IFCNN: A general image fusion framework based on convolutional neural network
(IFCNN: 基于卷积神经网络的通用图像融合框架)
在本文中,我们提出了一种基于卷积神经网络的通用图像融合框架,称为IFCNN。**受变换域图像融合算法的启发,**我们首先利用两个卷积层从多个输入图像中提取显着的图像特征。之后,通过适当的融合规则 (elementwise-max,elementwise-min或elementwise-mean) 融合多个输入图像的卷积特征,该融合规则是根据输入图像的类型选择的。最后,通过两个卷积层重建融合的特征,以生成信息丰富的融合图像。所提出的模型是完全卷积的,因此可以以端到端的方式进行训练,而无需任何后处理程序。为了充分训练模型,我们基于大规模rgb-d数据集 (即NYU-D2) 生成了一个大规模多焦点图像数据集,它拥有ground truth融合图像,并且比现有的图像融合数据集包含更多种类和更大的图像。 实验结果表明,在没有对其他类型图像数据集进行微调的情况下,该模型比现有的图像融合模型具有更好的泛化能力,可以融合多种类型的图像,例如多焦点,红外视觉,多模态医学和多曝光图像。
介绍
通常,传统图像融合算法可以分为两类,即空间域算法和变换域算法。
空间域图像融合算法首先将输入图像按照一定的标准解析成小块或区域,然后测量相应区域的显著性,最后结合最显著的区域形成融合图像。这种算法主要适用于融合相同模态的图像 (例如多焦点图像),并且可能在拼接位置周围遭受块或区域伪影。
变换域图像融合算法首先通过多尺度几何分解 (例如多尺度金字塔和多尺度形态算子) 将源图像转换为某些特征域,然后对多个输入图像的特征进行加权融合。之后,对融合的特征进行反变换以生成融合图像。由于在特征域中,即使是不同模态的图像也具有相似的特性,因此变换域图像融合算法通常可以用于融合更多类型的图像, 例如红外视觉图像和CT-MR图像。但是变换域算法的融合策略或权重系数往往难以针对融合的目的进行优化,从而可能无法达到最佳的融合效果,并遭受低对比度效应或模糊效应的影响。
机器学习的方法:
Yang等人 采用稀疏表示技术融合多焦点图像,其中用过完备的字典和相应的稀疏系数表示图像补丁,然后通过融合每对或每组图像补丁的稀疏系数对输入图像进行融合。
深度学习的方法
最近,深度学习技术,尤其是卷积神经网络 (CNN),为图像融合领域带来了新的发展。首先,刘等人介绍了CNN融合多焦点图像。他们制定了多焦点图像融合作为分类任务,并使用CNN来预测焦点图,因为每对图像补丁可以分为两类 😦 1) 第一个补丁被聚焦,第二个被模糊; (2) 第一个补丁被模糊,第二个被聚焦。Tang等人提出了一个CNN模型来学习有效的焦点度量 (即量化图像或图像斑块的锐度的度量),然后比较输入图像的局部图像斑块对的焦点度量,以确定焦点图。上述两种算法都对焦点图进行了后处理,并根据细化的焦点图重建了融合图像。Song等人。应用了两个CNN来融合卫星图像,即大分辨率MODIS和低分辨率landsat图像。具体来说,他们分别使用两个CNN对低分辨率landsat图像进行超分辨率处理并提取图像特征,然后采用高通调制和加权策略,从提取的特征中重建融合图像,类似于变换域图像融合算法。然而,上述三种算法并非以端到端的方式设计,并且都需要后处理程序来生成融合图像,因此它们的模型可能尚未针对图像融合任务进行完全优化。
Prabhakar等人提出了端到端的多曝光融合模型。具体来说,他们首先使用CNN融合多个输入图像的强度通道 (YCbCr颜色空间中的Y通道),然后利用对比度增强方法调整融合的强度通道,然后采用加权平均策略分别融合Cb和Cr通道。最后,将融合的通道 (Y,Cb和Cr) 堆叠在一起以产生融合图像。他们的模型可以端到端训练,并且可以应用于融合其他类型的图像,例如多焦点图像。但是,在多焦点图像数据集上的结果似乎受到低对比度影响的影响。
通过比较变换域图像融合算法和基于CNN的图像生成模型,我们发现这两种算法之间存在一些相似的特征。
首先, 变换域算法通常在开始时使用多个滤波器 (例如高斯滤波器或形态滤波器) 来提取图像特征,而CNN模型也使用大量的卷积滤波器来提取广泛的特征。
其次, 变换域融合算法通常通过加权平均策略来融合特征,而CNN模型也利用加权平均策略 (卷积特征的加权和) 来生成目标图像。与变换域图像融合算法相比,CNN模型具有三个优点 :( 1) 卷积滤波器的数量通常比传统的变换域算法中的滤波器要多得多,因此卷积滤波器可以提取更多信息的图像特征;(2) 可以学习卷积滤波器的适当参数来拟合图像融合任务; (3) 可以通过端到端的方式对CNN模型的参数进行联合优化。
