现。
间隔联结(Interval Join)返回的,同样是符合约束条件的两条中数据的笛卡尔积。只不过这里的“约束条件”除了常规的联结条件外,还多了一个时间间隔的限制。具体语法有以下要点:
-
两表的联结
间隔联结不需要用JOIN关键字,直接在FROM后将要联结的两表列出来就可以,用逗号分隔。这与标准SQL中的语法一致,表示一个“交叉联结”(Cross Join),会返回两表中所有行的笛卡尔积。
-
联结条件
联结条件用WHERE子句来定义,用一个等值表达式描述。交叉联结之后再用WHERE进行条件筛选,效果跟内联结INNER JOIN … ON …非常类似。
-
时间间隔限制
我们可以在WHERE子句中,联结条件后用AND追加一个时间间隔的限制条件;做法是提取左右两侧表中的时间字段,然后用一个表达式来指明两者需要满足的间隔限制。具体定义方式有下面三种,这里分别用ltime和rtime表示左右表中的时间字段:
(1)ltime = rtime
(2)ltime >= rtime AND ltime < rtime + INTERVAL ‘10’ MINUTE
(3)ltime BETWEEN rtime - INTERVAL ‘10’ SECOND AND rtime + INTERVAL ‘5’ SECOND
SELECT *
FROM ws,ws1
WHERE ws.id = ws1. id
AND ws.et BETWEEN ws1.et - INTERVAL '2' SECOND AND ws1.et + INTERVAL '2' SECOND
3.维表联结查询
Lookup Join 其实就是维表 Join,实时获取外部缓存的 Join,Lookup 的意思就是实时查找。
上面说的这几种 Join 都是流与流之间的 Join,而 Lookup Join 是流与 Redis,Mysql,HBase 这种外部存储介质的 Join。仅支持处理时间字段。
表A
JOIN 维度表名 FOR SYSTEM_TIME AS OF 表A.proc_time AS 别名
ON xx.字段=别名.字段
比如维表在mysql,维表join的写法如下:
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop102:3306/customerdb',
'table-name' = 'customers'
);
-- order表每来一条数据,都会去mysql的customers表查找维度数据
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;
11.5.11 Order by 和 limit
1)order by
支持 Batch\Streaming,但在实时任务中一般用的非常少。
实时任务中,Order By 子句中必须要有时间属性字段,并且必须写在最前面且为升序。
SELECT *
FROM ws
ORDER BY et, id desc
2)limit
SELECT *
FROM ws
LIMIT 3
11.5.12 SQL Hints
在执行查询时,可以在表名后面添加SQL Hints来临时修改表属性,对当前job生效。
select * from ws1/*+ OPTIONS('rows-per-second'='10')*/;
11.5.13 集合操作
1)UNION 和 UNION ALL
UNION:将集合合并并且去重
UNION ALL:将集合合并,不做去重。
(SELECT id FROM ws) UNION (SELECT id FROM ws1);
(SELECT id FROM ws) UNION ALL (SELECT id FROM ws1);
2)Intersect 和 Intersect All
Intersect:交集并且去重
Intersect ALL:交集不做去重
(SELECT id FROM ws) INTERSECT (SELECT id FROM ws1);
(SELECT id FROM ws) INTERSECT ALL (SELECT id FROM ws1);
3)Except 和 Except All
Except:差集并且去重
Except ALL:差集不做去重
(SELECT id FROM ws) EXCEPT (SELECT id FROM ws1);
(SELECT id FROM ws) EXCEPT ALL (SELECT id FROM ws1);
上述 SQL 在流式任务中,如果一条左流数据先来了,没有从右流集合数据中找到对应的数据时会直接输出,当右流对应数据后续来了之后,会下发回撤流将之前的数据給撤回。这也是一个回撤流
4)In 子查询
In 子查询的结果集只能有一列
SELECT id, vc
FROM ws
WHERE id IN (
SELECT id FROM ws1
)
上述 SQL 的 In 子句和之前介绍到的 Inner Join 类似。并且 In 子查询也会涉及到大状态问题,要注意设置 State 的 TTL。
11.5.14 系统函数
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/functions/systemfunctions/
系统函数(System Functions)也叫内置函数(Built-in Functions),是在系统中预先实现好的功能模块。我们可以通过固定的函数名直接调用,实现想要的转换操作。Flink SQL提供了大量的系统函数,几乎支持所有的标准SQL中的操作,这为我们使用SQL编写流处理程序提供了极大的方便。
Flink SQL中的系统函数又主要可以分为两大类:标量函数(Scalar Functions)和聚合函数(Aggregate Functions)。
1)标量函数(Scalar Functions)
标量函数指的就是只对输入数据做转换操作、返回一个值的函数。
标量函数是最常见、也最简单的一类系统函数,数量非常庞大,很多在标准SQL中也有定义。所以我们这里只对一些常见类型列举部分函数,做一个简单概述,具体应用可以查看官网的完整函数列表。
-
比较函数(Comparison Functions)
比较函数其实就是一个比较表达式,用来判断两个值之间的关系,返回一个布尔类型的值。这个比较表达式可以是用 <、>、= 等符号连接两个值,也可以是用关键字定义的某种判断。例如:
(1)value1 = value2 判断两个值相等;
(2)value1 <> value2 判断两个值不相等
(3)value IS NOT NULL 判断value不为空 -
逻辑函数(Logical Functions)
逻辑函数就是一个逻辑表达式,也就是用与(AND)、或(OR)、非(NOT)将布尔类型的值连接起来,也可以用判断语句(IS、IS NOT)进行真值判断;返回的还是一个布尔类型的值。例如:
(1)boolean1 OR boolean2 布尔值boolean1与布尔值boolean2取逻辑或
(2)boolean IS FALSE 判断布尔值boolean是否为false
(3)NOT boolean 布尔值boolean取逻辑非 -
算术函数(Arithmetic Functions)
进行算术计算的函数,包括用算术符号连接的运算,和复杂的数学运算。例如:
(1)numeric1 + numeric2 两数相加
(2)POWER(numeric1, numeric2) 幂运算,取数numeric1的numeric2次方
(3)RAND() 返回(0.0, 1.0)区间内的一个double类型的伪随机数 -
字符串函数(String Functions)
进行字符串处理的函数。例如:
(1)string1 || string2 两个字符串的连接
(2)UPPER(string) 将字符串string转为全部大写
(3)CHAR_LENGTH(string) 计算字符串string的长度 -
时间函数(Temporal Functions)
进行与时间相关操作的函数。例如:
(1)DATE string 按格式"yyyy-MM-dd"解析字符串string,返回类型为SQL Date
