🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
开发深度 Q 网络
怎么做...
这个怎么运作...
也可以看看
通过经验回放改进 DQN
怎么做...
这个怎么运作...
开发双深度 Q 网络
怎么做...
这个怎么运作...
为 CartPole 调整双 DQN 超参数
怎么做...
这个怎么运作...
开发决斗深度 Q 网络
怎么做...
这个怎么运作...
将深度 Q 网络应用于 Atari 游戏
怎么做...
这个怎么运作...
在 Atari 游戏中使用卷积神经网络
怎么做...
这个怎么运作...
深度 Q 学习,或使用深度 Q 网络,被认为是最现代的强化学习技术。在本章中,我们将逐步开发各种深度 Q 网络模型,并将它们应用于解决几个强化学习问题。我们将从香草 Q 网络开始,并通过经验回放来增强它们。我们将通过使用额外的目标网络来提高稳健性,并演示如何微调深度 Q 网络。我们还将试验决斗深度 Q 网络,看看它们的价值函数与其他类型的深度 Q 网络有何不同。在最后两个秘籍中,我们将通过将卷积神经网络纳入深度 Q 网络来解决复杂的 Atari 游戏问题。
本章将介绍以下食谱:
- 开发深度 Q 网络
- 通过经验回放改进 DQN
- 开发双深度 Q 网络
- 为 CartPole 调整双 DQN 超参数
- 开发决斗深度 Q 网络
- 将深度 Q 网络应用于 Atari 游戏
- 在 Atari 游戏中使用卷积神经网络
开发深度 Q 网络
您会记得函数逼近( FA ) 使用一组从原始状态生成的特征来逼近状态空间。深度 Q 网络( DQN ) 与具有神经网络的 FA 非常相似,但它们使用神经网络将状态直接映射到动作值,而不是使用一组生成的特征作为媒体。
在深度 Q 学习中,神经网络被训练为给定输入状态 s 的每个动作输出适当的Q(s,a)值。代理的动作 a 是根据遵循 epsilon-greedy 策略的输出 Q(s,a) 值来选择的。具有两个隐藏层的 DQN 结构如下图所示:

你会记得 Q-learning 是一种 off-policy 学习算法,它根据以下等式更新 Q 函数:
![]()
这里,s'是在状态s中 采取行动后的结果状态a;r是相关奖励;α 是学习率;γ 是贴现因子。此外,![]() 意味着行为策略是贪婪的,其中选择状态s'中的最高 Q 值来生成学习数据。同样,DQN 学习最小化以下误差项:
意味着行为策略是贪婪的,其中选择状态s'中的最高 Q 值来生成学习数据。同样,DQN 学习最小化以下误差项:
![]()
现在,目标变成了为每个可能的动作找到最佳网络模型以最好地近似状态值函数Q(s, a) 。我们在这种情况下试图最小化的损失函数类似于回归问题中的损失函数,它是实际值和估计值之间的均方误差。
现在,我们将开发一个 DQN 模型来解决 Mountain Car ( https://gym.openai.com/envs/MountainCar-v0/ ) 问题。
怎么做...
