前言
今天给大家介绍的是Python爬虫批量下载旅游景点信息数据,在这里给需要的小伙伴们代码,并且给出一点小心得。
首先是爬取之前应该尽可能伪装成浏览器而不被识别出来是爬虫,基本的是加请求头,但是这样的纯文本数据爬取的人会很多,所以我们需要考虑更换代理IP和随机更换请求头的方式来对旅游景点信息数据进行爬取。
在每次进行爬虫代码的编写之前,我们的第一步也是最重要的一步就是分析我们的网页。
通过分析我们发现在爬取过程中速度比较慢,所以我们还可以通过禁用谷歌浏览器图片、JavaScript等方式提升爬虫爬取速度。
开发工具
Python版本: 3.6
相关模块:
requests模块
parsel模块
time模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
文中完整代码及文件,评论留言获取
数据来源查询分析
浏览器中打开我们要爬取的页面
按F12进入开发者工具,查看我们想要的旅游景点信息数据在哪里
这里我们需要页面数据就可以了

代码实现
for page in range(1, 12):
# '{}'.format(page) 字符串格式化的方法
print(f'===============================正在爬取第{page}页数据内容=======================================')
time.sleep(2)
url = f'https://piao.qunar.com/ticket/list_%E6%B9%98%E8%A5%BF.html?from=mps_search_suggest_h&keyword=%E6%B9%98%E8%A5%BF&page={page}'
# 请求头:把python代码伪装成浏览器 给服务器发送请求
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Cookie': '你的Cookie'
}
response = requests.get(url=url, headers=headers)
# 获取网页文本数据 response.text
# print(response.text)
# 解析数据
selector = parsel.Selector(response.text)
# css选择器 根据标签提取数据内容
# 第一次提取 所以景区标签内容 返回的页是一个对象 列表
# id选择器 直接可以使用# 开头
lis = selector.css('#search-list .sight_item_detail')
for li in lis:
title = li.css('.name::text').get() # 景区
level = li.css('.level::text').get() # 星级
area = li.css('.area a::text').get() # 地区
# attr属性选择器 replace() 字符串替换
hot = li.css('.product_star_level em::attr(title)').get().replace('热度: ', '') # 热度
hot = int(float(hot)*100)
address = li.css('.address span::attr(title)').get() # 地址
price = li.css('.sight_item_price em::text').get() # 价格
hot_num = li.css('.hot_num::text').get() # 销量
intro = li.css('.intro::text').get() # 简介
href = li.css('.name::attr(href)').get() # 详情页
href = 'https://piao.qunar.com/' + href
dit = {
'景区': title,
'星级': level,
'地区': area,
'热度': hot,
'销量': hot_num,
'地址': address,
'价格': price,
'简介': intro,
'详情页': href,
}
Cookie获取

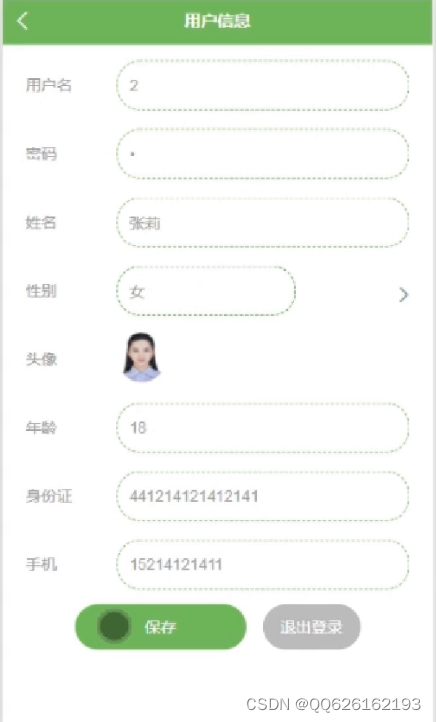
效果展示

最后
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
里面有适合小白新手的实战教程给到大家~
快来和小鱼一起成长进步吧!
① 100+多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库(最全中文版)
③ 爬虫项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)

![[GYCTF2020]Easyphp](https://img-blog.csdnimg.cn/1c70c7eb42664e8183b89c16ffc31e7f.png)

![[附源码]Python计算机毕业设计高校教材管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/dfa18268da2e45c0be536d5d06705787.png)