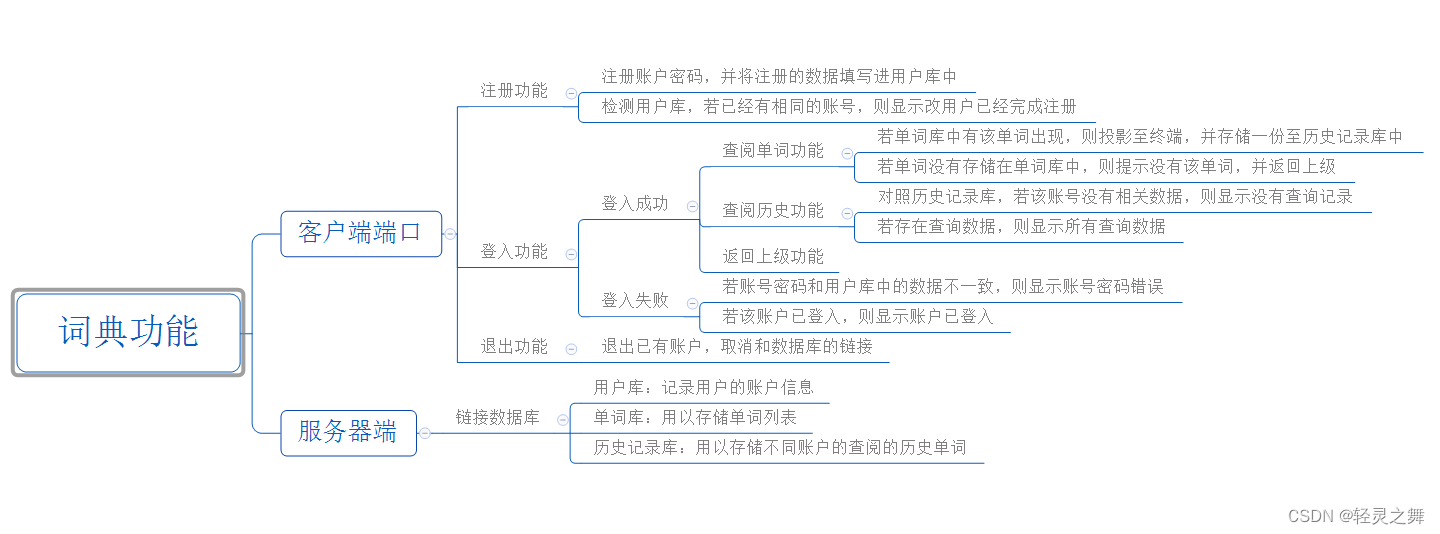
文章目录
- 十一、UrbanBIS-城市场景数据集;B-Seg实例分割(SIGGRAPH 2023)
- 0.摘要
- 1. 数据集特点
- 2.B-Seg实例分割算法
提示:本文衔接上一篇文章【3D点云】分割算法总结(一)
十一、UrbanBIS-城市场景数据集;B-Seg实例分割(SIGGRAPH 2023)
作者:VCC杨国庆博士(深圳大学可视计算研究中心黄惠教授课题组与香港中文大学傅志荣教授合作完成)
论文:UrbanBIS: a Large-scale Benchmark for Fine-grained Urban Building Instance Segmentation
期刊:国际计算机图形学顶级会议SIGGRAPH 2023
项目主页: https://vcc.tech/UrbanBIS/
该工作构建了一个大规模城市场景理解基准测试数据集,提供包括图像、点云以及网格模型(三角网格)在内的海量多模态数据和三维语义标注与建筑物实例标注,可广泛应用于语义分割、实例分割、点云重建、布局规划等多项城市理解任务,为智慧城市前沿技术建设提供重要支撑。同时提供一个面向城市场景点云建筑物实例分割的轻量化模型B-Seg,采用端到端的学习结构,提高处理效率的同时提升模型针对不同城市场景的泛化性能。
