63. 不同路径 II
文章目录
- [63. 不同路径 II](https://leetcode.cn/problems/unique-paths-ii/)
- 一、题目
- 二、题解
- 方法一:二维数组动态规划
- 方法二:一维数组动态规划
一、题目
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。
示例 1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-np1jHnOF-1690689693410)(D:\A_WHJ\Computer Science\typora图片\robot1.jpg)]](https://img-blog.csdnimg.cn/d7434a899f3541c89c4d05c339c94253.png)
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
1. 向右 -> 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右 -> 向右
示例 2:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cy53IlVH-1690689693411)(D:\A_WHJ\Computer Science\typora图片\robot2.jpg)]](https://img-blog.csdnimg.cn/9e4c73360bfb496d8f2dd3c63c9ffaf0.png)
输入:obstacleGrid = [[0,1],[0,0]]
输出:1
提示:
m == obstacleGrid.lengthn == obstacleGrid[i].length1 <= m, n <= 100obstacleGrid[i][j]为0或1
二、题解
方法一:二维数组动态规划
步骤一:确认dp数组以及下标的含义
- dp[i][j] 表示从起点 (0, 0) 到达网格中第 i 行第 j 列的格子时的不同路径数量。
步骤二:确认递推公式
- 对于非障碍物格子,可以从上方格子和左侧格子到达,因此 dp[i][j] = dp[i-1][j] + dp[i][j-1]。
- 对于障碍物格子,无法到达,路径数量为0,即 dp[i][j] = 0。
步骤三:数组初始化
- 初始化一个二维数组 dp,大小为 m 行 n 列,所有元素初始化为0。
- 如果起点是障碍物,直接返回0,因为无法到达终点。
步骤四:确定遍历顺序
- 首先处理起点的特殊情况,然后分别初始化第一列和第一行,再进行动态规划遍历填充剩余的格子。
步骤五:举例推导dp数组
让我们通过一个示例来推导 dp 数组。假设输入网格 obstacleGrid 为:
[
[0, 0, 0],
[0, 1, 0],
[0, 0, 0]
]
进行推导:
- 初始化 dp 数组:
dp = [
[1, 0, 0],
[0, 0, 0],
[0, 0, 0]
]
- 初始化第一列和第一行:
dp = [
[1, 1, 1],
[1, 0, 0],
[1, 0, 0]
]
- 动态规划遍历填充剩余格子:
dp = [
[1, 1, 1],
[1, 0, 1],
[1, 1, 2]
]
最终返回 dp [m-1] [ n-1 ] 即 dp [2] [2] = 2,表示从起点 (0, 0) 到达终点 (2, 2) 的不同路径数量为 2。
