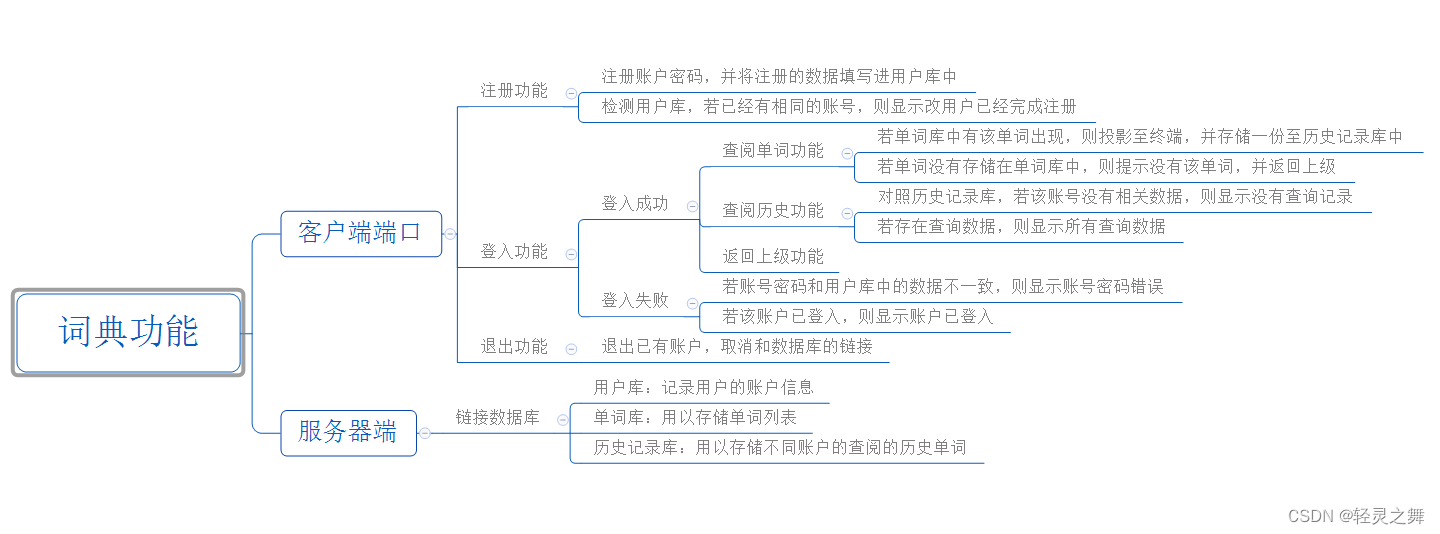
目录
七、函数进阶
7.1、函数多返回值
7.2、函数多种传参方式
位置参数
关键字参数
缺省参数
不定长参数
位置传递
关键字传递
7.3、匿名函数
函数作为参数传递
lambda匿名函数
八、文件操作
8.1、文件的读取
open()打开函数
mode常用的三种基础访问模式
读操作相关方法
read()方法
readlines()方法
readline()方法
for循环读取文件行
close() 关闭文件对象
8.2、文件的写入
8.3、文件的追加
九、异常、模块与包
9.1、什么是异常?
9.2、异常的捕获方法
捕获常规异常
捕获指定异常
捕获多个异常
捕获异常并输出描述信息
捕获所有异常
异常else
异常的finally
9.3、异常的传递
9.4、Python模块
模块的导入
什么是模块?
模块的导入方式
import模块名
from 模块名 import 功能名
from 模块名 import *
as定义别名
自定义模块
制作自定义模块
测试模块
__all__
9.5、Python包
快速入门
导入包
方式一
方式二
安装第三方包
安装第三方包 - pip
pip的网络优化
安装第三方包 - PyCharm
9.6、JSON运用
十、面向对象
10.1、初始对象
10.2、成员方法
什么是类?
成员变量和成员方法
成员方法的定义语法
10.3、构造方法
10.4、其它内置方法
魔术方法
__str__ 字符串方法
__lt__ 小于符号比较方法
__le__ 小于等于比较符号方法
__eq__比较运算符实现方法
10.5、封装
面向对象的三大特性
私有成员
10.6、继承
单继承
多继承
调用父类同名成员
10.7、类型注解
变量的类型注解
基础数据类型注解
类对象类型注解
基础容器类型注解
容器类型详细注解
类型注解的语法
函数(方法)的类型注解
形参注解
返回值注解
union类型
10.8、多态
什么是多态?
抽象类(接口)
十一、操作SQL
11.1、基本操作
11.2、插入数据
11.3、查询数据
十二、PySpark
12.1基础准备
PySpark库的安装
构建PySpark执行环境入口对象
12.2、数据输入
RDD对象
Python数据容器转RDD对象
读取文件转RDD对象
12.3、数据计算
map方法
flatMap方法
reduceByKey方法
filter方法
distainct方法
sortBy方法
12.4、数据输出
collect方法
take方法
count方法
七、函数进阶
7.1、函数多返回值
如果一个函数要有多个返回值,该如何书写代码?
def test_return():
return 1, 2
x, y = test_return()
print(x) # 1
print(y) # 2按照返回值的顺序,写对应顺序的多个变量接收即可。
变量之间用逗号隔开。
支持不同类型的数据return。
7.2、函数多种传参方式
位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数。
def user_info(name, age, gender):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
user_info('TOM', 30, '男')注意:传递的参数和定义的参数的顺序及个数必须一致。
关键字参数
关键字参数:函数调用时通过“键=值”形式传递参数。
作用:可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。
def user_info(name, age, gender):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
user_info(gender='男', name='Jerry', age=20)注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
缺省参数
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
作用:当调用函数时没有传递参数, 就会使用默认是用缺省参数对应的值.
