pandas基础介绍-命令模版
- 描述性统计量
- pandas 统计函数
- 相关与协方差
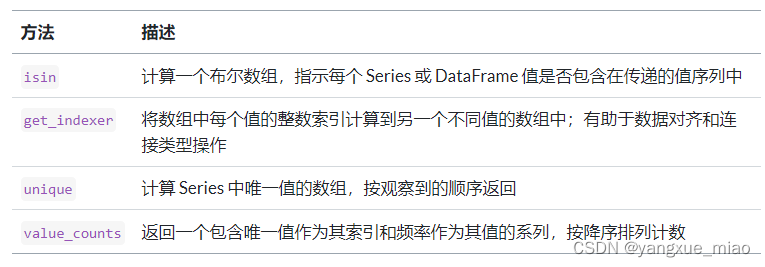
- 唯一值,频次统计,成员关系
- 1. Series.unique()
- 2. Series/DataFrame/array.value_counts()
- 3. Series.isin()
- 4. get_indexer() 索引对应转换
本文介绍pandas中一些常用的描述性统计量相关知识,包括pandas统计函数、相关系数与协方差、唯一值、频次统计和成员关系。希望可以帮助到有需要的小伙伴。
描述性统计量
pandas 统计函数
从 Series 中提取单个值(如总和或平均值)的方法,或从 DataFrame 的行或列中提取一系列值的方法。与 NumPy 数组上的类似方法相比,它们具有针对缺失数据的内置处理,默认跳过。
- 以sum举例
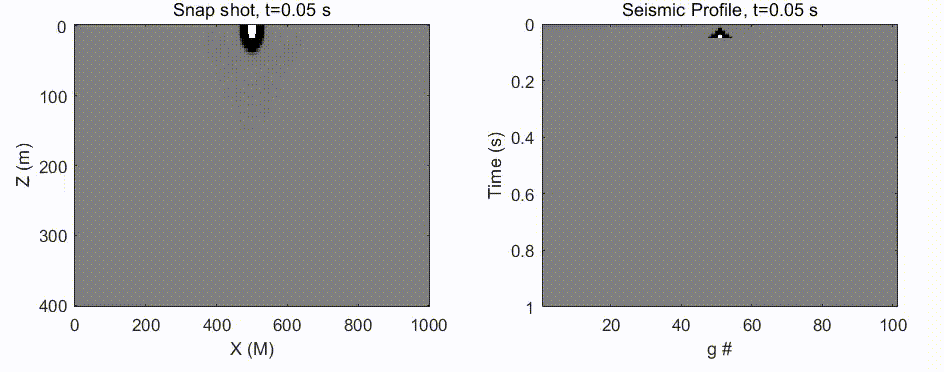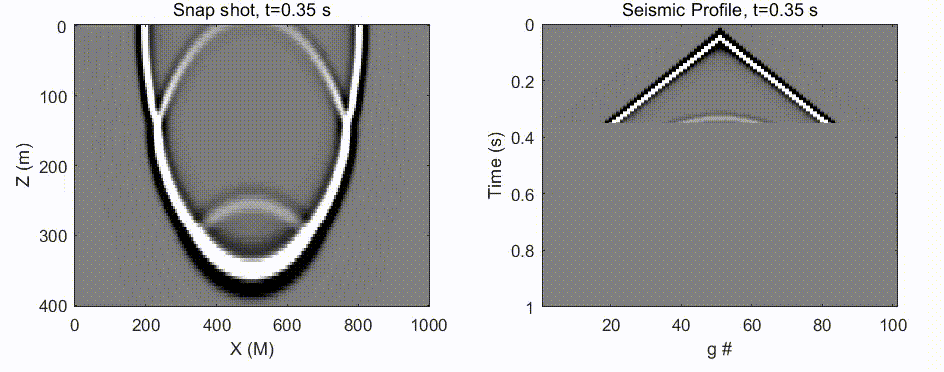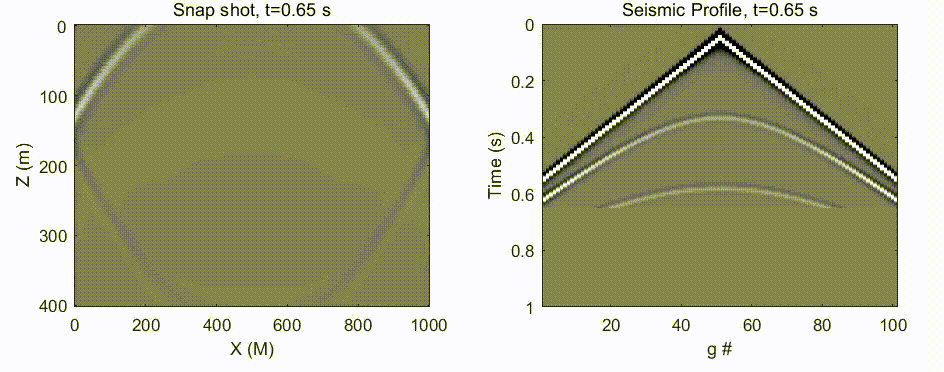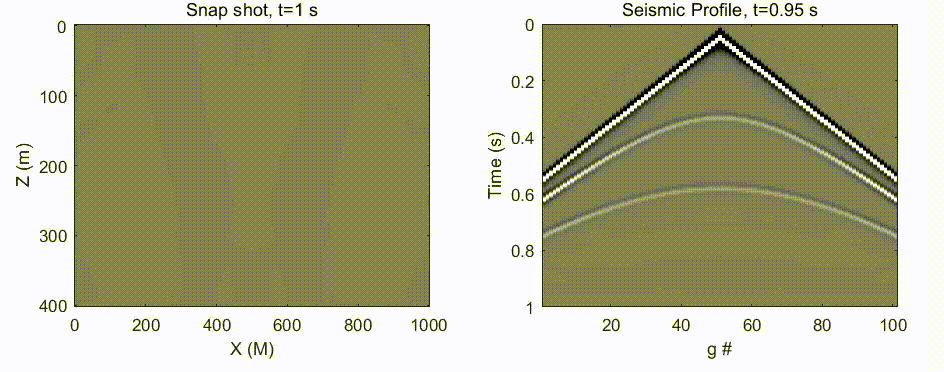
#默认沿行计算,得到每一列的和
df.sum()
df.sum(axis='index')
#通过制定axis 变为沿列计算,得到每一行的和
df.sum(axis='columns')
#若不想跳过缺失数据,某行中有NA 则结果就为NA,使用 skipna
df.sum(axis='columns',skipna=False)
可以选择的参数:

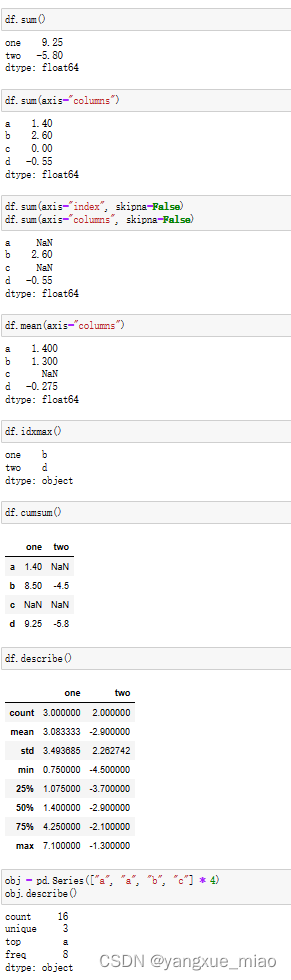
- 求达到最大值时的索引 df.idxmax()
