一.前言

当我们进行购物的时候,不知道大家有没有想过,每个人有那么多订单,要浏览海量商品,要加载许多网页,屏幕背后的网站是怎么完成这一系列的网页响应,数据存储的?本文将带大家深入了解这背后的机制和原理.
在进⾏技术学习过程中,由于⼤部分人没有经历过⼀些中⼤型系统的实际经验,导致⽆法从全 局理解⼀些概念,所以本⽂以⼀个 "电⼦商务" 应⽤为例,介绍从⼀百个到千万级并发情况下服务端的 架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让⼤家对架构的演进有⼀个整体的认 知,⽅便⼤家对后续知识做深⼊学习时有⼀定的整体视野。
二.概念铺垫
首先我们需要对一些基础概念进行引入,以便大家后续的理解和沟通.
1.基本概念
| 概念名称 | 含义 |
| 应⽤(Application)/ 系统(System) | 为了完成⼀整套服务的⼀个程序或者⼀组相互配合的程序群。⽣活例⼦类⽐:为了完成⼀项任 务,⽽搭建的由⼀个⼈或者⼀群相互配的⼈组成的团队。 |
| 模块(Module)/ 组件(Component) | 当应⽤较复杂时,为了分离职责,将其中具有清晰职责的、内聚性强的部分,抽象出概念,便于 理解。⽣活例⼦类⽐:军队中为了进⾏某据点的攻克,将⼈员分为突击⼩组、爆破⼩组、掩护⼩组、 通信⼩组等。 |
| 分布式(Distributed) | 系统中的多个模块被部署于不同服务器之上,即可以将该系统称为分布式系统。如 Web 服务器与 数据库分别⼯作在不同的服务器上,或者多台 Web 服务器被分别部署在不同服务器上。⽣活例⼦类 ⽐:为了更好的满⾜现实需要,⼀个在同⼀个办公场地的⼯作⼩组被分散到多个城市的不同⼯作场地 中进⾏远程配合⼯作完成⽬标。跨主机之间的模块之间的通信基本要借助⽹络⽀撑完成。 |
| 集群(Cluster) | 被部署于多台服务器上的、为了实现特定⽬标的⼀个/组特定的组件,整个整体被称为集群。⽐如 多个 MySQL ⼯作在不同服务器上,共同提供数据库服务⽬标,可以被称为⼀组数据库集群。⽣活例⼦ 类⽐:为了解决军队攻克防守坚固的⼤城市的作战⽬标,指挥部将⼤批炮兵部队集中起来形成⼀个炮 兵打击集群。 比特就业课 分布式 vs 集群。通常不⽤太严格区分两者的细微概念,细究的话,分布式强调的是物理形态,即 ⼯作在不同服务器上并且通过⽹络通信配合完成任务;⽽集群更在意逻辑形态,即是否为了完成特定 服务⽬标。 |
| 主(Master)/ 从(Slave) | 集群中,通常有⼀个程序需要承担更多的职责,被称为主;其他承担附属职责的被称为从。⽐如 MySQL 集群中,只有其中⼀台服务器上数据库允许进⾏数据的写⼊(增/删/改),其他数据库的数据 修改全部要从这台数据库同步⽽来,则把那台数据库称为主库,其他数据库称为从库。 |
| 中间件(Middleware) | ⼀类提供不同应⽤程序⽤于相互通信的软件,即处于不同技术、⼯具和数据库之间的桥梁。⽣活 例⼦类⽐:⼀家饭店开始时,会每天去市场挑选买菜,但随着饭店业务量变⼤,成⽴⼀个采购部,由 采购部专职于采买业务,称为厨房和菜市场之间的桥梁。 |
