1.README.md:(查看项目整体结构以及各个部分作用)
# Text Classification with RNN
使用循环神经网络进行中文文本分类
本文是基于TensorFlow在中文数据集上的简化实现,使用了字符级RNN对中文文本进行分类,达到了较好的效果。
## 环境
- Python 3
- TensorFlow 1.3以上
- numpy
- scikit-learn
- scipy
## 数据集
使用THUCNews的一个子集进行训练与测试,数据集请自行到[THUCTC:一个高效的中文文本分类工具包](http://thuctc.thunlp.org/)下载,请遵循数据提供方的开源协议。
本次训练使用了其中的10个分类,每个分类6500条数据。
类别如下:
```
体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐
```
这个子集可以在此下载:链接: https://pan.baidu.com/s/1hugrfRu 密码: qfud
数据集划分如下:
- 训练集: 5000*10
- 验证集: 500*10
- 测试集: 1000*10
从原数据集生成子集的过程请参看`helper`下的两个脚本。其中,`copy_data.sh`用于从每个分类拷贝6500个文件,`cnews_group.py`用于将多个文件整合到一个文件中。执行该文件后,得到三个数据文件:
- cnews.train.txt: 训练集(50000条)
- cnews.val.txt: 验证集(5000条)
- cnews.test.txt: 测试集(10000条)
## 预处理
`data/cnews_loader.py`为数据的预处理文件。
- `read_file()`: 读取文件数据;
- `build_vocab()`: 构建词汇表,使用字符级的表示,这一函数会将词汇表存储下来,避免每一次重复处理;
- `read_vocab()`: 读取上一步存储的词汇表,转换为`{词:id}`表示;
- `read_category()`: 将分类目录固定,转换为`{类别: id}`表示;
- `to_words()`: 将一条由id表示的数据重新转换为文字;
- `process_file()`: 将数据集从文字转换为固定长度的id序列表示;
- `batch_iter()`: 为神经网络的训练准备经过shuffle的批次的数据。
经过数据预处理,数据的格式如下:
| Data | Shape | Data | Shape |
| :---------- | :---------- | :---------- | :---------- |
| x_train | [50000, 600] | y_train | [50000, 10] |
| x_val | [5000, 600] | y_val | [5000, 10] |
| x_test | [10000, 600] | y_test | [10000, 10] |
## RNN循环神经网络
### 配置项
RNN可配置的参数如下所示,在`rnn_model.py`中。
```python
class TRNNConfig(object):
"""RNN配置参数"""
# 模型参数
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
vocab_size = 5000 # 词汇表达小
num_layers= 2 # 隐藏层层数
hidden_dim = 128 # 隐藏层神经元
rnn = 'gru' # lstm 或 gru
dropout_keep_prob = 0.8 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 128 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
```
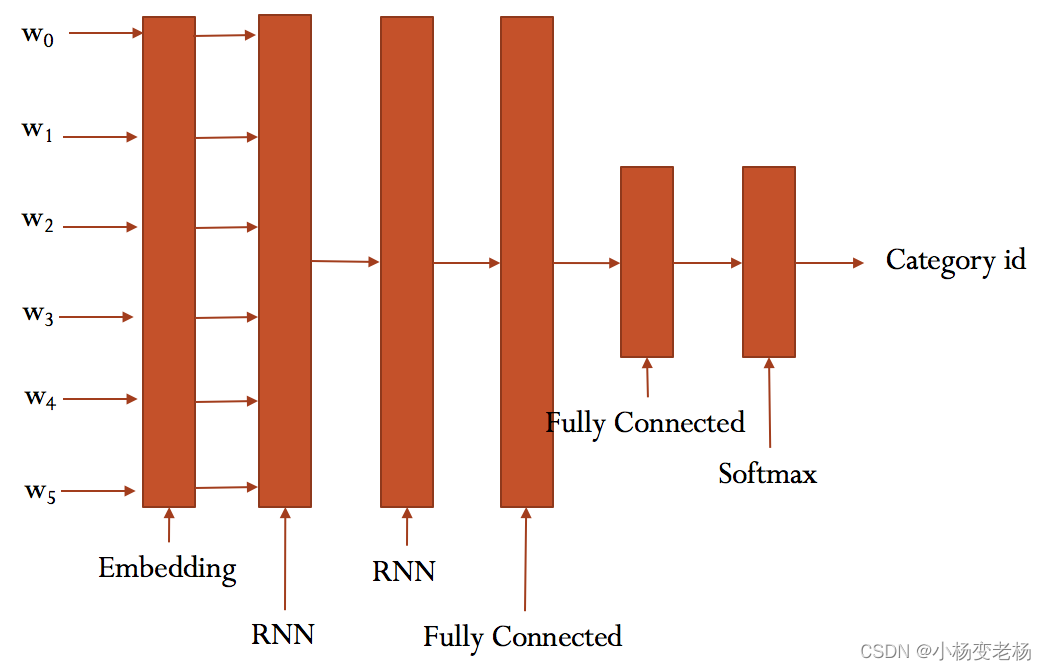
### RNN模型
具体参看`rnn_model.py`的实现。
大致结构如下:

### 训练与验证
> 这部分的代码与 run_cnn.py极为相似,只需要将模型和部分目录稍微修改。
运行 `python run_rnn.py train`,可以开始训练。
> 若之前进行过训练,请把tensorboard/textrnn删除,避免TensorBoard多次训练结果重叠。
```
Configuring RNN model...