受变换域算法的启发,我们提出了一种基于卷积神经网络的通用图像融合框架,其在训练阶段的体系结构如下图所示:

首先,我们使用两个卷积层从多个输入图像中提取信息丰富的低级特征。
其次,通过适当的融合策略 (例如元素最大和元素平均) 将提取的每个输入图像的卷积特征进行元素融合。
最后,通过两个卷积层重建集成特征以生成融合图像。由于所提出的模型是完全卷积的,因此可以使用任何后处理过程以端到端的方式对其进行训练,与大多数现有的图像融合模型相比,这是一个优越的优势。
此外,为了充分训练所提出的模型,我们创建了一个大规模的多焦点图像数据集,通过根据随机深度范围从我们预先构建的NYU-D2数据集 中模糊部分图像,这比模糊整个或某些部分的图像块更合理 。NYU-D2数据集中的源RGB图像可以作为我们数据集的地面真相融合图像,这比 没有地面真相融合图像要好得多。由于上述优点,我们的高分辨率大规模多焦点图像数据集可用于精细训练图像融合模型。在训练阶段,我们首先采用融合图像和ground truth融合图像的均方误差 (MSE) 来训练模型的参数,然后将感知损耗 (预测融合图像和ground truth融合图像的深度卷积特征的均方误差) 与MSE相匹配,以共同优化模型的参数。
贡献
• 本文将图像融合任务表述为全卷积神经网络,因此,可以以端到端的方式训练所提出的图像融合模型,以便可以针对图像融合任务联合优化所提出模型的所有参数,而无需任何后处理程序。基于提出的基于CNN的图像融合框架,研究人员可以方便地开发自己的图像融合模型,以融合各种类型的图像。
• 为了充分训练模型的参数,我们生成了一个大规模的多焦点图像数据集。我们没有创建低分辨率对的完全聚焦和完全模糊的图像补丁,而是通过模糊随机深度范围的图像部分来生成高分辨率对的部分聚焦图像在我们预先构建的RGB-D数据集中的RGB和深度图像。与现有的多焦点图像生成方法相比,我们的方法更接近光学镜头的成像原理,因此我们的方法生成的多焦点图像比成对的完全聚焦和完全模糊的图像更加自然和多样化。此外,可以自然地将RGB源图像作为生成的多焦点图像数据集的ground truth融合图像,这对于监督图像融合模型 (即回归模型) 以将来自多个输入的显着细节转移到一个融合图像中非常重要。凭借这些优点,我们的多焦点图像数据集可用于全面,精细地训练图像融合模型。
• 由于与变换域图像融合算法的结构相似,我们的模型在融合各种类型的图像方面比现有的CNN模型具有更好的泛化能力。尽管所提出的模型仅在多焦点图像数据集上进行了训练,但它已经很好地学习了融合相同类型甚至不同类型的多个图像的卷积特征的能力。因此,我们的模型可以直接应用于融合其他类型的图像 (例如红外视觉,CT-MR和多曝光图像),而无需任何微调程序,并且仍然可以达到最新的结果。
• 据我们所知,这是第一次在训练基于CNN的图像融合模型时引入感知损失。主要原因是感知损失的计算需要ground truth合图像,但是在用于训练图像融合模型的现有图像数据集中未生成该图像融合图像。通过引入感知损失,经过训练的图像融合模型可以产生比不包含感知损失的图像具有更多纹理信息的融合图像。
本文有两个主要的新颖性。首先,我们模型的全卷积神经网络特性和良好的泛化能力共同构成了本文的第一个主要新颖性。其次,我们的高分辨率大规模多焦点图**像数据集 (带有ground truth融合图像) 是本文的另一个主要新颖之处。原因如下 :
( 1) 据我们所知,仍然没有基于完全卷积神经网络的图像融合模型能够像我们的模型那样在不需要任何微调程序的情况下在多种类型的图像上实现最先进的融合图像,(2) 在深度学习领域,训练数据集的质量往往直接决定了模型性能的上限,因此,与现有的低分辨率大规模图像数据集 (没有ground truth融合图像) 相比,我们的高分辨率大规模多焦点图像数据集 (带有ground truth融合图像) 在充分训练图像融合模型方面更优越。因此,这两个主要新颖性中的任何一个都可以使所提出的图像融合模型从现有的基于CNN的图像融合模型中脱颖而出。
方法
我们提出的IFCNN 方法由三个模块组成: 特征提取模块、特征融合模块和图像重建模块
Image fusion model
为了方便地描述所提出的模块,我们假设有N (N ≥ 2) 个输入图像要融合,用I k (1 ≤ k ≤ N) 表示。然后,可以将所提出的图像融合模型的三个模块分别详细描述如下:
Feature extraction module