0.摘要
用于建筑物实例分割的大规模真实城市场景数据集UrbanBIS,UrbanBIS共包含6个真实场景,总面积高达10.78 km2 ,包含3370栋建筑,不仅提供城市场景的常见语义信息以及建筑物单体实例信息,同时提供细粒度的建筑物语义标注信息。是目前唯一一个可用于点云实例分割的大规模的3D真实城市场景数据集。
1. 数据集特点
1.场景面积大:共提供6个城市场景,总面积达到10.76 km2 ,这也是目前最大的三维真实场景数据;
2.多模态的数据:点云数据,图像以及三角网格数据,类型多样;
3.实例标注数据:语义信息、建筑物实例进行了提取与标注,并且进一步围绕建筑物使用功能提供了细粒度的标签;
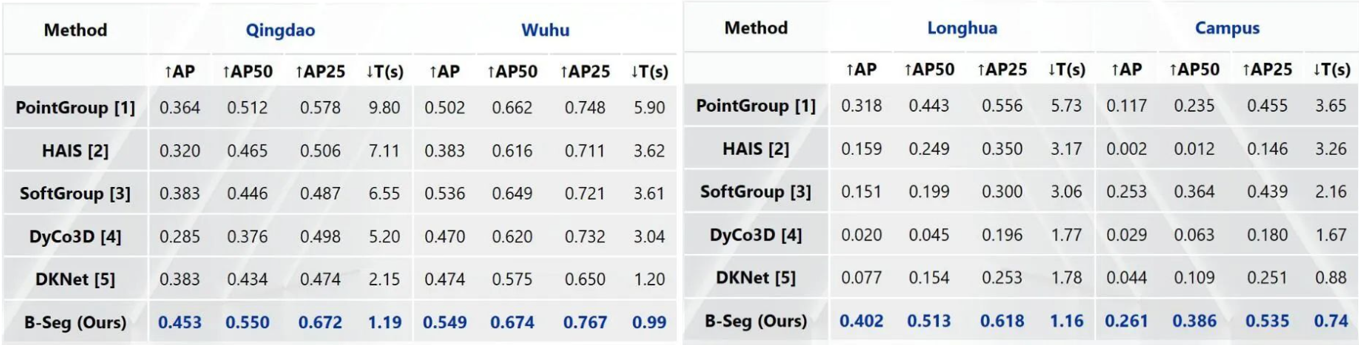
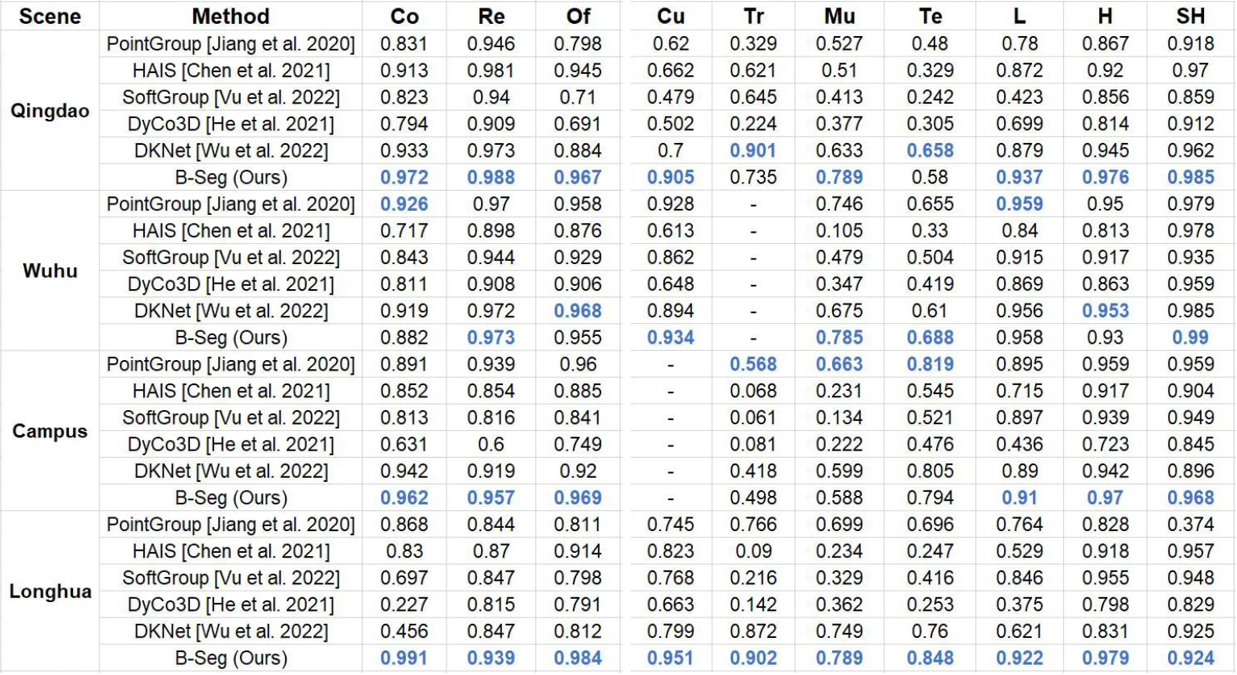
4.针对实例分割的基准测试:基于UrbanBIS对一些算法在其上的性能表现进行了测试,为新算法设计提供了新的评估基准,建立了首个城市场景实例分割的测试基准。
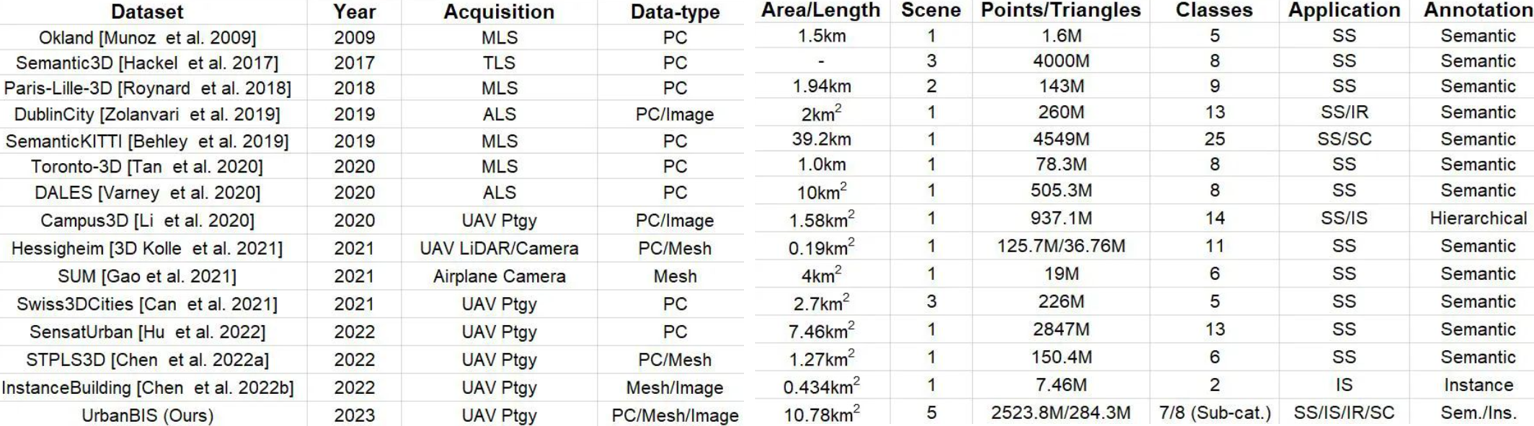
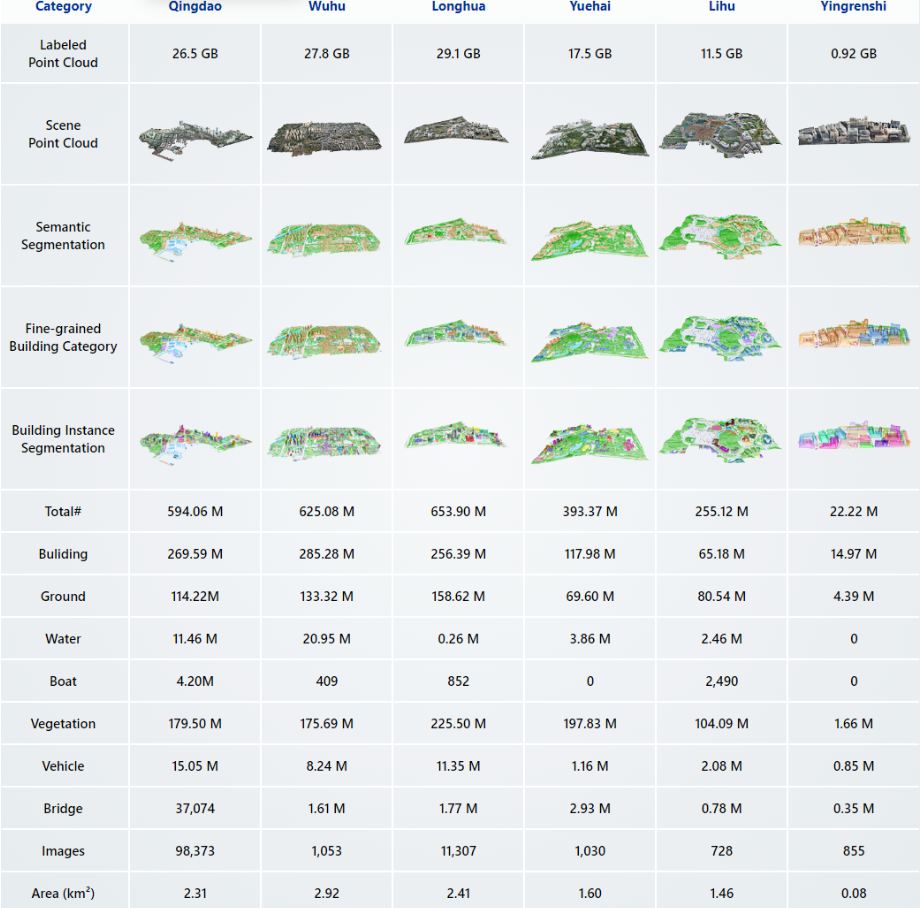
