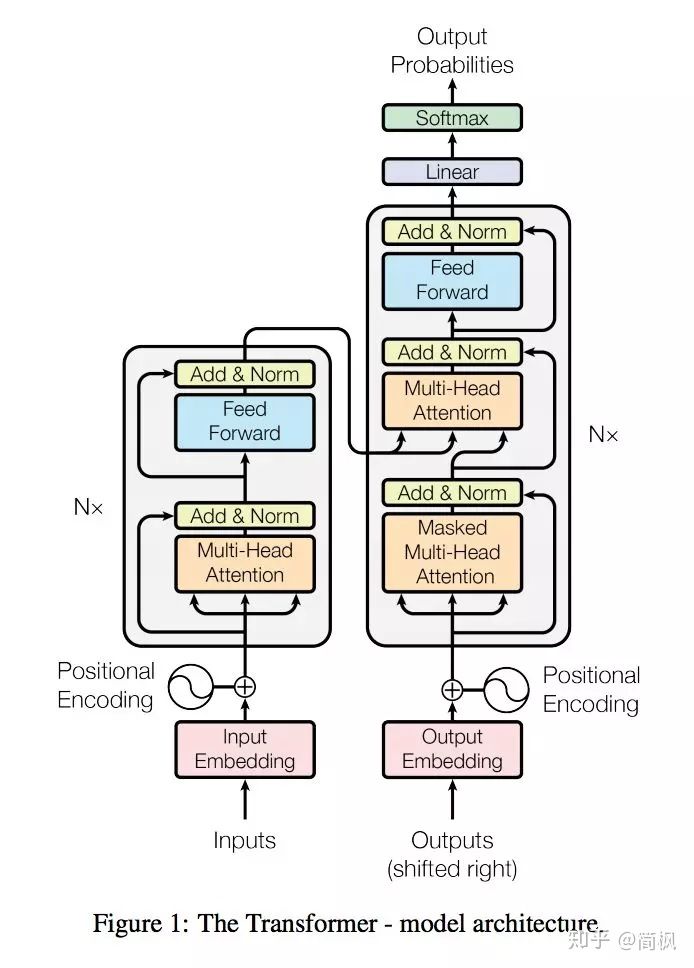
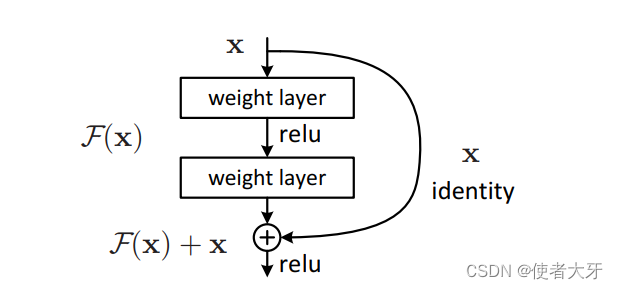
- transformer的整体结构:

1、自注意力机制
- 自注意力机制如下:

- 计算过程:

- 代码如下:
class ScaledDotProductAttention(nn.Module):
def __init__(self, embed_dim, key_size, value_size):
super().__init__()
self.W_q = nn.Linear(embed_dim, key_size, bias=False)
self.W_k = nn.Linear(embed_dim, key_size, bias=False)
self.W_v = nn.Linear(embed_dim, value_size, bias=False)
def forward(self, x, attn_mask=None):
"""
Args:
X: shape: (N, L, embed_dim), input sequence,
是经过input embedding后的输入序列,L个embed_dim维度的嵌入向量
attn_mask: (N, L, L),用于对注意力矩阵(L, L)进行mask
输出:shape:(N, L, embed_dim)
"""
query = self.W_q(x)
key = self.W_k(x)
value = self.W_v(x)
scores = torch.matmul(query, key.transpose(1, 2)) / math.sqrt(query.size(2))
if attn_mask is not None:
scores = scores.masked_fill(attn_mask, 0)
attn_weights = F.softmax(scores, dim=-1)
return torch.matmul(attn_weights, value)
2、多头注意力机制
- 结构如下:

- 计算过程如下:
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads, key_size, value_size, bias=False):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.q_head_dim = key_size // num_heads
self.k_head_dim = key_size // num_heads
self.v_head_dim = value_size // num_heads
self.W_q = nn.Linear(embed_dim, key_size, bias=bias)
self.W_k = nn.Linear(embed_dim, key_size, bias=bias)
self.W_v = nn.Linear(embed_dim, value_size, bias=bias)
self.q_proj = nn.Linear(key_size, key_size, bias=bias)
self.k_proj = nn.Linear(key_size, key_size, bias=bias)
self.v_proj = nn.Linear(value_size, value_size, bias=bias)
self.out_proj = nn.Linear(value_size, embed_dim, bias=bias)
def forward(self, x):
"""
Args:
X: shape: (N, L, embed_dim), input sequence,
是经过input embedding后的输入序列,L个embed_dim维度的嵌入向量
Returns:
output: (N, L, embed_dim)
"""
query = self.W_q(x)
key = self.W_k(x)
value = self.W_v(x)
q, k, v = self.q_proj(query), self.k_proj(key), self.v_proj(value)
N, L, value_size = v.size()
q = q.reshape(N, L, self.num_heads, self.q_head_dim).transpose(1, 2)
k = k.reshape(N, L, self.num_heads, self.k_head_dim).transpose(1, 2)
v = v.reshape(N, L, self.num_heads, self.v_head_dim).transpose(1, 2)
att = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(k.size(-1))
att = F.softmax(att, dim=-1)
output = torch.matmul(att, v)
output = output.transpose(1, 2).reshape(N, L, value_size)
output = self.out_proj(output)
return output