说明:最早出现这个需求,来自博主阅读《罪与罚》,书中陀思妥耶夫斯基有太多的语言描述,以至于我想知道这本书中到底出现了多少对白。文本介绍如果使用python程序统计一本书中的对话,角色名称,标点符号。
找到文件
首先,需要找到你要统计的小说文本文件,如下,分别是《罪与罚》、《白鹿原》两本书的文本文件。
设置统计清单
如果是统计语言描写是不需要的,但如果你需要统计小说中的角色名称,那就需要把角色名称的姓名都罗列出来,当然越多越准确,如下:
# 《白鹿原》中的角色名称
nameTwo = [
"白灵",
"皮匠",
"鹿三",
"黑娃",
"兔娃",
"郑芒",
"方升"
]
nameThree = [
"白嘉轩",
"白秉德",
"白赵氏",
"吴仙草",
"白孝文",
"白孝武",
"白孝义",
"朱先生",
"鹿泰恒",
"鹿子霖",
"鹿兆鹏",
"鹿兆海",
"冷先生",
"鹿惠氏",
"田小蛾",
"郭举人",
"白嘉道",
"吴长贵",
"岳维山",
"胡县长",
"田福贤",
"白兴儿",
"韩裁缝",
"彭县长",
"梁县长",
"郝县长",
"高玉凤",
"鹿兆谦",
]
按照角色名称的长度来分。《罪与罚》中的姓名大多是XXX·XXX,反正是统计长度,拆开成两部分即可,如下:
# 《罪与罚》中的角色名称
nameTwo = [
"罗佳",
"卢任",
"谢苗",
"科赫",
"伊万",
"彼得",
"莉达"
]
nameThree = [
"罗季昂",
"阿廖娜",
"罗季卡",
"帕申卡",
"杜尼娅",
"玛尔法",
"米季卡",
"尼古拉",
"米科拉",
"杜什金",
"科利亚",
"波莉娅",
"波莲卡",
"廖尼娅",
"索尼娅",
"索菲娅",
"福米奇",
"伊利亚",
"瓦赫鲁",
]
nameFour = [
"娜塔利娅",
"莉扎薇塔",
"扎哈雷奇",
"杜涅奇卡",
"卡捷琳娜",
"阿玛莉娅",
"阿尔卡季",
"拉祖米欣",
"索涅奇卡",
"德米特里",
"波列奇卡",
"切巴罗夫",
"克留科夫",
"尼科季姆",
"米科尔卡",
"德米特里",
"莉多奇卡",
"扎苗托夫",
"亚历山大",
"阿凡纳西",
"波尔菲里",
]
…………
编码
代码思想是:
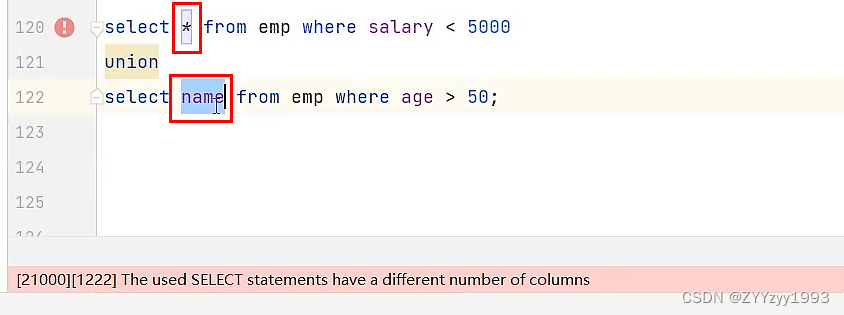
统计对话,当遇到文本中的左引号时,表示这是语言描写,标记为对话开始;当遇到文本中的右引号时,表示这是对话结束。以此来统计语言描写。
统计文本中的角色姓名,通过角色名称的长度,分长度去遍历文本,如果符合该长度的字符串,在角色名称列表中,说明这是一个角色名称,则统计下来,存入到一个字典中,字典的键为角色名称,值为出现的数量。
统计文本的标点符号,则是通过判断该字符是否处于汉字区间即可,不包括0-9的数字,因为一般文学作品中的数字也会用大写汉字来表示,如一、二、三……,当然,也不绝对。
# 文件路径
path = r"C:\Users\10765\Desktop\books\zuiyufa.txt"
# 总字数统计
str = ""
# 临时字数统计
tempStr = []
nameTwo = [
"罗佳",
"卢任",
"谢苗",
"科赫",
"伊万",
"彼得",
"莉达"
]
nameThree = [
"罗季昂",
"阿廖娜",
"罗季卡",
"帕申卡",
"杜尼娅",
"玛尔法",
"米季卡",
"尼古拉",
"米科拉",
"杜什金",
"科利亚",
"波莉娅",
"波莲卡",
"廖尼娅",
"索尼娅",
"索菲娅",
"福米奇",
"伊利亚",
"瓦赫鲁",
]
nameFour = [
"娜塔利娅",
"莉扎薇塔",
"扎哈雷奇",
"杜涅奇卡",
"卡捷琳娜",
"阿玛莉娅",
"阿尔卡季",
"拉祖米欣",
"索涅奇卡",
"德米特里",
"波列奇卡",
"切巴罗夫",
"克留科夫",
"尼科季姆",
"米科尔卡",
"德米特里",
"莉多奇卡",
"扎苗托夫",
"亚历山大",
"阿凡纳西",
"波尔菲里",
]
nameFive = [
"罗曼诺维奇",
"伊万诺芙娜",
"叶戈罗芙娜",
"娜斯塔西娅",
"帕夫洛芙娜",
"扎尔尼岑娜",
"扎哈罗维奇",
"彼特罗维奇",
"谢苗诺芙娜",
"费多罗芙娜",
"普莉赫里娅",
"阿芙多季娅",
"罗曼诺芙娜",
"伊万诺维奇",
"彼特罗芙娜",
"弗拉祖米欣",
"赫鲁维莫夫",
"杰缅季耶夫",
"尼科拉什卡",
]
nameSix = [
"普拉斯科维娅",
"马尔梅拉多夫",
"利佩韦赫泽尔",
"普罗科菲伊奇",
"托尔斯佳科夫",
"米哈依洛维奇"
]
nameSeven = [
"佩斯特里亚科夫",
"拉斯科利尼科夫",
"娜斯塔西尤什卡",
"亚历山德罗芙娜",
"拉斯科利尼科娃",
"斯维德里盖洛娃",
"斯维德里盖洛夫",
"格里戈里耶维奇",
"卡佩尔纳乌莫夫",
]
# 统计人物名字数目
dic = {}
# 统计人物名字数目
nameSum = 0
# 统计对话/想象字数
wordSum = 0
# 标记对话/想象开始标记
flag = False
# 输出文件名
print("《罪与罚》:")