下表为多种城市场景数据集,UrbanBIS拥有目前最大的面积以及最为丰富的数据类型,并支持多项任务的训练与验证。
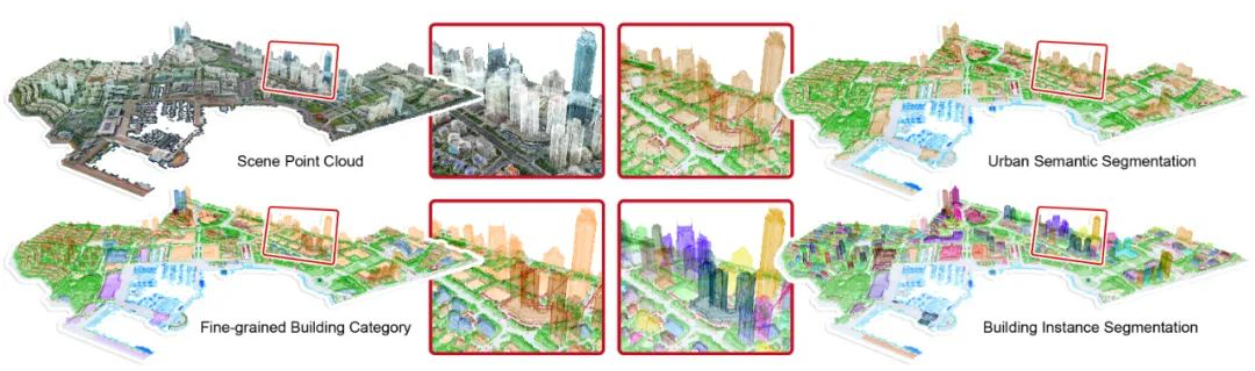
1. 7种语义类别:UrbanBIS是基于无人机倾斜摄影技术获取图像作为原始数据并基于此采用处理软件进行重建得到的三维模型。重建得到的模型进行了人工标注,确定7种城市场景中常见的语义类别,具体包括地面、水面、船只、植被、桥梁、车辆以及建筑物,如下图所示:
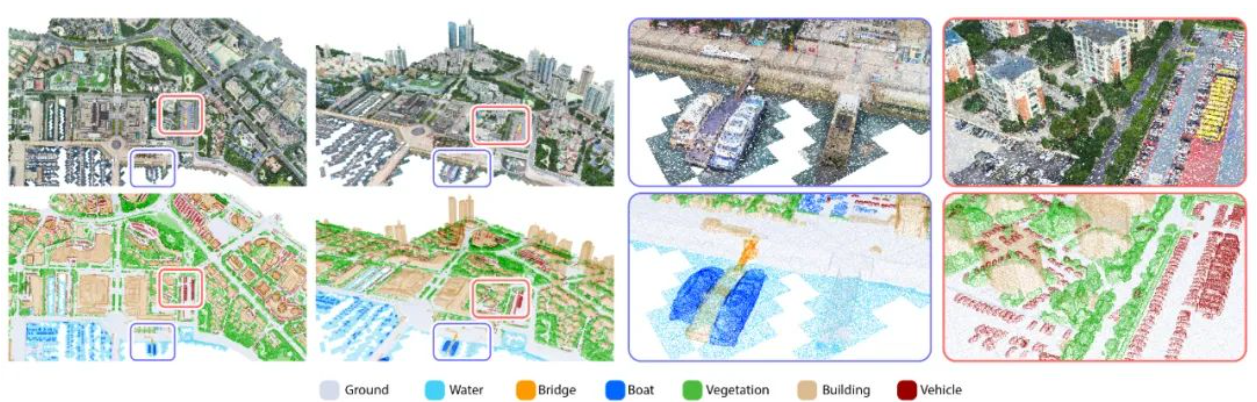
各类别的统计:
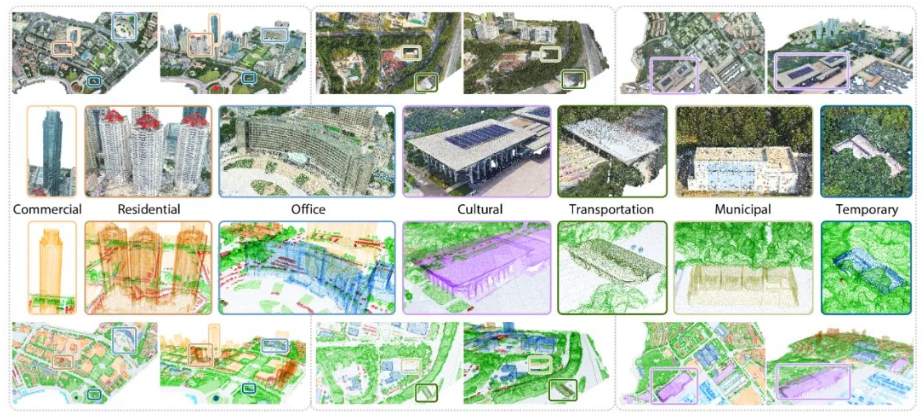
2.建筑实例划分: 除了语义信息,同样对建筑物实例进行了划分:考虑到建筑物的类内差异过大的实际情况,进一步按照使用功能对建筑物进行划分为商业建筑、居住建筑、办公建筑、文化建筑、交通建筑、市政建筑以及临时建筑,各个建筑物示意如下图所示:
3. 多种标注类型:UrbanBIS提供了多源数据和丰富的标注信息,可以用于多项视觉与图形学相关任务中,例如:


2.B-Seg实例分割算法

B-Seg的主要流程包含三步:
(1)特征提取:骨干网络提取点云特征,学习到的点云特征将用于后续的三个子任务分支;