2.评价指标(Metric)
| 概念名称 | 含义 |
| 可⽤性(Availability) | 考察单位时间段内,系统可以正常提供服务的概率/期望。例如: 年化系统可⽤性 = 系统正常提供 服务时⻓ / ⼀年总时⻓。这⾥暗含着⼀个指标,即如何评价系统提供⽆法是否正常,我们就不深⼊了。 平时我们常说的 4 个 9 即系统可以提供 99.99% 的可⽤性,5 个 9 是 99.999% 的可⽤性,以此类推。 我们平时只是⽤⾼可⽤(High Availability HA)这个⾮量化⽬标简要表达我们系统的追求。 |
| 响应时⻓(Response Time RT) | 指⽤⼾完成输⼊到系统给出⽤⼾反应的时⻓。例如点外卖业务的响应时⻓ = 拿到外卖的时刻 - 完成 点单的时刻。通常我们需要衡量的是最⻓响应时⻓、平均响应时⻓和中位数响应时⻓。这个指标原则 上是越⼩越好,但很多情况下由于实现的限制,需要根据实际情况具体判断 |
| 吞吐(Throughput)vs 并发(Concurrent) | 吞吐考察单位时间段内,系统可以成功处理的请求的数量。并发指系统同⼀时刻⽀持的请求最⾼ 量。例如⼀条辆⻋道⾼速公路,⼀分钟可以通过 20 辆⻋,则并发是 2,⼀分钟的吞吐量是 20。实践 中,并发量往往⽆法直接获取,很多时候都是⽤极短的时间段(⽐如 1 秒)的吞吐量做代替。我们平 时⽤⾼并发(Hight Concurrnet)这个⾮量化⽬标简要表达系统的追求。 |
三. 架构演进
1.单机架构
在我们在购物软件的搜索框里输入"XXX"商品的之后,相关页面将在一段时间后出现在我们面前?那么,在这段时间里发生了什么呢?
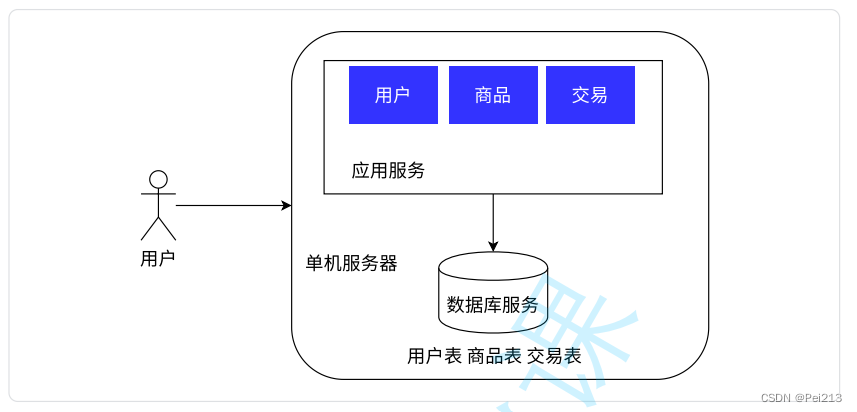
首先,在用户发出请求后,服务器对用户的信息进行分析处理,得到了从数据库中调取相关商品信息的指令,然后调取了相关数据后,数据库(以MySQL数据库为例)将数据返回给服务器,服务器将信息响应给用户,完成了商品信息的查询.
绝大数情况下都是这样完成一个响应的.不仅快捷方便,而且易于维护操作.
但是,随着业务量的增加,用户量和数据量都会大量增加,然而一台主机(在这里指服务器)的存储量和硬件资源是有限的,包括CPU,内存,硬盘,网络资源等,服务器每收到一次请求,都是需要消耗一些资源的,如果同一时刻,处理的请求太多了,此时就会有可能导致一些硬件资源不够用了.
如果我们遇到了这样的情况,我们该如何处理呢?
方法一般有两种:
- 开源
- 节流
节流怎么做呢?我们知道,一些请求的协议内容,数据库的语句等其实是可能存在冗余的,我们要想通过优化它们的功能来达到增加存储或减少资源消耗的效果,也是可以的,但是就需要我们对很多内容进行性能测试,然后进行软件优化,这样不仅麻烦,而且对程序员的能力要求很高.那么,有没有别的办法呢?