def user_info(name, age, gender='男'):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
user_info(name='Jerry', age=20) # 您的名字是Jerry,年龄是20,性别是男注意:函数调用时,如果为缺省参数传值则修改默认参数值, 否则使用这个默认值。
不定长参数
不定长参数:不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。
作用:当调用函数时不确定参数个数时, 可以使用不定长参数。
不定长参数的类型:
①位置传递
②关键字传递
位置传递
def user_info(*args):
print(args)
user_info('TOM', 20) # ('TOM', 20)注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递。
关键字传递
def user_info(**kwargs):
print(kwargs)
user_info(name='TOM', age=20, school='哈尔滨工业大学') # {'name': 'TOM', 'age': 20, 'school': '哈尔滨工业大学'}注意:参数是“键=值”形式的形式的情况下,所有的“键=值”都会被kwargs接受,同时会根据“键=值”组成字典。
7.3、匿名函数
函数作为参数传递
在前面的函数学习中,我们一直使用的函数,都是接受数据作为参数传入: 数字 字符串 字典、列表、元组等。其实,我们学习的函数本身,也可以作为参数传入另一个函数内。
def compute(x, y):
return x + y
def test_func(compute):
result = compute(1, 2)
print(result)
test_func(compute) # 3lambda匿名函数
函数的定义中:
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用。
无名称的匿名函数,只可临时使用一次。
匿名函数定义语法:
lambda 传入参数:函数体(一行代码)lambda 是关键字,表示定义匿名函数。
传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数。
函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码。
正常写法:
def compute(x, y):
return x + y
def test_func(compute):
result = compute(1, 2)
print(result)
test_func(compute) # 3lambda匿名写法:
def test_func(compute):
result = compute(1, 2)
print(result)
test_func(lambda x,y:x+y) # 3八、文件操作
8.1、文件的读取
想想我们平常对文件的基本操作,大概可以分为三个步骤(简称文件操作三步走):
① 打开文件
② 读写文件
③ 关闭文件
open()打开函数
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
open(name, mode, encoding)name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
示例代码:
f = open('python.txt', 'r', encoding=”UTF-8)注意:encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定。
mode常用的三种基础访问模式
| 模式 | 描述 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。 如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。 如果该文件不存在,创建新文件进行写入。 |
读操作相关方法
read()方法
文件对象.read(num)num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
readlines()方法
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
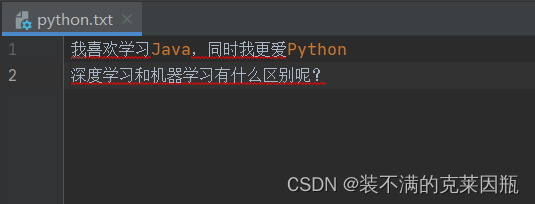
f = open('python.txt', 'r', encoding='UTF-8')
content = f.readlines()
print(content) # ['我喜欢学习Java,同时我更爱Python']
# 关闭文件
f.close()readline()方法
一次读取一行内容。
f = open('python.txt', 'r', encoding='UTF-8')
content = f.readline()
print(content) # 我喜欢学习Java,同时我更爱Python
content = f.readline()
print(content) # 深度学习和机器学习有什么区别呢?
# 关闭文件
f.close()for循环读取文件行
for line in open('python.txt', 'r', encoding='UTF-8'):
print(line)
close() 关闭文件对象
f = open("python.txt", "r")
f.close()
# 最后通过close,关闭文件对象,也就是关闭对文件的占用
# 如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用。
8.2、文件的写入
示例代码:
# 打开文件/创建文件
f = open('python1.txt', 'w', encoding='UTF-8')
# 文件写入
f.write('HelloWorld')
# 内容刷新
f.flush()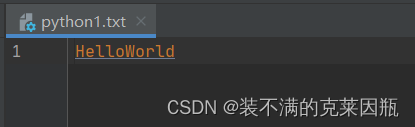
注意:
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区。
- 当调用flush的时候,内容会真正写入文件,这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)。
- 文件如果不存在,使用”w”模式,会创建新文件。
- 文件如果存在,使用”w”模式,会将原有内容清空。
8.3、文件的追加
f = open('python.txt', 'a', encoding='UTF-8')
# 文件追加
f.write('计算机视觉是什么?')
f.flush() 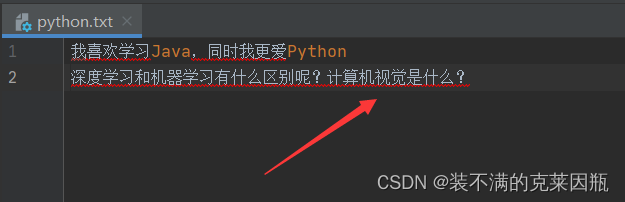
九、异常、模块与包
9.1、什么是异常?
当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”, 也就是我们常说的BUG。
例如:以`r`方式打开一个不存在的文件。
f = open('python222.txt', 'r', encoding='UTF-8')
9.2、异常的捕获方法
当我们的程序遇到了BUG,那么接下来有两种情况:
① 整个程序因为一个BUG停止运行。
② 对BUG进行提醒,整个程序继续运行。
显然在之前的学习中,我们所有的程序遇到BUG就会出现①的这种情况,也就是整个程序直接奔溃。
但是在真实工作中,我们肯定不能因为一个小的BUG就让整个程序全部奔溃,也就是我们希望的是达到②的这种情况,那这里我们就需要使用到捕获异常。
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
捕获常规异常
基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码快速入门
需求:尝试以`r`模式打开文件,如果文件不存在,则以`w`方式打开。
try:
f = open('python.txt', 'r', encoding='UTF-8')
except:
f = open('python.txt', 'w', encoding='UTF-8')捕获指定异常
基本语法:
try:
print(name)
except NameError as e:
print('name变量名称未定义异常')注意事项:
① 如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
② 一般try下方只放一行尝试执行的代码。
捕获多个异常
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except 后,并使用元组的方式进行书写。
基本语法:
try:
print(1/0)
except (NameError, ZeroDivisionError):
print('ZeroDivision错误...')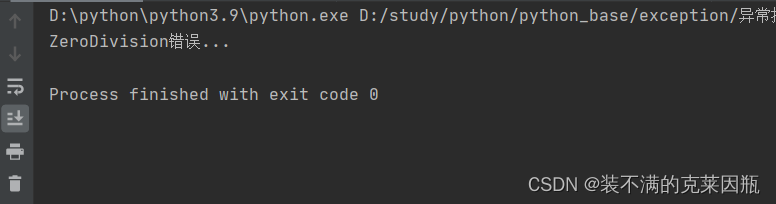
捕获异常并输出描述信息
基本语法:
try:
print(num)
except (NameError, ZeroDivisionError) as e:
print(e)

捕获所有异常
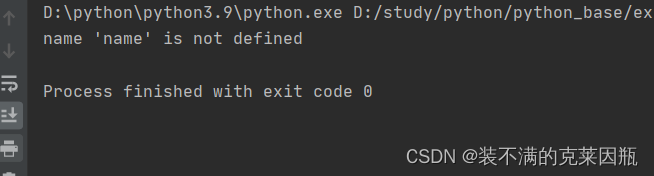
基本语法:
try:
print(name)
except Exception as e:
print(e)
异常else
else表示的是如果没有异常要执行的代码。
try:
print(1)
except Exception as e:
print(e)
else:
print('我是else,是没有异常的时候执行的代码')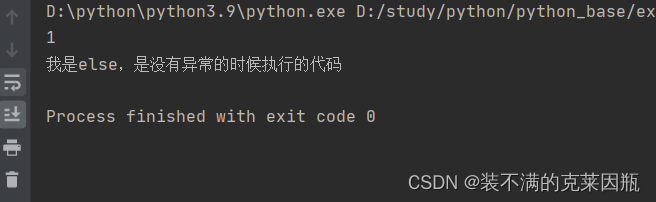
异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件。
try:
f = open('test.txt', 'r')
except Exception as e:
f = open('test.txt', 'w')
else:
print('没有异常,真开心')
finally:
f.close()
9.3、异常的传递
异常是具有传递性的。

当函数func01中发生异常,并且没有捕获处理这个异常的时候,异常会传递到函数func02,当func02也没有捕获处理这个异常的时候,main函数会捕获这个异常,这就是异常的传递性。
提示:当所有函数都没有捕获异常的时候,程序就会报错。
9.4、Python模块
模块的导入
什么是模块?
