在开始之前,先抛出一个问题:我们都知道,目前(MySQL 5.6以上)数据库已普遍使用InnoDB存储引擎,InnoDB相对于MyISAM存储引擎其中一个好处就是在数据库级别锁和表级别锁的基础上支持了行锁,还有就是支持事务,保证一组数据库操作要么成功,要么失败。基于此,问题来了,在InnoDB默认隔离级别(可重复读)下,一个事务想要更新一行数据,如果刚好有另外一个事务拥有这个行锁,那么这个事务就会进入等待状态。既然进入等待状态,那么等到这个事务获取到行锁要更新数据的时候,它读取到的值是什么呢?
具体的问题见下图,我们设定有一张表user,初始化语句如下,试想在这样的场景下,事务A三次查询的值分别是什么?
create table `user` (
`id` bigint not null,
`name` varchar(50) default null,
PROMARY KEY (`id`)
) ENGINE = InnoDB;
insert into user(id,name) values (1,'A');

想要把这件事情回答正确,我们先来铺垫一下基础知识。
提到事务,首先会想到的就是ACID(Atomic原子性、Consist一致性、Isolate隔离性、Durable持久性),今天我们主要关注隔离性,当有多个事务同时执行发生并发时,数据库可能会出现脏读、不可重复读和幻读等问题,为了解决这些问题,“隔离级别”这位大哥上场,包含:读未提交、读已提交、可重复读和串行。
但我们都知道,隔离级别越高,执行效率越低。毕竟大哥就是大哥,级别越高,越谨慎,常在河边走哪能不湿鞋。
我们通过一个例子简单说一下这四种隔离级别:

• 读未提交:一个事务还未提交,它的变更就能被其他事务看到。V1为B,V2为B,V3为B。
• 读已提交:一个事务提交之后,变更结果对其他事务可见。V1为A,V2和V3为B。
• 可重复读:一个事务执行过程中看到的数据与事务启动时一致。V1为A,V2为A,V3为B。
• 串行:不管读和写,加锁就完了,就是干!V1和V2均为A,V3为B。
事务是怎么实现的呢?实际上,事务执行时,数据库会创建一个视图,读未提交直接返回最新值,没有视图概念;串行是直接加锁避免并发访问;读已提交是在每个SQL语句开始执行时创建的视图。可重复读的视图是在事务启动的时候创建的,整个事务都会使用这个视图。这样的话,上面四种不同隔离级别下的V1、V2、V3值便对号入座,有了结果。
