数据复制典型的算法就是Paxo和Raft。
1 分片元数据的存储
分布式存储系统中,收到客户端请求后,承担路由功能的节点:
- 先访问分片元数据(简称元数据),确定分片对应节点
- 然后才访问真正数据
元数据,一般包括分片的数据范围、数据量、读写流量和分片副本处于哪些物理节点及副本状态等信息。
存储角度,元数据也是数据,但特别之处在于每个请求都要访问它,所以元数据的存储很容易成为整个系统性能瓶颈和高可靠性短板。如系统支持动态分片,分片要自动地分拆、合并,还会在节点间来回移动。元数据就处在不断变化,又带来了多副本一致性(Consensus)问题。
来看不同产品如何存储元数据。
1.1 静态分片
最简单情况。可忽略元数据变动问题,只要把元数据复制多份放在对应的工作节点,同时兼顾性能和高可靠。TBase大致这思路,直接将元数据存储在协调节点。即使协调节点是工作节点,随着集群规模扩展,会导致元数据副本过多,但由于哈希分片基本上就是静态分片,也就不用考虑多副本一致性的问题。
但若要更新分片信息,这显然不适合,因副本数量过多,数据同步代价太大。所以对于动态分片,通常是不会在有工作负载的节点上存放元数据的。
咋设计?专门给元数据搞小规模集群,用Paxos协议复制数据。保证高可靠,数据同步的成本也较低。
TiDB大致这思路。
1.2 TiDB:无服务状态
TiKV节点:实际存储分片数据的节点
Placement Driver节点:管理元数据。Placement Driver这名称来自Spanner中对应节点角色,简称PD。
PD与TiKV通讯过程中,PD完全被动:
- TiKV节点定期主动向PD报送心跳,分片的元数据信息随心跳一起报送
- PD将分片调度指令放在心跳的返回信息
- 等TiKV下次报送心跳时,PD就能了解到调度执行情况
由于每次TiKV心跳包含全量的分片元数据,PD甚至可不落盘任何分片元数据,完全做成一个无状态服务。好处是PD宕机后选举出的新主不用处理与旧主的状态衔接,在一个心跳周期后就可工作。实现上,PD仍会做部分信息的持久化,可认为是一种缓存。
通讯过程

三个TiKV节点每次上报心跳时,由主副本(Leader)提供该分片的元数据,PD可获得全量且没有冗余的信息。
虽然无状态服务有很大优势,但PD仍是单点,即该方案还是一个中心化的设计思路,可能存在性能问题。
有完全“去中心化”设计?有,来看P2P架构的CockroachDB。
1.3 CockroachDB:去中心化
CockroachDB使用Gossip协议。Paxos协议本质是一种广播机制,由一个中心节点向其他节点发消息。当节点数量较多时,通讯成本高。
CockroachDB采用P2P架构,每个节点都保存完整元数据,这样节点规模就很大,当然也不适用广播机制。而Gossip协议的原理是谣言传播机制,每一次谣言都在几个人的小范围内传播,但最终会成为众人皆知的谣言。这种方式达成的数据一致性是 “最终一致性”,即执行数据更新操作后,经过一定的时间,集群内各个节点所存储的数据最终会达成一致。
分布式数据库是强一致性,现在搞个最终一致性的元数据,行?