Python 模块(Module),是一个 Python 文件,以 .py 结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码。
大白话来说,模块就是一个Python文件,里面有类、函数、变量等,我们可以 拿过来用(导入模块去使用)。
模块的导入方式
模块在使用前需要先导入,导入的语法如下:
[from 模块名] import [模块 | 类 | 变量 | 函数 | *] [as 别名]常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
import模块名
基本语法:
import 模块名
import 模块名1,模块名2
模块名.功能名()
示例代码:导入time模块
import time
print('start')
# 让程序睡眠1秒
time.sleep(1)
print('end')
from 模块名 import 功能名
基本语法:
from 模块名 import 功能名
功能名()
示例代码:导入time模块中的sleep方法
from time import sleep
print('start')
# 让程序睡眠1秒
sleep(1)
print('end')from 模块名 import *
基本语法:
from 模块名 import *
功能名()
示例代码:导入time模块中的所有方法
from time import *
print('start')
# 让程序睡眠1秒
sleep(1)
print('end')as定义别名
基本语法:
# 模块定义别名
import 模块名 as 别名
# 功能定义别名
from 模块名 import 功能 as 别名
示例代码:
import time as t
print('start')
# 让程序睡眠1秒
t.sleep(1)
print('end')from time import sleep as s1
print('start')
# 让程序睡眠1秒
s1(1)
print('end')自定义模块
制作自定义模块
Python中已经帮我们实现了很多的模块,不过有时候我们需要一些个性化的模块,这里就可以通过自定义模块实现,也就是自己制作一个模块。
示例代码:新建一个Python文件,命名为my_module1.py,并定义test函数
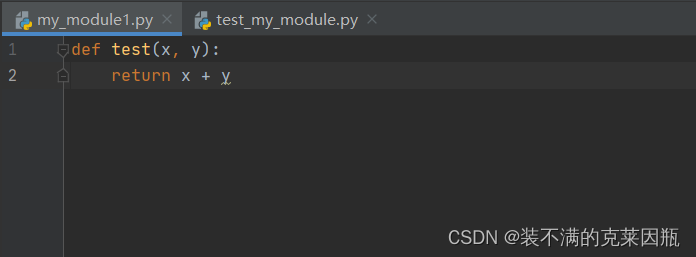

测试模块
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果, 这个开发人员会自行在py文件中添加一些测试信息,例如,在my_module1.py文件中添加测试代码test(1,1)。
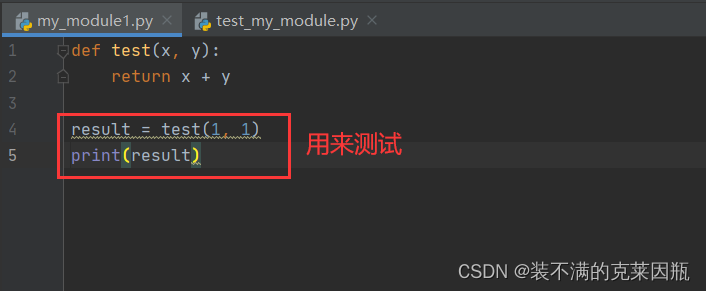
问题:此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行`test`函数的调用。
解决方案: 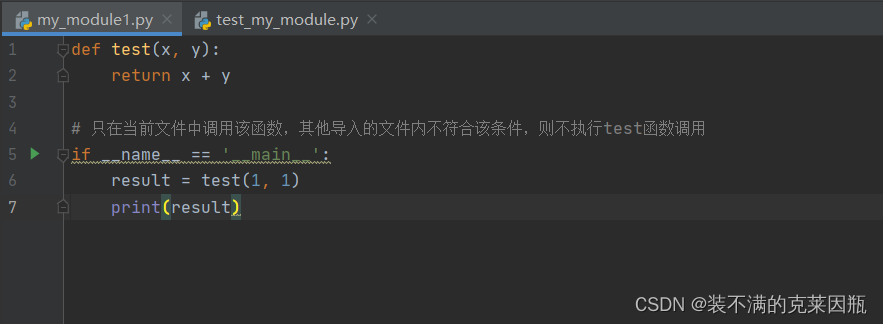
__all__
如果一个模块文件中有`__all__`变量,当使用`from xxx import *`导入时,只能导入这个列表中的元素。
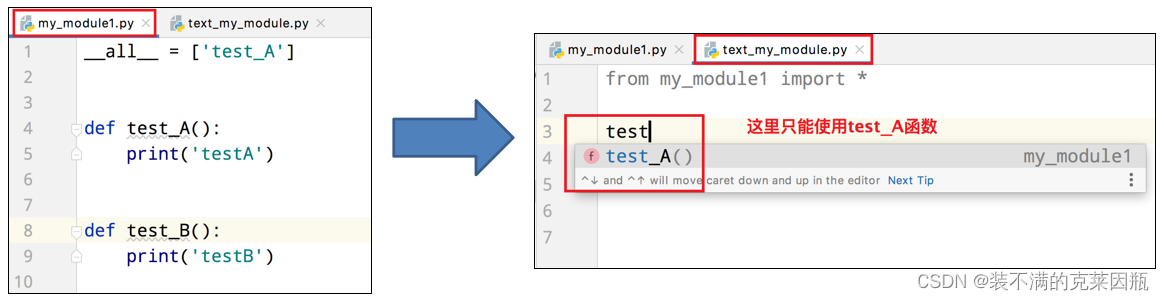
9.5、Python包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 __init__.py 文件,该文件夹可用于包含多个模块文件。
从逻辑上看,包的本质依然是模块。
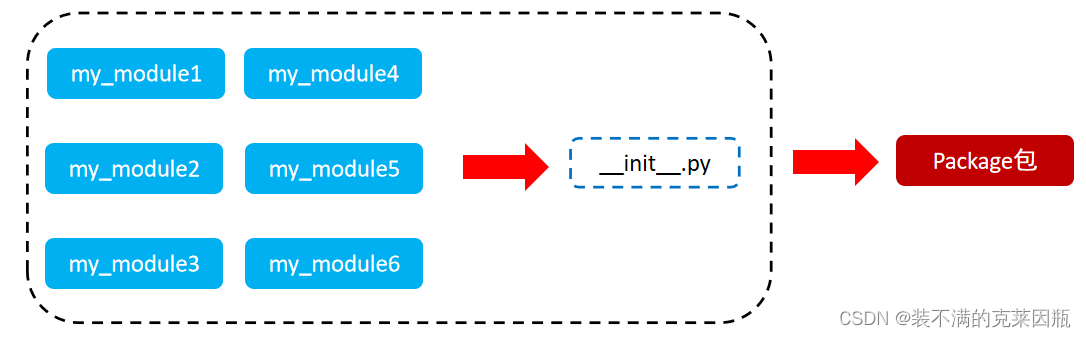
包的作用:当我们的模块文件越来越多时,包可以帮助我们管理这些模块,包的作用就是包含多个模块,但包的本质依然是模块。
快速入门
步骤如下:
① 新建包`my_package`
② 新建包内模块:`my_module1` 和 `my_module2`
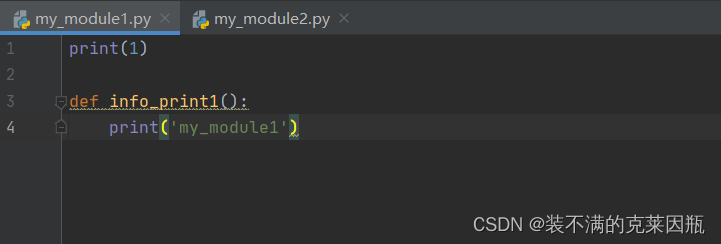
③ 模块内代码如下
示例代码:
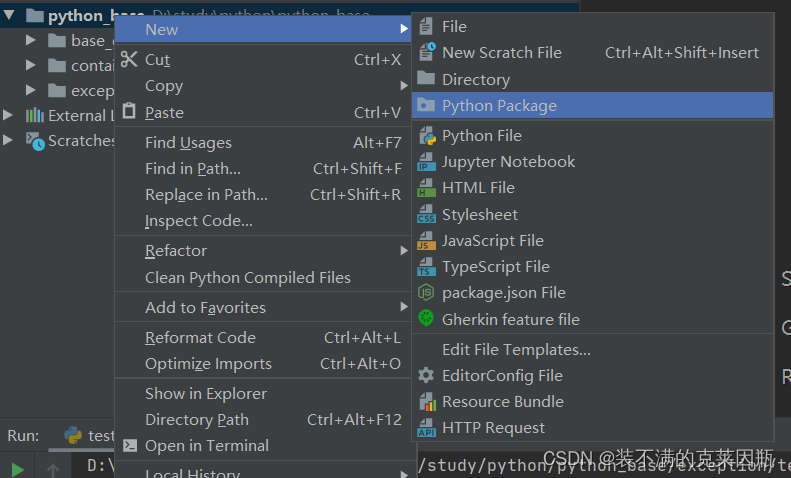
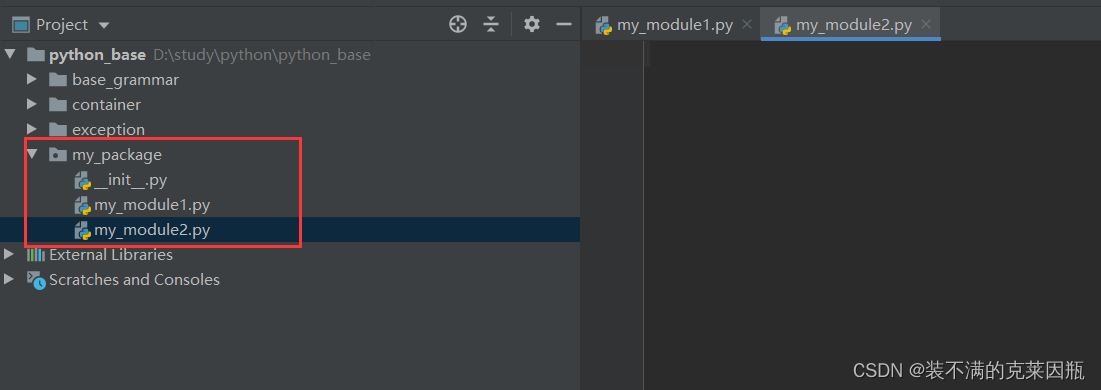
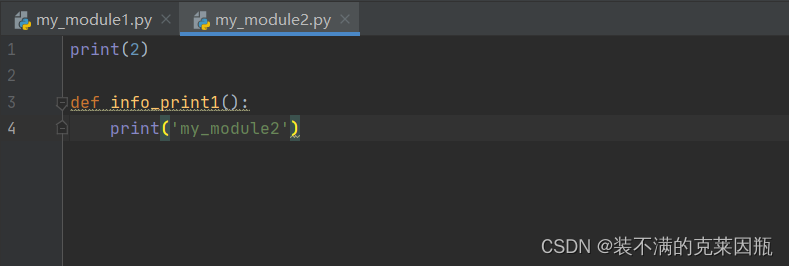
注意:新建包后,包内部会自动创建`__init__.py`文件,这个文件控制着包的导入行为。
导入包
方式一
import 包名.模块名
包名.模块名.目标
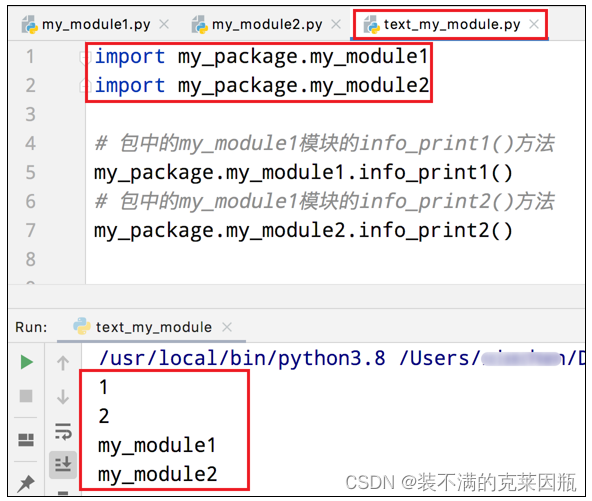
方式二
注意:必须在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表。
from 包名 import *
模块名.目标
安装第三方包
安装第三方包 - pip
第三方包的安装非常简单,我们只需要使用Python内置的pip程序即可。
打开我们许久未见的:命令提示符程序,在里面输入:
pip install 包名称即可通过网络快速安装第三方包。
pip的网络优化
由于pip是连接的国外的网站进行包的下载,所以有的时候会速度很慢。