我们使用 DQN 开发深度 Q 学习,如下所示:
1.导入所有必要的包:
>>> import gym
>>> import torch
>>> from torch.autograd import Variable
>>> import random该变量包装了一个张量并支持反向传播。
2.让我们从类的__init__方法开始DQN:
>>> class DQN():
... def __init__(self, n_state, n_action, n_hidden=50,
lr=0.05):
... self.criterion = torch.nn.MSELoss()
... self.model = torch.nn.Sequential(
... torch.nn.Linear(n_state, n_hidden),
... torch.nn.ReLU(),
... torch.nn.Linear(n_hidden, n_action)
... )
... self.optimizer = torch.optim.Adam(
self.model.parameters(), lr)3.我们现在开发训练方法,用数据点更新神经网络:
>>> def update(self, s, y):
... """
... Update the weights of the DQN given a training sample
... @param s: state
... @param y: target value
... """
... y_pred = self.model(torch.Tensor(s))
... loss = self.criterion(y_pred,
Variable(torch.Tensor(y)))
... self.optimizer.zero_grad()
... loss.backward()
... self.optimizer.step()4.接下来是给定状态下每个动作的状态值预测:
>>> def predict(self, s):
... """
... 使用学习模型计算所有动作的状态 Q 值
... @param s: 输入状态
... @return: Q所有动作的状态值
... """
... with torch.no_grad():
... return self.model(torch.Tensor(s))这就是DQN课堂的全部内容!现在我们可以继续开发学习算法了。
5.我们首先创建一个 Mountain Car 环境:
>>> env = gym.envs.make("MountainCar-v0")6.然后,我们定义 epsilon-greedy 策略:
>>> def gen_epsilon_greedy_policy(estimator, epsilon, n_action):
... def policy_function(state):
... if random.random() < epsilon:
... return random.randint(0, n_action - 1)
... else:
... q_values = estimator.predict(state)
... return torch.argmax(q_values).item()
... return policy_function7.现在,用 DQN 定义深度 Q 学习算法:
>>> def q_learning(env, estimator, n_episode, gamma=1.0,
epsilon=0.1, epsilon_decay=.99):
... """
... 使用 DQN 的深度 Q 学习
... @param env: 健身房环境
... @param estimator:估算器对象
... @param n_episode:剧集数
... @param gamma:折扣因子
... @param epsilon:epsilon_greedy 的参数
... @param epsilon_decay:epsilon 递减因子
... """
... for episode in range(n_episode):
... policy = gen_epsilon_greedy_policy(
estimator, epsilon, n_action)
... state = env.reset()
... is_done = False
... while not is_done:
... action = policy(state)
... next_state, reward, is_done, _ = env.step(action)
... total_reward_episode[episode] += reward
... modified_reward = next_state[0] + 0.5
... if next_state[0] >= 0.5:
... modified_reward += 100
... elif next_state[0] >= 0.25:
... modified_reward += 20
... elif next_state[0] >= 0.1:
... modified_reward += 10
... elif next_state[0] >= 0:
... modified_reward += 5
...
... q_values = estimator.predict(state).tolist()
...
... if is_done:
... q_values[action] = modified_reward
... estimator.update(state, q_values)
... break
... q_values_next = estimator.predict(next_state)
... q_values[action] = modified_reward + gamma *
torch.max(q_values_next).item()
... estimator.update(state, q_values)
... state = next_state
... print('Episode: {}, total reward: {}, epsilon:
{}'.format(episode,
total_reward_episode[episode], epsilon))
... epsilon = max(epsilon * epsilon_decay, 0.01)8.然后我们指定隐藏层的大小和学习率,并DQN相应地创建一个实例:
>>> n_state = env.observation_space.shape[0]
>>> n_action = env.action_space.n
>>> n_hidden = 50
>>> lr = 0.001
>>> dqn = DQN(n_state, n_action, n_hidden, lr)9.然后,我们使用刚刚开发的 DQN 执行深度 Q 学习 1,000 集,并跟踪每集的总(原始)奖励:
>>> n_episode = 1000
>>> total_reward_episode = [0] * n_episode
>>> q_learning(env, dqn, n_episode, gamma=.99, epsilon=.3)
Episode: 0, total reward: -200.0, epsilon: 0.3
Episode: 1, total reward: -200.0, epsilon: 0.297
Episode: 2, total reward: -200.0, epsilon: 0.29402999999999996
……
……
Episode: 993, total reward: -177.0, epsilon: 0.01
Episode: 994, total reward: -200.0, epsilon: 0.01
Episode: 995, total reward: -172.0, epsilon: 0.01
Episode: 996, total reward: -200.0, epsilon: 0.01
Episode: 997, total reward: -200.0, epsilon: 0.01
Episode: 998, total reward: -173.0, epsilon: 0.01
Episode: 999, total reward: -200.0, epsilon: 0.0110.现在,让我们展示情节奖励随时间变化的情节:
>>> import matplotlib.pyplot as plt
>>> plt.plot(total_reward_episode)
>>> plt.title('Episode reward over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Total reward')
>>> plt.show()这个怎么运作...
