一.引言
LLM model 类 generate 支持传递 num_return_sequences 进行批量生成,下面简单介绍下原始模型 generate 和 lora 模型 generate 的代码并给出基于 Baichuan-7B 和 ChatGLM 的批量预测效率。
二.generate 参数
介绍 batch generate 之前,先熟悉下 generate 的几个参数。
◆ input_ids
输入的 token 序列索引,它是将输入文本转换为模型可理解的数值表示的结果,generate 会根据该 ids 进行后续的 generate,生成后通过 tokenizer 进行反 token 即可得到文本结果。
◆ max_length
生成文本的最大长度限制。
◆ temperature
控制生成的随机性,较高的值会产生更多样化的输出。
◆ top_k
控制模型生成过程中考虑的词汇范围,只从概率最高的 k 个候选词中选择。
◆ top_p
控制模型生成过程中考虑的词汇范围,使用累计概率选择候选词,知道累计概率超过给定的阈值。该参数也可以控制生成结果的多样性,它基于累积概率选择候选词,直到累计概率超过给定的阈值为止。以下是 top_p 的工作原理:
- 模型为每个候选词生成概率分布,表示该词被选择的可能性
- 按照概率降序对词汇表进行排序
- 从概率最高的词开始累积,直到累积概率超过给定阈值,一般为 0.8、0.9
- 在累积概率超过阈值后,选择此时词汇表中的词为候选词,其余的舍弃
top_p 采样的好处在于根据上下文动态生成结果的多样性,如果上下文的概率分布比较平摊,则更多的词会保留在候选集中,增加多样性;而如果上下文中的概率分布比较尖锐,那么候选集会变小,生成的结果则集中在概率较高的词上。使用较低的阈值会获得相对保守的结果,选择较高的阈值则会产生更多样化的结果。
◆ num_beams
使用 beam search 时同时保留的可能序列的数量。当使用 beam search 束搜索算法进行文本生成时,num_beams 参数用于控制保留可能的序列数量。它决定了在生成过程中多少个假设序列被保留下来。以下是 num_beams 的工作原理:
- 在初始状态下,模型生成一个起始序列
- 每个候选序列都会考虑从当前位置生成的所有可能的下一个词,并计算每个词的概率
- 根据这些概率,根据 beam search 的规则,选择最有可能的 num_beams 个序列作为下一个候选
- 重复上述步骤,知道达到指定的生成长度或满足停止条件
通过使用 beam search,可以生成多个候选序列,每个序列都代表着一种可能的生成结果。num_beams 参数决定了同时保留的候选序列的数量。较大的 num_beams 会产生更多的候选序列,但也会增加计算开销。较小的值可能导致模型陷入局部最优解。
◆ repetition_penalty
repetition_penalty(重复惩罚)是一种技术,用于减少在文本生成过程中出现重复片段的概率。它对之前已经生成的文本进行惩罚,使得模型更倾向于选择新的、不重复的内容。以下是 repetition_penalty 的工作原理:
- 在生成每个新词的候选列表时,模型会计算每个候选词的分数。
- 如果一个候选词已经在之前的生成结果中出现过,并且其重复次数超过了预设的阈值,那么该候选词的分数将被惩罚。
- 惩罚的方式可以是减少候选词的分数,或者增加候选词的成本。这样就降低了模型选择重复词汇的可能性。
- 通过施加重复惩罚,模型被鼓励尝试生成与之前生成内容不同的词汇,从而增加生成结果的多样性和连贯性。
重复惩罚参数的具体取值会影响到模型对重复片段的敏感度。较高的重复惩罚值会更严厉地限制重复内容,有助于产生更多样化的生成结果。较低的重复惩罚值则会允许一定程度的重复。
◆ length_penalty
控制生成结果长度的惩罚或奖励。长度惩罚参数的实际取值会影响到模型对生成结果长度的偏好程度。较高的长度惩罚值会更严厉地限制生成结果的长度,有助于产生更为紧凑的输出。较低的长度惩罚值则会允许生成较长的结果。
◆ no_repeat_ngram_size
防止重复n-gram片段出现在生成结果中。
◆ max_length
用于控制生成文本的最大长度。
◆ max_new_tokens
允许的最大新标记数目。具体而言,"max_new_tokens" 参数控制从模型生成的文本中添加到最终输出中的最大词汇数量。通过设置这个参数,您可以确保生成结果不会过于冗长或超出预期的长度。
◆ do_sample
使用采样策略,当设置 do_sample = True 时,生成过程将采用随机采样策略。在生成每个新词时,模型会根据词汇表中词汇的概率分布进行随机采样,从而选择下一个词。采样的随机性使得生成的文本更加多样化,且可能会产生更为创造性的结果。
◆ num_return_sequences
返回多个生成序列。用于根据给定的 input_ids,一次生成多个候选输出。批量输出就是用该参数控制。
三.batch generate
from peft import PeftModel
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM
import torch
import time
def cost(st, end):
# 转换为 ms
return (end - st) * 1000
# 加载原始 LLM
model_path = "/model/ChatGLM-6B/chatglm-6b/"
device = torch.device(0)
model = AutoModel.from_pretrained(model_path, load_in_8bit=False, trust_remote_code=True).half().to(device)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 原始 LLM 安装上 Lora 模型
lora_model = PeftModel.from_pretrained(model, "weights/simple_test_by_chatglm").half()
print("Warm Up Start...")