(2)生成proposal 候选:建筑物候选生成模块,生成实例候选(包括建筑物候选选择、分组以及合并三个子模块);
(3)实例打分:预测建筑物实例 proposal 的得分,该模块预测的 score 用于评估建筑物实例的预测质量,同时滤除错误的预测。
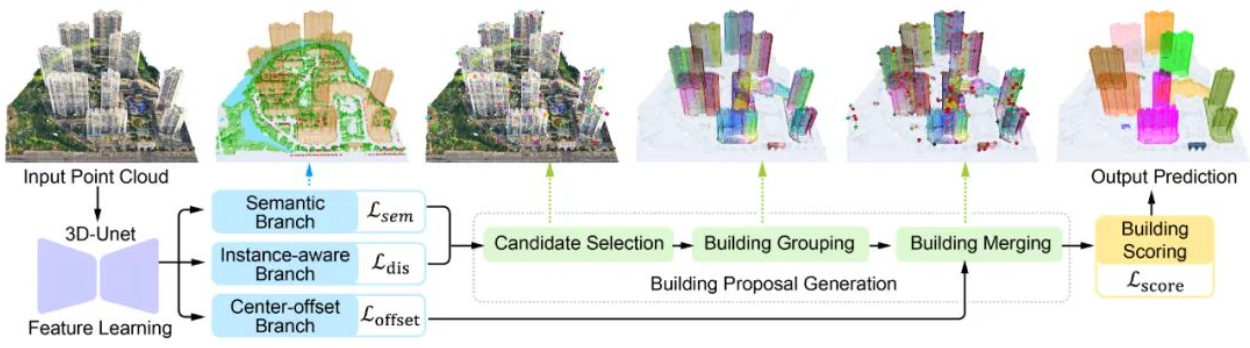
下图所示为B-Seg的特征提取网络和三个分支,其中特征提取网络采用3D UNet,而分支采用全连接网络:
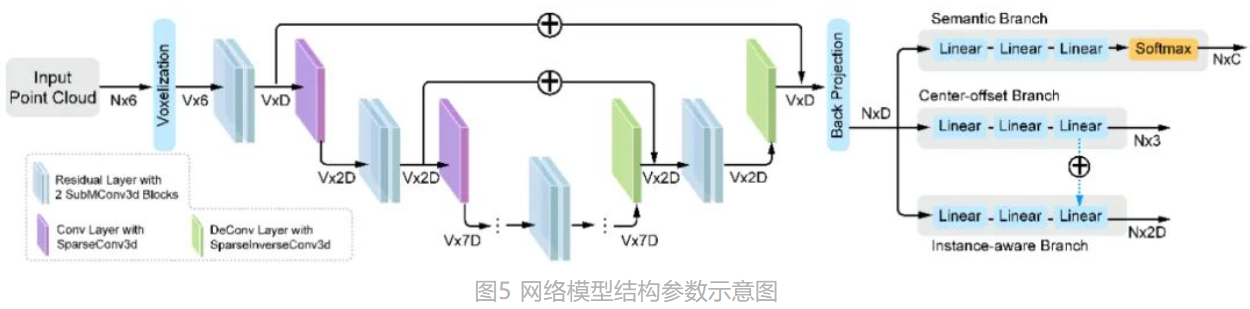
- 语义分割分支
为了获取建筑物实例,本文需要对输入的点云进行前后景分离,得到只包含建筑物类别的前景点
Pb。具体地,本文使用了由三层线性层构成的感知机和一个Softmax函数作为输出层构造语义分割分支子网络,用来学习每个点的语义特征信息,并输出语义类别预测的概率分布S∈RN*C ,其中 C 是类别总数。本文选择最大预测概率的类别作为每个点的语义预测结果。这个过程由语义损失函数进行监督学习:
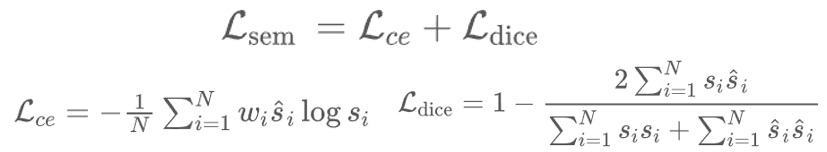
其中, si 和
s
^
\hat{s}
