目录
一、Excel透视表
1、源数据
2、数据总分析
3、数据top分析
二、python实现
1、第一张表演示
2、第二张表演示
一、Excel透视表
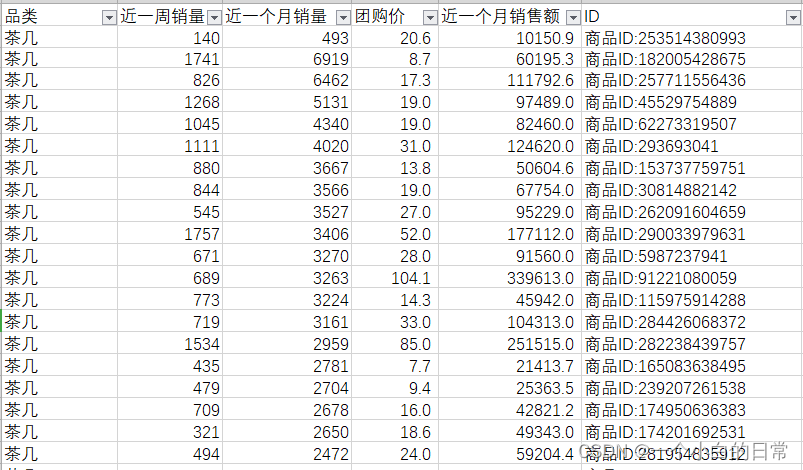
1、源数据
1)四个类目,每类50条数据

2)数据内容
2、数据总分析

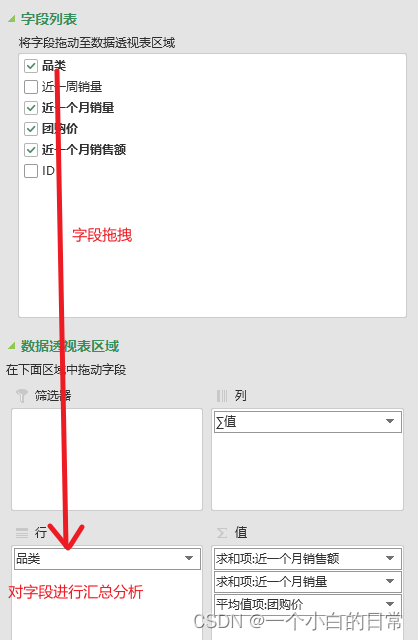
1)选择要分析的字段,左侧为要对其进行汇总的数据,右侧为要汇总的具体值项
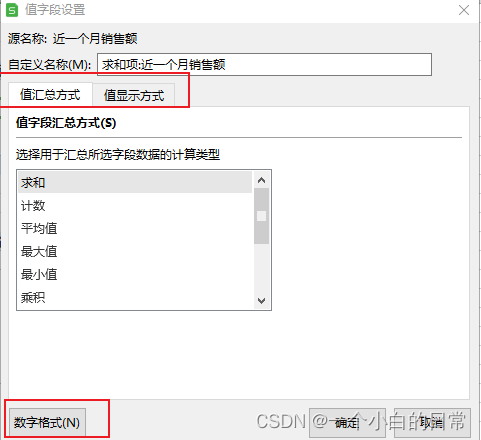
2)值字段设置
值汇总方式:数据计算方式
值显示方式:数据的百分比
数字格式:数字的表示方式(如小数点个数等)
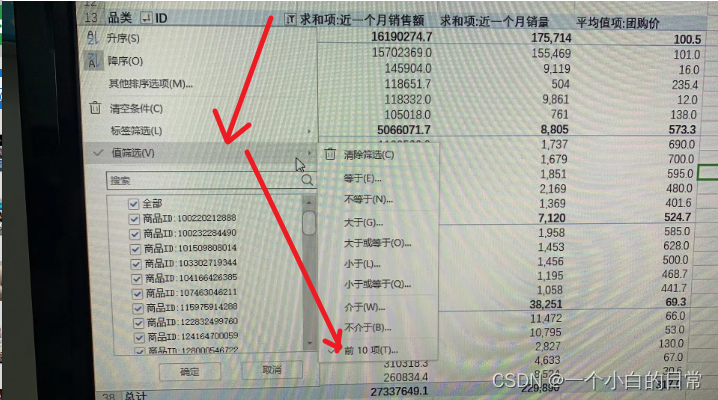
3、数据top分析
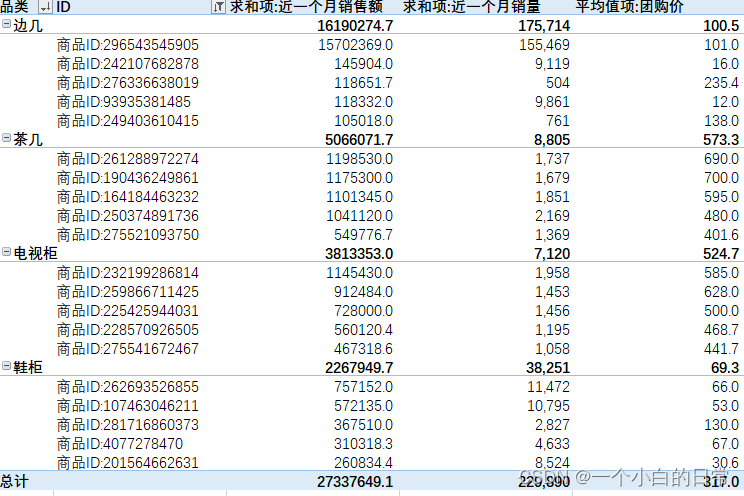
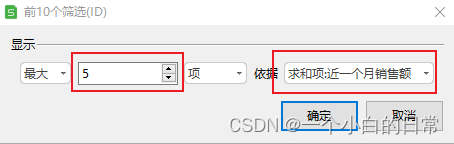
1)按照近一个销售额对每个品类的top5进行分析
依据 “求和项:近一个月销售额” 对ID的top5进行选择
二、python实现
1、第一张表演示
import pandas as pd
import numpy as np
#读取原始文件
file=pd.read_excel('F:\Excel\\透视表.xlsx',sheet_name='销售源数据')
#对数据汇总做成透视表 第一张表
data1=file.pivot_table(index=['品类'],values=['近一个月销售额','近一个月销量','团购价'],aggfunc=[np.sum,np.mean]).reset_index()
data11=pd.DataFrame(data1.values[:,[0,2,3,6]],columns=['品类','求和项:近一个月销售额','求和项:近一个月销量','平均值项:团购价']).sort_values('求和项:近一个月销售额',ascending=False).reset_index(drop=True)