我们还可以"开源".通过增加内存条或者外接固态硬盘来增加更多的资源.但是,一个主机上能增加的硬件资源也是有限的,这取决于主板的扩展能力.如果一台主机已经扩展到了极限了,但是还是不够,这个时候,我们就只能引入多台主机了.
但是不是说新的机器买来就可以直接解决问题了,这也需要我们在软件上做出相应的调整和适配.
一旦我们引入了多台主机了,我们的系统就可以称为是"分布式系统"了.

但是要注意的是:引入分布式系统是"无奈之举",因为引入多台主机后,系统的复杂程度就会大大提高,出现bug的概率也会大大增加.
2.应⽤数据分离架构
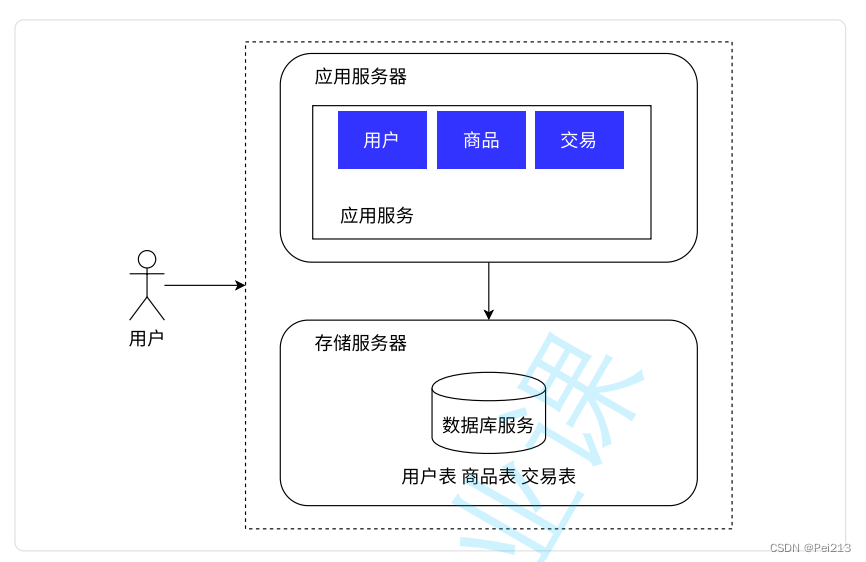
这个时候我们拥有了应用服务器和存储服务器.
- 应用服务器里面可能包含很多的业务逻辑,比较消耗CPU和内存.
- 存储服务器即数据库服务器,需要更大的硬盘空间,更快的数据访问速度.
我们将其分开来进行访问,响应速度,存储空间等都会得到提升.
但是,由于应用服务器对CPU和内存的消耗很大,如果这个时候我们还想继续提高处理请求的效率,我们该怎么做呢?
我们可以添加多个应用服务器来进行处理请求.
3.应⽤服务集群架构

在这里,多出了一个负载均衡,那么,它是怎么发挥作用的呢?
假定有1万个用户请求,有2个应用服务器(这里只画出和列举了两个,可以有多个),此时按照负载均衡的方式,就可以让每个应用服务器承载5千的访问量,可以大大提高效率.(负载均衡器分类请求的算法这里不作具体讨论).
负载均衡器
有的人可能会好奇,这个负载均衡器看起来不是接受了所有的用户请求吗?这样可以承受吗?
实际上,负载均衡器对于请求量的承担能力,是要远超应用服务器的.
举个例子:
- 负载均衡器就相当于领导,分配工作
- 应用服务器就相当于组员,完成任务
那是否可能出现请求量大到负载均衡器也扛不住了呢?
也是有可能的,因此我们也可以引入多个负载均衡器,就可以解决了.
举个例子来帮助大家理解:
如果一个电商网站只是将所有的商品信息进行存储,假如我们此时想购买狗粮,接着搜索狗狗,可能会出现很多商品信息,但是很大一部分商品并不是我们需要的.