CockroachDB真的是基于“最终一致性”的元数据实现了强一致性的分布式数据库。
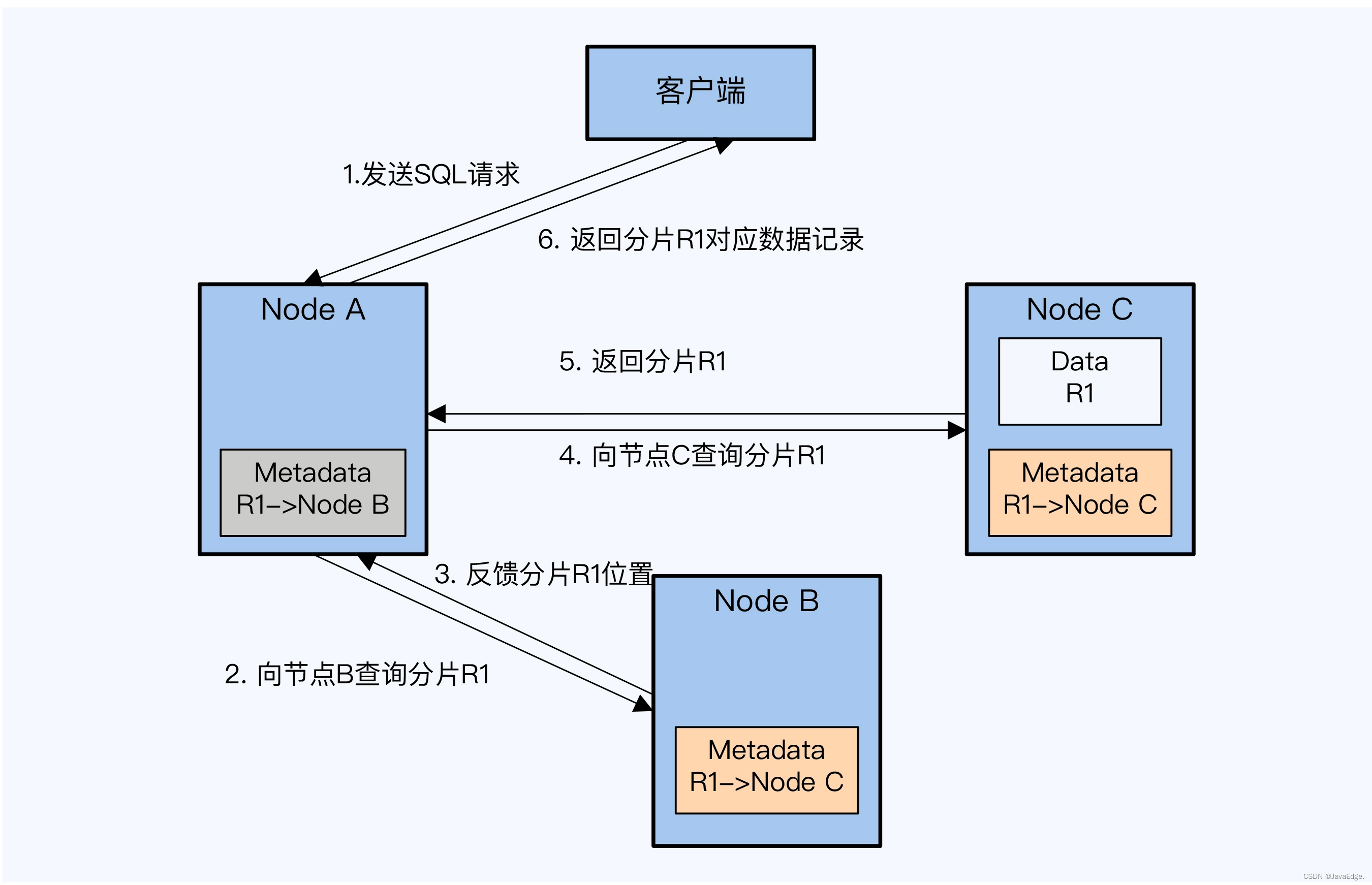
- 节点A接到客户端的SQL请求,要查询数据表T1的记录,根据主键范围确定记录可能在分片R1上,而本地元数据显示R1存储在节点B
- 节点A向节点B发送请求。很不幸,节点A的元数据已过时,R1已重新分配到节点C。
- 此时节点B会回复给节点A重要信息,R1存储在节点C
- 节点A得到该信息后,向节点C再次发起查询请求,这次运气好,R1确实在节点C
- 节点A收到节点C返回的R1。
- 节点A向客户端返回R1上的记录,同时会更新本地元数据。
CockroachDB在寻址过程中会不断地更新分片元数据,促成各节点元数据达成一致。
1.4 小结
复制协议的选择和数据副本数量有很大关系:
- 副本少,参与节点少,可以采用广播方式,也就是Paxos、Raft等协议
- 副本多,节点多,那就更适合采用Gossip协议
2 复制效率
就是Raft与Paxos效率差异及Raft优化。
分布式数据库采用Paxos协议较少,知名产品仅OceanBase,所以下面差异分析基于Raft。
2.1 Raft的性能缺陷
比较Paxos和Raft的文章,都提到复制效率Raft稍差,主要是Raft须“顺序投票”,不允许日志出现空洞。顺序投票确实影响Raft算法复制效率的关键因素。
为啥“顺序投票”对性能这么大影响?