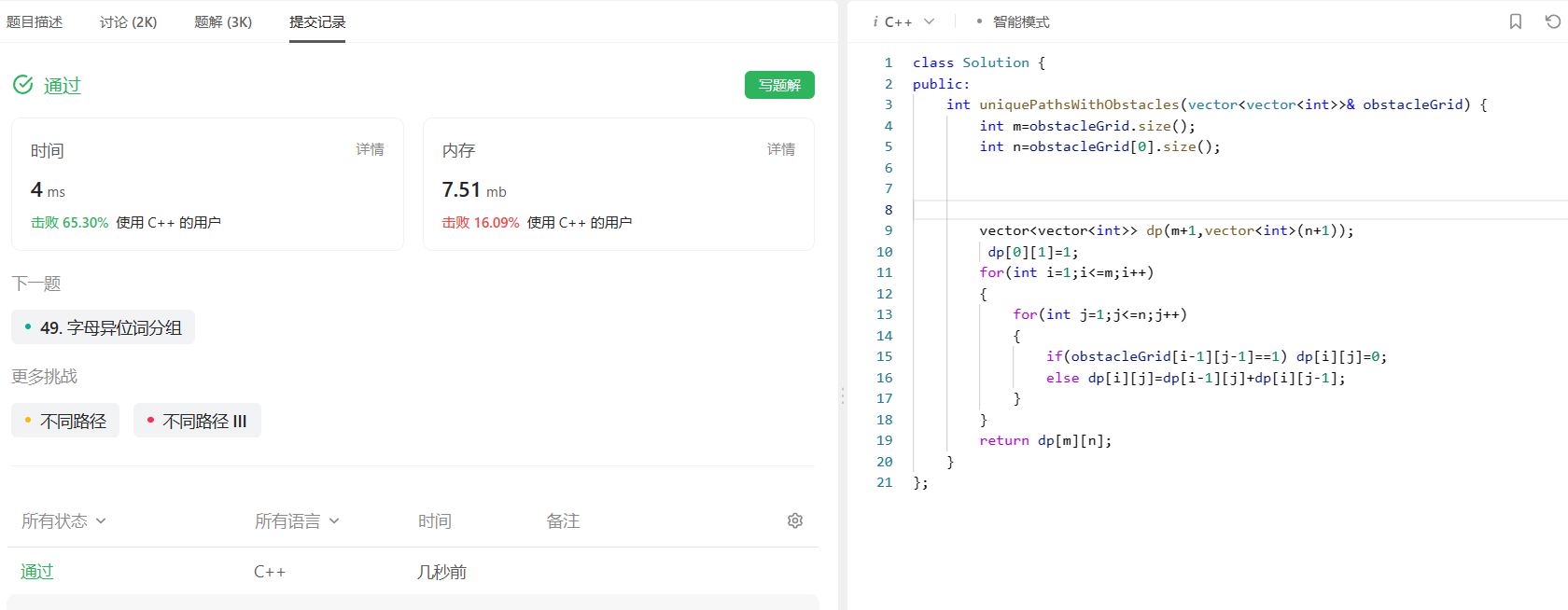
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
vector<vector<int>> dp(m, vector<int>(n, 0));
// 处理起始点为障碍物的情况
if (obstacleGrid[0][0] == 0)
dp[0][0] = 1;
// 初始化第一列,只要遇到障碍物,后面的都不可达
for (int i = 1; i < m; ++i) {
if (obstacleGrid[i][0] == 0){
dp[i][0] = dp[i-1][0];
}else{
break;
}
}
// 初始化第一行,只要遇到障碍物,后面的都不可达
for (int j = 1; j < n; ++j) {
if (obstacleGrid[0][j] == 0){
dp[0][j] = dp[0][j-1];
}else{
break;
}
}
// 动态规划遍历
for (int i = 1; i < m; ++i) {
for (int j = 1; j < n; ++j) {
if (obstacleGrid[i][j] == 0)
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}
};
方法二:一维数组动态规划
先给出代码
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
vector<int> dp(n, 0);
// 初始化边界状态
dp[0] = (obstacleGrid[0][0] == 0) ? 1 : 0;
// 计算dp数组
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (obstacleGrid[i][j] == 1) {
dp[j] = 0;
} else {
if (j > 0) {
dp[j] += dp[j - 1];
}
}
}
}
return dp[n - 1];
}
};
之前我们用一个二维数组dp[i][j]表示从起点到达网格(i, j)位置的不同路径数。假设网格总共有m行、n列,那么起点在dp[0] [0],终点在dp[m-1] [n-1]。那么状态转移方程可以表示为:
dp[i] [j] = dp[i-1] [j] + dp[i] [j-1]
意思是到达当前格子的路径数等于从上方格子和左侧格子的路径数之和。
现在,我们来思考如何用一个一维数组来表示dp数组。注意到,在更新dp[i] [j]时,我们只需要用到上一行dp[i-1] [j]和当前行左侧位置dp[i] [j-1]的值。所以,如果我们用一个一维数组dp[j]来表示当前行的状态,那么在计算dp[i] [j]时,dp[j](下面状态转移方程等号右侧的dp[j],不是左侧)实际上就是上一行的dp[i-1] [j],而dp[j-1]实际上就是当前行左侧位置dp[i] [j-1]。
因此,我们可以将状态转移方程改写为:
dp[j] = dp[j] + dp[j-1]
这里的dp[j]表示当前行到达网格(i, j)位置的不同路径数。
由于我们只需要用到上一行的dp数组和当前行左侧位置的值,所以我们可以用一个一维数组dp来更新当前行的状态,然后逐行向下更新,最终得到最后一行dp数组的值,即为从左上角到右下角的不同路径数。
这是不是一种非常好的改进方法?