MySQL是怎么实现的呢?我们以MySQL默认的可重复读隔离级别为例,实际上每条行记录在更新时都会记录一条回滚日志,也就是大家常说的undo log。通过回滚操作,都可以得到前一个状态的值。假设name值从初始值A被依次更新为B、C、D,我们看一下回滚日志:
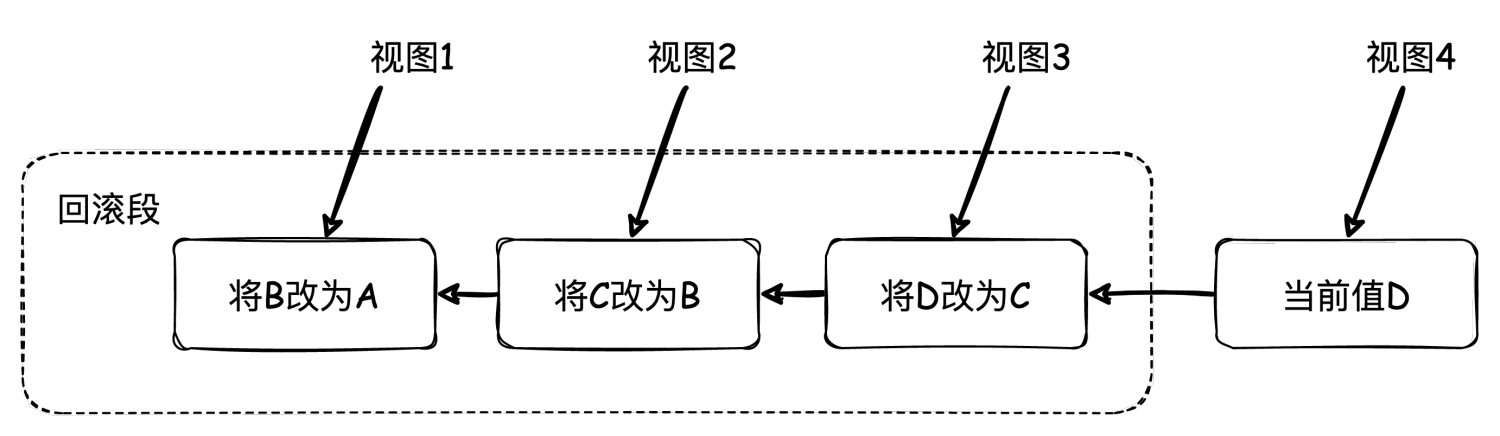
当前值是D,但是在查询这条记录的时候,不同时刻启动的事务会有不同的视图,看到的值也就不一样。在视图1、2、3、4里面,记录的name值分别是A、B、C、D。同一条行记录在数据库中可以存在多个版本,这就是多版本并发控制(MVCC)。对于视图1,如果想要将name值回到A,那么就要依次执行图中所有回滚操作。
到这里,你已经接触到了MVCC的概念,也许你已经对文章最开始的问题有了一点点想法,别着急,我们先来简单总结下MVCC的特点:
MVCC的出现使得一条行记录在不同隔离级别下不同的事务操作会形成一条不同版本的链路,从而实现在不加锁的前提下使不同事务的读写操作能够并发安全执行,这个版本链就是通过回滚日志undo log实现的。用大白话说,你这个事务想要查询一条行记录,MVCC会通过你这个事务所在视图确认版本链中哪个版本的行数据对你可见。刚才我们提到,四种隔离级别下,只有读已提交和可重复读会用到视图。对于读已提交,MVCC会在每次查询前都会生成一个视图,可重复读隔离级别只会在第一次查询时生成一个视图,之后在这个事务中的所有查询操作都会重复使用这个视图。行业上,将创建视图的那一刻称为快照,晃你一下子,让你激灵激灵,别发生脏读,变脏喽~
想要解决文章最开始的那个问题,我们还得展开说说版本链是如何形成的和快照的原理,稍有枯燥,先忍一下,耐心看下去,乖~
对于InnoDB存储引擎来说,主键索引(也称为聚簇索引)记录中除了正常的字段数据外,还包含两个隐藏列:
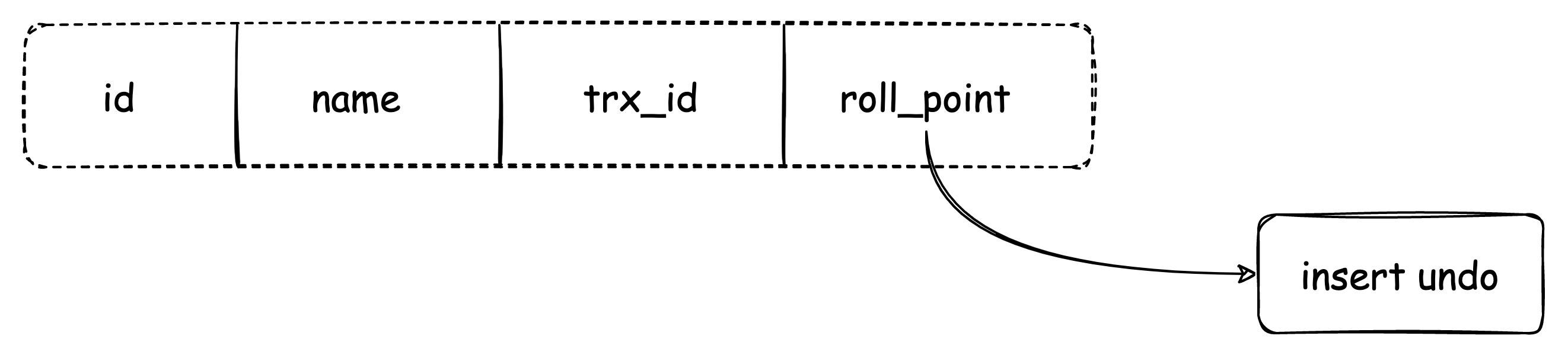
(1)trx_id:每次一个事务想要对主键索引进行更新、删除和新增时,都会把这个事务的事务id赋值给trx_id字段。注意事务id严格递增,且查询操作不会分配事务id,即trx_id = 0;