Configuring TensorBoard and Saver...
Loading training and validation data...
Time usage: 0:00:14
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 2.3, Train Acc: 8.59%, Val Loss: 2.3, Val Acc: 11.96%, Time: 0:00:08 *
Iter: 100, Train Loss: 0.95, Train Acc: 64.06%, Val Loss: 1.3, Val Acc: 53.06%, Time: 0:01:15 *
Iter: 200, Train Loss: 0.61, Train Acc: 79.69%, Val Loss: 0.94, Val Acc: 69.88%, Time: 0:02:22 *
Iter: 300, Train Loss: 0.49, Train Acc: 85.16%, Val Loss: 0.63, Val Acc: 81.44%, Time: 0:03:29 *
Epoch: 2
Iter: 400, Train Loss: 0.23, Train Acc: 92.97%, Val Loss: 0.6, Val Acc: 82.86%, Time: 0:04:36 *
Iter: 500, Train Loss: 0.27, Train Acc: 92.97%, Val Loss: 0.47, Val Acc: 86.72%, Time: 0:05:43 *
Iter: 600, Train Loss: 0.13, Train Acc: 98.44%, Val Loss: 0.43, Val Acc: 87.46%, Time: 0:06:50 *
Iter: 700, Train Loss: 0.24, Train Acc: 91.41%, Val Loss: 0.46, Val Acc: 87.12%, Time: 0:07:57
Epoch: 3
Iter: 800, Train Loss: 0.11, Train Acc: 96.09%, Val Loss: 0.49, Val Acc: 87.02%, Time: 0:09:03
Iter: 900, Train Loss: 0.15, Train Acc: 96.09%, Val Loss: 0.55, Val Acc: 85.86%, Time: 0:10:10
Iter: 1000, Train Loss: 0.17, Train Acc: 96.09%, Val Loss: 0.43, Val Acc: 89.44%, Time: 0:11:18 *
Iter: 1100, Train Loss: 0.25, Train Acc: 93.75%, Val Loss: 0.42, Val Acc: 88.98%, Time: 0:12:25
Epoch: 4
Iter: 1200, Train Loss: 0.14, Train Acc: 96.09%, Val Loss: 0.39, Val Acc: 89.82%, Time: 0:13:32 *
Iter: 1300, Train Loss: 0.2, Train Acc: 96.09%, Val Loss: 0.43, Val Acc: 88.68%, Time: 0:14:38
Iter: 1400, Train Loss: 0.012, Train Acc: 100.00%, Val Loss: 0.37, Val Acc: 90.58%, Time: 0:15:45 *
Iter: 1500, Train Loss: 0.15, Train Acc: 96.88%, Val Loss: 0.39, Val Acc: 90.58%, Time: 0:16:52
Epoch: 5
Iter: 1600, Train Loss: 0.075, Train Acc: 97.66%, Val Loss: 0.41, Val Acc: 89.90%, Time: 0:17:59
Iter: 1700, Train Loss: 0.042, Train Acc: 98.44%, Val Loss: 0.41, Val Acc: 90.08%, Time: 0:19:06
Iter: 1800, Train Loss: 0.08, Train Acc: 97.66%, Val Loss: 0.38, Val Acc: 91.36%, Time: 0:20:13 *
Iter: 1900, Train Loss: 0.089, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.18%, Time: 0:21:20
Epoch: 6
Iter: 2000, Train Loss: 0.092, Train Acc: 96.88%, Val Loss: 0.36, Val Acc: 91.42%, Time: 0:22:27 *
Iter: 2100, Train Loss: 0.062, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.56%, Time: 0:23:34
Iter: 2200, Train Loss: 0.053, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.02%, Time: 0:24:41
Iter: 2300, Train Loss: 0.12, Train Acc: 96.09%, Val Loss: 0.37, Val Acc: 90.84%, Time: 0:25:48
Epoch: 7
Iter: 2400, Train Loss: 0.014, Train Acc: 100.00%, Val Loss: 0.41, Val Acc: 90.38%, Time: 0:26:55
Iter: 2500, Train Loss: 0.14, Train Acc: 96.88%, Val Loss: 0.37, Val Acc: 91.22%, Time: 0:28:01
Iter: 2600, Train Loss: 0.11, Train Acc: 96.88%, Val Loss: 0.43, Val Acc: 89.76%, Time: 0:29:08