(2)TIMESTAMP string 按格式"yyyy-MM-dd HH:mm:ss[.SSS]"解析,返回类型为SQL timestamp
(3)CURRENT_TIME 返回本地时区的当前时间,类型为SQL time(与LOCALTIME等价)
(4)INTERVAL string range 返回一个时间间隔。
2)聚合函数(Aggregate Functions)
聚合函数是以表中多个行作为输入,提取字段进行聚合操作的函数,会将唯一的聚合值作为结果返回。聚合函数应用非常广泛,不论分组聚合、窗口聚合还是开窗(Over)聚合,对数据的聚合操作都可以用相同的函数来定义。
标准SQL中常见的聚合函数Flink SQL都是支持的,目前也在不断扩展,为流处理应用提供更强大的功能。例如:
(1)COUNT(*) 返回所有行的数量,统计个数。
(2)SUM([ ALL | DISTINCT ] expression) 对某个字段进行求和操作。默认情况下省略了关键字ALL,表示对所有行求和;如果指定DISTINCT,则会对数据进行去重,每个值只叠加一次。
(3)RANK() 返回当前值在一组值中的排名。
(4)ROW_NUMBER() 对一组值排序后,返回当前值的行号。
其中,RANK()和ROW_NUMBER()一般用在OVER窗口中。
11.5.15 Module操作
Module 允许 Flink 扩展函数能力。它是可插拔的,Flink 官方本身已经提供了一些 Module,用户也可以编写自己的 Module。
目前 Flink 包含了以下三种 Module:
-
CoreModule:CoreModule 是 Flink 内置的 Module,其包含了目前 Flink 内置的所有 UDF,Flink 默认开启的 Module 就是 CoreModule,我们可以直接使用其中的 UDF
-
HiveModule:HiveModule 可以将 Hive 内置函数作为 Flink 的系统函数提供给 SQL\Table API 用户进行使用,比如 get_json_object 这类 Hive 内置函数(Flink 默认的 CoreModule 是没有的)
-
用户自定义 Module:用户可以实现 Module 接口实现自己的 UDF 扩展 Module使用 LOAD 子句去加载 Flink SQL 体系内置的或者用户自定义的 Module,UNLOAD 子句去卸载 Flink SQL 体系内置的或者用户自定义的 Module。
1)语法
-- 加载
LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)]
-- 卸载
UNLOAD MODULE module_name
-- 查看
SHOW MODULES;
SHOW FULL MODULES;
在 Flink 中,Module 可以被 加载、启用 、禁用 、卸载 Module,当加载Module 之后,默认就是开启的。同时支持多个 Module 的,并且根据加载 Module 的顺序去按顺序查找和解析 UDF,先查到的先解析使用。
此外,Flink 只会解析已经启用了的 Module。那么当两个 Module 中出现两个同名的函数且都启用时, Flink 会根据加载 Module 的顺序进行解析,结果就是会使用顺序为第一个的 Module 的 UDF,可以使用下面语法更改顺序:
USE MODULE hive,core;
USE是启用module,没有被use的为禁用(禁用不是卸载),除此之外还可以实现调整顺序的效果。上面的语句会将 Hive Module 设为第一个使用及解析的 Module。
2)案例
加载官方已经提供的的 Hive Module,将 Hive 已有的内置函数作为 Flink 的内置函数。需要先引入 hive 的 connector。其中包含了 flink 官方提供的一个 HiveModule。
(1)上传jar包到flink的lib中
上传hive connector
cp flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar /opt/module/flink-1.17.0/lib/
注意:拷贝hadoop的包,解决依赖冲突问题
cp /opt/module/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.4.jar /opt/module/flink-1.17.0/lib/
(2)重启flink集群和sql-client
(3)加载hive module
-- hive-connector内置了hive module,提供了hive自带的系统函数
load module hive with ('hive-version'='3.1.3');
show modules;
show functions;
-- 可以调用hive的split函数
select split('a,b', ',');
11.6 常用 Connector 读写
参考官网:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/table/overview/
11.6.1 Kafka
1)添加kafka连接器依赖
(1)将flink-sql-connector-kafka-1.17.0.jar上传到flink的lib目录下
(2)重启yarn-session、sql-client
2)普通Kafka表
(1)创建Kafka的映射表
CREATE TABLE t1(
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
--列名和元数据名一致可以省略 FROM 'xxxx', VIRTUAL表示只读
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
id int,
ts bigint ,
vc int )
WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = 'hadoop103:9092',
'properties.group.id' = 'atguigu',
-- 'earliest-offset', 'latest-offset', 'group-offsets', 'timestamp' and 'specific-offsets'
'scan.startup.mode' = 'earliest-offset',
-- fixed为flink实现的分区器,一个并行度只写往kafka一个分区
'sink.partitioner' = 'fixed',
'topic' = 'ws1',
'format' = 'json'
)
(2)插入Kafka表
insert into t1(id,ts,vc) select * from source
(3)查询Kafka表
select * from t1
2)upsert-kafka表
如果当前表存在更新操作,那么普通的kafka连接器将无法满足,此时可以使用Upsert Kafka连接器。
Upsert Kafka 连接器支持以 upsert 方式从 Kafka topic 中读取数据并将数据写入 Kafka topic。
作为 source,upsert-kafka 连接器生产 changelog 流,其中每条数据记录代表一个更新或删除事件。更准确地说,数据记录中的 value 被解释为同一 key 的最后一个 value 的 UPDATE,如果有这个 key(如果不存在相应的 key,则该更新被视为 INSERT)。用表来类比,changelog 流中的数据记录被解释为 UPSERT,也称为 INSERT/UPDATE,因为任何具有相同 key 的现有行都被覆盖。另外,value 为空的消息将会被视作为 DELETE 消息。
作为 sink,upsert-kafka 连接器可以消费 changelog 流。它会将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,从而保证主键上的消息有序,因此同一主键上的更新/删除消息将落在同一分区中。
