💓博主个人主页:不是笨小孩👀
⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀
🚚代码仓库:笨小孩的代码库👀
⏩社区:不是笨小孩👀
🌹欢迎大家三连关注,一起学习,一起进步!!💓

复杂链表+OJ
- 链表的分类
- 带头双向循环链表的实现
- 结构
- 接口有哪些呢?
- 初始化
- 打印链表
- 尾插
- 头插
- 尾删
- 头删
- 查找
- 在pos前面插入
- 删除pos位置的数据
- 销毁链表
- 链表和顺序表的区别
- 用随机指针复制列表
链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1.单向or双向
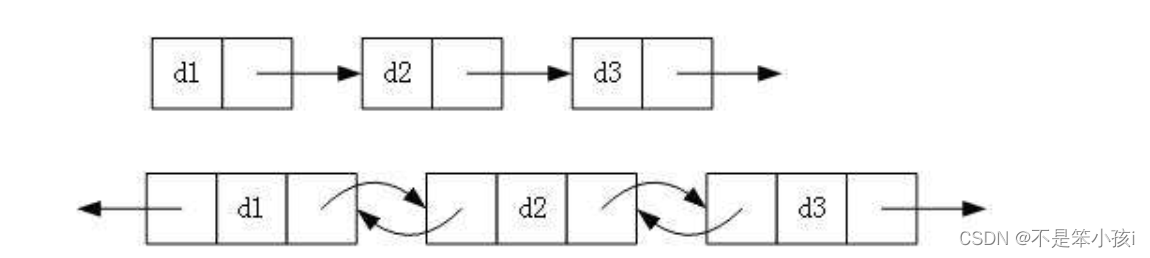
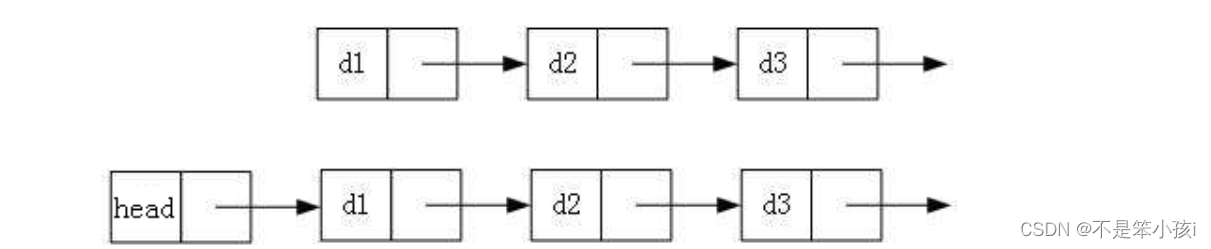
2.带头or不带头(哨兵位头结点)
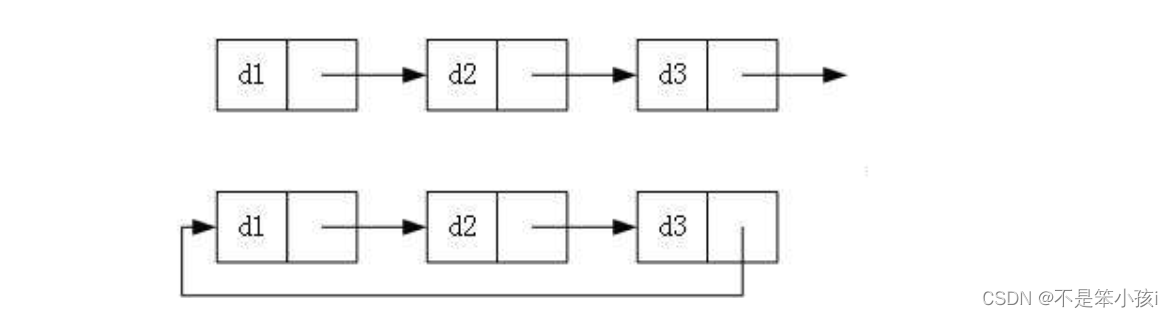
3.循环or不循环
它们组合起来一共有8种结构,虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
1.无头单向非循环链表

这个链表我们前面已经讲过了,想详细了解的可以去看单链表详解。
2.带头双向循环链表

这个是我们本章节的重点,下面细讲。
总结:
1.无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结
构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2.带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都
是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带
来很多优势,实现反而简单了,后面我们代码实现了就知道了。
带头双向循环链表的实现
结构
既然是双向,那么这个结构体种就需要两个指针,一个用来存储下一个节点的指针,一个用来存储上一个节点的指针。
typedef int LTDateType;
typedef struct ListNode
{
//存储数据
LTDateType date;
//保存下一个节点的地址
struct ListNode* next;
//保存上一个节点的地址
struct ListNode* prev;
}ListNode;
接口有哪些呢?