我们可以通过如下命令,让其连接国内的网站进行包的安装:
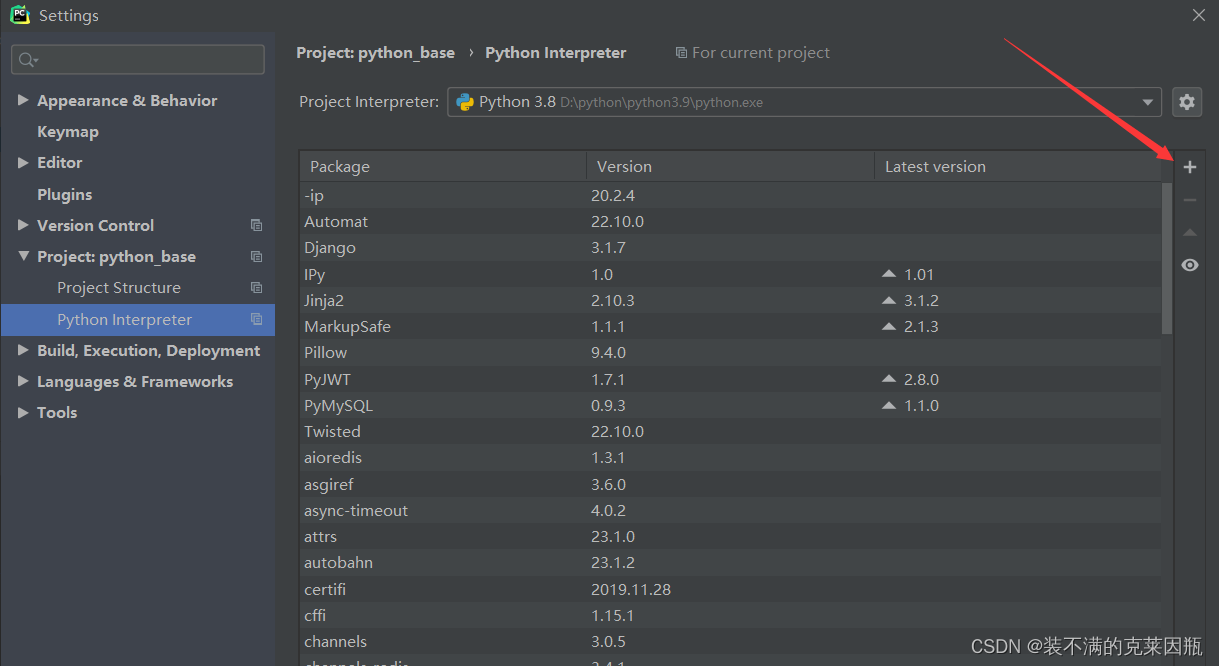
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称安装第三方包 - PyCharm

9.6、JSON运用
"""
演示JSON数据和Python字典的相互转换
"""
import json
# json数据
data = [{'name': '米米', 'age': 18}, {'name': '豆豆', 'age': 23}]
# 将JSON对象转为JSON字符串
json_str = json.dumps(data, ensure_ascii=False)
print(json_str) # [{"name": "米米", "age": 18}, {"name": "豆豆", "age": 23}]
# 将JSON字符串转为JSON对象
data = json.loads(json_str)
print(data) # [{"name": "米米", "age": 18}, {"name": "豆豆", "age": 23}]十、面向对象
10.1、初始对象
什么是对象呢?其实用白话来解释很简单,就是我们日常生活中的人、动物、植物,甚至是桌椅板凳都是对象。
10.2、成员方法
什么是类?
我们上面讲过对象是什么,那类其实就是对象的模板,你想象一下,假如你是女娲,你在造每个人的时候是不是要设置个模板,比如你是眼睛大,厚嘴唇,那就设置一个眼睛大,厚嘴唇的类,然后通过类可以创建无数个对象,这些对象的特征都是眼睛大,厚嘴唇。
语法:
class 类名称:
类的属性
类的行为class是关键字,表示要定义类了。
类的属性,即定义在类中的变量(成员变量)。
类的行为,即定义在类中的函数(成员方法)。
创建类对象的语法:
对象 = 类名称()
成员变量和成员方法
那么,什么是类的行为(方法)呢?
比如我们现在是女娲,我要造一个人,这个人具有学习的行为,那么在造人之前我先设定好模板。
# Person类
class Person:
name = None
age = None
def study(self):
print(f'我是{self.name},我具有学习的能力')设定好模板后,我们创建对象,注意,这时才开始创建真正的人。
stu = Person() # 创建人的对象
stu.name = '荀彧'
stu.age = 60
stu.study()可以看出,类中:
- 不仅可以定义属性用来记录数据
- 也可以定义函数,用来记录行为
其中:
- 类中定义的属性(变量),我们称之为:成员变量
- 类中定义的行为(函数),我们称之为:成员方法
成员方法的定义语法
在类中定义成员方法和定义函数基本一致,但仍有细微区别:
def 方法名(self, 参数1...参数n):
方法体可以看到,在方法定义的参数列表中,有一个:self关键字
self关键字是成员方法定义的时候,必须填写的。
- 它用来表示类对象自身的意思。
- 当我们使用类对象调用方法的是,self会自动被python传入。
- 在方法内部,想要访问类的成员变量,必须使用self。
class Person:
name = None
age = None
def study(self):
print(f'我是{self.name},我具有学习的能力')注意:self关键字,尽管在参数列表中,但是传参的时候可以忽略它。self是透明的,可以不用理会它。
10.3、构造方法
Python类可以使用:__init__()方法,称之为构造方法。
可以实现:
- 在创建类对象(构造类)的时候,会自动执行。
- 在创建类对象(构造类)的时候,将传入参数自动传递给__init__方法使用。
class Person:
name = None
age = None
school = None
# 构造方法
def __init__(self, name, age, school):
self.name = name
self.age = age
self.school = school
print('构造方法执行了')
p = Person('装不满的克莱因瓶', 27, '哈工大')
print(p.name)
print(p.age)
print(p.school)10.4、其它内置方法
魔术方法
上文学习的__init__ 构造方法,是Python类内置的方法之一。
这些内置的类方法,各自有各自特殊的功能,这些内置方法我们称之为:魔术方法
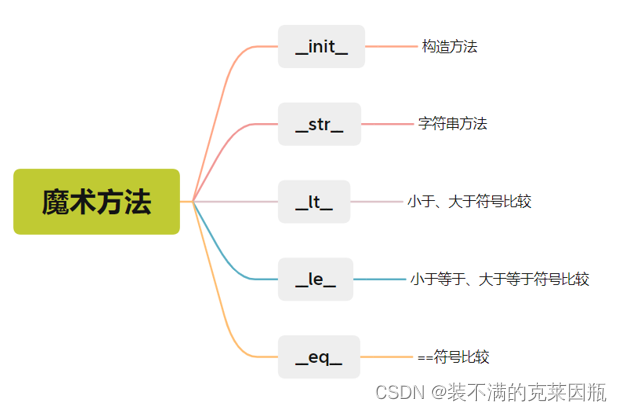
__str__ 字符串方法
先看一段代码,我们试着打印一下对象。
class Person:
name = None
age = None
school = None
def __init__(self, name, age, school):
self.name = name
self.age = age
self.school = school
p = Person('装不满的克莱因瓶', 27, '哈工大')
print(p) # <__main__.Person object at 0x000002625D84B9A0>打印的是一串我们看不懂的东西,其实它是对象的内存地址。