(1)创建upsert-kafka的映射表(必须定义主键)
CREATE TABLE t2(
id int ,
sumVC int ,
primary key (id) NOT ENFORCED
)
WITH (
'connector' = 'upsert-kafka',
'properties.bootstrap.servers' = 'hadoop102:9092',
'topic' = 'ws2',
'key.format' = 'json',
'value.format' = 'json'
)
(2)插入upsert-kafka表
insert into t2 select id,sum(vc) sumVC from source group by id
(3)查询upsert-kafka表
upsert-kafka 无法从指定的偏移量读取,只会从主题的源读取。如此,才知道整个数据的更新过程。并且通过 -U,+U,+I 等符号来显示数据的变化过程。
select * from t2
11.6.2 File
1)创建FileSystem映射表
CREATE TABLE t3( id int, ts bigint , vc int )
WITH (
'connector' = 'filesystem',
'path' = 'hdfs://hadoop102:8020/data/t3',
'format' = 'csv'
)
2)写入
insert into t3 select * from source
3)查询
select * from t3 where id = '1'
4)报错问题

如上报错是因为之前lib下放了sql-hive的连接器jar包,解决方案有两种:
-
将hive的连接器jar包挪走,重启yarn-session、sql-client
mv flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar.bak -
同10.8.3中的操作,替换planner的jar包
11.6.3 JDBC(MySQL)
Flink在将数据写入外部数据库时使用DDL中定义的主键。如果定义了主键,则连接器以upsert模式操作,否则,连接器以追加模式操作。
在upsert模式下,Flink会根据主键插入新行或更新现有行,Flink这样可以保证幂等性。为了保证输出结果符合预期,建议为表定义主键,并确保主键是底层数据库表的唯一键集或主键之一。在追加模式下,Flink将所有记录解释为INSERT消息,如果底层数据库中发生了主键或唯一约束违反,则INSERT操作可能会失败。
1)mysql的test库中建表
`CREATE TABLE `ws2` (
`id` int(11) NOT NULL,
`ts` bigint(20) DEFAULT NULL,
`vc` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2)添加JDBC连接器依赖
由于目前1.17的连接器官方还未提供,我们从apache snapshot仓库下载:
https://repository.apache.org/content/repositories/snapshots/org/apache/flink/flink-connector-jdbc/1.17-SNAPSHOT/
上传jdbc连接器的jar包和mysql的连接驱动包到flink/lib下:
-
flink-connector-jdbc-1.17-20230109.003314-120.jar
-
mysql-connector-j-8.0.31.jar
3)创建JDBC映射表
CREATE TABLE t4
(
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url' = 'jdbc:mysql://hadoop102:3306/test?useUnicode=true&characterEncoding=UTF-8',
'username' = 'root',
'password' = '000000',
'connection.max-retry-timeout' = '60s',
'table-name' = 'ws2',
'sink.buffer-flush.max-rows' = '500',
'sink.buffer-flush.interval' = '5s',
'sink.max-retries' = '3',
'sink.parallelism' = '1'
);
4)查询
select * from t4
5)写入
insert into t4 select * from source
11.7 sql-client 中使用 savepoint
1)提交一个insert作业,可以给作业设置名称
INSERT INTO sink select * from source;
2)查看job列表
SHOW JOBS;
3)停止作业,触发savepoint
SET state.checkpoints.dir='hdfs://hadoop102:8020/chk';
SET state.savepoints.dir='hdfs://hadoop102:8020/sp';
STOP JOB '228d70913eab60dda85c5e7f78b5782c' WITH SAVEPOINT;
4)从savepoint恢复
-- 设置从savepoint恢复的路径
SET execution.savepoint.path='hdfs://hadoop102:8020/sp/savepoint-37f5e6-0013a2874f0a';
-- 之后直接提交sql,就会从savepoint恢复
--允许跳过无法还原的保存点状态
set 'execution.savepoint.ignore-unclaimed-state' = 'true';
5)恢复后重置路径
指定execution.savepoint.path后,将影响后面执行的所有DML语句,可以使用RESET命令重置这个配置选项。
RESET execution.savepoint.path;
如果出现reset没生效的问题,可能是个bug,我们可以退出sql-client,再重新进,不需要重启flink的集群。
11.8 Catalog
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
数据处理最关键的方面之一是管理元数据。元数据可以是临时的,例如临时表、UDF。 元数据也可以是持久化的,例如 Hive MetaStore 中的元数据。Catalog 提供了一个统一的API,用于管理元数据,并使其可以从 Table API 和 SQL 查询语句中来访问。
Catalog 允许用户引用其数据存储系统中现有的元数据,并自动将其映射到 Flink 的相应元数据。例如,Flink 可以直接使用 Hive MetaStore 中的表的元数据,不必在Flink中手动重写ddl,也可以将 Flink SQL 中的元数据存储到 Hive MetaStore 中。Catalog 极大地简化了用户开始使用 Flink 的步骤,并极大地提升了用户体验。
11.8.1 Catalog类型
目前 Flink 包含了以下四种 Catalog:
-
GenericInMemoryCatalog:基于内存实现的 Catalog,所有元数据只在session 的生命周期(即一个 Flink 任务一次运行生命周期内)内可用。默认自动创建,会有名为“default_catalog”的内存Catalog,这个Catalog默认只有一个名为“default_database”的数据库。
-
JdbcCatalog:JdbcCatalog 使得用户可以将 Flink 通过 JDBC 协议连接到关系数据库。Postgres Catalog和MySQL Catalog是目前仅有的两种JDBC Catalog实现,将元数据存储在数据库中。
-