首先,我们采用两个卷积层从输入图像中提取广泛的低级特征。由于特征提取是变换域图像融合算法中的关键过程,通常通过使用多尺度DOG (高斯差) ,多尺度形态滤波器 等处理图像来进行。至于CNN,从随机初始化的卷积内核中训练回归模型 (图像到图像) 通常是困难的,并且不稳定的,因此一种实用的方法是将训练良好的分类模型的参数转移到回归模型中。因此,我们采用在ImageNet上预先训练的高级ResNet101的第一卷积层作为我们的第一卷积层 (CONV1)。CONV1包含64个大小为7 × 7的卷积核,这些卷积核足以提取广泛的图像特征,并且CONV1已经在最大的自然图像数据集 (即ImageNet) 上进行了训练。因此,CONV1可用于提取有效的图像特征,从而在训练所提出的模型时固定了CONV1的参数。但是,CONV1提取的特征最初用于分类任务,因此将它们直接输入特征融合模块可能不适合图像融合任务。因此,我们添加了第二卷积层 (CONV2) 来调整CONV1的卷积特征,以适应特征融合。
Feature fusion module
本文的目标是提出一种基于CNN的通用图像融合模型,该模型可以融合各种类型的输入图像,也可以融合各种数量的输入图像。一般情况下,通常有两种方法来融合多个输入的卷积特征 😦 1) 首先将多个输入的卷积特征沿信道维度进行级联,然后通过以下的卷积层对级联特征进行融合,(2) 通过元素融合规则 (例如元素最大,元素总和和元素均值) 直接融合多个输入的卷积特征。由于串联融合方法要求特征融合模块的参数编号随输入数量而变化,因此,使用该融合方法的模型只能在模型架构固定后融合特定数量的图像。而具有元素融合方法的特征融合模块不包含任何参数,可以融合各种数量的输入图像,并且在图像融合模型中曾经引入过。
因此,在我们的特征融合模块中,已利用元素融合规则来融合多个输入的卷积特征,可以将其数学表示为公式
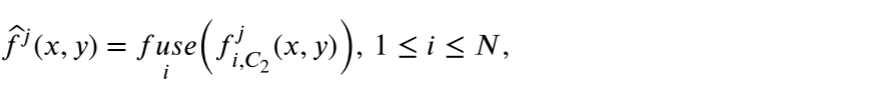
(其中 𝑓 𝑗 ( 𝑓 𝑗 𝑖,𝐶 2 (𝑥,𝑦) ),1 ≤ 𝑖 ≤ 𝑁,(1) 𝑖,𝐶 2表示CONV2提取的第i个输入图像的第j个特征图,在我们的特征融合模块中,fuse表示融合特征图的第j个通道,fuse表示元素融合规则 (例如元素最大,元素总和和元素均值)。)
如上所述,存在三种常用的元素融合规则,即元素最大,元素总和和元素平均。在实际应用中,应根据图像数据集的特点选择融合规则。例如,清晰的特征 (最大值) 表示受监督场景的显着对象,因此,在转换域图像融合算法中经常使用元素最大融合规则来融合多焦点图像,红外和视觉图像,以及医学图像。但是,多曝光图像融合是集成每个输入图像的视觉愉悦的中间曝光部分,其中最有可能对应于多个输入的平均特征。因此,此时,与元素最大融合规则(可用于融合其他图像)相比,元素平均融合规则可能更适合融合多曝光图像。
我们的模型旨在融合多个RGB图像并产生一个RGB融合图像 可以通过堆叠三个相同的通道来方便地扩展所提出的模型以融合单通道图像。 具体地,RGB多焦点图像可以通过所提出的模型直接融合,红外和视觉图像或多模态医学图像应首先扩展到三个通道,然后可以通过我们的模型进行融合。最后,参考执行RGB多曝光图像的融合 :
( 1) 将RGB输入图像转换为YCbCr颜色空间,(2) 对于每个输入图像,分离YCbCr通道并堆叠三个Y通道作为我们图像融合模型的输入,(3) 使用我们的模型融合所有源图像的三通道Y图像,并根据公式将三通道输出转换为单通道Y ′。

((4) 通过与Prabhakar等人相同的加权策略融合所有源图像的Cb和Cr通道,(5) 将Y ′ 、融合Cb和融合Cr堆叠在一起,并将其转换回RGB色彩空间,以产生融合图像。请注意,Prabhakar等人的方法的输入和输出与我们的方法略有不同,他们的模型的输入和输出都是单通道,而我们的模型的输入和输出都是三通道。因此,在融合多曝光图像时,将每个源图像的Y通道扩展到三个Y通道,然后再输入到我们的图像融合模型中。
![[附源码]Python计算机毕业设计电影网站系统设计Django(程序+LW)](https://img-blog.csdnimg.cn/8db40f659be64277bf73b35c426d3a0a.png)
![OpenAi[ChatGPT] 使用Python对接OpenAi APi 实现智能QQ机器人-学习详解篇](https://img-blog.csdnimg.cn/img_convert/ffb49a865373b32b1690f0c4a22dd7f9.png)

![[附源码]Node.js计算机毕业设计大悦城电竞赛事管理系统Express](https://img-blog.csdnimg.cn/114da38b708642cdbb855c0a178b8474.png)