s^i 分别是点 pi 的语义概率预测值以及语义类别标签的真实值。 Lce 是传统的交叉熵损失函数,由于城市场景中的数据广泛存在长尾分布问题,为了这种缓解类别不平衡的情况,本文采用了加权交叉熵损失形式,这使得分割网络模型对于场景中数量较少的类别关注度更高。此外, Ldice 是广泛应用于医学图像分割的dice损失函数,衡量了预测样本和真实样本之间的相似度。本文通过引进该损失函数用于解决城市场景中正负样本强烈不平衡的情况,提高建筑物的语义分割精度。
- 中心偏移分支
为了方便后续建筑物合并的操作,在点云特征提取阶段后,设计了一个子网络用于预测每个点到其建筑物中心的偏移向量。本文使用了由两层线性层构成的感知机学习每个点的中心偏移特征,然后使用一层线性层预测每个点在三维空间中的中心偏移向量 O∈RN*3 。 该向量指示了每个点到其对应建筑物实例中心的距离和方向,经过中心偏移后每个点会朝着其建筑物实例中心的位置进行靠近。为了达到这个目的,本文使用以下的中心偏移损失函数进行约束:
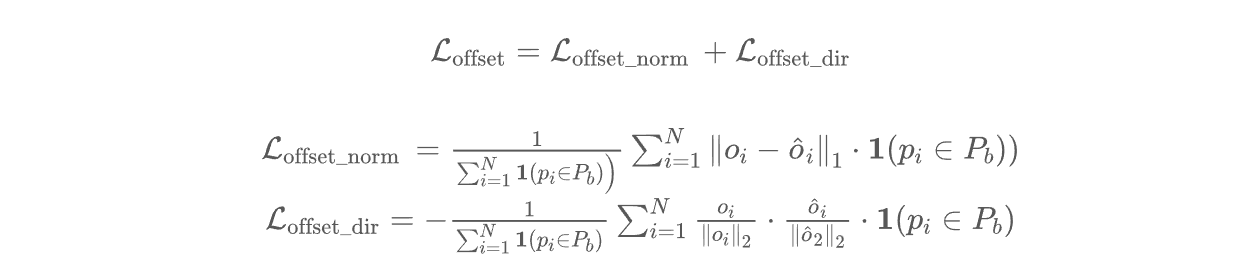
其中, oi 和
o
^
\hat{o}
o^i 分别是点 pi 的建筑物中心偏移向量的预测值和真实值, ci 是点 pi 对应的建筑物中心。 Loffset_norm 损失函数限制了预测的中心偏移向量和中心偏移向量真实值之间的距离差异尽可能小。此外本文使用 Loffset_dir 损失函数限制了预测的中心偏移向量与中心偏移向量真实值两者之间的夹角尽可能小。借助这两个损失函数的约束,中心偏移分支可以准确地输出每个点的中心偏移向量。