在步骤2中,DQN该类接受四个参数:输入状态和输出动作的数量、隐藏节点的数量(我们这里仅以一个隐藏层为例)和学习率。它用一个隐藏层初始化一个神经网络,然后是一个 ReLU 激活函数。它接收n_state单位并生成一个n_action输出,即单个动作的预测状态值。优化器 Adam 与每个线性模型一起初始化。损失函数是均方误差。
第 3 步用于更新网络:给定训练数据点,预测结果连同目标值一起用于计算损失和梯度。然后通过反向传播更新神经网络模型。
在步骤 7中,深度 Q 学习函数执行以下任务:
- 在每一集中,创建一个 epsilon 因子衰减到 99% 的 epsilon-greedy 策略(例如,如果第一集中的 epsilon 为 0.1,则第二集中将为 0.099)。我们还将 0.01 设置为 epsilon 下限。
- 运行一个情节:在状态s 的每个步骤中,通过遵循 epsilon-greedy 策略采取行动 a;然后,使用DQN中的predict方法计算先前状态的Q值q_value。
- 计算新状态s'的Q值; 然后,q_values_next通过更新旧的Q值来计算目标值q_values,对于操作,
 。
。 - 使用数据点(s, Q(s))来训练神经网络。请注意,Q(s)由所有操作的值组成。
- 运行n_episode剧集并记录每个剧集的总奖励。
您可能会注意到我们在训练模型时使用了修改后的奖励版本。它基于汽车的位置,因为我们希望它到达 +0.5 的位置。并且我们还分别对大于等于+0.5、+0.25、+0.1、0的职位给予分级激励。这种修改后的奖励设置区分了不同的汽车位置,并倾向于更接近目标的位置;因此,与最初单调的每一步 -1 奖励相比,它大大加快了学习速度。
最后,在第 10 步中,您将看到如下所示的结果图:

你可以看到在最后 200 集中,汽车在大约 170 到 180 步后到达山顶。
与使用一组中间人工特征相比,深度 Q 学习使用更直接的模型(神经网络)来近似状态值。给定一个步骤,旧状态通过采取行动转移到新状态并获得奖励,训练 DQN 涉及以下阶段:
- 使用神经网络模型来估计旧状态的Q值。
- 使用神经网络模型来估计新状态的Q值。
- 使用奖励和新Q值更新动作的目标 Q值,如

- 请注意,如果它是终端状态,则目标 Q 值将更新为 r。
- 以旧状态为输入,目标Q值为输出,训练神经网络模型。
它通过梯度下降更新网络的权重,并可以预测给定状态的 Q 值。
DQN 大大减少了要学习的状态数量,而在 TD 方法中学习数百万个状态是不可行的。而且,它直接将输入状态映射到 Q 值,不需要任何额外的函数来生成人工特征。
也可以看看
如果您不熟悉 Adam 优化器作为一种高级梯度下降方法,请查看以下资料:
- https://towardsdatascience.com/adam-latest-trends-in-deep-learning-optimization-6be9a291375c
- https://arxiv.org/abs/1412.6980
通过经验回放改进 DQN
使用一次一个样本的神经网络对 Q 值的近似不是很稳定。你会记得,在 FA 中,我们结合了经验回放来提高稳定性。同样,在这个秘籍中,我们会将经验回放应用于 DQN。
通过经验回放,我们将代理的经验(经验由旧状态、新状态、动作和奖励组成)存储在内存队列中的训练会话中。每当我们获得足够的经验时,就会从内存中随机抽取成批的经验,用于训练神经网络。Learning with experience replay 分为两个阶段:获得经验,以及根据随机选择的过去经验更新模型。否则,该模型将继续从最近的经验中学习,神经网络模型可能会陷入局部最小值。
我们将开发具有经验回放的 DQN 来解决 Mountain Car 问题。
怎么做...
我们将开发一个具有经验回放的 DQN,如下所示:
1.导入必要的模块并创建 Mountain Car 环境:
>>> import gym
>>> import torch
>>> from collections import deque
>>> import random
>>> from torch.autograd import Variable
>>> env = gym.envs.make("MountainCar-v0")2.为了合并经验回放,我们replay向类中添加了一个方法DQN:
>>> def replay(self, memory, replay_size, gamma):
... """
... 经验重播
... @param memory: 经验列表
... @param replay_size: 我们使用的样本数每次更新模型
... @param gamma: 折扣因子
... """
... if len(memory) >= replay_size:
... replay_data = random.sample(memory, replay_size)
... states = []
... td_targets = []
... for state, action, next_state, reward,
is_done in replay_data:
... states.append(state)
... q_values = self.predict(state).tolist()
... if is_done:
... q_values[action] = reward
... else:
... q_values_next = self.predict(next_state)
... q_values[action] = reward + gamma *
torch.max(q_values_next).item()
... td_targets.append(q_values)
...
