首先要说的是,这是一个很简易的案例,目的在于体会这样一种结构。
第一部分:基本操作
案例描述:启动浏览器--打开好123--点击logo--跳转到百度--输入搜索词汇--点击按钮开始搜索。
模式描述:这个模式把元素的提取、元素的操作、场景都写在了一个文件内。
1.目录结构

实际上,report目录我暂时没用到,以后再说。
2.各文件源码
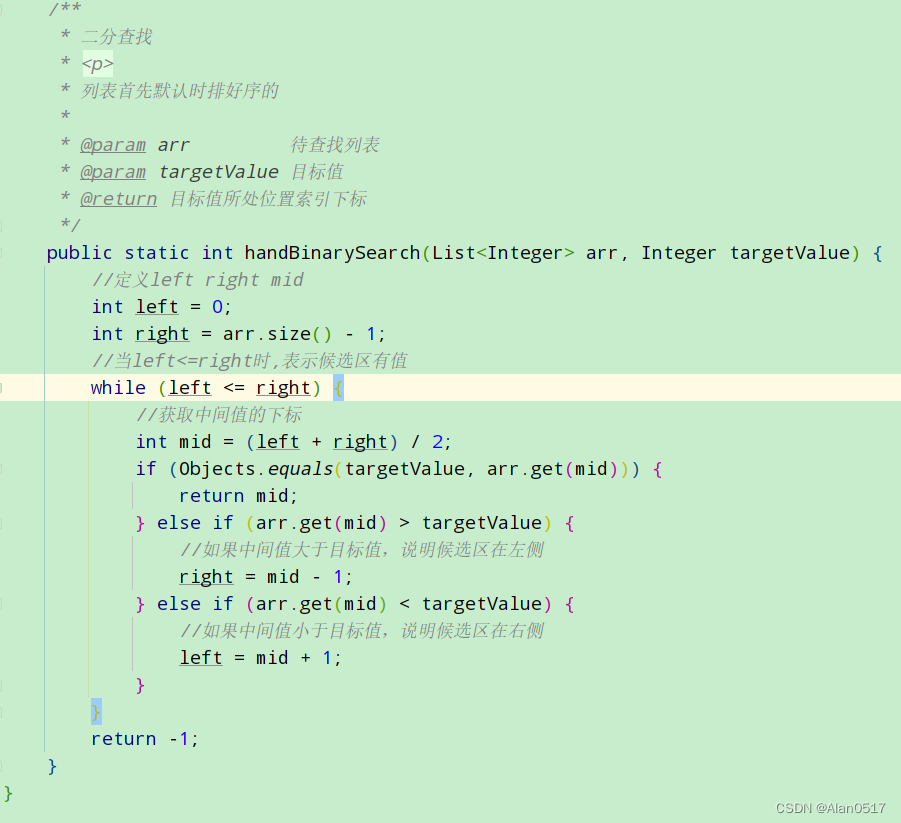
1)elementpage.py
# 本类用来描述案例中用到的全部元素,每个方法对应一个元素
class Element(object):
def __init__(self, driver):
self.driver = driver
def find_logo(self):
ele = self.driver.find_element_by_id('search_logolink') # 用来获取好123首页上的百度logo
return ele
def find_textarea(self):
ele = self.driver.find_element_by_id('kw') # 用来获取百度首页上的输入框
return ele
def find_searchbutton(self):
ele = self.driver.find_element_by_id('su') # 用来获取百度首页输入框旁边的"百度一下"按钮
return ele
# 本类用来描述一些基本的元素操作,每个方法代表一种操作
class Operation(object):
def __init__(self, driver):
self.element = Element(driver)
def jump_to_baidu(self):
self.element.find_logo().click() # 点击百度logo的动作
def input_and_click(self, aimstring):
self.element.driver.switch_to.window(self.element.driver.window_handles[1]) # 切换标签页,因为百度首页会以新的标签呈现
self.element.find_textarea().send_keys(aimstring) # 向输入框传入搜索词汇
self.element.find_searchbutton().click() # 点击百度一下按钮开始搜索
# 本类用来描述一个场景,它由前面的若干种操作组成
class SearchScenario(object):
def __init__(self, driver):
self.operation = Operation(driver)
# 本方法就是一个具体的场景
def search(self, aimstring):
self.operation.jump_to_baidu() # 从好123跳转到百度
self.operation.input_and_click(aimstring) # 从输入到搜索
2)test_001_search.py
import time
from selenium import webdriver
import pytest
from pageobject import elementpage
data = [('AA'), ('BB'), ('CC')]
@pytest.mark.parametrize('aimstring', data)
class TestSearch():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.get('https://www.hao123.com')
time.sleep(5)
def teardown(self):
time.sleep(5)
self.driver.quit()
def test_001_search(self, aimstring):
time.sleep(5)
elementpage.SearchScenario(self.driver).search(aimstring)
if __name__ == '__main__':
pytest.main(['-s'])
3.运行结果:
/usr/local/bin/python3.10 /Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pycharm/_jb_pytest_runner.py --path /Users/gyf/mypython/PO2/Baidu_Search2/testcases/test_001_search.py
Testing started at 09:03 ...
