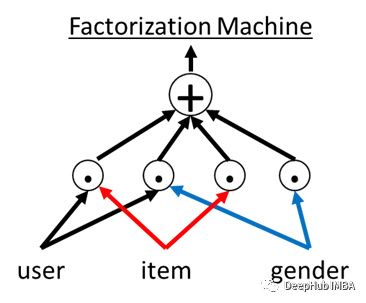
因子分解机(Factorization Machines,简称FM)是一种用于解决推荐系统、回归和分类等机器学习任务的模型。它由Steffen Rendle于2010年提出,是一种基于线性模型的扩展方法,能够有效地处理高维稀疏数据,并且在处理特征组合时表现出色。它是推荐系统的经典模型之一,并且模型简单、可解释性强,所以搜索广告与推荐算法领域还在被使用。今天我们来详细介绍它并使用Pytorch代码进行简单的实现。
我们这里使用一个用户、电影和评分的数据集,现在需要通过因子分解机进行电影的推荐。数据特征包括:电影、评级、时间戳、标题和类型。用户特征包括:年龄、性别、职业、邮政编码。数据集中没有分级的电影将被删除。
DATA_DIR = './data/ml-1m/'
df_movies = pd.read_csv(DATA_DIR+'movies.dat', sep='::',
names=['movieId', 'title','genres'],
encoding='latin-1',
engine='python')
user_cols = ['userId', 'gender' ,'age', 'occupation', 'zipcode']
df_users = pd.read_csv(DATA_DIR+'users.dat', sep='::',
header=None,
names=user_cols,
engine='python')
df = pd.read_csv(DATA_DIR+'ratings.dat', sep='::',
names=['userId','movieId','rating','time'],
engine='python')
# Left merge removes movies with no rating. # of unique movies: 3883 -> 3706
df = df.merge(df_movies, on='movieId', how='left')
df = df.merge(df_users, on='userId', how='left')
df = df.sort_values(['userId', 'time'], ascending=[True, True]).reset_index(drop=True)
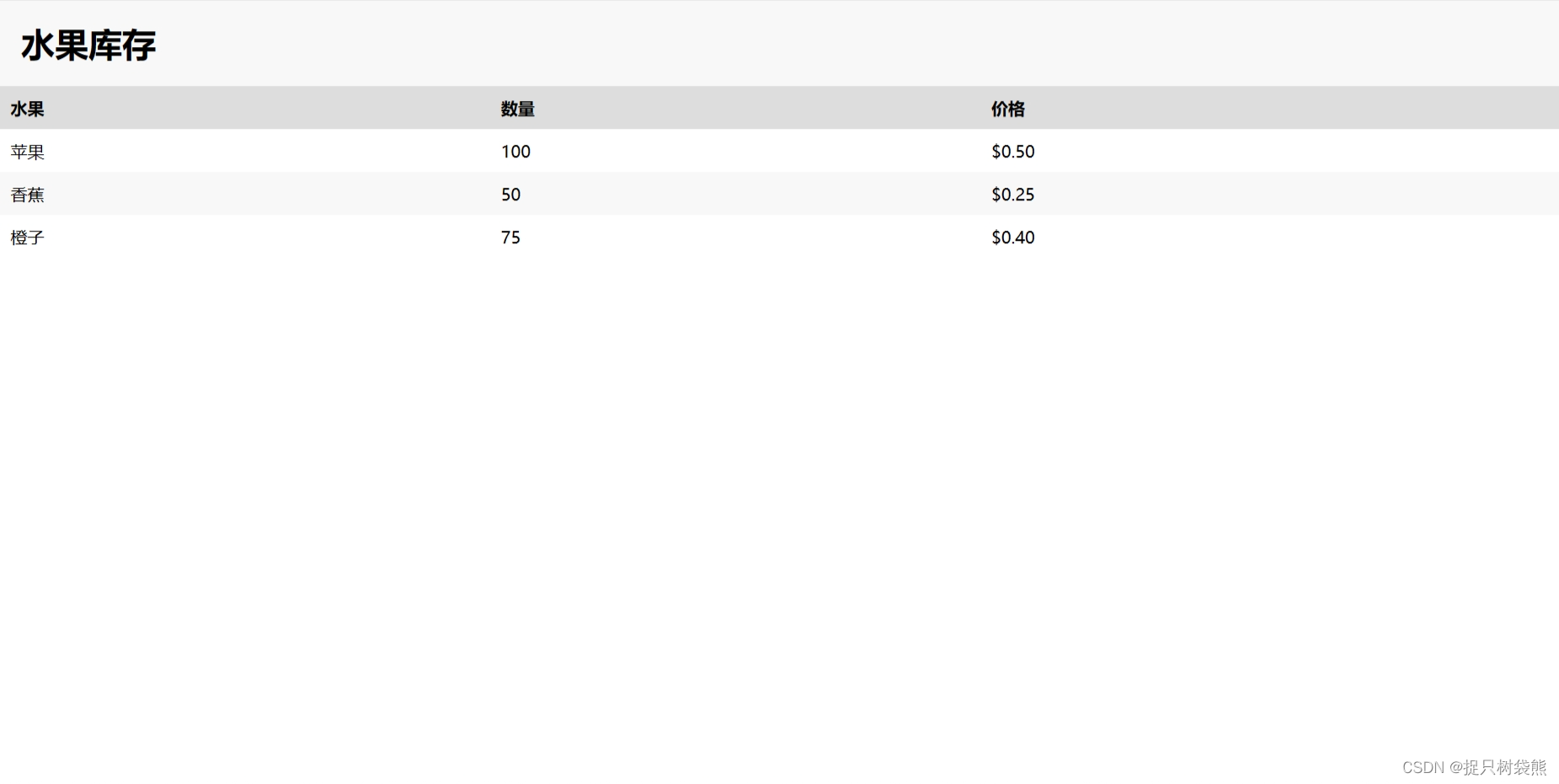
数据集是这个样子的