(2)roll_point:每次一个事务对主键索引进行更新时,都会把旧的版本写入到undo日志中,roll_point相当于一个指针,通过它可以找到这条记录修改前的信息。
我们以可重复读隔离级别为例,为了尚未提交的更新结果对其他事务不可见,InnoDB在创建视图时,有以下四部分组成:
• m_ids:表示生成视图时,当前系统中“活跃”的读写事务的事务id列表,这里的活跃大白话就是事务尚未提交;
• min_trx_id:表示在生成视图时,当前系统中活跃的读写事务中最小的事务id,即m_ids中的最小值;
• max_trx_id:表示生成视图时系统应该分配给下一个事务的id值;
• creator_trx_id:表示生成该视图的事务id。
概念比较多,举个例子,现在有事务id分别是1、2、3三个事务,1和2事务尚未提交,3事务已提交,这个时候如果来了一个新事务,那么它创建的视图对应这几个参数分别为:m_ids包含1、2,min_trx_id为1,max_trx_id为4。
关键的知识点来了,如何根据某个事务生成的视图,判断版本链上的某个版本对这个事务可见呢?
遵循下面步骤:
1、版本链上的不同版本trx_id值如果与这个视图的creator_trx_id值相同,说明当前事务在访问它自己修改过的记录,所以被访问的版本对当前事务可见。一家人还是认识一家人的~
2、版本链上的不同版本trx_id值小于这个视图的min_trx_id值,说明这个版本的事务在当前事务生成视图之前就已经提交了,所以被访问的版本对当前事务可见。
3、版本链上的不同版本的trx_id值大于或等于这个视图的max_trx_id值,说明这个版本的事务在当前事务之后才开启,所以被访问版本对当前事务不可见。
4、版本链上的不同版本的trx_id值在这个视图的min_trx_id和max_trx_id之间,需要进一步判断被访问版本trx_id值是不是在m_ids中,如果在,说明当前事务是活跃的,被访问版本对当前事务不可见。如果不在,说明被访问版本的事务已经提交了,被访问版本对当前事务可见。
比较绕是不是,千万别晕,兄弟呀~,大白话解释一下,设定某个事务生成的视图瞬间(也就是快照),这个事务的id为creator_trx_id,那么有下面三种可能:

1、如果creator_trx_id落在绿色部分,表示被访问的版本是已提交的事务或者就是当前事务自己生成的,这个数据是可见的;
2、如果creator_trx_id落在红色部分,表示被访问的版本还未开启,数据不可见;
3、如果creator_trx_id落在黄色部分,包括两种情况:
若creator_trx_id在m_ids集合中,表示被访问的版本尚未提交,数据不可见;
若creator_trx_id不在m_ids集合中,表示被访问的版本已经已经提交了,数据可见。
知道了这个之后,我们就可以回答文章最开始那个问题了,在隔离级别为可重复读的情况下(这里的隐含条件就是可重复读隔离级别只会在第一次查询时生成一个视图,之后在这个事务中的所有查询操作都会重复使用这个视图)分析一波:
以文章开头的例子,设定事务B的事务id=100,事务C的事务id=200,当事务B尚未提交时,id=1这条记录的版本链是这样的:
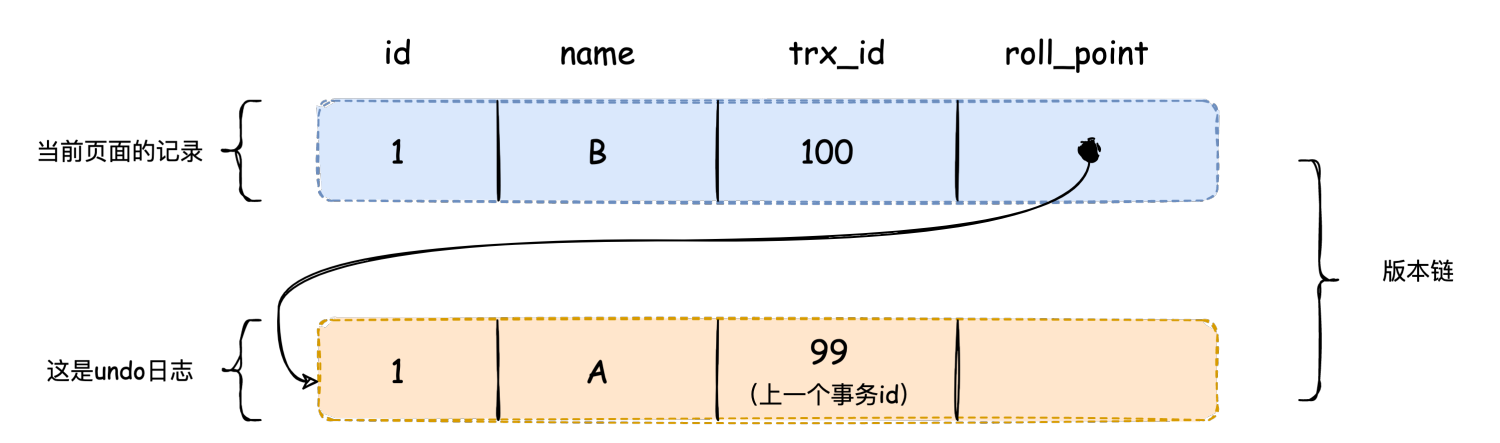
这个时候我们看一下事务A第一个select语句,注意查询操作的事务trx_id=0,在执行select语句时会创建一个视图,这个视图的m_ids={100},min_trx_id=100,max_trx_id=101,creator_trx_id=0。
然后在版本链中挑选可见的数据记录,从图中可以看到最新版本的name值是B,最新版本的trx_id值为100,在m_ids集合中,这个版本数据不可见,根据roll_point跳到下一个版本;
下一个版本的name值是A,这个版本的trx_id=99,小于min_trx_id,这个版本数据是可见的,所以返回name为A的记录,即V1为A。
我们继续,事务B这时进行了commit提交,此时事务C已经开启,那么事务A第二个select语句不会创建一个新的视图,而是重新利用第一次创建的视图。最新版本的trx_id为100,在m_ids中,数据不可见,即V2=A;
接下来,事务C进行了更新操作,此时版本链发生的改变如下:
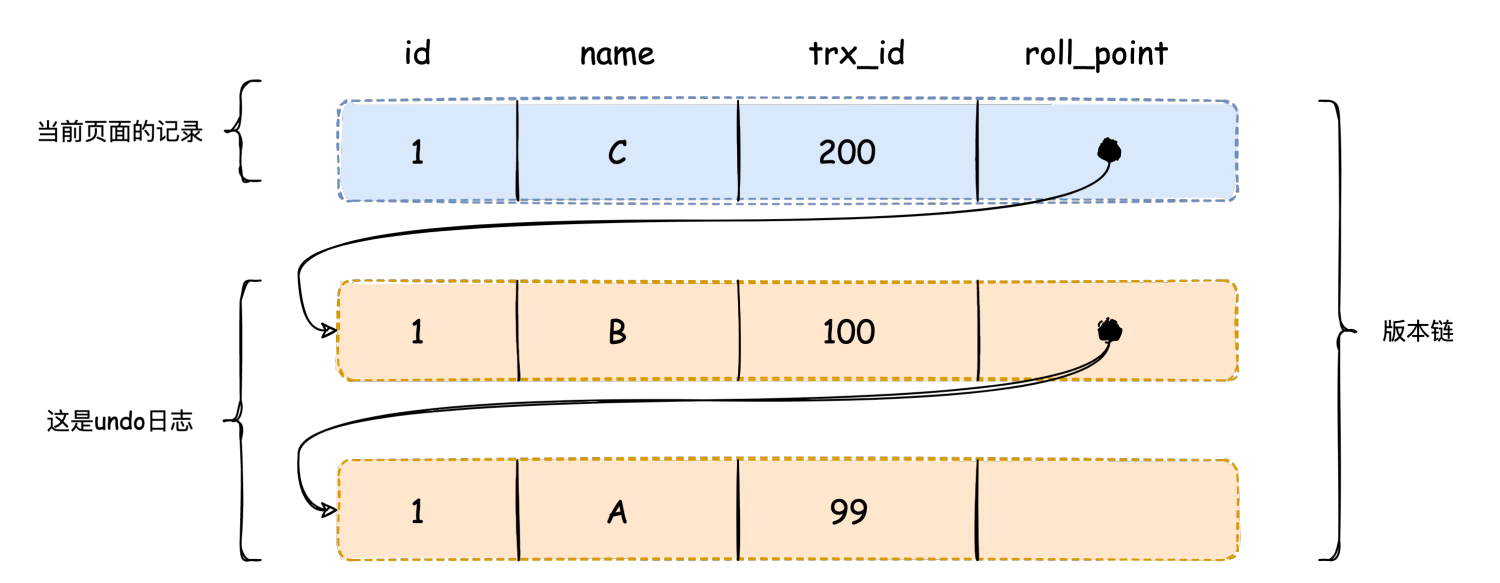