... self.update(states, td_targets)班级的其余部分DQN保持不变。
3.我们将重用gen_epsilon_greedy_policy我们在开发深度 Q 网络一节 中开发的函数,这里不再赘述。
4.然后我们指定神经网络的形状,包括输入、输出和隐藏层的大小,将学习率设置为 0.001,并相应地创建一个 DQN:
>>> n_state = env.observation_space.shape[0]
>>> n_action = env.action_space.n
>>> n_hidden = 50
>>> lr = 0.001
>>> dqn = DQN(n_state, n_action, n_hidden, lr)5.接下来,我们定义保存体验的缓冲区:
>>> memory = deque(maxlen=10000)新的样本将被添加到队列中,只要10000队列中的样本多于样本,旧的样本就会被删除。
6.现在,我们定义执行经验回放的深度 Q 学习函数:
>>> def q_learning(env, estimator, n_episode, replay_size,
gamma=1.0, epsilon=0.1, epsilon_decay=.99):
... """
... 使用 DQN 的深度 Q 学习,有经验回放
... @param env: Gym 环境
... @param estimator: 估计器对象
... @param replay_size: 我们每次用来更新模型的样本数
... @param n_episode: episodes数
... @param gamma: 折扣因子
... @param epsilon: epsilon_greedy 的参数
... @param epsilon_decay: 递减因子
... """
... for episode in range(n_episode):
... policy = gen_epsilon_greedy_policy(
estimator, epsilon, n_action)
... state = env.reset()
... is_done = False
... while not is_done:
... action = policy(state)
... next_state, reward, is_done, _ = env.step(action)
... total_reward_episode[episode] += reward
... modified_reward = next_state[0] + 0.5
... if next_state[0] >= 0.5:
... modified_reward += 100
... elif next_state[0] >= 0.25:
... modified_reward += 20
... elif next_state[0] >= 0.1:
... modified_reward += 10
... elif next_state[0] >= 0:
... modified_reward += 5
... memory.append((state, action, next_state,
modified_reward, is_done))
... if is_done:
... break
... estimator.replay(memory, replay_size, gamma)
... state = next_state
... print('Episode: {}, total reward: {}, epsilon:
{}'.format(episode, total_reward_episode[episode],
epsilon))
... epsilon = max(epsilon * epsilon_decay, 0.01)7.600然后,我们执行深度 Q 学习,并对情节进行经验回放:
>>> n_episode = 600我们将20每个步骤的重放样本大小设置为:
>>> replay_size = 20我们还跟踪每一集的总奖励:
>>> total_reward_episode = [0] * n_episode
>>> q_learning(env, dqn, n_episode, replay_size, gamma=.9, epsilon=.3)8.现在,是时候显示情节奖励随时间变化的情节了:
>>> import matplotlib.pyplot as plt
>>> plt.plot(total_reward_episode)
>>> plt.title('Episode reward over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Total reward')
>>> plt.show()这个怎么运作...
在步骤2中,经验回放函数首先随机选择replay_size经验样本。然后它将每个经验转换为由输入状态和输出目标值组成的训练样本。最后,它使用选定的批次更新神经网络。
在第 6 步中,使用以下任务执行具有经验回放的深度 Q 学习:
- 在每一集中,创建一个 epsilon 因子衰减到 99% 的 epsilon-greedy 策略。
- 运行一个 episode:在每一步中,采取一个动作a,遵循 epsilon-greedy 策略;将此经验(旧状态、动作、新状态、奖励)存储在内存中。
- 在每个步骤中,进行经验回放以训练神经网络,前提是我们有足够的训练样本可以随机选择。
- 运行n_episode剧集并记录每个剧集的总奖励。
执行第 8 步中的代码行将产生以下图:

你可以看到,在最近 200 集中的大多数集中,汽车到达山顶大约需要 120 到 160 步。
在深度 Q 学习中,经验回放意味着我们存储代理的每一步经验,并随机抽取一些过去经验的样本来训练 DQN。这种情况下的学习分为两个阶段:积累经验,以及根据过去的批量经验更新模型。具体来说,经验(也称为缓冲区或记忆)包括过去的状态、采取的行动、收到的奖励和下一个状态。经验回放可以通过提供一组低相关性的样本来稳定训练,从而提高学习效率。
开发双深度 Q 网络
在我们迄今为止开发的深度 Q 学习算法中,使用相同的神经网络来计算预测值和目标值。这可能会导致很多分歧,因为目标值不断变化并且预测必须追逐它。在这个秘籍中,我们将开发一种使用两个神经网络而不是一个神经网络的新算法。
在双 DQN中,我们使用单独的网络来估计目标而不是预测网络。分离网络与预测网络具有相同的结构。并且它的权重对于每个T集都是固定的(T是我们可以调整的超参数),这意味着它们仅在每个T集之后更新。更新只需复制预测网络的权重即可完成。这样一来,目标函数就固定了一段时间,训练过程更加稳定。
在数学上,训练双 DQN 以最小化以下误差项:
这里,s'是在状态s中采取行动a后的结果状态;r是相关奖励;α 是学习率;γ 是贴现因子。此外,![]() 是目标网络的函数,Q 是预测网络的函数。
是目标网络的函数,Q 是预测网络的函数。
现在让我们使用双 DQN 解决 Mountain Car 问题。
怎么做...