Iter: 2700, Train Loss: 0.089, Train Acc: 97.66%, Val Loss: 0.37, Val Acc: 91.18%, Time: 0:30:15
Epoch: 8
Iter: 2800, Train Loss: 0.0081, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 90.66%, Time: 0:31:22
Iter: 2900, Train Loss: 0.017, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 89.62%, Time: 0:32:29
Iter: 3000, Train Loss: 0.061, Train Acc: 96.88%, Val Loss: 0.43, Val Acc: 90.04%, Time: 0:33:36
No optimization for a long time, auto-stopping...
```
在验证集上的最佳效果为91.42%,经过了8轮迭代停止,速度相比CNN慢很多。
准确率和误差如图所示:

### 测试
运行 `python run_rnn.py test` 在测试集上进行测试。
```
Testing...
Test Loss: 0.21, Test Acc: 94.22%
Precision, Recall and F1-Score...
precision recall f1-score support
体育 0.99 0.99 0.99 1000
财经 0.91 0.99 0.95 1000
房产 1.00 1.00 1.00 1000
家居 0.97 0.73 0.83 1000
教育 0.91 0.92 0.91 1000
科技 0.93 0.96 0.94 1000
时尚 0.89 0.97 0.93 1000
时政 0.93 0.93 0.93 1000
游戏 0.95 0.97 0.96 1000
娱乐 0.97 0.96 0.97 1000
avg / total 0.94 0.94 0.94 10000
Confusion Matrix...
[[988 0 0 0 4 0 2 0 5 1]
[ 0 990 1 1 1 1 0 6 0 0]
[ 0 2 996 1 1 0 0 0 0 0]
[ 2 71 1 731 51 20 88 28 3 5]
[ 1 3 0 7 918 23 4 31 9 4]
[ 1 3 0 3 0 964 3 5 21 0]
[ 1 0 1 7 1 3 972 0 6 9]
[ 0 16 0 0 22 26 0 931 2 3]
[ 2 3 0 0 2 2 12 0 972 7]
[ 0 3 1 1 7 3 11 5 9 960]]
Time usage: 0:00:33
```
在测试集上的准确率达到了94.22%,且各类的precision, recall和f1-score,除了家居这一类别,都超过了0.9。
从混淆矩阵可以看出分类效果非常优秀。
## 预测
为方便预测,项目 中 `predict.py` 提供了 RNN 模型的预测方法。
## 比较(TEXTCNN&TEXTRNN)
对比两个模型分类效果,可见RNN除了在家居分类的表现不是很理想,其他几个类别较CNN差别不大。
还可以通过进一步的调节参数,来达到更好的效果。
2.主程序代码
# coding: utf-8
from __future__ import print_function
import os
import sys
import time
from datetime import timedelta
import numpy as np
import tensorflow as tf
from sklearn import metrics
from rnn_model import TRNNConfig, TextRNN
from data.cnews_loader import read_vocab, read_category, batch_iter, process_file, build_vocab
base_dir = 'data/cnews'
train_dir = os.path.join(base_dir, 'cnews.train.txt')
test_dir = os.path.join(base_dir, 'cnews.test.txt')
val_dir = os.path.join(base_dir, 'cnews.val.txt')
vocab_dir = os.path.join(base_dir, 'cnews.vocab.txt')
save_dir = 'checkpoints/textrnn'
save_path = os.path.join(save_dir, 'best_validation') # 最佳验证结果保存路径
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
def feed_data(x_batch, y_batch, keep_prob):
feed_dict = {
model.input_x: x_batch,
model.input_y: y_batch,
model.keep_prob: keep_prob
}
return feed_dict
def evaluate(sess, x_, y_):
"""评估在某一数据上的准确率和损失"""
data_len = len(x_)
batch_eval = batch_iter(x_, y_, 128)
total_loss = 0.0
total_acc = 0.0
for x_batch, y_batch in batch_eval:
batch_len = len(x_batch)
feed_dict = feed_data(x_batch, y_batch, 1.0)
loss, acc = sess.run([model.loss, model.acc], feed_dict=feed_dict)
total_loss += loss * batch_len
total_acc += acc * batch_len