// 创建返回链表的头结点.(初始化)
ListNode* ListCreate();
// 双向链表销毁
void ListDestory(ListNode* pHead);
// 双向链表打印
void ListPrint(ListNode* pHead);
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDateType x);
// 双向链表尾删
void ListPopBack(ListNode* pHead);
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDateType x);
// 双向链表头删
void ListPopFront(ListNode* pHead);
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDateType x);
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDateType x);
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos);
接下来我们来一一实现:
初始化
我们这里讲的是带头双向循环链表,所以我们在初始化的时候由于只有一个哨兵位头结点,所以我们直接让他的next和prev先指向自己,里面的数据可以是任何数。
// 创建返回链表的头结点.
ListNode* ListCreate()
{
ListNode* node = (ListNode*)malloc(sizeof(ListNode));
//判断是否开辟成功
if (node == NULL)
{
perror("malloc fail");
exit(-1);
}
//初始化
node->next = node;
node->prev = node;
node->date = 0;
return node;
}
打印链表
打印链表很简单只需要遍历链表就可以了,但是这里的头结点是哨兵位不需要遍历,所以我们从phead的next开始,由于他是循环的,所以到phead结束。
// 双向链表打印
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
printf("%d->", cur->date);
cur = cur->next;
}
printf("\n");
}
尾插
由于插入数据我们都需要开辟新的节点,所以我们下一个函数专门来创建节点:
ListNode* BuyListNode(int x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
//节点里面的指针可以初始化为NULL,因为他们暂时无任何指向。
newnode->date = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
有了节点以后,我们可以利用pHead的prev找到尾,并保存在tail中,然后开始改变链接关系,让tail->next指向newnode,newnode->prev指向tail,然后将pHead->prev指向newnode,newnode->next指向pHead。在没有节点的情况下同样使用,这就体现了结构的优势。
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDateType x)
{
assert(pHead);
ListNode* newnode = BuyListNode(x);
ListNode* tail = pHead->prev;
tail->next = newnode;
newnode->next = pHead;
pHead->prev = newnode;
newnode->prev = tail;
}
头插
头插同样需要新的节点,有了新的节点以后,我们保存pHead->next到first中去,然后改变链接关系,将first->prev指向newnode,将newnode->next指向first,将newnode的prev指向pHead,将pHead的next指向newnode。
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDateType x)
{
assert(pHead);
ListNode* newnode = BuyListNode(x);
newnode->prev = pHead;
newnode->next = pHead->next;
pHead->next->prev = newnode;
pHead->next = newnode;
}
尾删
尾删我们可以先保存一下尾节点,在保存尾节点的前一个节点,然后释放尾节点,在改变链接关系,将新的尾节点的next指向pHead,将pHead的prev指向新的尾。
