0 提纲
- 现象与原因
- 非平衡数据处理方法概览
- 数据预处理层面
- 特征层
- 算法层面
1 现象与原因
非平衡数据分类问题:在网络信息安全问题中,诸如恶意软件检测、SQL注入、不良信息检测等许多问题都可以归结为机器学习分类问题。这类机器学习应用问题中,普遍存在非平衡数据的现象。
产生的原因:
- 攻击者的理性特征使得攻击样本不会大规模出现;
- 警惕性高的攻击者,会经常变换攻击方式避免被防御方检测出来。
非平衡数据对各种分类器的影响:
- KNN
- Bayes
- 决策树
- Logistic回归
当用于非平衡数据分类时,为了最大化整个分类系统的分类精度,必然会使得分类模型偏向于多数类,从而造成少数类的分类准确性低。
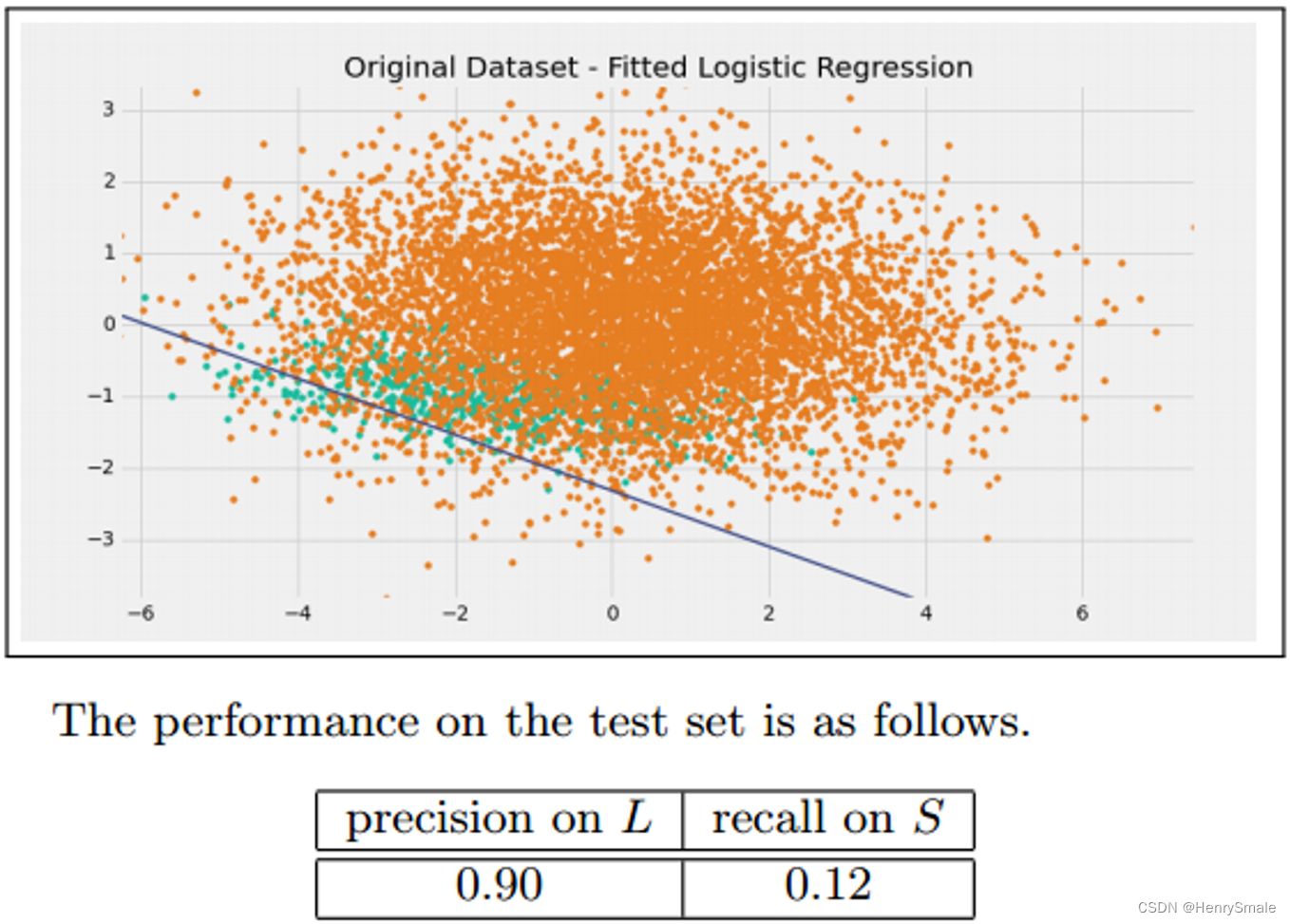
2 非平衡数据处理方法概览
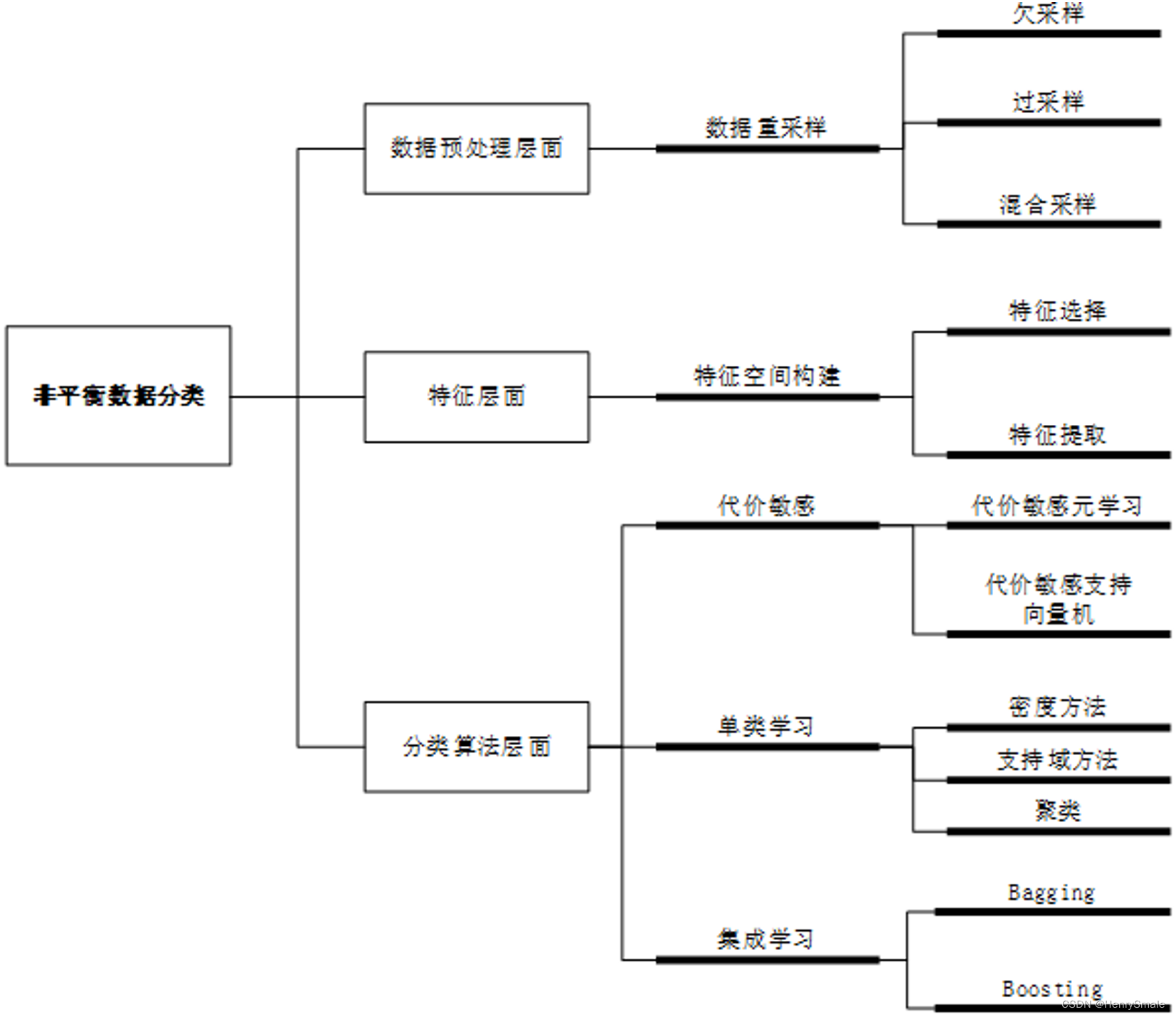
2.1 数据预处理层面
保证样本分布不变的情况下,改变训练集中每个类的样本数量,降低非平衡程度。
- 欠采样:减少多数类的样本数量;
- 过采样:提升少数类的样本数量;
- 混合采样:对多数类和少数类分别执行欠采样和过采样。
2.2 特征层面