数据预处理
我们数据集中最大movieId是3952,但是只有3706个唯一的movieId。所以需要重新映射(3952 -> 3706)
d = defaultdict(LabelEncoder)
cols_cat = ['userId', 'movieId', 'gender', 'age', 'occupation']
for c in cols_cat:
d[c].fit(df[c].unique())
df[c+'_index'] = d[c].transform(df[c])
print(f'# unique {c}: {len(d[c].classes_)}')
min_num_ratings = df.groupby(['userId'])['userId'].transform(len).min()
print(f'Min # of ratings per user: {min_num_ratings}')
print(f'Min/Max rating: {df.rating.min()} / {df.rating.max()}')
print(f'df.shape: {df.shape}')
结果如下

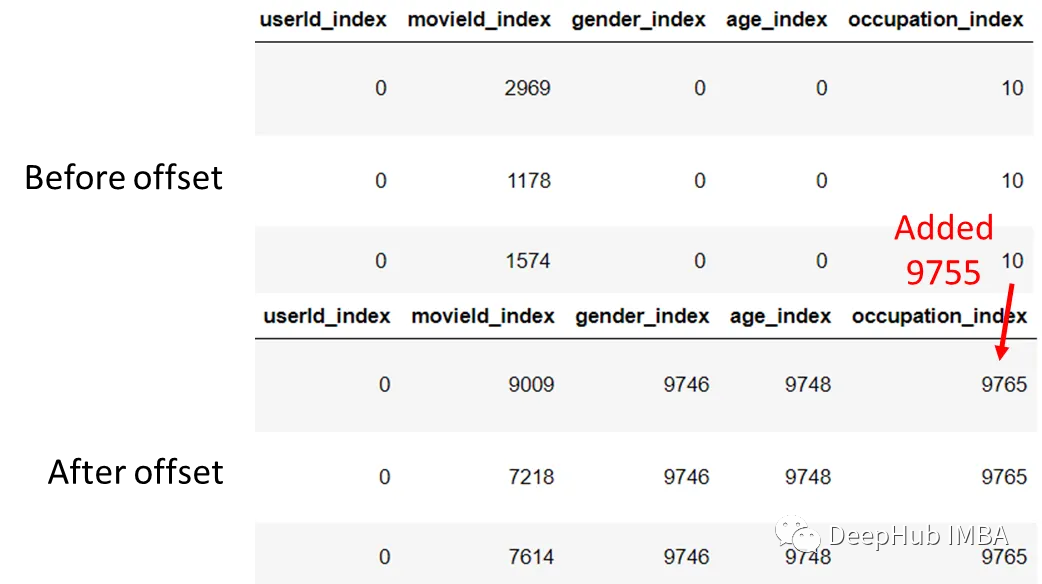
对于因子分解机器,在标签编码之后还需要一个额外的步骤,就是添加特征偏移量。通过添加特征偏移量,我们可以只使用一个嵌入矩阵,而不是使用多个嵌入矩阵+一个for循环。这对提高训练效率很有帮助。

