文章目录
- 4、多层感知机( MLP)
- 4.1、多层感知机
- 4.1.1、隐层
- 4.1.2、激活函数 σ
- 4.2、从零实现多层感知机
- 4.3、简单实现多层感知机
- 4.4、模型选择、欠拟合、过拟合
- 4.5、权重衰退
- 4.6、丢失法|暂退法(Dropout)
- 4.6.1、dropout 函数实现
- 4.6.2、简洁实现
- 4.7、数值稳定性
4、多层感知机( MLP)
4.1、多层感知机
加入一个或多个隐藏层+激活函数来克服线性模型的限制, 使其能处理更普遍的函数关系类型,这种架构通常称为多层感知机(multilayer perceptron)。
输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。

4.1.1、隐层
通用近似定理
多层感知机可以通过隐藏神经元,捕捉到输入之间复杂的相互作用, 这些神经元依赖于每个输入的值。多层感知机是通用近似器, 即使是网络只有一个隐藏层,给定足够的神经元和正确的权重, 可以对任意函数建模。
通过使用更深(而不是更广)的网络,可以更容易地逼近许多函数。
4.1.2、激活函数 σ
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活,换句话说,激活函数的目的是引入非线性变化。
常见激活函数
ReLU 是绝大多数情况的选择。原因是它计算简单,不用跑指数运算,CPU跑指数运算是很费时间的,GPU会好一些。
1)ReLU
R e L U ( x ) = m a x ( x , 0 ) ReLU(x) = max(x,0) ReLU(x)=max(x,0)
使用 ReLU 的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题目前还不理解,为什么这样优化表现更好?
2)Sigmoid
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1
它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值。
3)tanh
t a n h ( x ) = 1 − e − 2 x 1 + e − 2 x tanh(x) = \frac{1-e^{-2x}}{1+e^{-2x}} tanh(x)=1+e−2x1−e−2x
将其输入压缩转换到区间(-1, 1)上。
为什么要引入非线性变换?
非线性变换比线性变换有更强的表达能力。可逼近任意复杂函数,更加贴合真实世界问题,现实世界中单调、线性是极少存在的。
例如,如果我们试图预测一个人是否会偿还贷款。 我们可以认为,在其他条件不变的情况下, 收入较高的申请人比收入较低的申请人更有可能偿还贷款。 但是,虽然收入与还款概率存在单调性,但它们不是线性相关的。 收入从0增加到5万,可能比从100万增加到105万带来更大的还款可能性。 处理这一问题的一种方法是对我们的数据进行预处理, 使线性变得更合理,如使用收入的对数作为我们的特征。(该例来自 DIVE INTO DEEP LEARNING)
softmax 函数与隐层激活函数的区别?
softmax 函数主要用于输出层,而不是隐藏层。隐藏层的激活函数通常是为了引入非线性,而 softmax 函数则是为了将得分映射为概率,用于多分类问题的输出。
什么是层数塌陷?
梯度消失。
4.2、从零实现多层感知机
(损失函数、优化算法 来自 torch)
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
#生成了一个服从标准正态分布(均值为0,方差为1)的随机张量 大小(num_inputs, num_hiddens),作为 w 初始值。
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
# 大小为(num_hiddens,)的零张量 ,作为 b 的初始值
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
权重为什么要乘 0.01?