HiveCatalog:有两个用途,一是单纯作为 Flink 元数据的持久化存储,二是作为读写现有 Hive 元数据的接口。注意:Hive MetaStore 以小写形式存储所有元数据对象名称。Hive Metastore以小写形式存储所有元对象名称,而 GenericInMemoryCatalog会区分大小写。
-
用户自定义 Catalog:用户可以实现 Catalog 接口实现自定义 Catalog。从Flink1.16开始引入了用户类加载器,通过CatalogFactory.Context#getClassLoader访问,否则会报错ClassNotFoundException。
11.8.2 JdbcCatalog(MySQL)
JdbcCatalog不支持建表,只是打通flink与mysql的连接,可以去读写mysql现有的库表。
1)上传所需jar包到lib下
1.17的JDBC连接器还未发布到中央仓库,可以从apache snapshot仓库下载:
https://repository.apache.org/content/repositories/snapshots/org/apache/flink/flink-connector-jdbc/1.17-SNAPSHOT/
cp flink-connector-jdbc-1.17-20230109.003314-120.jar /opt/module/flink-1.17.0/lib/
cp mysql-connector-j-8.0.31.jar /opt/module/flink-1.17.0/lib/
2)重启flink集群和sql-client
3)创建Catalog
JdbcCatalog支持以下选项:
name:必需,Catalog名称。
default-database:必需,连接到的默认数据库。
username: 必需,Postgres/MySQL帐户的用户名。
password:必需,该帐号的密码。
base-url:必需,数据库的jdbc url(不包含数据库名),对于Postgres Catalog,是"jdbc:postgresql://:<端口>“,对于MySQL Catalog,是"jdbc: mysql://:<端口>”
CREATE CATALOG my_jdbc_catalog WITH(
'type' = 'jdbc',
'default-database' = 'test',
'username' = 'root',
'password' = '000000',
'base-url' = 'jdbc:mysql://hadoop102:3306'
);
4)查看Catalog
SHOW CATALOGS;
--查看当前的CATALOG
SHOW CURRENT CATALOG;
5)使用指定Catalog
USE CATALOG my_jdbc_catalog;
--查看当前的CATALOG
SHOW CURRENT CATALOG;
11.8.3 HiveCatalog
1)上传所需jar包到lib下
cp flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar /opt/module/flink-1.17.0/lib/
cp mysql-connector-j-8.0.31.jar /opt/module/flink-1.17.0/lib/
2)更换planner依赖
只有在使用Hive方言或HiveServer2时才需要这样额外的计划器jar移动,但这是Hive集成的推荐设置。
mv /opt/module/flink-1.17.0/opt/flink-table-planner_2.12-1.17.0.jar /opt/module/flink-1.17.0/lib/flink-table-planner_2.12-1.17.0.jar
mv /opt/module/flink-1.17.0/lib/flink-table-planner-loader-1.17.0.jar /opt/module/flink-1.17.0/opt/flink-table-planner-loader-1.17.0.jar
3)重启flink集群和sql-client
4)启动外置的hive metastore服务
Hive metastore必须作为独立服务运行,也就是hive-site中必须配置hive.metastore.uris
hive --service metastore &
5)创建Catalog
| 配置项 | 必需 | 默认值 | 类型 | 说明 |
|---|---|---|---|---|
| type | Yes | (none) | String | Catalog类型,创建HiveCatalog时必须设置为’hive’。 |
| name | Yes | (none) | String | Catalog的唯一名称 |
| hive-conf-dir | No | (none) | String | 包含hive -site.xml的目录,需要Hadoop文件系统支持。如果没指定hdfs协议,则认为是本地文件系统。如果不指定该选项,则在类路径中搜索hive-site.xml。 |
| default-database | No | default | String | Hive Catalog使用的默认数据库 |
| hive-version | No | (none) | String | HiveCatalog能够自动检测正在使用的Hive版本。建议不要指定Hive版本,除非自动检测失败。 |
| hadoop-conf-dir | No | (none) | String | Hadoop conf目录的路径。只支持本地文件系统路径。设置Hadoop conf的推荐方法是通过HADOOP_CONF_DIR环境变量。只有当环境变量不适合你时才使用该选项,例如,如果你想分别配置每个HiveCatalog。 |
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/opt/module/hive/conf'
);
6)查看Catalog
SHOW CATALOGS;
--查看当前的CATALOG
SHOW CURRENT CATALOG;
7)使用指定Catalog
USE CATALOG myhive;
--查看当前的CATALOG
SHOW CURRENT CATALOG;
建表,退出sql-client重进,查看catalog和表还在。
8)读写Hive表
SHOW DATABASES; -- 可以看到hive的数据库
USE test; -- 可以切换到hive的数据库
SHOW TABLES; -- 可以看到hive的表
SELECT * from ws; --可以读取hive表
INSERT INTO ws VALUES(1,1,1); -- 可以写入hive表
11.9 代码中使用FlinkSQL
11.9.1 引入相关的依赖
// “桥接器”(bridge),主要就是负责Table API和下层DataStream API的连接支持
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
11.9.2 创建表环境
对于Flink这样的流处理框架来说,数据流和表在结构上还是有所区别的。所以使用Table API和SQL需要一个特别的运行时环境,这就是所谓的“表环境”(TableEnvironment)。它主要负责:
(1)注册Catalog和表;
(2)执行 SQL 查询;
(3)注册用户自定义函数(UDF);
(4)DataStream 和表之间的转换。
每个表和SQL的执行,都必须绑定在一个表环境(TableEnvironment)中。 TableEnvironment是Table API中提供的基本接口类,可以通过调用静态的create()方法来创建一个表环境实例。方法需要传入一个环境的配置参数EnvironmentSettings,它可以指定当前表环境的执行模式和计划器(planner)。执行模式有批处理和流处理两种选择,默认是流处理模式;计划器默认使用blink planner。
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 使用流处理模式