事务C接着进行了commit提交,此时事务A第三次select语句也不会创建一个新的视图,最新版本的trx_id为200,大于max_trx_id,数据不可见,即V3=A。
到这里,MVCC就结束啦,留一个小问题,如果是读已提交隔离级别,那么文章开头的例子中V1、V2、V3的值又分别是什么呢?答案在最后哦。
最后,我们再来总结一下MVCC的作用,使用可重复读隔离级别的事务在查询时,仅会使用第一次select时生成的视图,相比于读已提交隔离级别每次查询都会生成一个新的视图,可重复读在查询时使用的视图版本不会那么新,因此有些已经提交的事务对行记录进行修改时对查询事务就不可见,进而避免了不可重复读现象的发生,同时也避免了脏读。
小问题答案:
读已提交隔离级别下,每次select查询都会生成一个新的视图,基于此,分析如下:
事务A第一个select语句,注意查询操作的事务trx_id=0,在执行select语句时会创建一个视图,这个视图的m_ids={100},min_trx_id=100,max_trx_id=101,creator_trx_id=0。
然后在版本链中挑选可见的数据记录,从图中可以看到最新版本的name值时B,最新版本的trx_id值为100,在m_ids集合中,这个版本数据不可见,根据roll_point跳到下一个版本;
下一个版本的name值是A,这个版本的trx_id=99,小于min_trx_id,这个版本数据是可见的,所以返回name为A的记录,即V1为A。
事务B这时进行了commit提交,此时事务C已经开启,那么事务A第二个select语句会创建一个新的视图,这个视图的m_ids={200},min_trx_id=200,max_trx_id=201,creator_trx_id=0。版本链没有发生变化,最新版本trx_id值为100,小于min_trx_id,数据可见,即V2=B;
事务C接着进行了commit提交,此时事务A第三次select语句会创建一个新的视图,这个视图的m_ids={},min_trx_id不存在,max_trx_id=201,creator_trx_id=0。在版本链中挑选可见的数据记录,从图中可以看到最新版本的name值为C,最新版本的trx_id值为200,小于max_trx_id且不在m_ids中,则数据可见,即V3=C。