虽然样本数量少,但可能在某些特征子空间中,能有效区分少数类样本和多数类样本。利用特征选择或特征提取来确定子空间的构成。
主要特征选择或特征提取有:
- 信息增益;
- 卡方统计;
- 互信息;
- 主成分分析;
- 深度神经网络。
2.3 分类算法层面
虽然采样方法在一些数据集上取得了不错的效果,但欠采样容易剔除重要样本,过采样容易导致过学习,因此,采样方法调整非平衡数据的学习能力十分有限。
传统分类方法通常假设不同类别的样本分布均衡,并且错分代价相等,这种假设并不适合于非平衡数据的情况。因此,在分类模型与算法层面,改变假设前提,设计新的代价函数,提升对少数类样本的识别准确率。
改变代价函数就涉及到代价敏感学习,此外,单类学习和集成学习都可用来解决非平衡分类问题。
3 数据预处理层面
3.1 欠采样
欠抽样方法通过减少多数类样本来提高少数类的分类性能。
常见的欠采样方法有随机欠采样、启发式欠采样等。
- 随机欠采样通过随机地去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类的一些重要信息,不能够充分利用已有的信息。
- 启发式欠采样基本出发点是保留重要样本、有代表性的样本,而这些样本的选择是基于若干启发式规则。经典的欠采样方法是邻域清理(NCL,Neighborhood cleaning rule)和Tome links法,其中NCL包含ENN,典型的有以下若干种。
3.1.1 编辑最近邻规则Edited Nearest Neighbor (ENN)
对于多数类的样本,如果其大部分k近邻样本都跟它自己本身的类别不一样,就将他删除。
也可以从少数类的角度来处理:对于少数类样本,如果其大部分k近邻样本都是少数类,则将其多数类近邻删除。
3.1.2 浓缩最近邻规则Condensed Nearest Neighbor(CNN)
对点进行KNN分类,如果分类错误,则将该点作为少数类样本。在实际运用中,选择比较小的K。
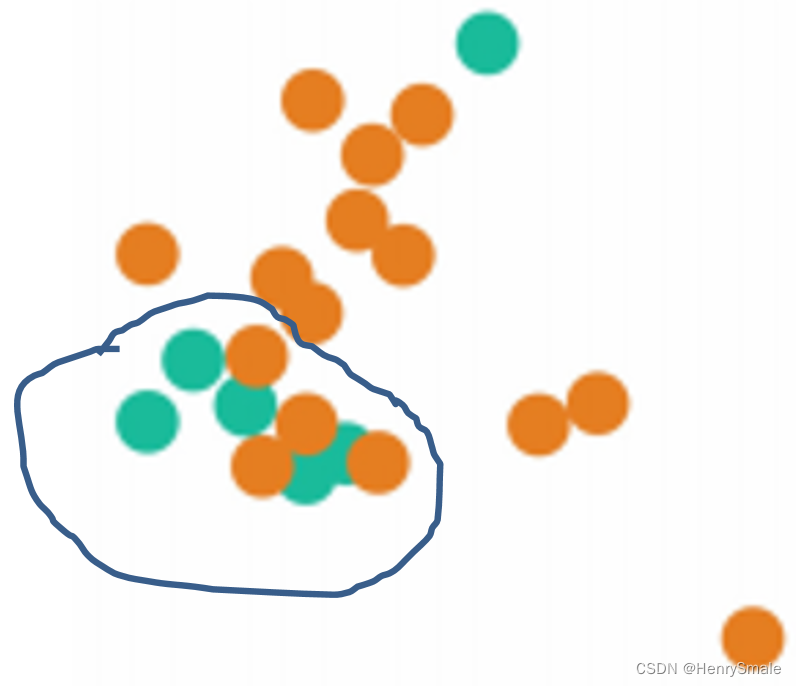
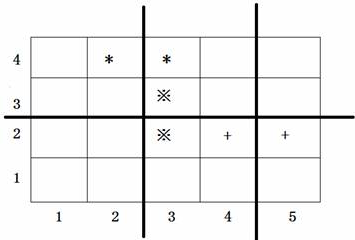
3.1.3 近似缺失方法Near Miss(NM)
- NearMiss-1:对于每个多数类样本,计算其与最近的三个少数类样本的平均距离,选择最小距离对应的多数类样本。
- NearMiss-2:与NearMiss-1相反,计算与最远的三个少数类样本的平均距离,并选择最小距离对应的多数类样本。