内存地址没有多大作用,我们可以通过__str__方法,控制类转换为字符串的行为。
class Person:
name = None
age = None
school = None
def __init__(self, name, age, school):
self.name = name
self.age = age
self.school = school
def __str__(self):
return f"name={self.name},age={self.age},school={self.school}"
p = Person('装不满的克莱因瓶', 27, '哈工大')
print(p) # name=装不满的克莱因瓶,age=27,school=哈工大
__lt__ 小于符号比较方法
class Person:
name = None
age = None
school = None
def __init__(self, name, age, school):
self.name = name
self.age = age
self.school = school
def __str__(self):
return f"name={self.name},age={self.age},school={self.school}"
def __lt__(self, other):
return self.age < other.age
p1 = Person('装不满的克莱因瓶', 27, '哈工大')
p2 = Person('小小康', 20, '北京理工大学')
print(p1 < p2) # False__le__ 小于等于比较符号方法
class Person:
name = None
age = None
school = None
def __init__(self, name, age, school):
self.name = name
self.age = age
self.school = school
def __str__(self):
return f"name={self.name},age={self.age},school={self.school}"
def __le__(self, other):
return self.age <= other.age
p1 = Person('装不满的克莱因瓶', 27, '哈工大')
p2 = Person('小小康', 20, '北京理工大学')
print(p1 <= p2) # False__eq__比较运算符实现方法
class Person:
name = None
age = None
school = None
def __init__(self, name, age, school):
self.name = name
self.age = age
self.school = school
def __str__(self):
return f"name={self.name},age={self.age},school={self.school}"
def __eq__(self, other):
return self.name == other.name
p1 = Person('装不满的克莱因瓶', 27, '哈工大')
p2 = Person('装不满的克莱因瓶', 20, '北京理工大学')
print(p1 == p2) # True不实现__eq__方法的话,对象之间可以比较,但是是比较内存地址,也即是:不同对象==比较一定是False结果。
实现了__eq__方法,就可以按照自己的想法来决定2个对象是否相等了。
10.5、封装
面向对象的三大特性
面向对象包含3大主要特性:
- 封装
- 继承
- 多态
封装表示的是,将现实世界事物的:属性,行为。封装到类中,描述为: 成员变量,成员方法。从而完成程序对现实世界事物的描述。
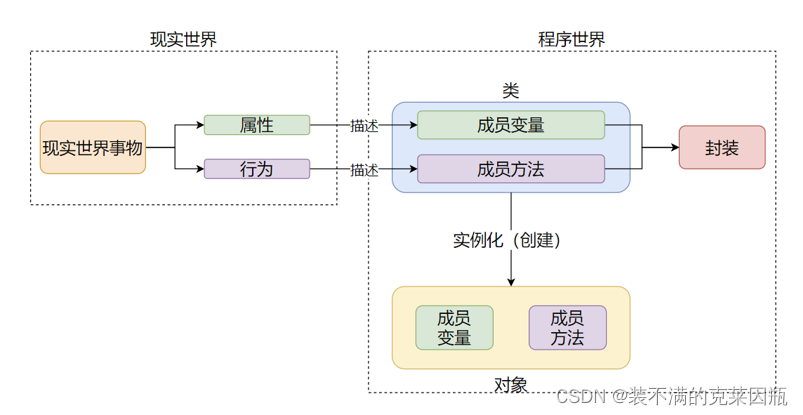
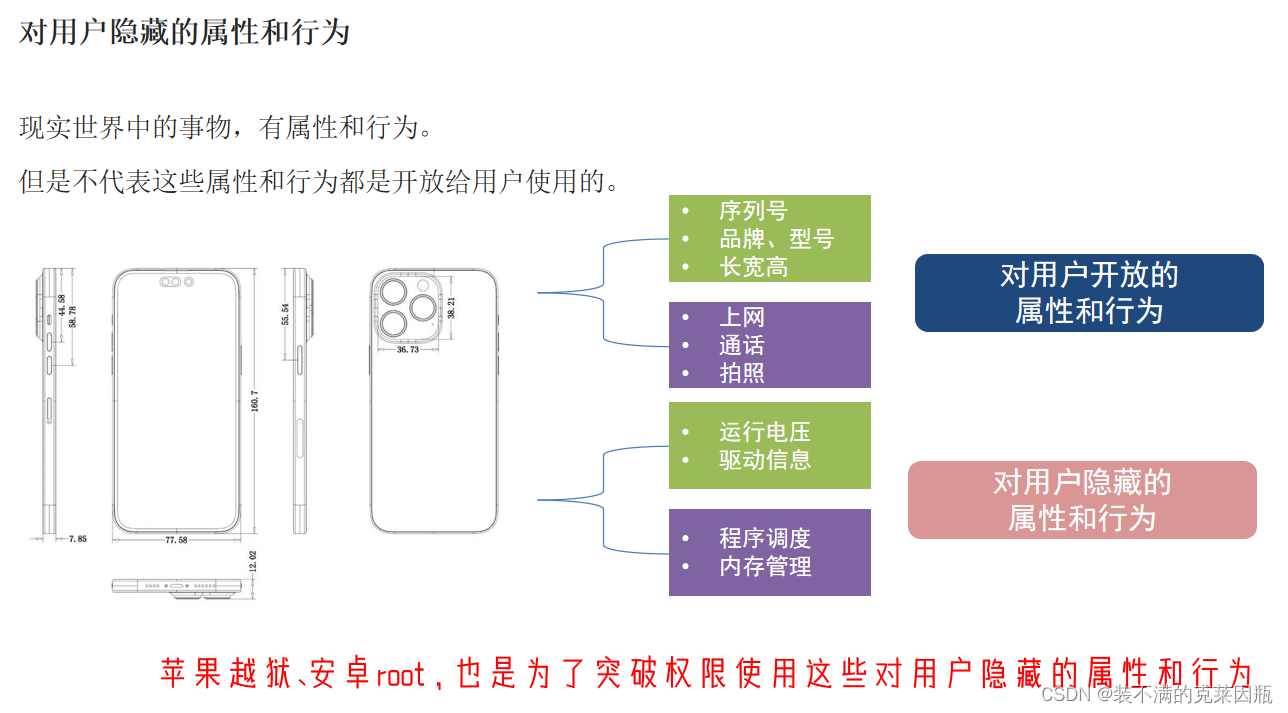
私有成员
既然现实事物有不公开的属性和行为,那么作为现实事物在程序中映射的类,也应该支持。
类中提供了私有成员的形式来支持:
- 私有成员变量
- 私有成员方法
定义私有成员的方式非常简单,只需要:
- 私有成员变量:变量名以__开头(2个下划线)
- 私有成员方法:方法名以__开头(2个下划线)
即可完成私有成员的设置
class Person:
name = None
age = None
__school = None # 私有成员变量
def study(self):
print('学习')
def __read(self): # 私有成员方法
print('阅读')私有成员无法被类对象使用,但是可以被其它的成员使用。
class Person:
name = None
age = None
__school = None # 私有成员变量
def study(self):
self.__read()
print(self.__school)
print('学习')
def __read(self): # 私有成员方法
print('阅读')