乘以0.01的目的是将初始权重缩放到一个较小的范围,以便更好地初始化网络。
激活函数
def relu(X):
# 创建了一个与输入张量X具有相同形状的全零张量a
a = torch.zeros_like(X)
return torch.max(X, a)
定义模型
def net(X):
# -1 表示该维度将根据张量的大小自动计算, 如:784, reshape(-1,28) 会得到28*28
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
损失函数
# reduction='none':表示不进行降维,张量的形状通常与输入的标签张量的形状相同。
loss = nn.CrossEntropyLoss(reduction='none')
训练 & 优化算法
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
评估
d2l.predict_ch3(net, test_iter)
4.3、简单实现多层感知机
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
4.4、模型选择、欠拟合、过拟合
模型选择
DL 的核心是,设计一个大的模型,控制它的容量,尽可能地降低泛化误差。
泛化误差(test_loss):模型在新数据上的误差。
训练误差(train_loss):模型在训练数据上的误差,反映了模型在训练数据上的拟合程度。
模型训练过程中用到的损失是 train_loss 。
测试集:只用一次的数据集【如竞赛提交后才进行测试的无法用于调超参数的不可知数据】。
验证集:用来评估模型好坏的数据集,根据结果调整超参数。
小数据集上做验证,通常使用K-则交叉验证,常用k=5或10。
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=42)这种分割之后,哪里涉及到验证损失?绘制出来的 test_loss 算测试损失还是验证损失?沐神提到过,数据集分割中的X_test,y_text 是当作测试集实际上是验证集(val),不代表模型在新数据上真实泛化能力。
对上方红字,我的理解:数据集分割的test,在使用时确实是当测试集对待的,对代码来说他就是测试集,但是在代码之外,往往会根据这个结果人为地去调整下学习率、隐层节点之类的超参数,那么就更加贴合验证集的定义,是实际中的验证集。
所以翻阅书籍看到 test 就应该啊理解为测试集,不要钻牛角尖说事实上我压根就没有测试集,到我手上了的都成为验证集了,因为我后续会调参,薛定谔的猫。所以书籍教程上谈 test为测试集,没有任何问题(一直纠结很久,所以记录一下)。
超参数:训练前预定义好的,训练中不会变,(lr、epoch、batchsize、正则化参数、隐层节点数)。
参数:权重w、偏移量b之类的。
过拟合&欠拟合
-
低容量配简单数据时,高容量模型配复杂数据时,拟合正常。
-
高容量模型数据少,容易过拟合;低容量模型数据复杂,易欠拟合。
模型容量
拟合各种函数的能力,高容量的模型可以记住所有训练数据。
如何估计模型容量?
- 参数个数
- 参数值的选择范围
VC维(Wapnik-Chervonenkis dimension)是统计学提供的量化模型容量的方法,提供一个为什么一个模型好的理论依据。在DL中使用VC维很困难。

(图片来自 《DIVE INTO DEEP LEARNING》)
数据复杂度
样本数、没样本元素数、时空结构、多样性。
更多的,模型容量和数据复杂度是直观感受,不断积累调参得来的感受。
4.5、权重衰退
权重衰减是最广泛使用的正则化的技术之一, 它通常也被称为 L 2 正则化 L_2正则化 L2正则化。
正则化是处理过拟合常用方法,在训练集损失函数中加入惩罚项,以降低模型复杂度。保持模型简单的一个特别的选择是使用 L 2 惩罚 L_2惩罚 L2惩罚的权重衰减。
常见的正则化方法:
- L1 正则化(L1 Regularization):在损失函数中添加参数的绝对值之和,即 L1 范数。这将导致一些参数变为零,从而实现特征选择的效果,使得模型更稀疏。
- L2 正则化(L2 Regularization):在损失函数中添加参数的平方和的一半,即 L2 范数。这会使模型的参数更加平滑,防止参数过大,从而减轻过拟合。
- Elastic Net 正则化:结合了 L1 和 L2 正则化,同时对参数施加 L1 和 L2 惩罚项。
- Dropout 正则化:在训练过程中,随机地将一些神经元的输出设置为零,以降低神经网络的复杂性。
- 数据增强(Data Augmentation):通过对训练数据进行一系列随机变换(如翻转、旋转、缩放等),增加数据样本,从而提高模型的泛化能力。
参数更新法则
计算梯度
∂ ∂ w ( L ( w , b ) + λ 2 ∣ ∣ w ∣ ∣ 2 ) = ∂ L ( w , b ) ∂ w + λ w \frac{∂}{∂w}(L(w,b) + \frac{λ}{2}||w||^2) = \frac{∂L(w,b)}{∂w} + \lambda w ∂w∂(L(w,b)+2λ∣∣w∣∣2)=∂w∂L(w,b)+λw