return total_loss / data_len, total_acc / data_len
def train():
print("Configuring TensorBoard and Saver...")
# 配置 Tensorboard,重新训练时,请将tensorboard文件夹删除,不然图会覆盖
tensorboard_dir = 'tensorboard/textrnn'
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
tf.summary.scalar("loss", model.loss)
tf.summary.scalar("accuracy", model.acc)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(tensorboard_dir)
# 配置 Saver
saver = tf.train.Saver()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print("Loading training and validation data...")
# 载入训练集与验证集
start_time = time.time()
x_train, y_train = process_file(train_dir, word_to_id, cat_to_id, config.seq_length)
x_val, y_val = process_file(val_dir, word_to_id, cat_to_id, config.seq_length)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# 创建session
session = tf.Session()
session.run(tf.global_variables_initializer())
writer.add_graph(session.graph)
print('Training and evaluating...')
start_time = time.time()
total_batch = 0 # 总批次
best_acc_val = 0.0 # 最佳验证集准确率
last_improved = 0 # 记录上一次提升批次
require_improvement = 1000 # 如果超过1000轮未提升,提前结束训练
flag = False
for epoch in range(config.num_epochs):
print('Epoch:', epoch + 1)
batch_train = batch_iter(x_train, y_train, config.batch_size)
for x_batch, y_batch in batch_train:
feed_dict = feed_data(x_batch, y_batch, config.dropout_keep_prob)
if total_batch % config.save_per_batch == 0:
# 每多少轮次将训练结果写入tensorboard scalar
s = session.run(merged_summary, feed_dict=feed_dict)
writer.add_summary(s, total_batch)
if total_batch % config.print_per_batch == 0:
# 每多少轮次输出在训练集和验证集上的性能
feed_dict[model.keep_prob] = 1.0
loss_train, acc_train = session.run([model.loss, model.acc], feed_dict=feed_dict)
loss_val, acc_val = evaluate(session, x_val, y_val) # todo
if acc_val > best_acc_val: # 10 11 1010
# 保存最好结果
best_acc_val = acc_val
last_improved = total_batch # total_batch = last_improved=10
saver.save(sess=session, save_path=save_path)
improved_str = '*'
else:
improved_str = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>6.2}, Train Acc: {2:>7.2%},' \
+ ' Val Loss: {3:>6.2}, Val Acc: {4:>7.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss_train, acc_train, loss_val, acc_val, time_dif, improved_str))
session.run(model.optim, feed_dict=feed_dict) # 运行优化
total_batch += 1
# total_batch 1010 last 10 > 1000
if total_batch - last_improved > require_improvement:
# 验证集正确率长期不提升,提前结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break # 跳出循环
if flag: # 同上
break
def test():
print("Loading test data...")
start_time = time.time()
x_test, y_test = process_file(test_dir, word_to_id, cat_to_id, config.seq_length)
session = tf.Session()
session.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess=session, save_path=save_path) # 读取保存的模型
print('Testing...')