- 实例感知分支
为了获得更准确的建筑物实例分割结果,本文从建筑物实例特征嵌入的角度考虑并构建了一个实例感知子网络。本文假设可以通过神经网络将每个点的特征映射到一个新的嵌入特征空间。在这个空间里,不同的建筑物点之间的特征距离尽可能大而相同建筑物点之间的特征距离尽可能小。为了达到这个目的,本文使用了一个由三层线性层构成的感知机学习每个点的建筑物实例感知特征 E∈RN*D ,其中第三层线性层的输入拼接了来自中心偏移分支的特征,使得学习得到的实例感知特征包含实例中心位置信息。为了更好学习实例感知特征,本文使用了一个判别式损失函数进行监督训练:
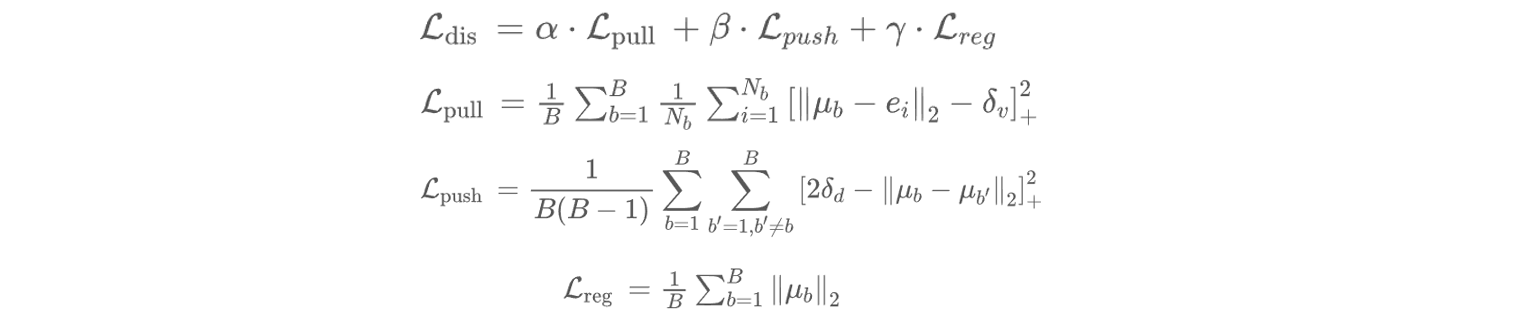

- 候选生成模块
在点云特征学习以及三个子任务分支之后,为了得到建筑物的实例预测,本文提出了一种建筑物实例候选生成模块,该模块包括了建筑物实例候选选取、建筑物分组、建筑物合并三个部分。
a. 筑物实例中心实例候选选取部分基于语义分割分支的预测结果将输入点云划分前景点(建筑物点)和背景点(非建筑物点)。对于前景点,本文选择简单的点云采样方法算法采样K个点作为建筑物实例候选点。为了使得采样得到的建筑物实例候选点能够均匀地覆盖每个建筑物实例表面上,本文选择FPS进行采样;