2.2 Raft日志复制过程
- Leader 收到客户端的请求
- Leader 将请求内容(即Log Entry)追加(Append)到本地的Log
- Leader 将Log Entry 发送给其他的 Follower
- Leader 等待 Follower 的结果,如果大多数节点提交了这个 Log,那么这个Log Entry就是Committed Entry,Leader就可以将它应用(Apply)到本地的状态机。
- Leader 返回客户端提交成功。
- Leader 继续处理下一次请求。
以上是单个事务的运行情况。多事务并行操作时,又啥样?
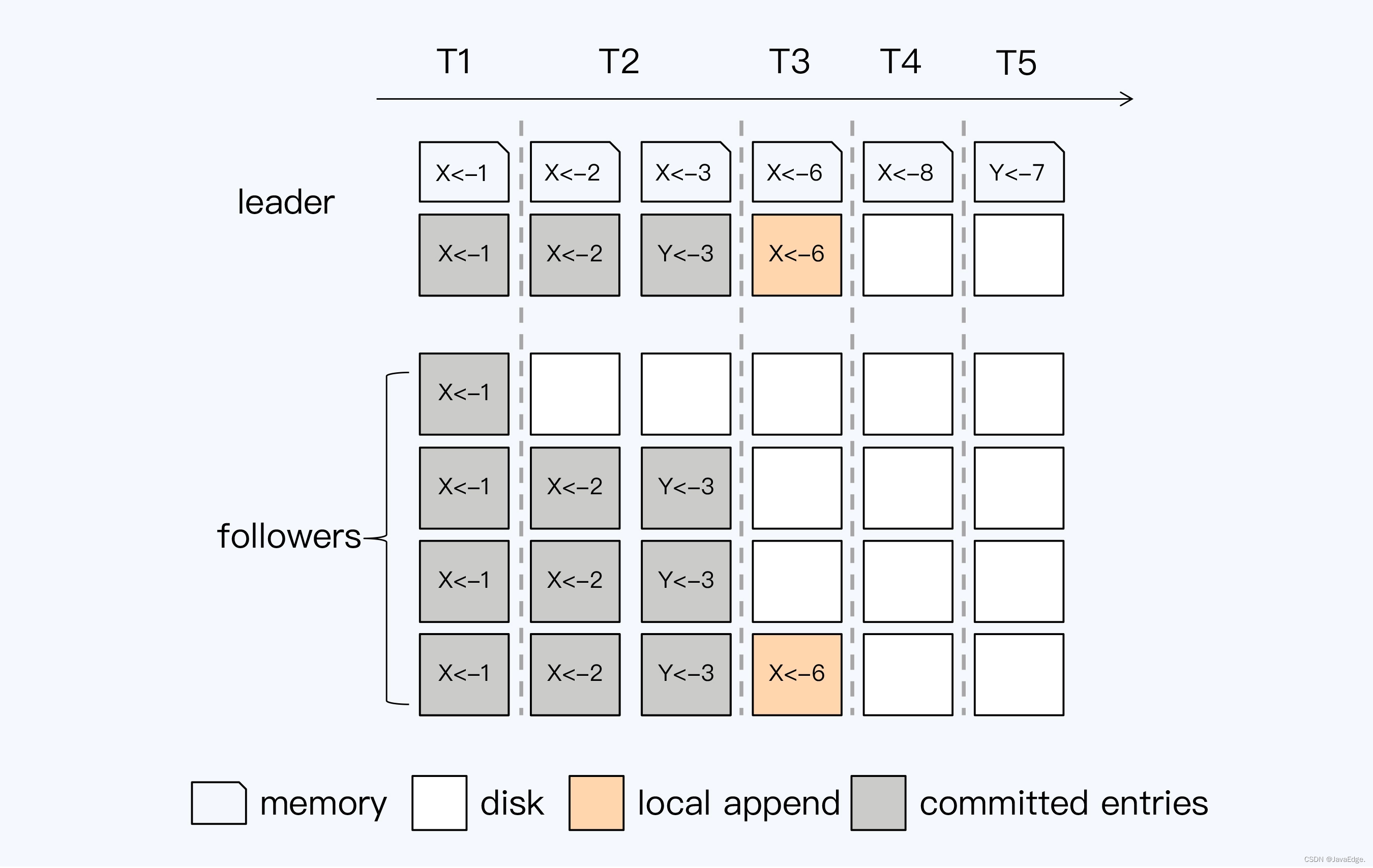
设定这Raft组由5个节点组成,T1到T5是先后发生的5个事务操作,被发送到这个Raft组。
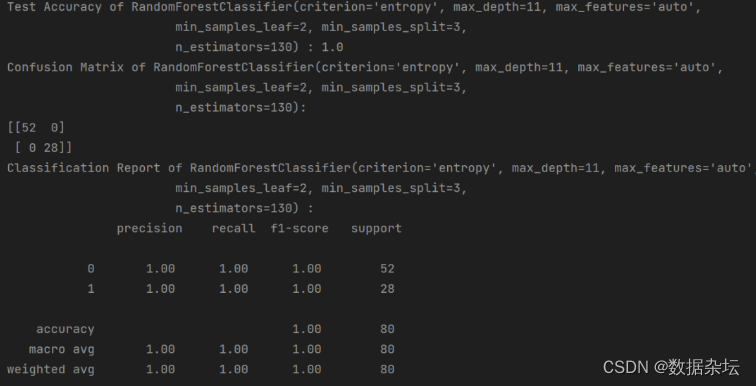
事务T1的操作是将X置为1,5个节点都Append成功,Leader节点Apply到本地状态机,并返回客户端提交成功。事务T2执行时,虽然有一个Follower没有响应,但仍然得到了大多数节点的成功响应,所以也返回客户端提交成功。
现在,轮到T3事务执行,没有得到超过半数的响应,这时Leader必须等待一个明确的失败信号,比如通讯超时,才能结束这次操作。因为有顺序投票的规则,T3会阻塞后续事务的进行。T4事务被阻塞是合理的,因为它和T3操作的是同一个数据项,但是T5要操作的数据项与T3无关,也被阻塞,显然这不是最优的并发控制策略。
同样的情况也会发生在Follower节点上,第一个Follower节点可能由于网络原因没有收到T2事务的日志,即使它先收到T3的日志,也不会执行Append操作,因为这样会使日志出现空洞。
Raft顺序投票是一种设计权衡,虽性能有些影响,但节点间日志比对简单。在两个节点,只要找到一条日志一致,那在这条日志之前的所有日志就都一致。这使得选举出的Leader与Follower同步数据非常便捷,开放Follower读操作也更加容易。保证一致性的Follower读操作,它可有效分流读操作的访问压力。
2.3 Raft的性能优化方法(TiDB)
实现中,Raft主副本也不是傻傻挨个处理请求,有优化。
- **批操作(Batch)。**Leader 缓存多个客户端请求,然后将这一批日志批量发送给 Follower。Batch的好处是减少的通讯成本