feature_cols = ['userId_index', 'movieId_index', 'gender_index', 'age_index',
'occupation_index']
# Get offsets
feature_sizes = {}
for feat in feature_cols:
feature_sizes[feat] = len(df[feat].unique())
feature_offsets = {}
NEXT_OFFSET = 0
for k,v in feature_sizes.items():
feature_offsets[k] = NEXT_OFFSET
NEXT_OFFSET += v
# Add offsets to each feature column
for col in feature_cols:
df[col] = df[col].apply(lambda x: x + feature_offsets[col])
print('Offset - feature')
for k, os in feature_offsets.items():
print(f'{os:<6} - {k}')

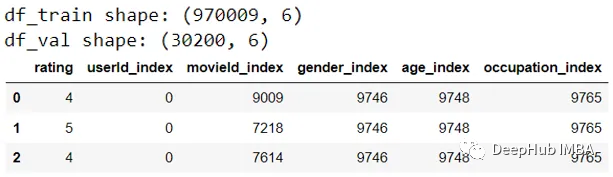
拆分数据,创建Dataset和Dataloader
THRES = 5
cols = ['rating', *feature_cols]
df_train = df[cols].groupby('userId_index').head(-THRES).reset_index(drop=True)
df_val = df[cols].groupby('userId_index').tail(THRES).reset_index(drop=True)
print(f'df_train shape: {df_train.shape}')
print(f'df_val shape: {df_val.shape}')
df_train.head(3)
Dataset和Dataloader如下:
class MovieDataset(Dataset):
""" Movie DS uses x_feats and y_feat """
def __init__(self, df, x_feats, y_feat):
super().__init__()
self.df = df
self.x_feats = df[x_feats].values
self.y_rating = df[y_feat].values
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
return self.x_feats[idx], self.y_rating[idx]
BS = 1024
ds_train = MovieDataset(df_train, feature_cols, 'rating')
ds_val = MovieDataset(df_val, feature_cols, 'rating')
dl_train = DataLoader(ds_train, BS, shuffle=True, num_workers=2)
dl_val = DataLoader(ds_val, BS, shuffle=True, num_workers=2)
xb, yb = next(iter(dl_train))
print(xb.shape, yb.shape)
print(xb)
print(yb)

FM模型
FM的主要目标是处理特征之间的交互作用,尤其在拥有大量离散特征的问题中,传统的线性模型容易遇到维度灾难的问题。FM采用了因子分解的技术来捕捉特征之间的隐含关系,从而在高维数据中学习特征之间的相互作用,而无需显式地考虑所有可能的特征组合。
FM的核心思想是将每个特征表示为一个向量,然后通过向量之间的内积来表示特征之间的交互作用。具体来说,FM通过学习每个特征的一维权重(表示特征的重要性)以及每个特征的隐向量(表示特征之间的相互作用)来实现这一目标。
简单的说,因子分解机器可以使用任意数量的特征来训练模型。它会对两两(特征到特征)特征进行交互建模,取每个特征与其他特征的点积。然后把它们加起来。