但是,假如网站已经对商品进行了分类,这个时候我们再去搜索就会快捷很多.
这里就相当于已经有负载均衡器帮我们进行了分类,我们此时只需要访问不同的类别,即相关的应用服务器即可.

正如上面讨论的,当应用服务器增加了,确实能够处理更高的请求量,但是随之存储服务器要承担的数据量也更多了,这个时候怎么办呢?
其实和上述处理方法一样,也是"开源+节流".而"节流"的限制性和上述一样具有很大的限制性,所以还是要"开源".
4.读写分离 / 主从分离架构
我们把⽤⼾的请求通过负载均衡分发到不同的应⽤服务器之后,可以并⾏处理了, 并且可以随着业务的增⻓,可以动态扩张服务器的数量来缓解压⼒。但是现在的架构⾥,⽆论扩展多 少台服务器,这些请求最终都会从数据库读写数据,到⼀定程度之后,数据的压⼒称为系统承载能⼒ 的瓶颈点。我们可以像扩展应⽤服务器⼀样扩展数据库服务器么?答案是否定的,因为数据库服务有 其特殊性:如果将数据分散到各台服务器之后,数据的⼀致性将⽆法得到保障。
所谓数据的⼀致性, 此处是指:针对同⼀个系统,⽆论何时何地,我们都应该看到⼀个始终维持统⼀的数据。想象⼀下, 银⾏管理的账⼾⾦额,如果收到⼀笔转账之后,⼀份数据库的数据修改了,但另外的数据库没有修 改,则⽤⼾得到的存款⾦额将是错误的。
在我们访问或者请求时,我们往往"读"的频率远小于"写"的频率.
因此,我们可以保留⼀个主要的数据库作为写⼊数据库,其他的数据库作为从属数据库。(一主多从)
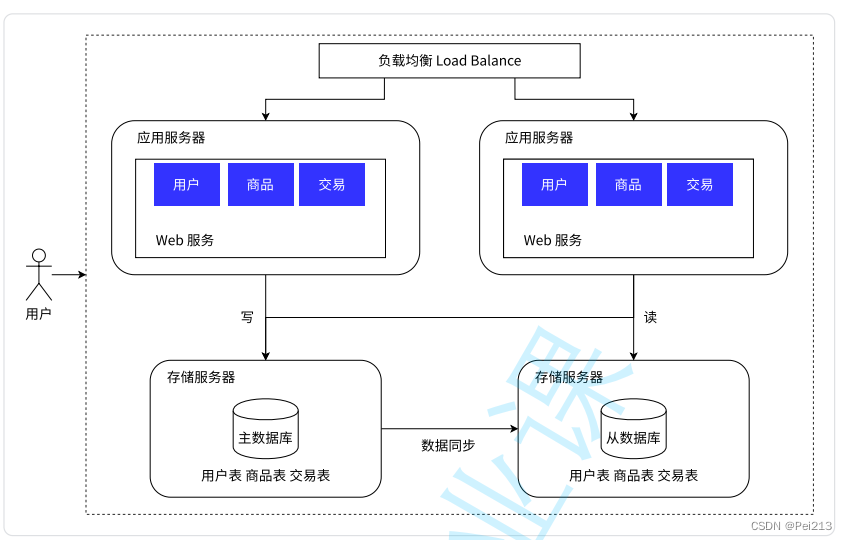
从库的所有数据全部来⾃主库的数据,经过同步后,从库可以维护着与主库⼀致的数据。然后为了分担数据库的压⼒,我们可以将写数据请求全部交给主库处理,但读请求分散到各个从库中。 由于⼤部分的系统中,读写请求都是不成⽐例的,例如 100 次读 1 次写,所以只要将读请求由各个从 库分担之后,数据库的压⼒就没有那么⼤了。
5.引⼊缓存⸺冷热分离架构
我们知道,计算机里也有它的"二八原则",即20%的数据可以支持80%的访问量,更极端的甚至能达到"一九原则",根据实际场景的不同会有所区别.
