目录
💥1 概述
📚2 运行结果
🌈3 Python代码及数据
🎉4 参考文献

💥1 概述
前馈神经网络的输出只依赖当前输入,但是在文本、视频、语音等时序数据中,时序数据长度并不固定,前馈神经网络的输入输出维数不能任意更改,因此难以适应这类型时序数据的处理。短期电力负荷预测的输入与输出均为时间序列,其本质仍是基于先前元素的序列预测问题,为此需要采用与前馈神经网络不同的方法,进行短期电力负荷预测。
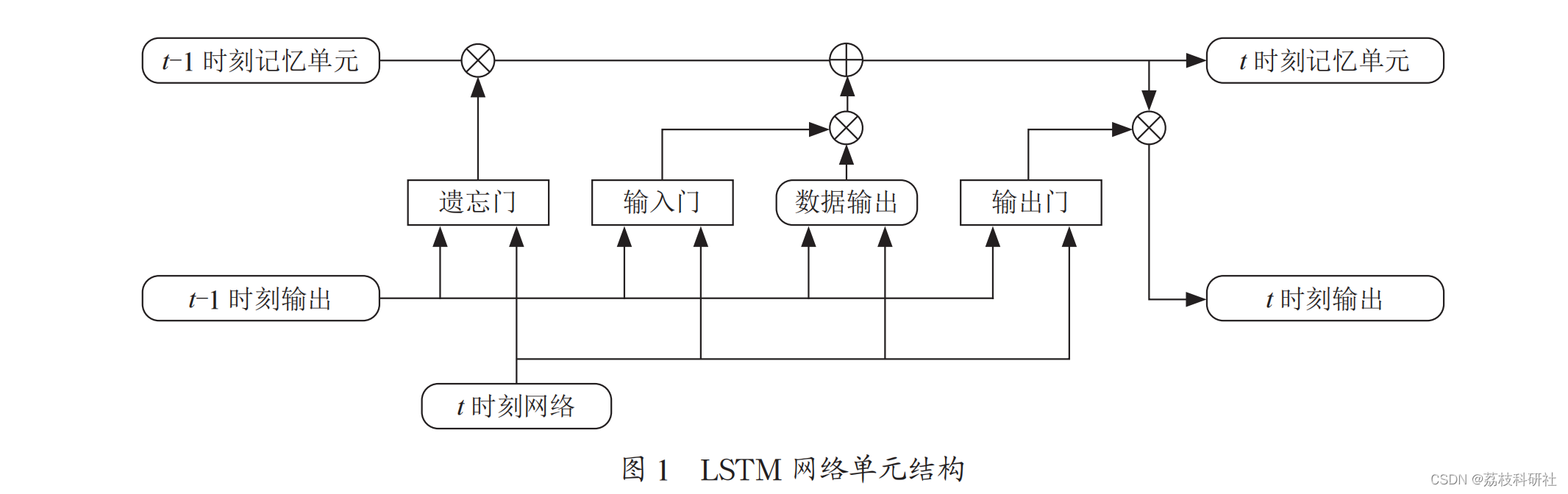
循环神经网络具有记忆功能,可提升网络性能。与前馈神经网络相比,循环神经网络具备可同时接受自身信息与其他神经元信息的神经元,更贴合生物神经网络结构,在文本等序列数据分析中有广泛应用。循环神经网络的参数学习随时间反向传播,错误信息前传递学习,建立长时间间隔的状态间依赖,支持序列数据的分析处理。但随着网络层数增多与时间加长,循环神经网络容易因梯度消失或爆炸问题,导致只能学习短距离依赖,无法解决长距离依赖问题。为了解决循环神经网络的长程依赖问题,在循环神经网络上添加门控机制,实现调度信息积累速度控制,这类方法被称之为基于门控的循环神经网络,例如LSTM长短期记忆网络。LSTM是一种基于RNN的改进模型,通过引入门和单元的概念,解决长距离依赖问题,具有比RNN更强的适应性。LSTM网络的单结构如图1所示。每个神经单元内部结构如图2所示。
每个LSTM神经单元都包含遗忘门、输入门和输出门三个门控结构,以控制数据有信息的换地。其中,遗忘门负责丢弃和保留上一个时刻的有效信息在C{C内,输入门将当前时刻有效信息存放在Ct内,输出门决定神经单元输出中C·的信息。
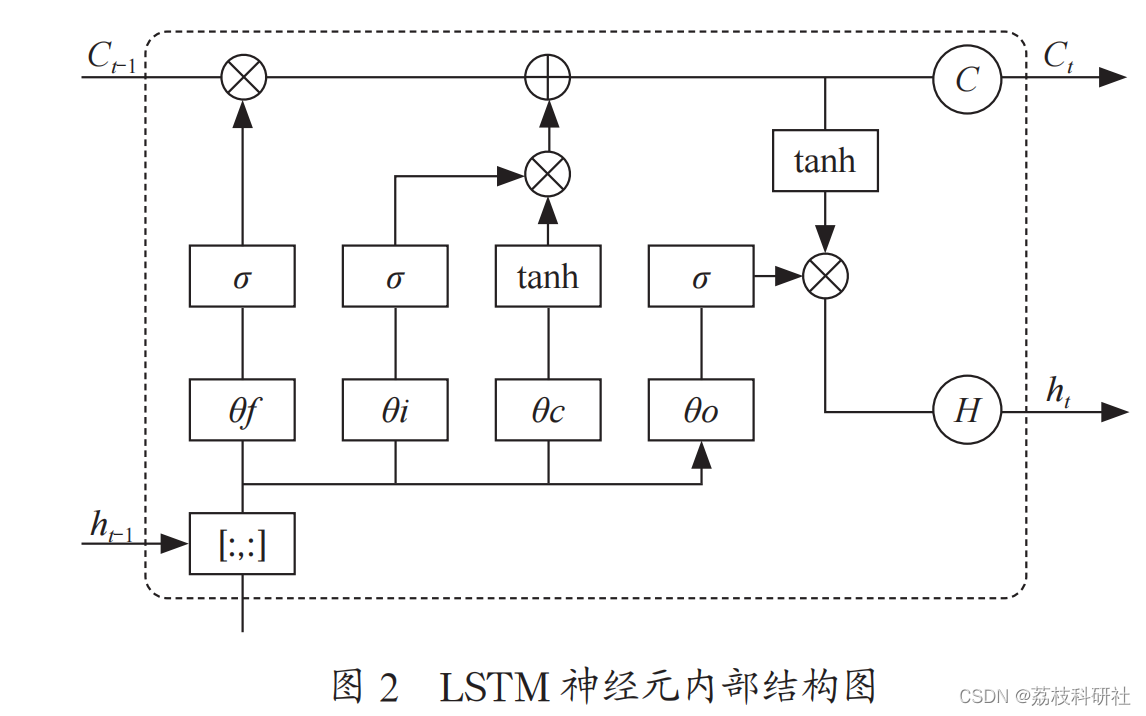
与传统神经网络算法相比,LSTM网络具有更强的自适应学习能力,对复杂样本数据有更好的拟合效果。LSTM网络通过门控结构,有效避免了时间增加所导致的梯度消失的问题,且由于采用了三个输入值与两个输入值的当前时刻记忆单元,因此模型也具有更好的泛化能力。
📚2 运行结果
City AEP, model MLP, epoch 10, train_mse_loss 0.035387418246355606, [150s]
City AEP, model MLP, epoch 20, train_mse_loss 0.032379517520683396, [289s]
City AEP, model MLP, epoch 30, train_mse_loss 0.02896040348687034, [427s]
City AEP, model MLP, epoch 40, train_mse_loss 0.025020044269985046, [567s]
City AEP, model MLP, epoch 50, train_mse_loss 0.020603562772705936, [705s]
City AEP, model MLP, epoch 60, train_mse_loss 0.017132578714602234, [841s]
City AEP, model MLP, epoch 70, train_mse_loss 0.013568510578108438, [2662s]
City AEP, model MLP, epoch 80, train_mse_loss 0.010349302512148151, [2804s]
City AEP, model MLP, epoch 90, train_mse_loss 0.008659378628826875, [2966s]
City AEP, model MLP, epoch 100, train_mse_loss 0.007364045838703928, [3117s]
City AEP, model MLP, epoch 110, train_mse_loss 0.006385179391751687, [3279s]
City AEP, model MLP, epoch 120, train_mse_loss 0.005340989620046879, [3414s]