p = Person()
p.study()10.6、继承

单继承
语法:
class 类名(父类名):
类内容体继承表示:将从父类那里继承(复制)来成员变量和成员方法(不含私有)。
示例代码:
class Father:
name = '曹操'
def study(self):
print(f'{self.name}会学习')
class Son(Father):
name = '曹植'
def play(self):
print(f'{self.name}会玩')
son = Son()
print(son.name)
son.study()
son.play()
多继承
Python的类之间也支持多继承,即一个类,可以继承多个父类。
语法:
class 类名(父类1,父类2,.....,父类N):
类内容体调用父类同名成员
一旦复写父类成员,那么类对象调用成员的时候,就会调用复写后的新成员。也就是上面的例子,父类有属性叫name,子类也有属性叫name,那调用name属性的时候,肯定是调用的子类的name属性。
如果需要使用被复写的父类的成员,需要特殊的调用方式:
方式1: 调用父类成员
- 使用成员变量:父类名.成员变量
- 使用成员方法:父类名.成员方法(self)
方式2: 使用super()调用父类成员
- 使用成员变量:super().成员变量
- 使用成员方法:super().成员方法()
10.7、类型注解
变量的类型注解
Python在3.5版本的时候引入了类型注解,以方便静态类型检查工具,IDE等第三方工具。
类型注解:在代码中涉及数据交互的地方,提供数据类型的注解(显式的说明)。
主要功能:
- 帮助第三方IDE工具(如PyCharm)对代码进行类型推断,协助做代码提示。
- 帮助开发者自身对变量进行类型注释
基础数据类型注解
var_1: int = 0
var_2: float = 3.14
var_3: bool = True
var_4: str = "Python"类对象类型注解
class Student:
pass
stu: Student = Student()基础容器类型注解
my_list: list = [1, 2, 3]
my_tuple: tuple = (1, 2, 3)
my_set: set = {1, 2, 3}
my_dict: dict = {'name', 'CLAY'}
my_str: str = 'CLAY'容器类型详细注解
my_list: list[int] = [1, 2, 3]
my_tuple: tuple[str, int, bool] = ('CLAY', 1, True)
my_set: set[int] = {1, 2, 3}
my_dict: dict[str, int] = {'age', 20}类型注解的语法
除了使用 变量: 类型, 这种语法做注解外,也可以在注释中进行类型注解。 、
语法: # type: 类型
class Student:
pass
import random
var_1 = random.randint(1, 10) # type: int函数(方法)的类型注解
形参注解
语法:
def 函数方法名(形参名: 类型, 形参名: 类型, ......):
pass
返回值注解
语法:
def 函数方法名(形参名: 类型, 形参名: 类型, ......) -> 返回值类型:
pass示例代码:
def add(x: int, y:int) -> int:
return x + yunion类型
有种情况,比如dict中,我要求限制类型,key是str,但value可以是int或者str,如何做?
from typing import Union
my_dict: dict[str: Union[str, int]] = {'name': 'CLAY', 'age': 10}Union联合类型注解,在变量注解、函数(方法)形参和返回值注解中,均可使用。
from typing import Union
def func(data: Union[int, str]) -> Union[int, str]:
pass10.8、多态
什么是多态?
多态,指的是:多种状态,即完成某个行为时,使用不同的对象会得到不同的状态。

同样的行为(函数),传入不同的对象,得到不同的状态。
抽象类(接口)


十一、操作SQL
11.1、基本操作
第一步:安装pymysql
pip install pymysql第二步:创建到MySQL的数据库链接
from pymysql import Connection
# 获取到Mysql数据库的链接对象
conn = Connection(
host='localhost',
port=3306,
user='root',
password='root'
)
# 打印Mysql数据库软件信息
print(conn.get_server_info())
conn.close()第三步:执行SQL语句
from pymysql import Connection
# 获取到Mysql数据库的链接对象
conn = Connection(
host='localhost',
port=3306,
user='root',
password='root'
)