随着访问量继续增加,发现业务中⼀些数据的读取频率远⼤于其他数据的读取频率。我们把这部 分数据称为热点数据,与之相对应的是冷数据。
因为数据库天然有个问题,它的响应速度是比较慢的,把数据区分"冷热",针对热数据,将其放在缓存中,而缓存的访问速度往往比数据库快多了.
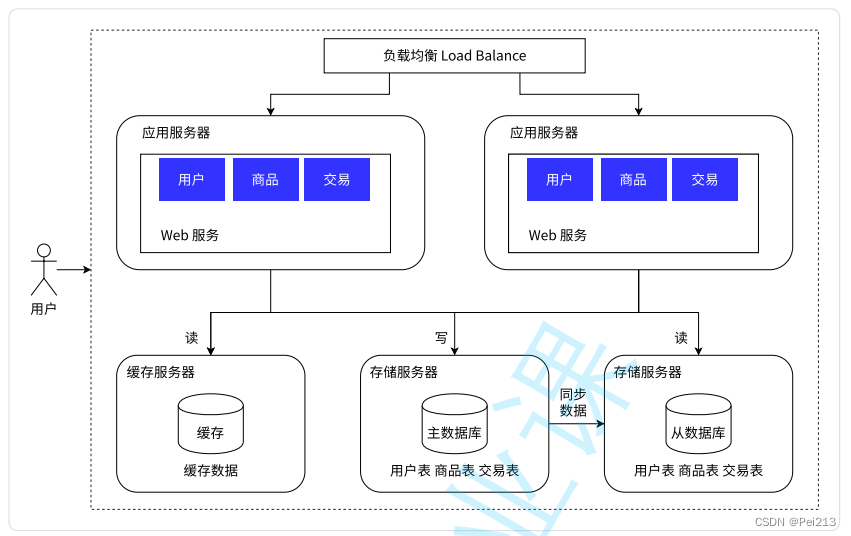
此时主从数据库中存储的仍然是完整的全量数据,只是将一部分热点数据放在缓存服务器里面了.
6.垂直分库
随着业务的数据量增⼤,⼤量的数据存储在同⼀个库中已经显得有些⼒不从⼼了,所以可以按照 业务,将数据分别存储。
⽐如针对评论数据,可按照商品ID进⾏hash,路由到对应的表中存储;针对⽀付记录,可按照⼩时创建表,每个⼩时表继续拆分为⼩表,使⽤⽤⼾ID或记录编号来路由数据。只 要实时操作的表数据量⾜够⼩,请求能够⾜够均匀的分发到多台服务器上的⼩表,那数据库就能通过 ⽔平扩展的⽅式来提⾼性能。
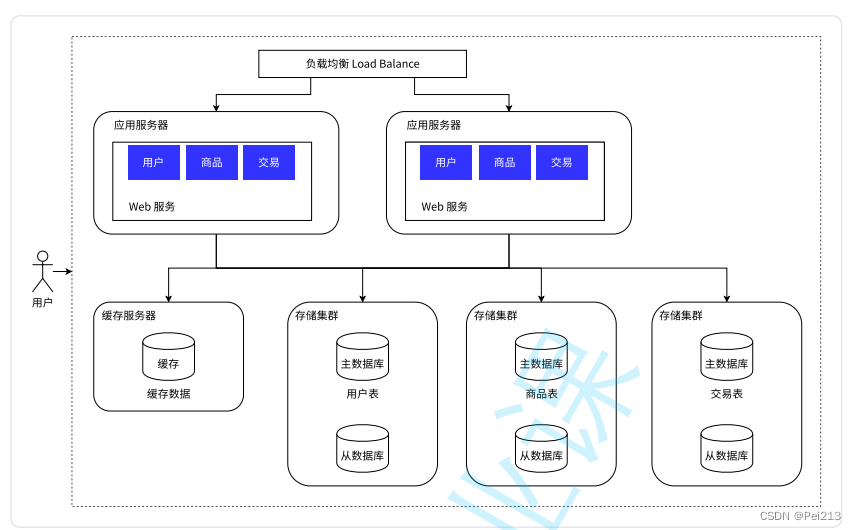
而具体分库分表如何实践还是要结合实际的业务场景来展开 .