- **流水线(Pipeline)。**Leader本地增加一个变量(称为NextIndex),每次发送一个Batch后,更新NextIndex记录下一个Batch的位置,然后不等待Follower返回,马上发送下一个Batch。如果网络出现问题,Leader重新调整NextIndex,再次发送Batch。当然,这个优化策略的前提是网络基本稳定
- **并行追加日志(Append Log Parallelly)。**Leader将Batch发送给Follower的同时,并发执行本地的Append操作。因为Append是磁盘操作,开销相对较大,而标准流程中Follower与Leader的Append是先后执行的,当然耗时更长。改为并行就可以减少部分开销。当然,这时Committed Entry的判断规则也要调整。在并行操作下,即使Leader没有Append成功,只要有半数以上的Follower节点Append成功,那就依然可以视为一个Committed Entry,Entry可以被Apply
- **异步应用日志(Asynchronous Apply)。**Apply并不是提交成功的必要条件,任何处于Committed状态的Log Entry都确保是不会丢失的。Apply仅仅是为了保证状态能够在下次被正确地读取到,但多数情况下,提交的数据不会马上就被读取。因此,Apply是可以转为异步执行的,同时读操作配合改造
CockroachDB和一些Raft库也做类似优化。如SOFA-JRaft也实现Batch和Pipeline优化。
etcd,最早的、生产级Raft协议开源实现,TiDB和CockroachDB都借鉴其设计。它们选择Raft就是因为etcd提供可靠的工程实现,而Paxos则没同样可靠的工程实现。既然是开源,为啥不直接用?因为etcd是单Raft组,写性能受限。所以,TiDB和CockroachDB都改造成多Raft组,Multi Raft,所有采用Raft协议的分布式数据库都是Multi Raft。这种设计,可让多组并行,一定程度规避Raft性能缺陷。
Raft组的大小,即分片大小,越小的分片,事务阻塞概率越低。TiDB默认分片96M,CockroachDB分片不超过512M。TiDB分片更小,就是更好的设计?未必,分片过小又增加扫描操作的成本,这也是一大权衡点。
3 总结
- 分片元数据的存储是分布式数据库的关键设计,要满足性能和高可靠两方面的要求。静态分片相对简单,可以直接通过多副本分散部署的方式实现。
- 动态分片,满足高可靠的同时还要考虑元数据的多副本一致性,必须选择合适的复制协议。如果搭建独立的、小规模元数据集群,则可以使用Paxos或Raft等协议,传播特点是广播。如果元数据存在工作节点上,数量较多则可以考虑Gossip协议,传播特点是谣言传播。虽然Gossip是最终一致性,但通过一些寻址过程中的巧妙设计,也可以满足分布式数据的强一致性要求。