b. 由于每个建筑物实例候选点代表的是一个完整的建筑物实例,因此对于剩下的建筑物前景点本文需要对它们进行分组操作,即把每个建筑物前景点划分到对应的建筑物实例候选点,从而产生初始的建筑物实例候选预测。本文根据建筑物实例候选点直接为每个建筑物前景点分配一个唯一的建筑物实例预测标签,基于K 个建筑物实例候选点以及 N’ 个建筑物前景点构造了一个关系矩阵 R∈RK*N‘
。在关系矩阵 R 中,每个元素是由建筑物前景点 pi 与建筑物实例候选点 pj 两者之间的建筑物实例感知特征的特征距离计算得到,代表着这两个点属于同一个建筑物的关系相似性。在特征学习阶段,实例感知分支为每个点学习了其对应建筑物的实例感知特征,该特征具有在同一个建筑物内的特征距离较小,在不同建筑物之间的特征距离较大的特点,因此可选择具有最小特征距离的建筑物候选点 pi 的矩阵列索引 i 作为第个建筑物前景点的建筑物实例预测标签;
c. 尽管在建筑物分组阶段,本文已经得到了每个建筑物前景点的初始建筑物实例预测标签,但这些预测标签会出现冗余的情况。这是因为在建筑物实例候选选择阶段,本文为了避免对建筑物的遗漏设置了大量的建筑实例候选点采样。这种做法虽然能覆盖场景中的建筑物,但是也会大概率使得同一个建筑物上分布着多个建筑物候选点。