.build();
TableEnvironment tableEnv = TableEnvironment.create(setting);
对于流处理场景,其实默认配置就完全够用了。所以我们也可以用另一种更加简单的方式来创建表环境:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
11.9.3 创建表
方式一:创建虚拟表(视图)——一般是通过已有表的查询结果等
Table newTable = tableEnv.sqlQuery("SELECT ... FROM MyTable... ");
方式二:通过连接器Connector——一般接入外部系统数据,FileSystem、Kafka…
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable ... WITH ( 'connector' = ... )");
11.9.4 表的查询
方式一:SQL
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
// 查询用户Alice的点击事件,并提取表中前两个字段
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
得到的是一个新的Table对象,我们可以再次将它注册为虚拟表继续在SQL中调用。另外,我们也可以直接将查询的结果写入到已经注册的表中,这需要调用表环境的executeSql()方法来执行DDL,传入的是一个INSERT语句:
// 注册表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 将查询结果输出到OutputTable中
tableEnv.executeSql (
"INSERT INTO OutputTable " +
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
方式二:调用Table API进行查询
// 获取table对象
Table eventTable = tableEnv.from("EventTable");
// 进行查询操作
Table maryClickTable = eventTable
.where($("user").isEqual("Alice"))
.select($("url"), $("user"));
Table API是嵌入编程语言中的DSL,SQL中的很多特性和功能必须要有对应的实现才可以使用,因此跟直接写SQL比起来肯定就要麻烦一些。目前Table API支持的功能相对更少,可以预见未来Flink社区也会以扩展SQL为主。
11.9.5 输出表
在代码上,输出一张表最直接的方法,就是调用Table的方法executeInsert()方法将一个 Table写入到注册过的表中,方法传入的参数就是注册的表名。
// 注册表,用于输出数据到外部系统
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 经过查询转换,得到结果表
Table result = ...
// 将结果表写入已注册的输出表中
result.executeInsert("OutputTable");
在底层,表的输出是通过将数据写入到TableSink来实现的。TableSink是Table API中提供的一个向外部系统写入数据的通用接口,可以支持不同的文件格式(比如CSV、Parquet)、存储数据库(比如JDBC、Elasticsearch)和消息队列(比如Kafka)。
public class SqlDemo {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO 1.创建表环境
// 1.1 写法一:
// EnvironmentSettings settings = EnvironmentSettings.newInstance()
// .inStreamingMode()
// .build();
// StreamTableEnvironment tableEnv = TableEnvironment.create(settings);
// 1.2 写法二
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// TODO 2.创建表
tableEnv.executeSql("CREATE TABLE source ( \n" +
" id INT, \n" +
" ts BIGINT, \n" +
" vc INT\n" +
") WITH ( \n" +
" 'connector' = 'datagen', \n" +
" 'rows-per-second'='1', \n" +
" 'fields.id.kind'='random', \n" +
" 'fields.id.min'='1', \n" +
" 'fields.id.max'='10', \n" +
" 'fields.ts.kind'='sequence', \n" +
" 'fields.ts.start'='1', \n" +
" 'fields.ts.end'='1000000', \n" +
" 'fields.vc.kind'='random', \n" +
" 'fields.vc.min'='1', \n" +
" 'fields.vc.max'='100'\n" +
");\n");
tableEnv.executeSql("CREATE TABLE sink (\n" +
" id INT, \n" +
" sumVC INT \n" +
") WITH (\n" +
"'connector' = 'print'\n" +
");\n");
// TODO 3.执行查询
// 3.1 使用sql进行查询
// Table table = tableEnv.sqlQuery("select id,sum(vc) as sumVC from source where id>5 group by id ;");
// 把table对象,注册成表名
// tableEnv.createTemporaryView("tmp", table);
// tableEnv.sqlQuery("select * from tmp where id > 7");
// 3.2 用table api来查询
Table source = tableEnv.from("source");
Table result = source
.where($("id").isGreater(5))
.groupBy($("id"))
.aggregate($("vc").sum().as("sumVC"))
.select($("id"), $("sumVC"));
// TODO 4.输出表
// 4.1 sql用法
// tableEnv.executeSql("insert into sink select * from tmp");
// 4.2 tableapi用法
result.executeInsert("sink");
}
}
11.9.6 表和流的转换
1)将流(DataStream)转换成表(Table)
-
fromDataStream()
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 获取表环境 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 读取数据源 SingleOutputStreamOperator<WaterSensor> sensorDS = env.fromSource(...) // 将数据流转换成表 Table sensorTable = tableEnv.fromDataStream(sensorDS);我们还可以在fromDataStream()方法中增加参数,用来指定提取哪些属性作为表中的字段名,并可以任意指定位置:
// 提取Event中的timestamp和url作为表中的列 Table sensorTable = tableEnv.fromDataStream(sensorDS, $("id"), $("vc"));也可以通过表达式的as()方法对字段进行重命名:
// 将timestamp字段重命名为ts Table sensorTable = tableEnv.fromDataStream(sensorDS, $("id").as("sid"), $("vc")); -
createTemporaryView()
tableEnv.createTemporaryView("sensorTable",sensorDS, $("id"),$("ts"),$("vc"));
2)将表转换成流
-
toDataStream()
tableEnv.toDataStream(table).print(); -
toChangelogStream()
表中进行了分组聚合统计,那表中的每一行是会“更新”的。对于这样有更新操作的表,我们不应该直接把它转换成DataStream打印输出,而是记录一下它的“更新日志”(change log)。这样一来,对于表的所有更新操作,就变成了一条更新日志的流,我们就可以转换成流打印输出了。
Table table = tableEnv.sqlQuery( "SELECT id, sum(vc) " + "FROM source " + "GROUP BY id " ); // 将表转换成更新日志流 tableEnv.toChangelogStream(table).print();
3)支持的数据类型
(1)原子类型
基础数据类型(Integer、Double、String)和通用数据类型(也就是不可再拆分的数据类型)统一称作“原子类型”
(2)Tuple类型
(3)POJO类型
(4)Row类
—行(Row),它是Table中数据的基本组织形式。它的长度固定,而且无法直接推断出每个字段的类型,所以在使用时必须指明具体的类型信息;我们在创建Table时调用的CREATE语句就会将所有的字段名称和类型指定,这在Flink中被称为表的“模式结构”(Schema)。
4)综合应用示例
现在,我们可以将介绍过的所有API整合起来,写出一段完整的代码。同样还是用户的一组点击事件,我们可以查询出某个用户(例如Alice)点击的url列表,也可以统计出每个用户累计的点击次数,这可以用两句SQL来分别实现。
public class TableStreamDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> sensorDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 2L, 2),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3),
new WaterSensor("s3", 4L, 4)
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// TODO 1. 流转表
Table sensorTable = tableEnv.fromDataStream(sensorDS);
tableEnv.createTemporaryView("sensor", sensorTable);
Table filterTable = tableEnv.sqlQuery("select id,ts,vc from sensor where ts>2");
Table sumTable = tableEnv.sqlQuery("select id,sum(vc) from sensor group by id");
// TODO 2. 表转流
// 2.1 追加流
tableEnv.toDataStream(filterTable, WaterSensor.class).print("filter");
// 2.2 changelog流(结果需要更新)
tableEnv.toChangelogStream(sumTable ).print("sum");
env.execute();
}
}
11.9.7 自定义函数(UDF)
系统函数尽管庞大,也不可能涵盖所有的功能;如果有系统函数不支持的需求,我们就需要用自定义函数(User Defined Functions,UDF)来实现了。
Flink的Table API和SQL提供了多种自定义函数的接口,以抽象类的形式定义。当前UDF主要有以下几类:
-
标量函数(Scalar Functions):将输入的标量值转换成一个新的标量值;
-
表函数(Table Functions):将标量值转换成一个或多个新的行数据,也就是扩展成一个表;
-
聚合函数(Aggregate Functions):将多行数据里的标量值转换成一个新的标量值;
-
表聚合函数(Table Aggregate Functions):将多行数据里的标量值转换成一个或多个新的行数据。
1)整体调用流程
(0)定义对应UDF抽象类的实现
(1)注册函数
// 注册函数
tableEnv.createTemporarySystemFunction("MyFunction", MyFunction.class);
(2)使用Table API调用函数
tableEnv.from("MyTable").select(call("MyFunction", $("myField")));
这里call()方法有两个参数,一个是注册好的函数名MyFunction,另一个则是函数调用时本身的参数。这里我们定义MyFunction在调用时,需要传入的参数是myField字段。
(3)在SQL中调用函数
当我们将函数注册为系统函数之后,在SQL中的调用就与内置系统函数完全一样了:
tableEnv.sqlQuery("SELECT MyFunction(myField) FROM MyTable");
可见,SQL的调用方式更加方便,我们后续依然会以SQL为例介绍UDF的用法。
2)标量函数(Scalar Functions)
自定义标量函数可以把0个、 1个或多个标量值转换成一个标量值,它对应的输入是一行数据中的字段,输出则是唯一的值。所以从输入和输出表中行数据的对应关系看,标量函数是“一对一”的转换。
想要实现自定义的标量函数,我们需要自定义一个类来继承抽象类ScalarFunction,并实现叫作eval() 的求值方法。标量函数的行为就取决于求值方法的定义,它必须是公有的(public),而且名字必须是eval。求值方法eval可以重载多次,任何数据类型都可作为求值方法的参数和返回值类型。
这里需要特别说明的是,ScalarFunction抽象类中并没有定义eval()方法,所以我们不能直接在代码中重写(override);但Table API的框架底层又要求了求值方法必须名字为eval()。这是Table API和SQL目前还显得不够完善的地方,未来的版本应该会有所改进。
下面我们来看一个具体的例子。我们实现一个自定义的哈希(hash)函数HashFunction,用来求传入对象的哈希值。
public class MyScalarFunctionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> sensorDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 2L, 2),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3),
new WaterSensor("s3", 4L, 4)
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table sensorTable = tableEnv.fromDataStream(sensorDS);
tableEnv.createTemporaryView("sensor", sensorTable);
// TODO 2.注册函数
tableEnv.createTemporaryFunction("HashFunction", HashFunction.class);