# 获取游标对象
cursor = conn.cursor()
# 选择test数据库
conn.select_db('test')
# 执行SQL语句
cursor.execute("create table test_pymsql(id int, info varchar(255))")
conn.close()
11.2、插入数据
from pymysql import Connection
# 获取到Mysql数据库的链接对象
conn = Connection(
host='localhost',
port=3306,
user='root',
password='root',
autocommit=True # 设置事务自动提交
)
# 获取游标对象
cursor = conn.cursor()
# 选择test数据库
conn.select_db('test')
# 执行SQL语句
cursor.execute("insert into test_pymsql values(1, '随便写点什么')")
conn.close()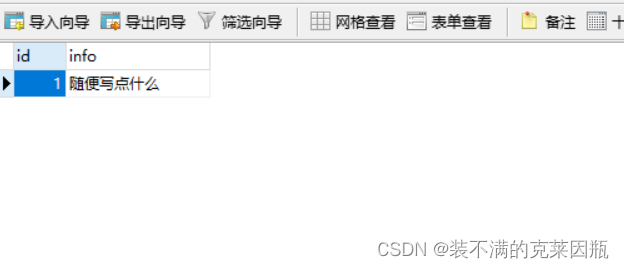
11.3、查询数据
from pymysql import Connection
# 获取到Mysql数据库的链接对象
conn = Connection(
host='localhost',
port=3306,
user='root',
password='root',
autocommit=True # 设置事务自动提交
)
# 获取游标对象
cursor = conn.cursor()
# 选择test数据库
conn.select_db('test')
# 执行SQL语句
cursor.execute("select * from test_pymsql")
# 获取查询结果
results: tuple = cursor.fetchall()
for r in results:
print(r)
conn.close()
十二、PySpark

咱们这里就是把它当做一个第三方库来使用,用做数据处理。
12.1基础准备
PySpark库的安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark构建PySpark执行环境入口对象
from pyspark import SparkConf, SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
# 打印PySpark的运行版本
print(sc.version)
sc.stop()
12.2、数据输入
RDD对象
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
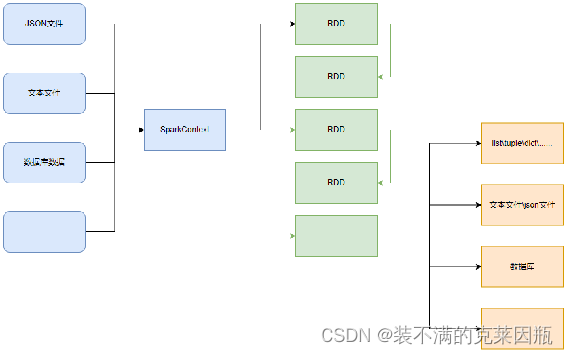
PySpark的编程模型(左图)可以归纳为:
- 准备数据到RDD -> RDD迭代计算 -> RDD导出为list、文本文件等
- 即:源数据 -> RDD -> 结果数据
Python数据容器转RDD对象
PySpark支持通过SparkContext对象的parallelize成员方法,将:
- list
- tuple
- set
- dict
- str
转换为PySpark的RDD对象。
注意:
- 字符串会被拆分出1个个的字符,存入RDD对象
- 字典仅有key会被存入RDD对象
from pyspark import SparkConf, SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("abcdefg")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1": "value1", "key2": "value2"})
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
sc.stop()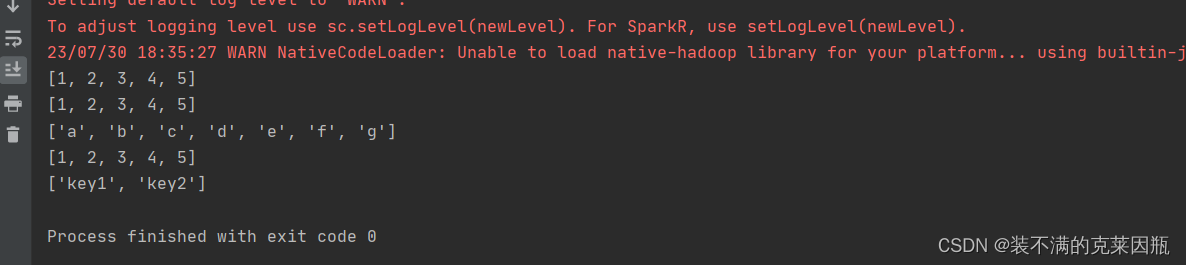
读取文件转RDD对象
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。
比如在当前目录下,我们创建一个hello.txt文件。

from pyspark import SparkConf, SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
rdd = sc.textFile('hello.txt')
print(rdd.collect())
sc.stop()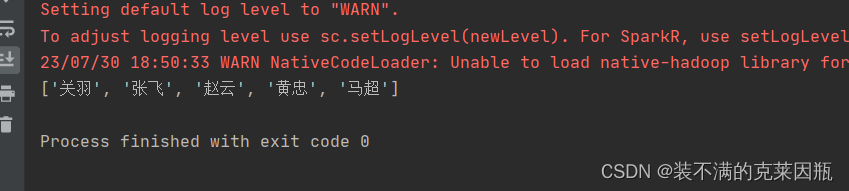
12.3、数据计算
map方法
示例代码:将list里面元素都乘以10
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python3.9/python.exe"
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 通过map方法将全部数据都乘以10
def func(data):