更新参数(时间t)
w t + 1 = ( 1 − η λ ) w t − η ∂ L ( w , b ) ∂ w wt+1 =(1-ηλ)wt - η\frac{∂L(w,b)}{∂w} wt+1=(1−ηλ)wt−η∂w∂L(w,b)
通常 η λ < 1 η\lambda < 1 ηλ<1,深度学习中这个就叫做权重衰减。
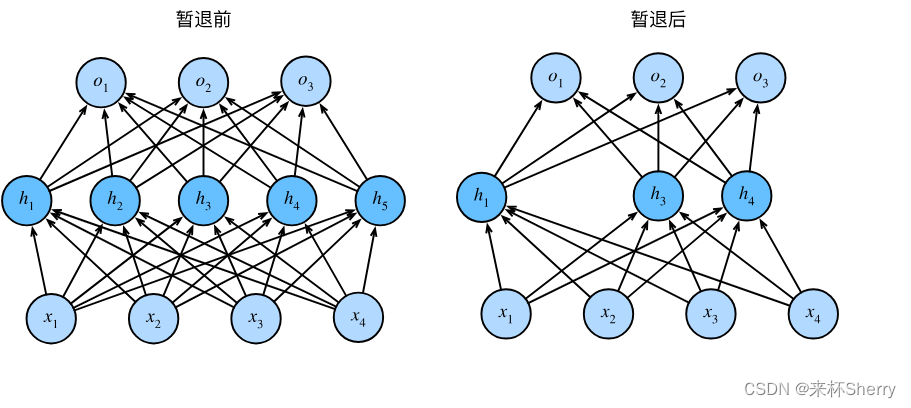
4.6、丢失法|暂退法(Dropout)
Dropout 是一种常用的正则化技术,正则技术就是用于防止神经网络过拟合。
丢弃法将一些输出项随机置0来控制模型复杂度,常作用在多层感知机的隐藏层输出上,丢弃概率是控制模型复杂度的超参数。
常用 dropout rate = 0.5 or 0.9 or 0.1
无偏差的加入噪音
对 x x x加入噪音得到 x ′ x' x′,我们希望
E [ x ′ ] = x E[x'] = x E[x′]=x
丢弃法对每个元素进行如下扰动
x i ′ = { 0 with probability p x i 1 − p otherise x_i' = \begin{cases} 0& \text{with probability p} \\ \frac{x_i}{1-p} &\text{otherise} \end{cases} xi′={01−pxiwith probability potherise
怎么能看出"加噪音"这个动作,这不是"丢弃"动作吗?
理论上 dropout 是在做一个隐层之间加噪音的操作,实际上是通过上述 x x x转 x ′ x' x′实现的。
丢弃法的实际使用
通常将丢弃法作用于隐层的输出上。
[hidden layers]
↓
[dropout layer]
↓
[output layer]
h = σ ( W 1 x + b 1 ) h = σ(W_1x + b_1) h=σ(W1x+b1)
h ′ = d r o p o u t ( h ) h' = dropout(h) h′=dropout(h)
o = W 2 h ′ + b 2 o = W_2h' + b_2 o=W2h′+b2
y = s o f t m a x ( o ) y = softmax(o) y=softmax(o)
(图片来自 《DIVE INTO DEEP LEARNING》)
4.6.1、dropout 函数实现
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X,dropout):
#dropout只有在合理范围内,断言允许继续执行
assert 0 <= dropout <= 1
# dropout =1 分母无意义
if dropout ==1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout ).float()
return mask * X / (1.0 - dropout)
4.6.2、简洁实现
在每个全连接层之后添加一个Dropout层
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
训练和测试
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
4.7、数值稳定性
参数初始化重要性:影响梯度和参数本身的稳定性
梯度计算的是矩阵与梯度向量的乘积,最初矩阵可能具有各种各样的特征值,他们的乘积可能非常大也可能非常小。
不稳定梯度带来的风险不止在于数值表示; 不稳定梯度也威胁到我们优化算法的稳定性。 梯度爆炸,参数更新过大,破坏模型稳定收敛;梯度消失,参数更新过小,模型无法学习。
当网络有很多层时,sigmoid函数的输入很大或是很小时,它的梯度都会消失,激活函数会选择更稳定的ReLU系列函数。
参数对称性
神经网络设计中的另一个问题是其参数化所固有的对称性。 假设我们有一个简单的多层感知机,它有一个隐藏层和两个隐藏单元。 在这种情况下,我们可以对第一层的权重 W ( 1 ) W^{(1)} W(1)进行重排列, 并且同样对输出层的权重进行重排列,可以获得相同的函数。 第一个隐藏单元与第二个隐藏单元没有什么特别的区别。 换句话说,我们在每一层的隐藏单元之间具有排列对称性。
这种对称性意味着在参数化的角度上,我们有多个等效的参数组合可以表示相同的函数。在神经网络训练过程中,可能会出现参数收敛到其中一个等效组合上,而忽略了其他等效组合。这可能导致训练过程不稳定或收敛较慢。
小批量随机梯度下降不会打破这种对称性,但暂退法正则化可以。
如何让训练更加稳定?
让梯度值在一个合理的范围。
-
将乘法变加法【ResNet,LSTM】
-
归一化【梯度归一化,梯度裁剪】
-
合理的权重初始和激活函数
-
让每层的方差是一个常数
- 将每层的输出梯度看作随机变量
- 让他们的均值和方差都保持一致

![[保研/考研机试] 括号匹配问题 C++实现](https://img-blog.csdnimg.cn/334a300fd3d04f6f9bee541b7cbeed9f.png)