// TODO 3.调用自定义函数
// 3.1 sql用法
tableEnv.sqlQuery("select HashFunction(id) from sensor").execute().print();
// 3.2 table api
sensorTable.select(call("HashFunction",$("id"))).execute().print();
}
// TODO 1.定义 自定义函数的实现类
public static class HashFunction extends ScalarFunction {
// 接受任意类型的输入,返回 INT型输出
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
}
3)表函数(Table Functions)
跟标量函数一样,表函数的输入参数也可以是 0个、1个或多个标量值;不同的是,它可以返回任意多行数据。“多行数据”事实上就构成了一个表,所以“表函数”可以认为就是返回一个表的函数,这是一个“一对多”的转换关系。之前我们介绍过的窗口TVF,本质上就是表函数。
类似地,要实现自定义的表函数,需要自定义类来继承抽象类TableFunction,内部必须要实现的也是一个名为 eval 的求值方法。与标量函数不同的是,TableFunction类本身是有一个泛型参数T的,这就是表函数返回数据的类型;而eval()方法没有返回类型,内部也没有return语句,是通过调用collect()方法来发送想要输出的行数据的。
在SQL中调用表函数,需要使用LATERAL TABLE()来生成扩展的“侧向表”,然后与原始表进行联结(Join)。这里的Join操作可以是直接做交叉联结(cross join),在FROM后用逗号分隔两个表就可以;也可以是以ON TRUE为条件的左联结(LEFT JOIN)。
下面是表函数的一个具体示例。我们实现了一个分隔字符串的函数SplitFunction,可以将一个字符串转换成(字符串,长度)的二元组。
public class MyTableFunctionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> strDS = env.fromElements(
"hello flink",
"hello world hi",
"hello java"
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table sensorTable = tableEnv.fromDataStream(strDS, $("words"));
tableEnv.createTemporaryView("str", sensorTable);
// TODO 2.注册函数
tableEnv.createTemporaryFunction("SplitFunction", SplitFunction.class);
// TODO 3.调用 自定义函数
// 3.1 交叉联结
tableEnv
// 3.1 交叉联结
// .sqlQuery("select words,word,length from str,lateral table(SplitFunction(words))")
// 3.2 带 on true 条件的 左联结
// .sqlQuery("select words,word,length from str left join lateral table(SplitFunction(words)) on true")
// 重命名侧向表中的字段
.sqlQuery("select words,newWord,newLength from str left join lateral table(SplitFunction(words)) as T(newWord,newLength) on true")
.execute()
.print();
}
// TODO 1.继承 TableFunction<返回的类型>
// 类型标注: Row包含两个字段:word和length
@FunctionHint(output = @DataTypeHint("ROW<word STRING,length INT>"))
public static class SplitFunction extends TableFunction<Row> {
// 返回是 void,用 collect方法输出
public void eval(String str) {
for (String word : str.split(" ")) {
collect(Row.of(word, word.length()));
}
}
}
}
4)聚合函数(Aggregate Functions)
用户自定义聚合函数(User Defined AGGregate function,UDAGG)会把一行或多行数据(也就是一个表)聚合成一个标量值。这是一个标准的“多对一”的转换。
聚合函数的概念我们之前已经接触过多次,如SUM()、MAX()、MIN()、AVG()、COUNT()都是常见的系统内置聚合函数。而如果有些需求无法直接调用系统函数解决,我们就必须自定义聚合函数来实现功能了。
自定义聚合函数需要继承抽象类AggregateFunction。AggregateFunction有两个泛型参数<T, ACC>,T表示聚合输出的结果类型,ACC则表示聚合的中间状态类型。
Flink SQL中的聚合函数的工作原理如下:
(1)首先,它需要创建一个累加器(accumulator),用来存储聚合的中间结果。这与DataStream API中的AggregateFunction非常类似,累加器就可以看作是一个聚合状态。调用createAccumulator()方法可以创建一个空的累加器。
(2)对于输入的每一行数据,都会调用accumulate()方法来更新累加器,这是聚合的核心过程。
(3)当所有的数据都处理完之后,通过调用getValue()方法来计算并返回最终的结果。
所以,每个 AggregateFunction 都必须实现以下几个方法:
-
createAccumulator()
这是创建累加器的方法。没有输入参数,返回类型为累加器类型ACC。
-
accumulate()
这是进行聚合计算的核心方法,每来一行数据都会调用。它的第一个参数是确定的,就是当前的累加器,类型为ACC,表示当前聚合的中间状态;后面的参数则是聚合函数调用时传入的参数,可以有多个,类型也可以不同。这个方法主要是更新聚合状态,所以没有返回类型。需要注意的是,accumulate()与之前的求值方法eval()类似,也是底层架构要求的,必须为public,方法名必须为accumulate,且无法直接override、只能手动实现。
-
getValue()
这是得到最终返回结果的方法。输入参数是ACC类型的累加器,输出类型为T。
在遇到复杂类型时,Flink 的类型推导可能会无法得到正确的结果。所以AggregateFunction也可以专门对累加器和返回结果的类型进行声明,这是通过 getAccumulatorType()和getResultType()两个方法来指定的。
AggregateFunction 的所有方法都必须是 公有的(public),不能是静态的(static),而且名字必须跟上面写的完全一样。createAccumulator、getValue、getResultType 以及 getAccumulatorType 这几个方法是在抽象类 AggregateFunction 中定义的,可以override;而其他则都是底层架构约定的方法。
下面举一个具体的示例,我们从学生的分数表ScoreTable中计算每个学生的加权平均分。
public class MyAggregateFunctionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 姓名,分数,权重
DataStreamSource<Tuple3<String,Integer, Integer>> scoreWeightDS = env.fromElements(