除了特征到特征的点积之外,论文还添加了全局偏移和特征偏差。我们的Pytorch实现中包含了偏移和偏差。下面是论文中的方程。“n”=特征的数量。k =特征维度

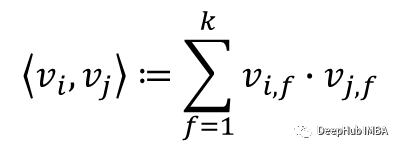
在上面的等式中,每个特征乘以每个特征。如果有“k”维的“n”个特征,这将导致O(k * n²)时间复杂度。如下图所示,论文推导出一个时间复杂度为O(k * n)的更快实现。
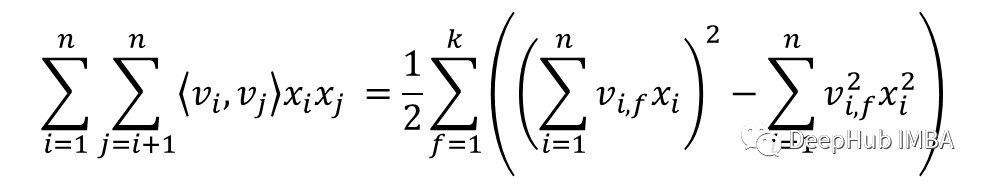
在我们实现中,使用nn.Embedding层来处理输入(通常是编码的)。
class FM(nn.Module):
""" Factorization Machine + user/item bias, weight init., sigmoid_range
Paper - https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
"""
def __init__(self, num_feats, emb_dim, init, bias, sigmoid):
super().__init__()
self.x_emb = nn.Embedding(num_feats, emb_dim)
self.bias = bias
self.sigmoid = sigmoid
if bias:
self.x_bias = nn.Parameter(torch.zeros(num_feats))
self.offset = nn.Parameter(torch.zeros(1))
if init:
self.x_emb.weight.data.uniform_(0., 0.05)
def forward(self, X):
# Derived time complexity - O(nk)
x_emb = self.x_emb(X) # [bs, num_feats] -> [bs, num_feats, emb_dim]
pow_of_sum = x_emb.sum(dim=1).pow(2) # -> [bs, num_feats]
sum_of_pow = x_emb.pow(2).sum(dim=1) # -> [bs, num_feats]
fm_out = (pow_of_sum - sum_of_pow).sum(1)*0.5 # -> [bs]
if self.bias:
x_biases = self.x_bias[X].sum(1) # -> [bs]
fm_out += x_biases + self.offset # -> [bs]
if self.sigmoid:
return self.sigmoid_range(fm_out, low=0.5) # -> [bs]
return fm_out
def sigmoid_range(self, x, low=0, high=5.5):
""" Sigmoid function with range (low, high) """
return torch.sigmoid(x) * (high-low) + low
训练
采用AdamW优化器和均方损失(mean squared loss, MSE)对模型进行训练。为了便于使用,超参数被放入配置类(CFG)中。
CFG = {
'lr': 0.001,
'num_epochs': 8,
'weight_decay': 0.01,
'sigmoid': True,
'bias': True,
'init': True,
}
n_feats = int(pd.concat([df_train, df_val]).max().max())
n_feats = n_feats + 1 # "+ 1" to account for 0 - indexing
mdl = FM(n_feats, emb_dim=100,
init=CFG['init'], bias=CFG['bias'], sigmoid=CFG['sigmoid'])
mdl.to(device)
opt = optim.AdamW(mdl.parameters(), lr=CFG['lr'], weight_decay=CFG['weight_decay'])
loss_fn = nn.MSELoss()
print(f'Model weights: {list(dict(mdl.named_parameters()).keys())}')
脚本也是常见的Pytorch训练流程
epoch_train_losses, epoch_val_losses = [], []
for i in range(CFG['num_epochs']):
train_losses, val_losses = [], []
mdl.train()
for xb,yb in dl_train:
xb, yb = xb.to(device), yb.to(device, dtype=torch.float)
preds = mdl(xb)
loss = loss_fn(preds, yb)
train_losses.append(loss.item())
opt.zero_grad()
loss.backward()
opt.step()
mdl.eval()
for xb,yb in dl_val:
xb, yb = xb.to(device), yb.to(device, dtype=torch.float)
preds = mdl(xb)
loss = loss_fn(preds, yb)
val_losses.append(loss.item())
# Start logging
epoch_train_loss = np.mean(train_losses)
epoch_val_loss = np.mean(val_losses)
epoch_train_losses.append(epoch_train_loss)
epoch_val_losses.append(epoch_val_loss)
s = (f'Epoch: {i}, Train Loss: {epoch_train_loss:0.2f}, '
f'Val Loss: {epoch_val_loss:0.2f}'
)
print(s)
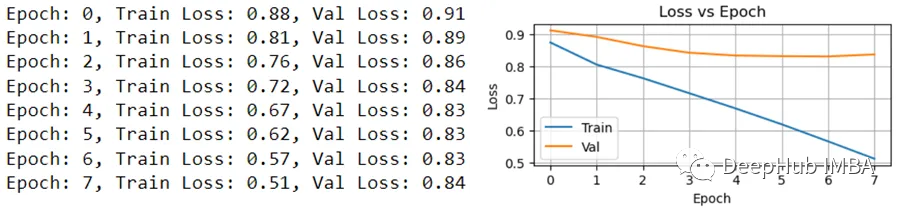
结果
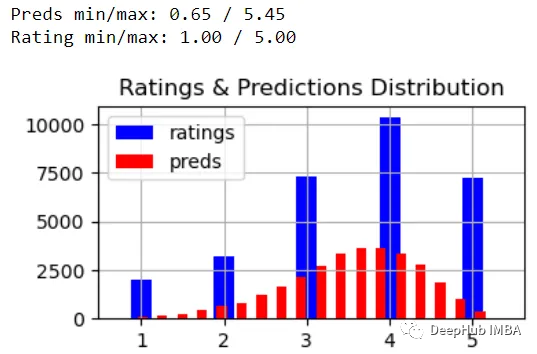
让我们做一些完整性检查。模型的评级范围为[0.65,5.45],偏离了实际评级范围[1,5]。但是预测分布看起来不错
lpreds, lratings = [], []
mdl.eval()
for xb,yb in dl_val:
xb, yb = xb.to(device), yb.to(device, dtype=torch.float)
preds = mdl(xb)
lpreds.extend(preds.detach().cpu().numpy().tolist())
lratings.extend(yb.detach().cpu().numpy().tolist())
print(f'Preds min/max: {min(lpreds):0.2f} / {max(lpreds):0.2f}')
print(f'Rating min/max: {min(lratings):0.2f} / {max(lratings):0.2f}')
plt.figure(figsize=(4,2))
plt.hist(lratings, label='ratings', bins=(np.arange(1,7)-0.5),
rwidth=0.25, color='blue')
plt.hist(lpreds, label='preds', bins=20, rwidth=0.5, color='red')
plt.title('Ratings & Predictions Distribution')
plt.grid()
plt.legend();
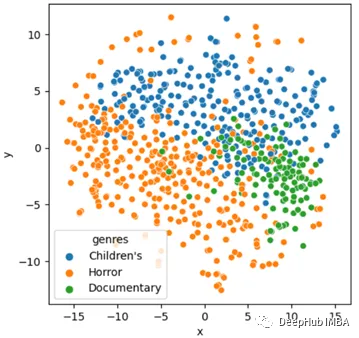
使用TSNE查看训练后的nn.Embedding,我们可以看到儿童,恐怖和纪录片的分组是学习得来的
# Check TSNE for genres - Make dataframe of movie + embeddings + biases
movies = df.drop_duplicates('movieId_index').reset_index(drop=True)
movies['movieId'] = d['movieId'].transform(movies.movieId)
# Get movie embeddings and biases
idxs_movies = torch.tensor(movies['movieId_index'].values, device=device)
movie_embs = mdl.x_emb.weight[idxs_movies]
movie_biases = mdl.x_bias[idxs_movies]
movies['emb'] = movie_embs.tolist()
movies['bias'] = movie_biases.tolist()
# Check TSNE, and scatter plot movie embeddings
# Movie embeddings do get separated after training
genre_cols = ['Children\'s', 'Horror', 'Documentary']
GENRES = '|'.join(genre_cols)
print(f'Genres: {GENRES}')
movies_subset = movies[movies['genres'].str.contains(GENRES)].copy()
X = np.stack(movies_subset['emb'].values)
ldr = TSNE(n_components=2, init='pca', learning_rate='auto', random_state=42)
Y = ldr.fit_transform(X)
movies_subset['x'] = Y[:, 0]
movies_subset['y'] = Y[:, 1]
def single_genre(genres):
""" Filter movies for genre in genre_cols"""
for genre in genre_cols:
if genre in genres: return genre
movies_subset['genres'] = movies_subset['genres'].apply(single_genre)
plt.figure(figsize=(5, 5))
ax = sns.scatterplot(x='x', y='y', hue='genres', data=movies_subset)
我们可以获取“Toy Story 2 (1999)”的电影推荐。也就是我们的推理过程,是通过余弦相似度来进行的。
# Helper function/dictionaries to convert form name to labelEncoder index/label
d_name2le = dict(zip(df.title, df.movieId))
d_le2name = {v:k for k,v in d_name2le.items()}
def name2itemId(names):
"""Give movie name, returns labelEncoder label. This is before adding any offset"""
if not isinstance(names, list):
names = [names]
return d['movieId'].transform([d_name2le[name] for name in names])
# Input: movie name. Output: movie recommendations using cosine similarity
IDX = name2itemId('Toy Story 2 (1999)')[0] # IDX = 2898, before offset
IDX = IDX + feature_offsets['movieId_index'] # IDX = 8938, after offset to get input movie emb
emb_toy2 = mdl.x_emb(torch.tensor(IDX, device=device))
cosine_sim = torch.tensor(
[F.cosine_similarity(emb_toy2, emb, dim=0) for emb in movie_embs]
)
top8 = cosine_sim.argsort(descending=True)[:8]
movie_sims = cosine_sim[top8]
movie_recs = movies.iloc[top8.detach().numpy()]['title'].values
for rec, sim in zip(movie_recs, movie_sims):
print(f'{sim.tolist():0.3f} - {rec}')