- NearMiss-3:对每个少数类样本,选择与之最接近的若干个多数类样本。
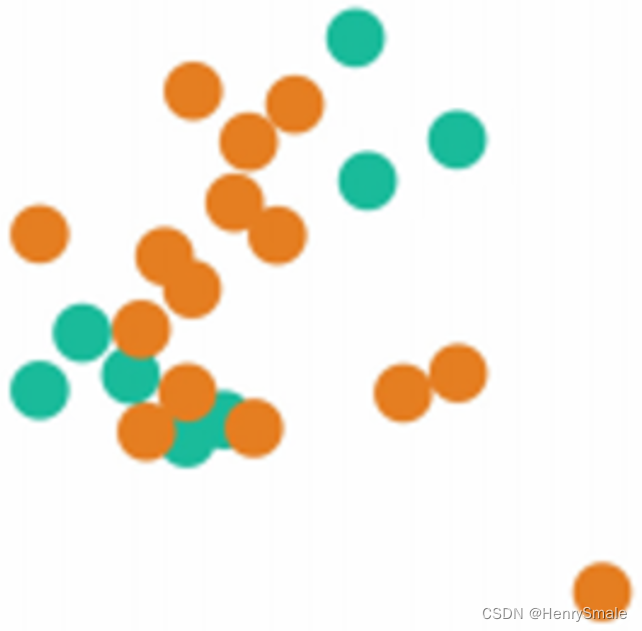
NearMiss-1针对数据分布的局部特征;
NearMiss-2针对数据分布的全局特征;
NearMiss-3倾向于在比较集中的少数类附近找到更多的多数类样本,而在离群的少数类附近找到更少的多数类样本。
3.1.4 Tomek Links方法
如果有两个不同类别的样本,它们的最近邻都是对方,也就是A的最近邻是B,B的最近邻是A,那么A,B就是Tomek link。
数学语言:两个不同类别的样本点 x i x_i xi和 x j x_j xj,它们之间的距离表示为 d ( x i , x j ) d(x_i,x_j) d(xi,xj),如果不存在第三个样本点 x l x_l xl使得 d ( x l , x i ) < d ( x i , x j ) d(x_l,x_i)<d(x_i,x_j) d(xl,xi)<d(xi,xj)或者 d ( x l , x j ) < d ( x i , x j ) d(x_l,x_j)<d(x_i,x_j) d(xl,xj)<d(xi,xj)成立,则称 ( x i , x j ) (x_i,x_j) (x