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{
assert(pHead);
//链表为空就别删了
assert(pHead->next != pHead);
//保存尾节点
ListNode* tail = pHead->prev;
//保存尾节点的前一个节点
ListNode* tailPrev = tail->prev;
//释放尾节点
free(tail);
//改变链接关系
tailPrev->next = pHead;
pHead->prev = tailPrev;
}
头删
我们保存第一个节点,也就是pHead->next到first中去,然后改变链接关系,将pHead->next改为first->next,然后将first后面的一个节点的prev,也就是first->next->prev改为pHead,然后释放first即可。
// 双向链表头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(pHead->next != pHead);
ListNode* first = pHead->next;
pHead->next = first->next;
first->next->prev = pHead;
free(first);
}
查找
查找和打印的方法一样遍历链表,找到就返回该节点,找不到返回NULL。
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDateType x)
{
ListNode* cur = pHead->next;
while (cur != pHead)
{
if (cur->date == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
在pos前面插入
我们可以先保存pos前面的的节点到posPrev中去,在开辟一个新的节点,然后改变链接关系,将posPrev->next改为newnode,然后将newnode->prev指向posPrev,然后将newnode->next指向pos,最后将pos->prev指向newnode即可。
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDateType x)
{
assert(pos);
ListNode* posPrev = pos->prev;
ListNode* newnode = BuyListNode(x);
posPrev->next = newnode;
newnode->prev = posPrev;
newnode->next = pos;
pos->prev = newnode;
}
删除pos位置的数据
删除就更简单了,只需要将pos前一个节点的next指向pos的next,将pos的下一个节点的prev指向pos的prev,然后释放pos即可。
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{
assert(pos);
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(pos);
}
销毁链表
遍历链表,依次销毁,最后销毁头即可。
// 双向链表销毁
void ListDestory(ListNode* pHead)
{
ListNode* cur = pHead->next;
while (cur != pHead)
{
ListNode* del = cur;
cur = cur->next;
free(del);
}
free(pHead);
}
双向带头循环链表到这里基本上就讲完了,它的结构复杂,但是代码写起来比起单链表还是非常简单的,接下来我们来比较一下链表和顺序表的区别。
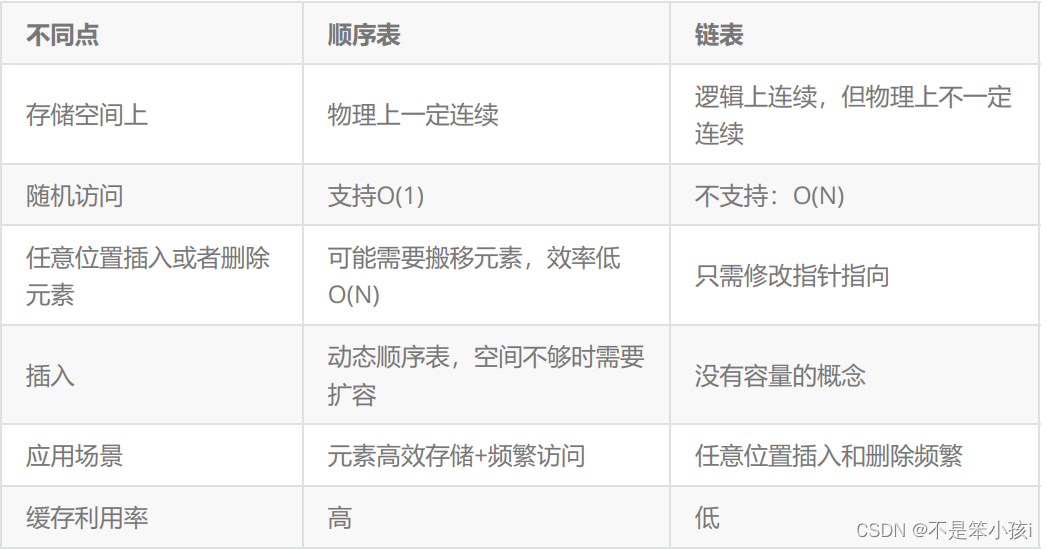
链表和顺序表的区别
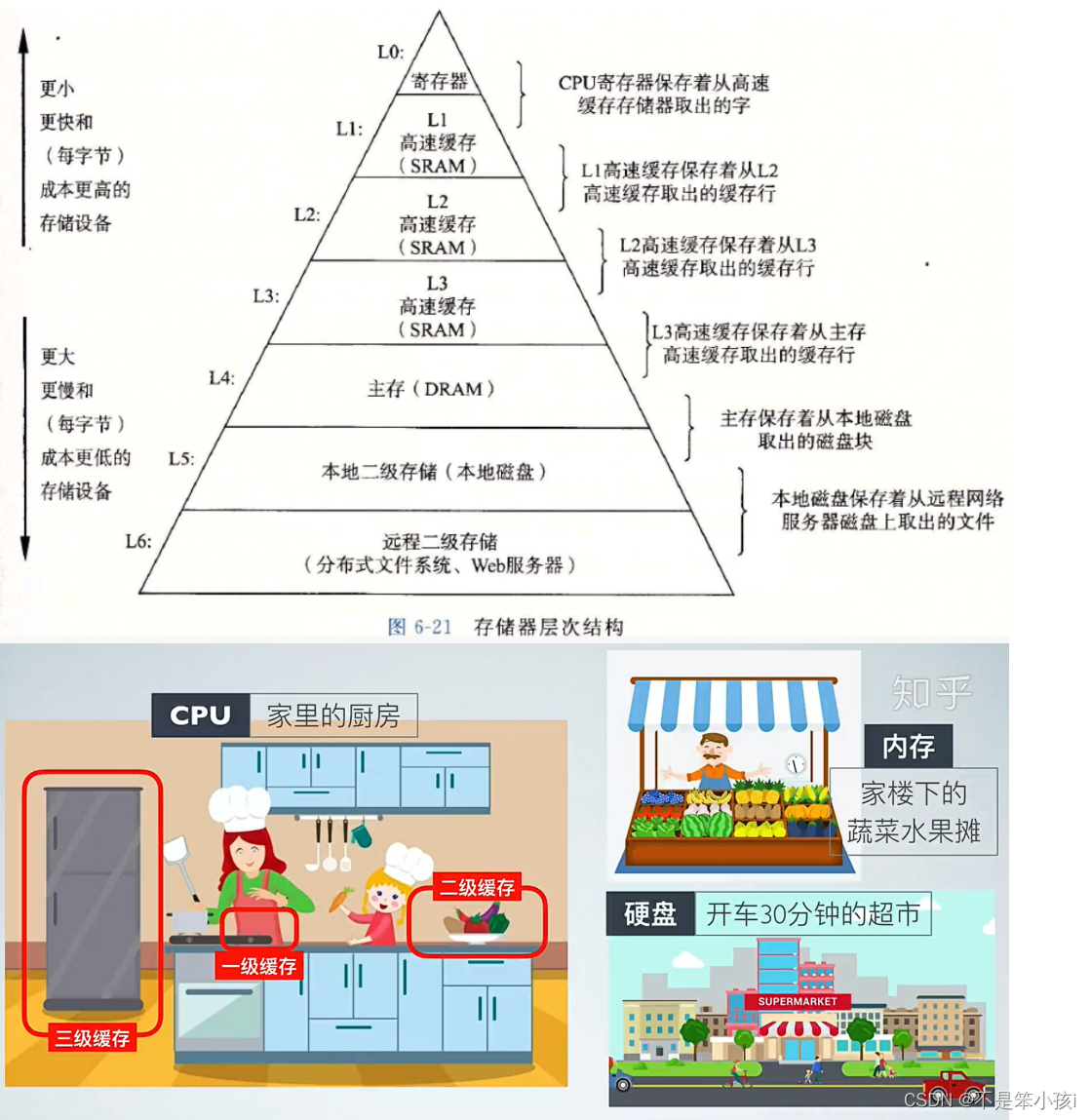
下图是缓存的一些知识:
用随机指针复制列表
如果我们单纯的拷贝一个链表,那非常简单,只需要遍历原链表,在遍历的同时开辟新的节点,存储原链表的值,然后将新的节点尾插起来就可以了。
但是这个题目出除了需要拷贝这个以外,每个结构中还有一个random指针,他们在原链表中指向原链表的任意节点或者空,我们还要拷贝这个,但是问题是我们在新的链表中无法找到原链表中random所对应的新的链表中的地址,所以我们原链表中找random的同时,还有在新的链表中找对应的random,这是比较麻烦的,而且时间复杂度是O(N^2),效率也低。