City AEP, model MLP, epoch 130, train_mse_loss 0.004808902484027372, [3553s]
City AEP, model MLP, epoch 140, train_mse_loss 0.004394962796536477, [3705s]
City AEP, model MLP, epoch 150, train_mse_loss 0.0043113342354722, [3850s]
City AEP, model MLP, epoch 160, train_mse_loss 0.00431272537663471, [4003s]
City AEP, model MLP, epoch 170, train_mse_loss 0.004233362978202817, [4165s]
City AEP, model MLP, epoch 180, train_mse_loss 0.0041272962850559015, [4320s]
City AEP, model MLP, epoch 190, train_mse_loss 0.004165695266514693, [4465s]
City AEP, model MLP, epoch 200, train_mse_loss 0.004172246530314611, [4606s]
City AEP, model MLP, epoch 210, train_mse_loss 0.0043414913436762344, [4760s]
City AEP, model MLP, epoch 220, train_mse_loss 0.00410465720831754, [4895s]
City AEP, model MLP, epoch 230, train_mse_loss 0.00419495751797829, [5028s]
City AEP, model MLP, epoch 240, train_mse_loss 0.004089633657502523, [5168s]
City AEP, model MLP, epoch 250, train_mse_loss 0.0042064220887487345, [5331s]
City AEP, model MLP, epoch 260, train_mse_loss 0.004085837542821748, [5491s]
City AEP, model MLP, epoch 270, train_mse_loss 0.004034197799847933, [5645s]运行时间比较长。
for loss_type in ['mse', 'smoothl1loss']:
args.loss_type = loss_type
preds = pd.read_csv(args.save_res_dir + 'ele_' + args.loss_type + '_preds_' + args.model_name + '.csv')
# 绘图
plt.plot(preds[[args.city_name]].values.flatten()[::args.plot_gap], 'r', label='prediction')
plt.plot(np.multiply(data_y.flatten()[::args.plot_gap], scalar), 'b', label='real')
plt.legend(loc='best')
plt.savefig(save_plot_dir + args.city_name + '_' + args.loss_type + '.jpg')
# plt.show()
plt.close()部分代码:
#一、数据准备
datas = df1.values[:, 2]
print(datas.shape)
#归一化处理,这一步必不可少,不然后面训练数据误差会很大,模型没法用
max_value = np.max(datas)
min_value = np.min(datas)