Tuple3.of("zs",80, 3),
Tuple3.of("zs",90, 4),
Tuple3.of("zs",95, 4),
Tuple3.of("ls",75, 4),
Tuple3.of("ls",65, 4),
Tuple3.of("ls",85, 4)
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table scoreWeightTable = tableEnv.fromDataStream(scoreWeightDS, $("f0").as("name"),$("f1").as("score"), $("f2").as("weight"));
tableEnv.createTemporaryView("scores", scoreWeightTable);
// TODO 2.注册函数
tableEnv.createTemporaryFunction("WeightedAvg", WeightedAvg.class);
// TODO 3.调用 自定义函数
tableEnv
.sqlQuery("select name,WeightedAvg(score,weight) from scores group by name")
.execute()
.print();
}
// TODO 1.继承 AggregateFunction< 返回类型,累加器类型<加权总和,权重总和> >
public static class WeightedAvg extends AggregateFunction<Double, Tuple2<Integer, Integer>> {
@Override
public Double getValue(Tuple2<Integer, Integer> integerIntegerTuple2) {
return integerIntegerTuple2.f0 * 1D / integerIntegerTuple2.f1;
}
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0);
}
/**
* 累加计算的方法,每来一行数据都会调用一次
* @param acc 累加器类型
* @param score 第一个参数:分数
* @param weight 第二个参数:权重
*/
public void accumulate(Tuple2<Integer, Integer> acc,Integer score,Integer weight){
acc.f0 += score * weight; // 加权总和 = 分数1 * 权重1 + 分数2 * 权重2 +....
acc.f1 += weight; // 权重和 = 权重1 + 权重2 +....
}
}
}
5)表聚合函数(Table Aggregate Functions)
用户自定义表聚合函数(UDTAGG)可以把一行或多行数据(也就是一个表)聚合成另一张表,结果表中可以有多行多列。很明显,这就像表函数和聚合函数的结合体,是一个“多对多”的转换。
自定义表聚合函数需要继承抽象类TableAggregateFunction。TableAggregateFunction的结构和原理与AggregateFunction非常类似,同样有两个泛型参数<T, ACC>,用一个ACC类型的累加器(accumulator)来存储聚合的中间结果。聚合函数中必须实现的三个方法,在TableAggregateFunction中也必须对应实现:
-
createAccumulator()
创建累加器的方法,与AggregateFunction中用法相同。
-
accumulate()
聚合计算的核心方法,与AggregateFunction中用法相同。
-
emitValue()
所有输入行处理完成后,输出最终计算结果的方法。这个方法对应着AggregateFunction中的getValue()方法;区别在于emitValue没有输出类型,而输入参数有两个:第一个是ACC类型的累加器,第二个则是用于输出数据的“收集器”out,它的类型为Collect。另外,emitValue()在抽象类中也没有定义,无法override,必须手动实现。
表聚合函数相对比较复杂,它的一个典型应用场景就是TOP-N查询。比如我们希望选出一组数据排序后的前两名,这就是最简单的TOP-2查询。没有现成的系统函数,那么我们就可以自定义一个表聚合函数来实现这个功能。在累加器中应该能够保存当前最大的两个值,每当来一条新数据就在accumulate()方法中进行比较更新,最终在emitValue()中调用两次out.collect()将前两名数据输出。
public class MyTableAggregateFunctionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 姓名,分数,权重
DataStreamSource<Integer> numDS = env.fromElements(3, 6, 12, 5, 8, 9, 4);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table numTable = tableEnv.fromDataStream(numDS, $("num"));
// TODO 2.注册函数
tableEnv.createTemporaryFunction("Top2", Top2.class);
// TODO 3.调用 自定义函数: 只能用 Table API
numTable
.flatAggregate(call("Top2", $("num")).as("value", "rank"))
.select( $("value"), $("rank"))
.execute().print();
}
// TODO 1.继承 TableAggregateFunction< 返回类型,累加器类型<加权总和,权重总和> >
// 返回类型 (数值,排名) =》 (12,1) (9,2)
// 累加器类型 (第一大的数,第二大的数) ===》 (12,9)
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>> {
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0);
}
/**
* 每来一个数据调用一次,比较大小,更新 最大的前两个数到 acc中
*
* @param acc 累加器
* @param num 过来的数据
*/
public void accumulate(Tuple2<Integer, Integer> acc, Integer num) {
if (num > acc.f0) {
// 新来的变第一,原来的第一变第二
acc.f1 = acc.f0;
acc.f0 = num;
} else if (num > acc.f1) {
// 新来的变第二,原来的第二不要了
acc.f1 = num;
}
}
/**
* 输出结果: (数值,排名)两条最大的
*
* @param acc 累加器
* @param out 采集器<返回类型>
*/
public void emitValue(Tuple2<Integer, Integer> acc, Collector<Tuple2<Integer, Integer>> out) {
if (acc.f0 != 0) {
out.collect(Tuple2.of(acc.f0, 1));
}
if (acc.f1 != 0) {
out.collect(Tuple2.of(acc.f1, 2));
}
}
}
}
目前SQL中没有直接使用表聚合函数的方式,所以需要使用Table API的方式来调用。
这里使用了flatAggregate()方法,它就是专门用来调用表聚合函数的接口。统计num值最大的两个;并将聚合结果的两个字段重命名为value和rank,之后就可以使用select()将它们提取出来了。