- Paxos和Raft是广泛使用的复制协议,也称为共识算法,都是通过投票方式动态选主,可以保证高可靠和多副本的一致性。Raft算法有“顺序投票”的约束,可能出现不必要的阻塞,带来额外的损耗,性能略差于Paxos。但是,etcd提供了优秀的工程实现,促进了Raft更广泛的使用,而etcd的出现又有Raft算法易于理解的内因。
- 分布式数据库产品都对Raft做了一定的优化,另外采用Multi Raft设计实现多组并行,再通过控制分片大小,降低事务阻塞概率,提升整体性能。
讲了这么多,回到我们最开始的问题,为什么有时候Paxos不是最佳选择呢?一是架构设计方面的原因,看参与复制的节点规模,规模太大就不适合采用Paxos,同样也不适用其他的共识算法。二是工程实现方面的原因,在适用共识算法的场景下,选择Raft还是Paxos呢?因为Paxos没有一个高质量的开源实现,而Raft则有etcd这个不错的工程实现,所以Raft得到了更广泛的使用。这里的深层原因还是Paxos算法本身过于复杂,直到现在,实现Raft协议的开源项目也要比Paoxs更多、更稳定。
有关分片元数据的存储,在我看来,TiDB和CockroachDB的处理方式都很优雅,但是TiDB的方案仍然建立在PD这个中心点上,对集群的整体扩展性,对于主副本跨机房、跨地域部署,有一定的局限性。
关于Raft的优化方法,大的思路就是并行和异步化,其实这也是整个分布式系统中常常采用的方法,在第10讲原子协议的优化中我们还会看到类似的案例。
4 FAQ
最后是今天的思考题时间。我们在第1讲就提到过分布式数据库具备海量存储能力,那么你猜,这个海量有上限吗?或者说,你觉得分布式数据库的存储容量会受到哪些因素的制约呢?欢迎你在评论区留言和我一起讨论,我会在答疑篇回复这个问题。
你是不是也经常听到身边的朋友讨论数据复制的相关问题呢,而且得出的结论有可能是错的?如果有的话,希望你能把今天这一讲分享给他/她,我们一起来正确地理解分布式数据库的数据复制是怎么一回事。
分布式数据库的瓶颈可能在:
- 元数据,元数据过多,可能需多层查找,才能找到数据的节点
- 心跳包,如果网络中太多节点,那么心跳包也会占用相当多带宽,影响IO性能
我觉得容量上限主要受制于业务场景,为了提高性能需要增加分片,但是分片多了以后,为了达到一致性的要求,节点太多影响通讯和数据复制的成本,这两个方面权衡一下就决定了容量的上限?