Launching pytest with arguments /Users/gyf/mypython/PO2/Baidu_Search2/testcases/test_001_search.py --no-header --no-summary -q in /Users/gyf/mypython/PO2/Baidu_Search2/testcases
============================= test session starts ==============================
collecting ... collected 3 items
test_001_search.py::TestSearch::test_001_search[AA]
test_001_search.py::TestSearch::test_001_search[BB]
test_001_search.py::TestSearch::test_001_search[CC]
========================= 3 passed in 67.02s (0:01:07) =========================
进程已结束,退出代码04.个人体会
我感觉这种模式比之前写过的那种元素提取、操作描述、场景描述分散在不同地方的结构更加易于理解。
第二部分:数据分离
数据分离的含义:就是把测试数据从代码中分离出去,这样不用在去修改代码了,更加易于以后的维护。
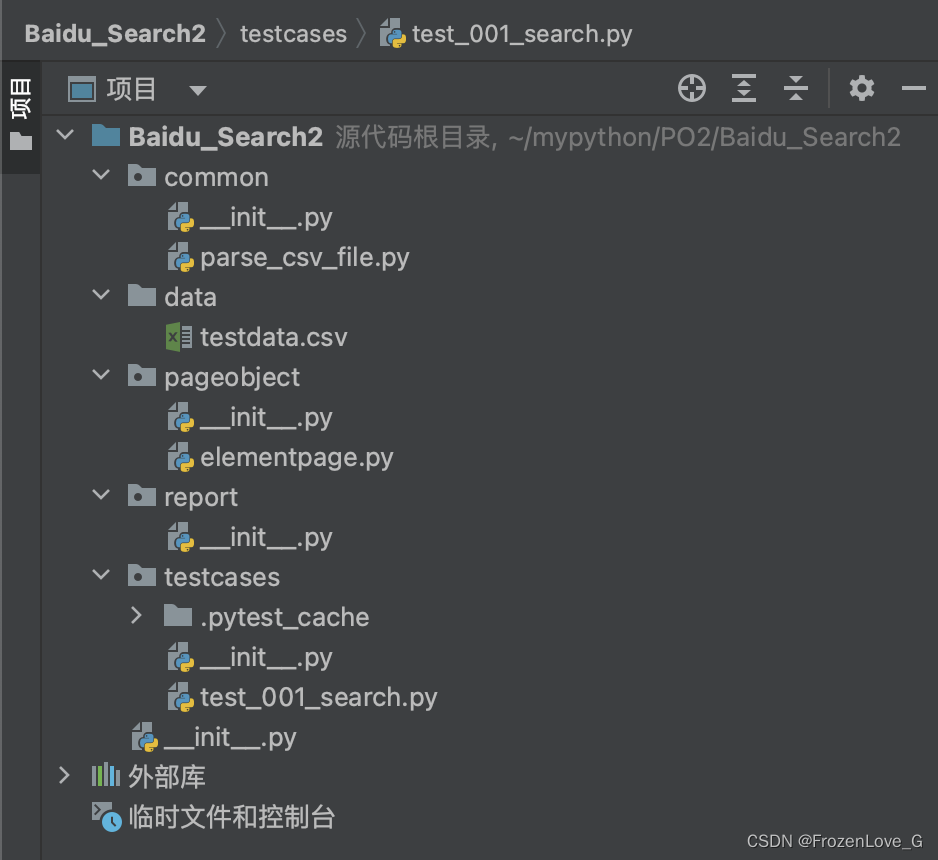
首先增加一个data目录,用于存放测试数据。增加一个common目录用于存放从文件中解析出测试数据的脚本parse_csv_file.py。
目录结构如下图:
parse_csv_file.py源码如下
import csv
def parse_csv_file(file_path):
csvlist = []
with open(file_path, 'r', encoding='utf-8') as f:
data = csv.reader(f)
for i in data:
csvlist.append(tuple(i)) # 由于我们的测试案例基于pytest来写,因此需要将读出来的列表转换为元组后在加入的大列表中
del csvlist[0] # 一般第一行都是各个数据列的名字,并非测试数据,因此我们需要把它从列表中删除
print(csvlist)
return csvlist
#测试下看看输出的格式是否满足我们所需
if __name__=="__main__":
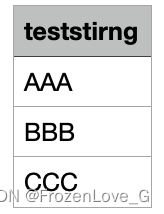
parse_csv_file("../data/testdata.csv")testdata.csv内容如下:
另外,还需要修改测试用例文件,使它获取到测试数据。
将test_001_search.py里原本的
data = [('AA'), ('BB'), ('CC')]屏蔽掉,加入如下一行
data = parse_csv_file.parse_csv_file("../data/testdata.csv")即可。
现在重新运行测试用例,结果如下
/usr/local/bin/python3.10 /Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pycharm/_jb_pytest_runner.py --path /Users/gyf/mypython/PO2/Baidu_Search2/testcases/test_001_search.py
Testing started at 10:31 ...
Launching pytest with arguments /Users/gyf/mypython/PO2/Baidu_Search2/testcases/test_001_search.py --no-header --no-summary -q in /Users/gyf/mypython/PO2/Baidu_Search2/testcases
============================= test session starts ==============================
collecting ... collected 3 items
test_001_search.py::TestSearch::test_001_search[aimstring0]
test_001_search.py::TestSearch::test_001_search[aimstring1]
test_001_search.py::TestSearch::test_001_search[aimstring2]
========================= 3 passed in 65.93s (0:01:05) =========================
进程已结束,退出代码0
PASSED [ 33%]PASSED [ 66%]PASSED [100%]个人体会:
数据分离,就是让测试数据离开源代码,使之存放在代码之外。这样我们将不可避免的使用到文件读取或者其他读取方式。另外,将读取到的数据整合成适合pytest读取的格式。








![[附源码]JAVA毕业设计学生公寓管理系统(系统+LW)](https://img-blog.csdnimg.cn/dc565216e6324f20bb60a48e1b24002e.png)