- 数字类型和非数字类型统计描述 df.describe()
数字类型返回非零计数、均值、方差、最大最小值等。非数字烈性返回元素出现的频次 - 其他描述性统计方法

相关与协方差
- 相关性
# 返回矩阵各个列之间的相关性系数
df.corr()
#计算某两列之间的相关性
df['col1'].corr(df['col2'])
#计算某列与整个矩阵之间的相关性
df.corrwith(df['col']
- 协方差
# 返回矩阵各个列之间的协方差
df.cov()
#计算某两列之间的协方差
df['col1'].cov(df['col2'])
唯一值,频次统计,成员关系
1. Series.unique()
返回Series中元素去掉重复值的结果,不排序
2. Series/DataFrame/array.value_counts()
Series 统计某一列各种值出现的次数
DataFrame 把每一行当做整体,统计其出现的次数
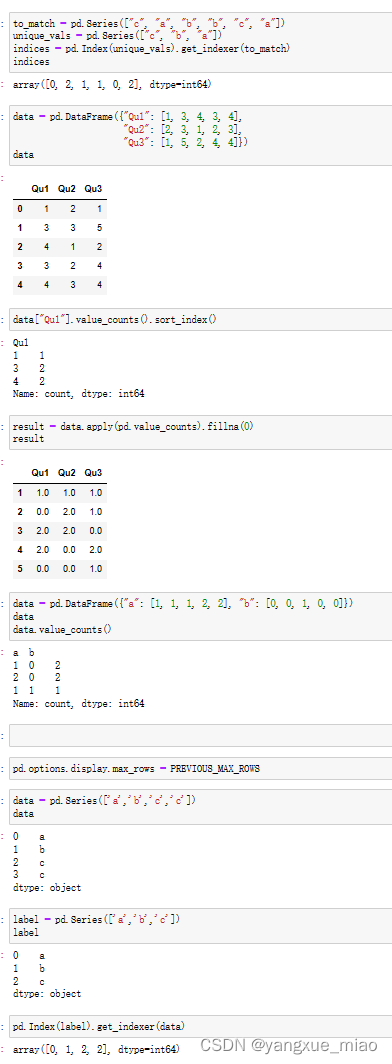
Series.value_counts()
df.value_counts()
#计算DF中每一列每个值出现的次数
df.apply(pd.value_counts).fillna(0)
3. Series.isin()
判断元素是否在Series中,返回布尔值
mask = obj.isin(['b','c'])
obj[mask]
4. get_indexer() 索引对应转换
Index_A.get_indexer(Series_B) 得到B的值对应的A种的索引的数组
to_match = pd.Series(['c','a','b','b','c','a'])
unique_vals = pd.Series(['c','b','a'])
indices = pd.Index(unique_vals).get_indexer(to_match)