显示labelEncoder用户元特征编码。
d_age_meta = {'Under 18': 1, '18-24': 18, '25-34': 25, '35-44': 35,
'45-49': 45, '50-55': 50, '56+': 56
}
d_gender = dict(zip(d['gender'].classes_, range(len(d['gender'].classes_))))
d_age = dict(zip(d['age'].classes_, range(len(d['age'].classes_))))
print(f'Gender mapping: {d_gender}')
print(f'Age mapping: {d_age}')

这样可以为特定类型的人群进行推荐,例如为18-24岁的男性提供冷启动的电影推荐。
# Get cold start movie recs for a male (GENDER=1), ages 18-24 (AGE=1)
GENDER = 1
AGE = 1
gender_emb = mdl.x_emb(
torch.tensor(GENDER+feature_offsets['gender_index'], device=device)
)
age_emb = mdl.x_emb(
torch.tensor(AGE+feature_offsets['age_index'], device=device)
)
metadata_emb = gender_emb + age_emb
rankings = movie_biases + (metadata_emb*movie_embs).sum(1) # dot product
rankings = rankings.detach().cpu()
for i, movie in enumerate(movies.iloc[rankings.argsort(descending=True)]['title'].values[:10]):
print(i, movie)

部署
可以使用streamlit进行简单的部署:
首先将模型保存成文件
SAVE = False
if SAVE:
movie_embs_cpu = movie_embs.cpu()
d_utils = {'label_encoder': d,
'feature_offsets': feature_offsets,
'movie_embs': movie_embs_cpu,
'movies': movies,
'd_name2le': d_name2le,
}
pd.to_pickle(d_utils, 'data/d_utils.pkl', protocol=4)
mdl_scripted = torch.jit.script(mdl)
mdl_scripted.save('mdls/fm_pt.pkl')
然后看看结果

总结
FM模型可以看作是一个结合了线性模型和低秩矩阵分解的模型,它克服了高维数据问题,减少了模型参数的数量,并且能够很好地捕捉特征之间的交互信息。此外,FM的训练过程相对简单高效。因子分解机是一种强大的机器学习模型,特别适用于处理高维稀疏数据,并且在推荐系统、广告推荐、个性化推荐等领域得到广泛应用。
本文的完整代码在这里:
https://avoid.overfit.cn/post/57c0d06f61ed4b67b9487750e8d2d211
作者:Daniel Lam