return data * 10
rdd2 = rdd.map(func())
print(rdd2.collect()) # [10, 20, 30, 40, 50]
sc.stop()或者用lambda实现:
rdd2 = rdd.map(lambda x: x * 10)flatMap方法
功能:对rdd执行map操作,然后进行解除嵌套操作。

示例代码:
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python3.9/python.exe"
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize(['赵云 典韦 程普', '关羽 张辽 太史慈', '张飞 许褚 黄盖'])
# 需求:将rdd数据里面的一个个人名提取出来
rdd2 = rdd.flatMap(lambda x: x.split(" "))
print(rdd2.collect()) # ['赵云', '典韦', '程普', '关羽', '张辽', '太史慈', '张飞', '许褚', '黄盖']
sc.stop()这是采用flatMap实现,其实也可以使用map方法,但效果却不同,如:
当我把代码改为:
# 需求:将rdd数据里面的一个个人名提取出来
rdd2 = rdd.map(lambda x: x.split(" "))结果就变成了:
[['赵云', '典韦', '程普'], ['关羽', '张辽', '太史慈'], ['张飞', '许褚', '黄盖']]虽然也能实现,但没有解除嵌套。
reduceByKey方法
功能:针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作。
白话讲其实就相当于mysql的group by操作,按key进行分组,然后你可以传入逻辑,比如同组的值相加等操作。
示例代码:
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python3.9/python.exe"
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
# 需求:分别统计男生总分和女生总分
rdd = sc.parallelize([('男', 99), ('男', 88), ('女', 75), ('女', 56)])
# 需求:将rdd数据里面的一个个人名提取出来
rdd2 = rdd.reduceByKey(lambda a, b: a + b)
print(rdd2.collect()) # [('男', 187), ('女', 131)]
sc.stop()filter方法
功能:过滤想要的数据进行保留。
示例代码:保留偶数
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python3.9/python.exe"
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
# 需求:保留偶数
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = rdd.filter(lambda num: num % 2 == 0)
print(rdd2.collect()) # [2, 4]
sc.stop()distainct方法
功能:对rdd数据进行去重操作,返回新rdd。
示例代码:
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python3.9/python.exe"
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
# 需求:去重
rdd = sc.parallelize([1, 2, 3, 4, 5, 1, 2, 4])
rdd2 = rdd.distinct()
print(rdd2.collect()) # [1, 2, 3, 4, 5]
sc.stop()sortBy方法
功能:对rdd数据进行排序,基于你指定的排序依据。
语法:
rdd.sortBy(func, ascending=False, numPartitions=1)
# ascending:True升序 False降序
# numPartitions:用多少分区排序12.4、数据输出
collect方法
功能:将rdd各个分区内的数据,统一收集到Driver中,形成一个List对象。
用法:
rdd.collect()返回值是一个list。
take方法
功能:取rdd的前N个元素,组合成list返回给你。
rdd = sc.parallelize([1, 2, 3, 4, 5])
take_list = rdd.take(3)
print(take_list) # [1, 2, 3]count方法
功能:计算rdd有多少条数据,返回值是一个数字。
rdd = sc.parallelize([1, 2, 3, 4, 5])
count = rdd.count()
print(count) # 5到此,Python全部更新完成,欢迎小伙伴们点赞收藏关注,感谢!!!
Python基础入门教程(上)