这个思路非常赞,集群规模增大对于局部业务来说,可能是不受影响,因为局部业务的分片和节点说可能并未增多。但是元数据是所有业务都会访问的,就会收到规模增大的影响。
一个Raft Group存储一个Region的多副本。例如TiDB默认副本数是3,那么一个Raft Group就是3个副本。同时一个节点可能有上千个Region(一般这些Region都不互为副本),每一个Region都属于一个Raft Group,那么也就是说这个节点可能参与上千个Raft Group。每个Raft Group又会选举出一个节点作为Raft Leader,负责写入数据。
基本正确,我再提示一下。Region之间的数据是不同的,所以任何情况下Region间都没有主副本关系。
文章中对比了Gossip和Raft/Paxos这种算法,能说明一下如果Gossip共识时间更短,为什么TiDB等数据库不选择呢?为什么它更适合多节点?是因为它把网络I/O分散到多个节点上吗?可是这也带来了一定的串行性呀!
BTW, Gossip达成共识要比Raft和Paxos要快么?
Gossip达成共识不比Raft更快,CRDB选择它,因为它不是广播机制。而节点规模很大是广播机制的通讯成本太高。TiDB和其他数据库的元数据节点规模很小,所以适用Raft
如果分片信息由单节点管理的话这个分布式数据库是会有瓶颈的,但不是存储瓶颈(像bigtable那样,就像个多级页表一样,最大存储2^61字节数据),是访问瓶颈(当然是不是还需要测试),但也就是因为访问瓶颈就可能导致数据存储是有上限的,但是如果像spanner一样,把每个分布式数据库看做一个spannerserver,再建立一层,就像zone去管理spannerserver,然后再有一层去管理zone,这样貌似就可以无限扩展了,当然说着简单,做起来就太难了。还有对于无主架构中gossip传播集群分片信息,就像redis cluster一样,我觉得瓶颈在于每台机器要存储全部的分片信息,当机器多了以后单机光存储这个就是一个巨大的开销,这也是一个限制的因素吧。
CockroachDB是如何判断R1分片的元数据过期的呢?全局时间戳吗?
全局时间戳貌似解决不了这个问题,R1过期是因为与实际数据存储不符,而原来承载R1的节点会记录R1的去向,可以再次路由
hbase 的 root 表位置放到zk上,root 表找到meta表, 再找到region表,这种方式好像和老师说的不同哦。 hbase不是分布式数据库,所以可以不一样的实现?
zk也是一个保证数据高可靠存储的小集群,和etcd一个道理。