# 读取文件
with open(path, "r", encoding="utf-8", errors="ignore") as f: # 设置对象
str = f.read() # 读取文件内容
# 输出原著总字符数
print("原著总字符数:%d个" % (str.__len__()))
# 统计人物名字为两个字的数目
for i in str:
tempStr.append(i)
if tempStr.__len__() == 2:
s = "".join(tempStr)
if s in nameTwo and s not in dic:
dic[s] = 1
tempStr.clear()
elif s in nameTwo and s in dic:
dic[s] = dic[s] + 1
tempStr.clear()
elif s not in nameTwo:
del tempStr[0]
# 统计人物名字为三个字的数目
for i in str:
tempStr.append(i)
if tempStr.__len__() == 3:
s = "".join(tempStr)
if s in nameThree and s not in dic:
dic[s] = 1
tempStr.clear()
elif s in nameThree and s in dic:
dic[s] = dic[s] + 1
tempStr.clear()
elif s not in nameThree:
del tempStr[0]
# 统计人物名字为四个字的数目
for i in str:
tempStr.append(i)
if tempStr.__len__() == 4:
s = "".join(tempStr)
if s in nameFour and s not in dic:
dic[s] = 1
tempStr.clear()
elif s in nameFour and s in dic:
dic[s] = dic[s] + 1
tempStr.clear()
elif s not in nameFour:
del tempStr[0]
# 统计人物名字为五个字的数目
for i in str:
tempStr.append(i)
if tempStr.__len__() == 5:
s = "".join(tempStr)
if s in nameFive and s not in dic:
dic[s] = 1
tempStr.clear()
elif s in nameFive and s in dic:
dic[s] = dic[s] + 1
tempStr.clear()
elif s not in nameFive:
del tempStr[0]
# 统计人物名字为六个字的数目
for i in str:
tempStr.append(i)
if tempStr.__len__() == 6:
s = "".join(tempStr)
if s in nameSix and s not in dic:
dic[s] = 1
tempStr.clear()
elif s in nameSix and s in dic:
dic[s] = dic[s] + 1
tempStr.clear()
elif s not in nameSix:
del tempStr[0]
# 统计人物名字为七个字的数目
for i in str:
tempStr.append(i)
if tempStr.__len__() == 7:
s = "".join(tempStr)
if s in nameSeven and s not in dic:
dic[s] = 1
tempStr.clear()
elif s in nameSeven and s in dic:
dic[s] = dic[s] + 1
tempStr.clear()
elif s not in nameSeven:
del tempStr[0]
# 统计人物名字数目总数
for i in dic:
nameSum = nameSum + (i.__len__() * dic[i])
print("人物名字数目:%d个" % nameSum)
# 左引号数目
markLeft = 0
# 右引号数目
markRight = 0
# 统计对话/想象字数
for i in str:
if i == "“":
flag = True
markLeft = markLeft + 1
elif i == "”":
flag = False
wordSum = wordSum - 1
markRight = markRight + 1
if flag:
wordSum = wordSum + 1
print("对话字数:%d个" % wordSum)
for i in str:
if i < "\u4e00" or i > "\u9fa5":
str = str.replace(i, "")
print("去掉标点符号:%d个" % str.__len__())
运行如下
《罪与罚》的统计如下:

《白鹿原》的统计如下(更换一下文件和角色名称列表即可):

可以看到,《罪与罚》中的对话达到了惊人的22万字,与之相比,总字数差不多的《白鹿原》只有12万不到。