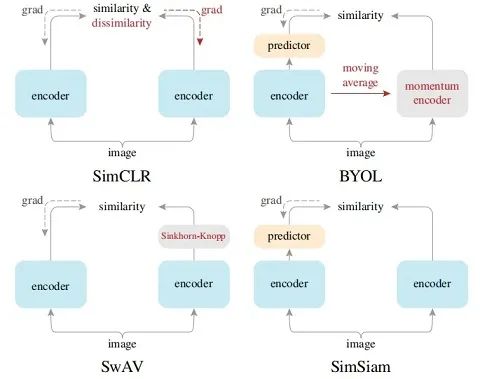
1. Introduction
利用手工制作的特征,如文章长度、句子长度、语法正确性或可读性来评分的文章面临以下问题。首先,它可能被学生用作欺骗系统的一种选择,即写出并提交一篇结构良好但偏离主题**的文章。由于文字结构和表面等语言特征,每一篇写得很好但不涉及问题主题的文章都可能从AES系统中获得一个好分数。如果每篇提交给AES系统的文章都被评估为标准的论文输入,那么可能会降低用户对AES引擎的信心。其次,创建这些手工制作的特征是繁琐的、耗时的,有时甚至是低效的。
- (偏离主题的话,那是否可以加一个主题判断???)
因此,必须使用新的方法,在没有手工制作特征的情况下对论文进行语义上的评分。
事实上现在的工作大多都是使用手工特征以及神经网络的结合来进行的,所以作者可能考虑到这点,想提出一个基于深度学习的网络模型来进行AES.
2.Contribution
- 引入了一个新的潜在语义模型,该模型利用双向门控递归神经网络的多通道卷积池操作,在单词n-gram和文章层面上捕捉到了上下文结构的前一个以及后一个特征。
3.Models
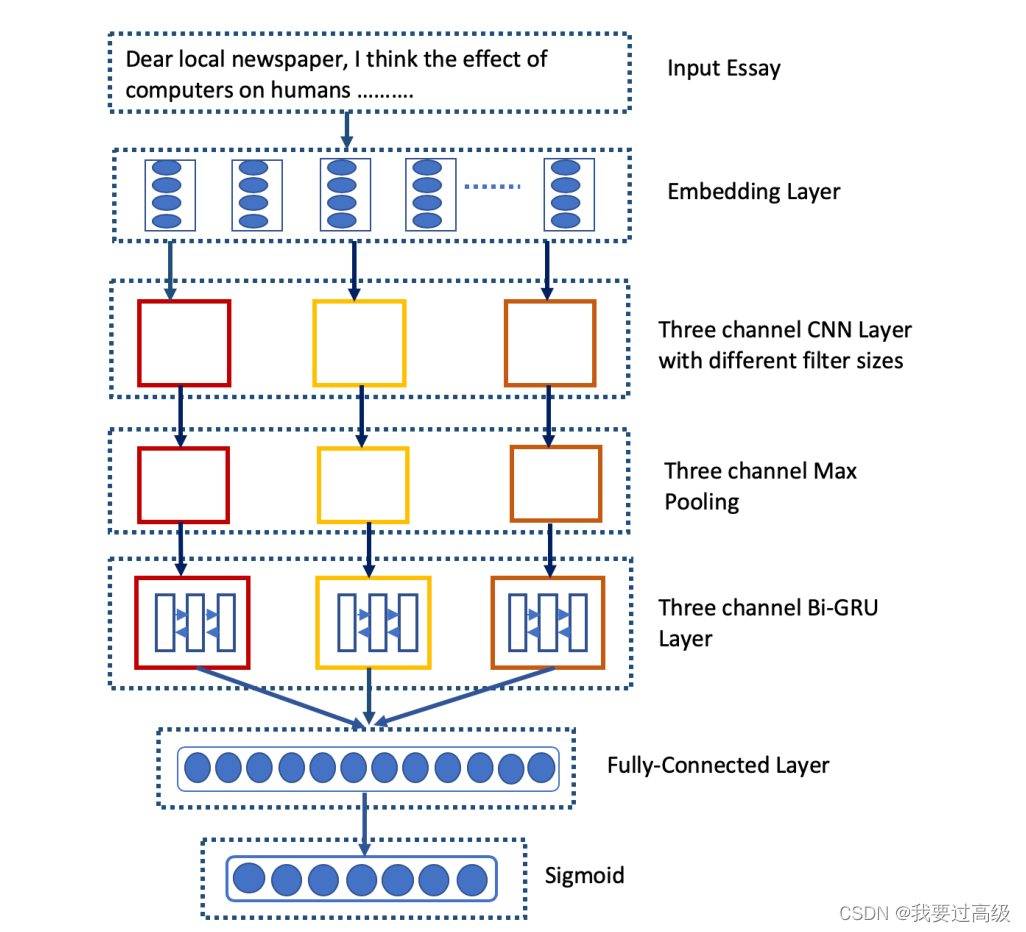
DeLAES不使用基于单词袋的输入表示,而是将一篇文章视为具有丰富上下文结构的单词序列,并在其预测的潜在语义表示中保留了最大的上下文信息。
- 该模型首先使用跳词模型将其上下文中的每个词投射到一个低维的连续特征向量上。