loss_test, acc_test = evaluate(session, x_test, y_test)
msg = 'Test Loss: {0:>6.2}, Test Acc: {1:>7.2%}'
print(msg.format(loss_test, acc_test))
batch_size = 128
data_len = len(x_test)
num_batch = int((data_len - 1) / batch_size) + 1
y_test_cls = np.argmax(y_test, 1)
y_pred_cls = np.zeros(shape=len(x_test), dtype=np.int32) # 保存预测结果
for i in range(num_batch): # 逐批次处理
start_id = i * batch_size
end_id = min((i + 1) * batch_size, data_len)
feed_dict = {
model.input_x: x_test[start_id:end_id],
model.keep_prob: 1.0
}
y_pred_cls[start_id:end_id] = session.run(model.y_pred_cls, feed_dict=feed_dict)
# 评估
print("Precision, Recall and F1-Score...")
print(metrics.classification_report(y_test_cls, y_pred_cls, target_names=categories))
# 混淆矩阵
print("Confusion Matrix...")
cm = metrics.confusion_matrix(y_test_cls, y_pred_cls)
print(cm)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
if __name__ == '__main__':
if len(sys.argv) != 2 or sys.argv[1] not in ['train', 'test']:
raise ValueError("""usage: python run_rnn.py [train / test]""")
print('Configuring RNN model...')
config = TRNNConfig()
if not os.path.exists(vocab_dir): # 如果不存在词汇表,重建
build_vocab(train_dir, vocab_dir, config.vocab_size)
categories, cat_to_id = read_category()
words, word_to_id = read_vocab(vocab_dir)
config.vocab_size = len(words)
model = TextRNN(config)
if sys.argv[1] == 'train':
train()
else:
test()
print(sys.argv)
3.模型结构及代码
# coding: utf-8
from __future__ import print_function
import os
import sys
import time
from datetime import timedelta
import numpy as np
import tensorflow as tf
from sklearn import metrics
from rnn_model import TRNNConfig, TextRNN
from data.cnews_loader import read_vocab, read_category, batch_iter, process_file, build_vocab
base_dir = 'data/cnews'
train_dir = os.path.join(base_dir, 'cnews.train.txt')
test_dir = os.path.join(base_dir, 'cnews.test.txt')
val_dir = os.path.join(base_dir, 'cnews.val.txt')
vocab_dir = os.path.join(base_dir, 'cnews.vocab.txt')
save_dir = 'checkpoints/textrnn'
save_path = os.path.join(save_dir, 'best_validation') # 最佳验证结果保存路径
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
def feed_data(x_batch, y_batch, keep_prob):
feed_dict = {
model.input_x: x_batch,
model.input_y: y_batch,
model.keep_prob: keep_prob
}
return feed_dict
def evaluate(sess, x_, y_):
"""评估在某一数据上的准确率和损失"""
data_len = len(x_)
batch_eval = batch_iter(x_, y_, 128)
total_loss = 0.0
total_acc = 0.0
for x_batch, y_batch in batch_eval:
batch_len = len(x_batch)
feed_dict = feed_data(x_batch, y_batch, 1.0)
loss, acc = sess.run([model.loss, model.acc], feed_dict=feed_dict)
total_loss += loss * batch_len
total_acc += acc * batch_len
return total_loss / data_len, total_acc / data_len
def train():
print("Configuring TensorBoard and Saver...")
# 配置 Tensorboard,重新训练时,请将tensorboard文件夹删除,不然图会覆盖
tensorboard_dir = 'tensorboard/textrnn'
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
tf.summary.scalar("loss", model.loss)
tf.summary.scalar("accuracy", model.acc)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(tensorboard_dir)
# 配置 Saver
saver = tf.train.Saver()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print("Loading training and validation data...")