经过了建筑物分组操作后会出现同一个建筑物会具有多个不同建筑物实例预测标签的情况。为了解决这个问题,本文提出了一个建筑物合并子模块将属于同一个建筑物上的所有建筑物实例预测标签进行合并。先使用了在中心偏移分支网络预测的建筑物实例中心偏移向量 O 将 K 个建筑物实例候选点进行偏移,使得它们朝着对应的建筑物实例中心移动。建筑物实例候选点在经过了中心偏移之后,会分别聚集在对应建筑物的中心附近区域,从而完成后续的合并;
d. 由于语义预测错误、建筑物候选点错误选择、中心偏移预测错误等原因,本文的建筑物实例候选生成模块难以避免地会产生一些错误、无效的建筑物实例预测。为了解决这种问题,引入了实例得分预测网络,用于对生成的建筑物实例预测进行质量评估与错误过滤。得分预测网络结构与本文的骨干网络类似,是具有两层对称结构的三维子流形稀疏卷积U-Net网络,为每一个建筑物实例输出一个建筑物评价得分,该得分衡量了生成的建筑物实例的质量好坏。
根据UrbanBIS上的设置不同,主要可分为几种不同的基准测试方式,包括全部场景的基准测试、交叉场景的基准测试以及单一场景的基准测试,每种不同的测试方法可根据需要具体选择。

UrbanBIS可提供图像、点云以及三角网格等多种不同格式的数据下载。项目主页下载数据,支持Dropbox与百度云网盘两种下载方式。对于图像和三角网格数据,提供了申请下载的方式。