7.业务拆分⸺微服务
之前的应用服务器,我们一个服务器程序里面做了很多的业务.这就可能会导致这一个服务器的代码变的越来越复杂.
为了更方便于代码的维护,就可以把这样的一个复杂的服务器,拆分成更多的,功能更单一,但是更小的服务器,也就是微服务.
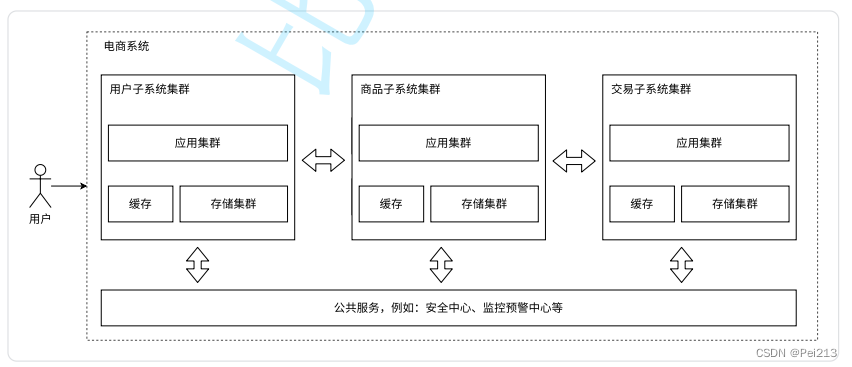
其实,微服务本质上是在解决“人”的问题
随着⼈员增加,业务发展,我们将业务分给不同的开发团队去维护.当应用服务器变复杂了,那么就会需要更多的人来维护,当人多了,就需要配套的管理,把成员组织好,划分组织结构,分成多个组,每个组分别配备领导进行管理.
而分成多个组,就需要把各个服务器进行分工,按照功能,拆分成多组微服务,就可以有利于上述人员的组织结构的分配了.并且各个功能模块之间,通过相关技术,还可以实现相互之间的调⽤关联。甚⾄可以把⼀些类似⽤⼾管理、安全管理、数据采集等业务提成公共服务。
引入微服务,虽然解决了人的问题,但是也要付出一定的代价.
1.系统的性能下降要想保证性能不下降太多,只能引入更多的机器,更多的硬件资源.并且拆出来更多的服务,多个功能之间要更依赖 网络通信.
(网络通信的速度很可能是比硬盘还慢的!!! 幸运的是,由于硬件的发展,网卡现在已经有万兆 网卡.读写速度已经能过超过硬盘读写了)
2.系统复杂程度提高,可用性受到影响.
服务器更多了,出现问题的概率就更大了,这就需要一系列的手段,来保证系统的可用性(更丰富的监控报警,以及配套的运维人员)
四.小结
⾄此,⼀个还算合理的⾼可⽤、⾼并发系统的基本雏形已显。
但是,以上所说的架构演变顺序只 是针对某个侧⾯进⾏单独的改进,在实际场景中,可能同⼀时间会有⼏个问题需要解决,或者可能先 达到瓶颈的是另外的⽅⾯,这时候就应该按照实际问题实际解决。如在政府类的并发量可能不⼤,但 业务可能很丰富的场景,⾼并发就不是重点解决的问题,此时优先需要的可能会是丰富需求的解决⽅ 案。
对于单次实施并且性能指标明确的系统,架构设计到能够⽀持系统的性能指标要求就⾜够了,但 要留有扩展架构的接⼝以便不备之需。对于不断发展的系统,如电商平台,应设计到能满⾜下⼀阶段 ⽤⼾量和性能指标要求的程度,并根据业务的增⻓不断的迭代升级架构,以⽀持更⾼的并发和更丰富的业务。