scalar = max_value - min_value
datas = list(map(lambda x: x / scalar, datas))
#数据集和目标值赋值,dataset为数据,look_back为以几行数据为特征维度数量
def creat_dataset(dataset,look_back):
data_x = []
data_y = []
for i in range(len(dataset)-look_back):
data_x.append(dataset[i:i+look_back])
data_y.append(dataset[i+look_back])
return np.asarray(data_x), np.asarray(data_y) #转为ndarray数据
#以2为特征维度,得到数据集
dataX, dataY = creat_dataset(datas,2)
train_size = int(len(dataX)*0.7)
x_train = dataX[:train_size] #训练数据
y_train = dataY[:train_size] #训练数据目标值
x_train = x_train.reshape(-1, 1, 2) #将训练数据调整成pytorch中lstm算法的输入维度
y_train = y_train.reshape(-1, 1, 1) #将目标值调整成pytorch中lstm算法的输出维度
#将ndarray数据转换为张量,因为pytorch用的数据类型是张量
#一、数据准备
datas = df1.values[:, 2]
print(datas.shape)
#归一化处理,这一步必不可少,不然后面训练数据误差会很大,模型没法用
max_value = np.max(datas)
min_value = np.min(datas)
scalar = max_value - min_value
datas = list(map(lambda x: x / scalar, datas))
#数据集和目标值赋值,dataset为数据,look_back为以几行数据为特征维度数量
def creat_dataset(dataset,look_back):
data_x = []
data_y = []
for i in range(len(dataset)-look_back):
data_x.append(dataset[i:i+look_back])
data_y.append(dataset[i+look_back])
return np.asarray(data_x), np.asarray(data_y) #转为ndarray数据
#以2为特征维度,得到数据集
dataX, dataY = creat_dataset(datas,2)
train_size = int(len(dataX)*0.7)
x_train = dataX[:train_size] #训练数据
y_train = dataY[:train_size] #训练数据目标值
x_train = x_train.reshape(-1, 1, 2) #将训练数据调整成pytorch中lstm算法的输入维度
y_train = y_train.reshape(-1, 1, 1) #将目标值调整成pytorch中lstm算法的输出维度
#将ndarray数据转换为张量,因为pytorch用的数据类型是张量
🌈3 Python代码及数据
🎉4 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]刘海峰,王艳如.基于LSTM的短期电力负荷预测算法研究[J].现代信息科技,2021,5(23):40-42+47.DOI:10.19850/j.cnki.2096-4706.2021.23.011.
[2]陈振宇,杨斌,阮文俊,沈杰,吴丽莉.基于LSTM神经网络的短期电能负荷预测[J].电力大数据,2021,24(04):8-15.DOI:10.19317/j.cnki.1008-083x.2021.04.002.