# 载入训练集与验证集
start_time = time.time()
x_train, y_train = process_file(train_dir, word_to_id, cat_to_id, config.seq_length)
x_val, y_val = process_file(val_dir, word_to_id, cat_to_id, config.seq_length)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# 创建session
session = tf.Session()
session.run(tf.global_variables_initializer())
writer.add_graph(session.graph)
print('Training and evaluating...')
start_time = time.time()
total_batch = 0 # 总批次
best_acc_val = 0.0 # 最佳验证集准确率
last_improved = 0 # 记录上一次提升批次
require_improvement = 1000 # 如果超过1000轮未提升,提前结束训练
flag = False
for epoch in range(config.num_epochs):
print('Epoch:', epoch + 1)
batch_train = batch_iter(x_train, y_train, config.batch_size)
for x_batch, y_batch in batch_train:
feed_dict = feed_data(x_batch, y_batch, config.dropout_keep_prob)
if total_batch % config.save_per_batch == 0:
# 每多少轮次将训练结果写入tensorboard scalar
s = session.run(merged_summary, feed_dict=feed_dict)
writer.add_summary(s, total_batch)
if total_batch % config.print_per_batch == 0:
# 每多少轮次输出在训练集和验证集上的性能
feed_dict[model.keep_prob] = 1.0
loss_train, acc_train = session.run([model.loss, model.acc], feed_dict=feed_dict)
loss_val, acc_val = evaluate(session, x_val, y_val) # todo
if acc_val > best_acc_val: # 10 11 1010
# 保存最好结果
best_acc_val = acc_val
last_improved = total_batch # total_batch = last_improved=10
saver.save(sess=session, save_path=save_path)
improved_str = '*'
else:
improved_str = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>6.2}, Train Acc: {2:>7.2%},' \
+ ' Val Loss: {3:>6.2}, Val Acc: {4:>7.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss_train, acc_train, loss_val, acc_val, time_dif, improved_str))
session.run(model.optim, feed_dict=feed_dict) # 运行优化
total_batch += 1
# total_batch 1010 last 10 > 1000
if total_batch - last_improved > require_improvement:
# 验证集正确率长期不提升,提前结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break # 跳出循环
if flag: # 同上
break
def test():
print("Loading test data...")
start_time = time.time()
x_test, y_test = process_file(test_dir, word_to_id, cat_to_id, config.seq_length)
session = tf.Session()
session.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess=session, save_path=save_path) # 读取保存的模型
print('Testing...')
loss_test, acc_test = evaluate(session, x_test, y_test)
msg = 'Test Loss: {0:>6.2}, Test Acc: {1:>7.2%}'
print(msg.format(loss_test, acc_test))
batch_size = 128
data_len = len(x_test)
num_batch = int((data_len - 1) / batch_size) + 1
y_test_cls = np.argmax(y_test, 1)
y_pred_cls = np.zeros(shape=len(x_test), dtype=np.int32) # 保存预测结果
for i in range(num_batch): # 逐批次处理
start_id = i * batch_size
end_id = min((i + 1) * batch_size, data_len)
feed_dict = {
model.input_x: x_test[start_id:end_id],
model.keep_prob: 1.0
}
y_pred_cls[start_id:end_id] = session.run(model.y_pred_cls, feed_dict=feed_dict)
# 评估
print("Precision, Recall and F1-Score...")
print(metrics.classification_report(y_test_cls, y_pred_cls, target_names=categories))
# 混淆矩阵
print("Confusion Matrix...")
cm = metrics.confusion_matrix(y_test_cls, y_pred_cls)
print(cm)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
if __name__ == '__main__':
if len(sys.argv) != 2 or sys.argv[1] not in ['train', 'test']:
raise ValueError("""usage: python run_rnn.py [train / test]""")
print('Configuring RNN model...')
config = TRNNConfig()
if not os.path.exists(vocab_dir): # 如果不存在词汇表,重建
build_vocab(train_dir, vocab_dir, config.vocab_size)
categories, cat_to_id = read_category()
words, word_to_id = read_vocab(vocab_dir)
config.vocab_size = len(words)
model = TextRNN(config)
if sys.argv[1] == 'train':
train()
else:
test()
print(sys.argv)
4.以上是模型代码以及主程序代码,完整代码请载以下链接下载:
链接: https://pan.baidu.com/s/1yOu0DogWkL8WOJksJmeiPw?pwd=4bsg 提取码: 4bsg 复制这段内容后打开百度网盘手机App,操作更方便哦
--来自百度网盘超级会员v4的分享

![[附源码]Node.js计算机毕业设计高校教学过程管理系统Express](https://img-blog.csdnimg.cn/e82bb92ebac64ddfae42f202eb704758.png)