- 然后,它使用一个三通道卷积神经网络直接学习和捕捉单词n-gram层面的上下文特
征。 - 第二,该模型没有发现和聚集所有的词n-gram特征,而只是发现了基本的语义概念,利用最大池形成了文章层面的特征向量。
- 第三,每个频道的文章层面的特征向量被传递给双向门控递归神经网络,该网络执行非线性转换,从每个频道的词序中提取高层次语义信息。
- 然后,从每个频道中提取的高层次语义表征被汇总,以获得文章层面的最终语义表征,并被送入一个全连接层,使用Sigmoid函数进行分数预测。
4.Result
5.Conclusion
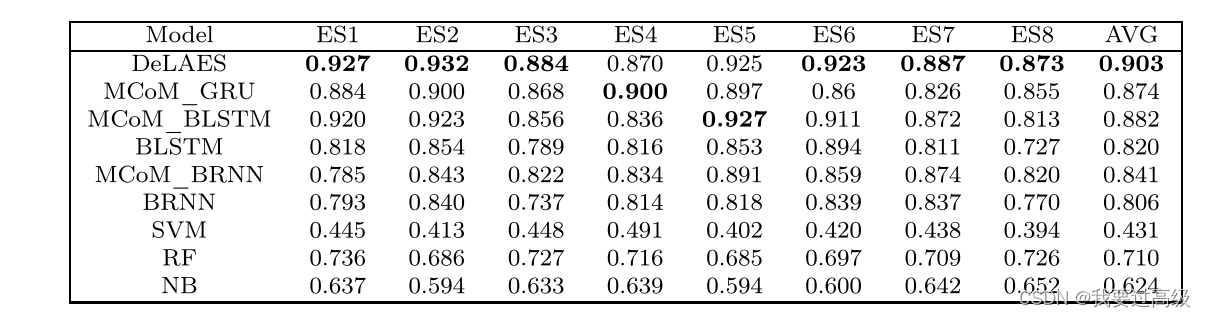
本文提出的双向门控网络,更好理解上下文信息,这是创新点,主要考虑的点是基于语义的学习。
![[附源码]Python计算机毕业设计电影网站系统设计Django(程序+LW)](https://img-blog.csdnimg.cn/8db40f659be64277bf73b35c426d3a0a.png)
![OpenAi[ChatGPT] 使用Python对接OpenAi APi 实现智能QQ机器人-学习详解篇](https://img-blog.csdnimg.cn/img_convert/ffb49a865373b32b1690f0c4a22dd7f9.png)

![[附源码]Node.js计算机毕业设计大悦城电竞赛事管理系统Express](https://img-blog.csdnimg.cn/114da38b708642cdbb855c0a178b8474.png)