inputs = tokenizer("你好" + "\n", return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs, max_new_tokens=512, do_sample=True)
pred = lora_model.generate(**inputs, max_new_tokens=512, do_sample=True)
print("Warm Up End...")
epoch=0
max_epoch = 100
batch_num = 10
ori_all_cost = 0
lora_all_cost = 0
while True:
time_st = time.time()
#inputText = input("请输入信息 [输入'q'退出]\n")
inputText = "请计算:39 * 0 = 什么?"
if inputText == 'q':
print("Exit!")
break
if epoch >= max_epoch:
break
#batch_num = int(input("请输入batch_num\n"))
inputs = tokenizer(inputText + "\n", return_tensors='pt')
inputs = inputs.to('cuda:0')
time_token = time.time()
ori_pred = model.generate(**inputs, max_new_tokens=512, do_sample=True, num_return_sequences=batch_num)
# print("原始输出")
for i in range(len(ori_pred)):
ori_answer = tokenizer.decode(ori_pred.cpu()[i], skip_special_tokens=True)
# print(ori_answer.strip())
time_ori = time.time()
lora_pred = lora_model.generate(**inputs, max_new_tokens=512, do_sample=True, num_return_sequences=batch_num)
# print("Lora输出")
for i in range(len(lora_pred)):
lora_answer = tokenizer.decode(lora_pred.cpu()[i], skip_special_tokens=True)
# print(lora_answer.strip())
time_lora = time.time()
print("Total Cost: %s Token Cost: %s Ori Cost: %s Lora Cost: %s" % (cost(time_st, time_lora), cost(time_st, time_token), cost(time_token, time_ori), cost(time_ori, time_lora)))
ori_all_cost += cost(time_token, time_ori)
lora_all_cost += cost(time_ori, time_lora)
epoch += 1
ori_mean = ori_all_cost / max_epoch
lora_mean = lora_all_cost / max_epoch
print("Total Epoch: %s Batch Num: %s Ori All: %s Lora All: %s Ori Mean: %s Lora Mean: %s" %(str(max_epoch), str(batch_num), str(ori_all_cost), str(lora_all_cost), str(ori_mean), str(lora_mean)))
这里分别加载了原始的 ChatGLM 和 lora 后的 ChatGLM 进行 batch generate 的时间测试。
◆ ChatGLM-bB 不同 Batch 耗时
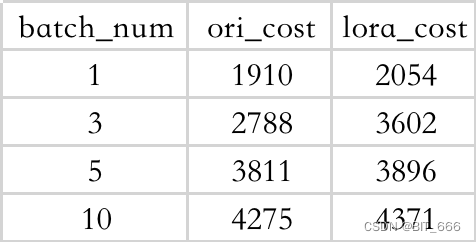
◆ Baichuan-7B 不同 Batch 耗时
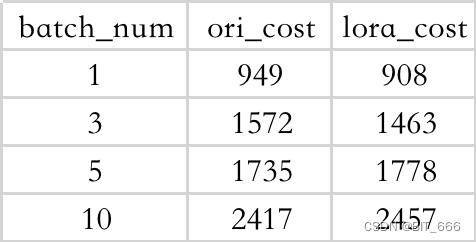
◆ 结论
- 生成多条会带来额外的时间开销,但开销并非线性
- 小模型情况下 lora 预测并不会带来特别大的额外推理开销
四.总结
上面简单测试了 batch generate 的 demo 和效率,除此之外熟悉了 generate 的生成参数,以下参数调整可以控制多样性:
temperature - 越高随机性越强
top_k - 越大多样性越强
top_p - 越高多样性越强
do_sample - True 提高随机性
针对多个控制参数,我们可以统一放到 dict 中,然后 **kwargs 传入 generate:
# Token 生成配置
generation_config = dict(
temperature=0.5,
top_k=30,
top_p=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.3,
max_new_tokens=400
)
... 此处省略模型加载等过程 ...
# 批量生成
pred = model.generate(
input_ids = inputs["input_ids"].to(device),
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
num_return_sequences=batch_num,
**generation_config
)