data11['求和项:近一个月销售额']=data11['求和项:近一个月销售额'].astype(float).map(lambda x:'{:.1f}'.format(x))
data11['平均值项:团购价']=data11['平均值项:团购价'].astype(float).map(lambda x:'{:.1f}'.format(x))
data11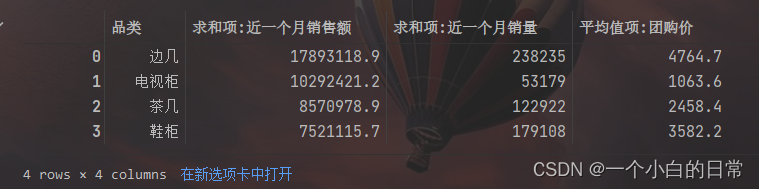
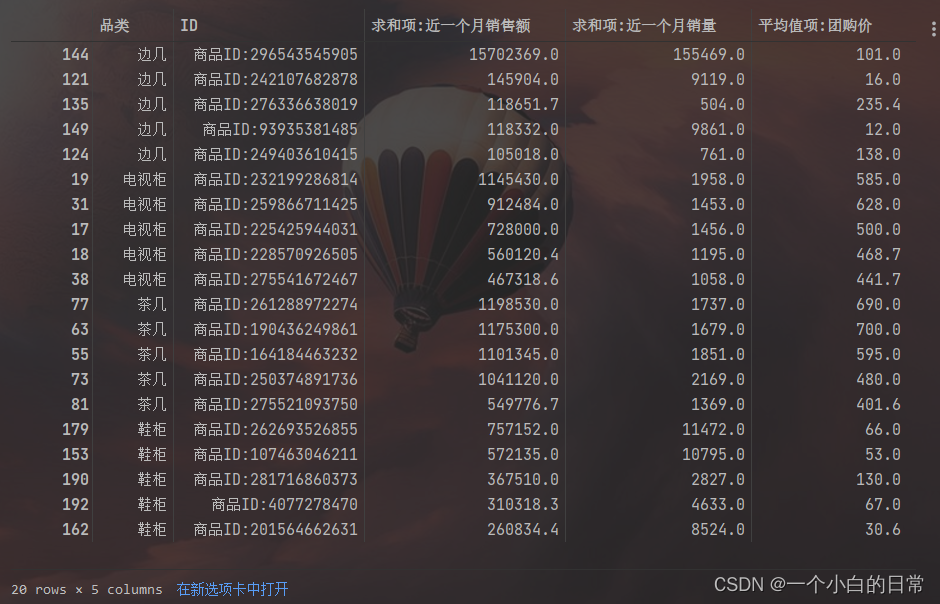
2、第二张表演示
#第二张表
data2=file.pivot_table(index=['品类','ID'],values=['近一个月销售额','近一个月销量','团购价'],aggfunc=[np.sum,np.mean]).reset_index()
data22=pd.DataFrame(data2.values[:,[0,1,3,4,5]],columns=['品类','ID','求和项:近一个月销售额','求和项:近一个月销量','平均值项:团购价'])
#按照品类选择出销售额最高的ID
data22[['求和项:近一个月销售额','求和项:近一个月销量','平均值项:团购价']]=data22[['求和项:近一个月销售额','求和项:近一个月销量','平均值项:团购价']].astype(float)
#建立一张新表进行拼接
data24=pd.DataFrame()
for i in data11['品类'].to_list():
data23=data22.loc[data22[data22.品类==i].index,:].nlargest(5,'求和项:近一个月销售额')
data24=pd.concat([data24,data23],axis=0)
data24['求和项:近一个月销售额']=data24['求和项:近一个月销售额'].astype(float).map(lambda x:'{:.1f}'.format(x))
data24['平均值项:团购价']=data24['平均值项:团购价'].astype(float).map(lambda x:'{:.1f}'.format(x))
data24