这里我们还有另外一个方法,就是我们先将每个节点都拷贝一份,放个拷贝的节点放在对应节点的后面,将他们重新链接起来,我们的问题就是找不到random对应的节点的地址,这样我们的节点的next即使random对应节点的地址,然后我们将拷贝的链表摘下来,尾插起来形成新的链表,同时恢复原链表,这样就可以了,这样做时间复杂度是O(N),而且没有额外的空间损耗,是个非常厉害的思路。
第一步:
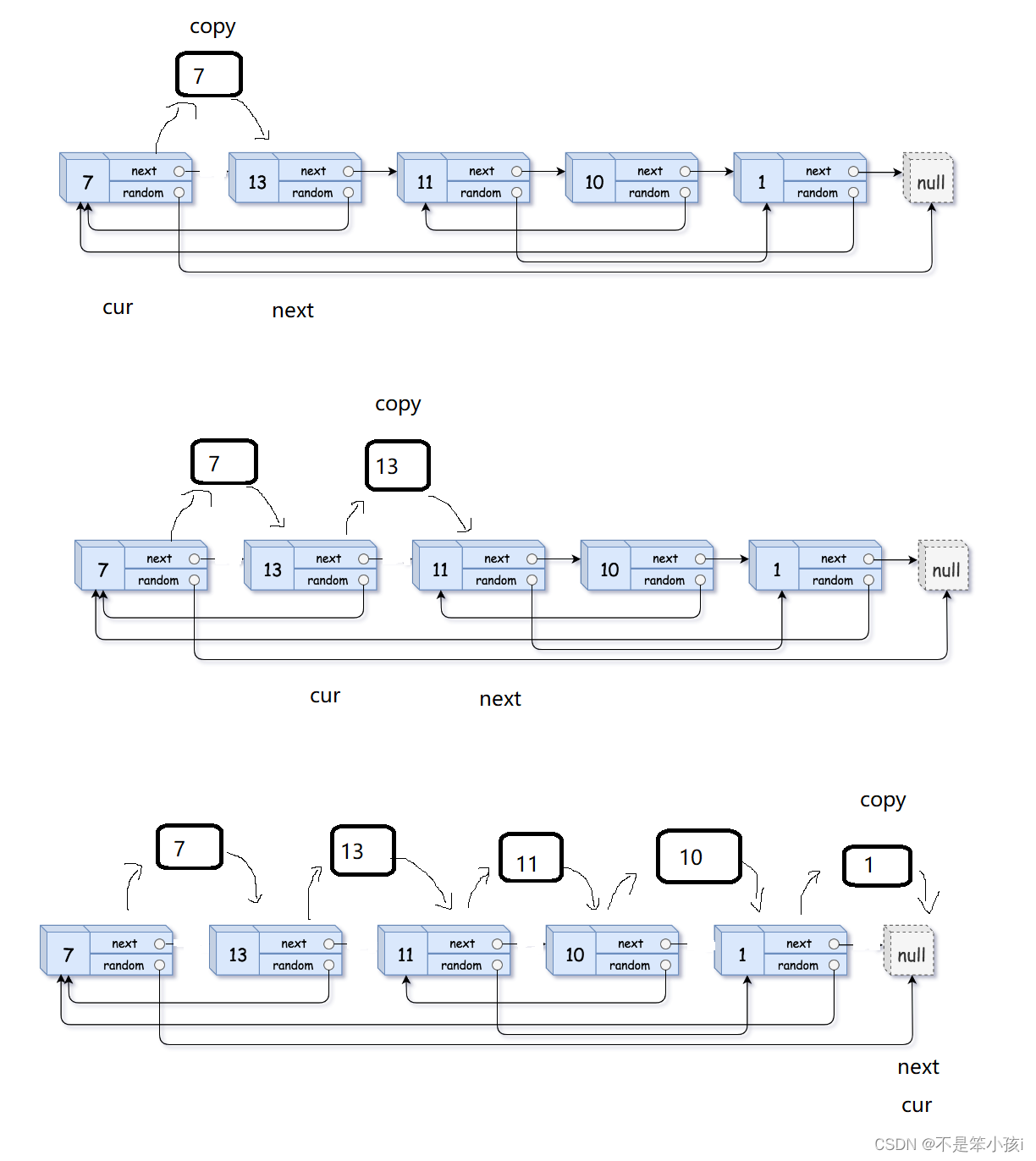
第二步;
改变拷贝链表的random的值,他就是原链表的random的next。
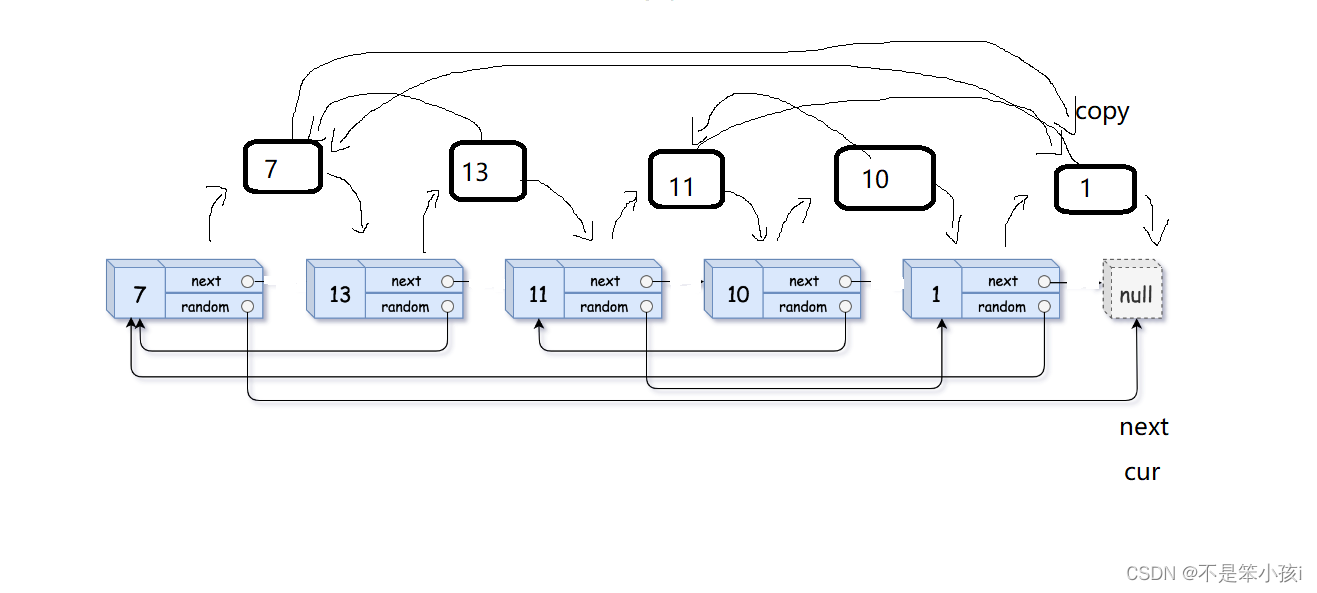
第三步
就是恢复链表,并且将拷贝的拿来尾插成新的链表。
代码如下:
struct Node* copyRandomList(struct Node* head)
{
struct Node* cur = head;
//第一步插入copy
while(cur)
{
struct Node* next = cur->next;
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
//拷贝
copy->val = cur->val;
//改变链接关系
cur->next = copy;
copy->next = next;
//cur迭代
cur = copy->next;
}
cur = head;
//第二步,改变copy的random
while(cur)
{
struct Node* copy = cur->next;
if(cur->random==NULL)
{
copy->random=NULL;
}
else
{
copy->random = cur->random->next;
}
cur = copy->next;
}
//第三步 尾插并且恢复原链表
cur = head;
struct Node* copyhead = NULL,*copytail = NULL;
while(cur)
{
struct Node* copy = cur->next;
struct Node* next = copy->next;
//尾插copy
if(copyhead==NULL)
{
copyhead=copytail=copy;
}
else
{
copytail->next = copy;
copytail = copytail->next;
}
//恢复原链表
cur->next = next;
cur = next;
}
return copyhead;
}
今天的分享就到这里,感谢大家的关注和支持。