我们使用双 DQN 开发深度 Q 学习,如下所示:
1.导入必要的模块并创建 Mountain Car 环境:
>>> import gym
>>> import torch
>>> from collections import deque
>>> import random
>>> import copy
>>> from torch.autograd import Variable
>>> env = gym.envs.make(“MountainCar- v0")2.为了将目标网络纳入经验回放阶段,我们首先在类的 __init__方法中对其进行初始化DQN:
>>> class DQN():
... def __init__(self, n_state, n_action,
n_hidden=50, lr=0.05):
... self.criterion = torch.nn.MSELoss()
... self.model = torch.nn.Sequential(
... torch.nn.Linear(n_state, n_hidden),
... torch.nn.ReLU(),
... torch.nn.Linear(n_hidden, n_action)
... )
... self.optimizer = torch.optim.Adam(
self.model.parameters(), lr)
... self.model_target = copy.deepcopy(self.model)目标网络与预测网络具有相同的结构。
3.因此,我们使用目标网络添加值的计算:
>>> def target_predict(self, s):
... """
... 使用目标网络计算所有动作的状态 Q 值
... @param s: 输入状态
... @return: 所有动作状态的 Q 值
... """
... with torch.no_grad():
... return self.model_target(torch.Tensor(s))4.我们还添加了同步目标网络权重的方法:
>>> def copy_target(self):
... self.model_target.load_state_dict(self.model.state_dict())5.在experience replay中,我们使用target network来计算目标值而不是prediction network:
>>> def replay(self, memory, replay_size, gamma):
... """
... 目标网络的经验重播
... @param memory: 经验列表
... @param replay_size: 我们每次用来更新模型的样本的数量
... @param gamma:折扣因子
... """
... if len(memory) >= replay_size:
... replay_data = random.sample(memory, replay_size)
... states = []
... td_targets = []
... for state, action, next_state, reward, is_done
in replay_data:
... states.append(state)
... q_values = self.predict(state).tolist()
... if is_done:
... q_values[action] = reward
... else:
... q_values_next = self.target_predict(
next_state).detach()
... q_values[action] = reward + gamma *
torch.max(q_values_next).item()
...
... td_targets.append(q_values)
...
... self.update(states, td_targets)班级的其余部分DQN保持不变。
6.我们将重用gen_epsilon_greedy_policy我们在开发深度 Q 网络 秘籍中开发的函数,这里不再赘述。
7.然后我们指定神经网络的形状,包括输入、输出和隐藏层的大小,设置0.01为学习率,并相应地创建一个 DQN:
>>> n_state = env.observation_space.shape[0]
>>> n_action = env.action_space.n
>>> n_hidden = 50
>>> lr = 0.01
>>> dqn = DQN(n_state, n_action, n_hidden, lr)8.接下来,我们定义保存体验的缓冲区:
>>> memory = deque(maxlen=10000)新的样本将被添加到队列中,只要10000队列中的样本多于样本,旧的样本就会被删除。
9.现在,我们将使用双 DQN 开发深度 Q 学习:
>>> def q_learning(env, estimator, n_episode, replay_size,
target_update=10, gamma=1.0, epsilon=0.1,
epsilon_decay=.99):
... """
... 使用双 DQN 的深度 Q 学习,与体验重播
... @param env: Gym 环境
... @param estimator: DQN 对象
... @param replay_size: 我们每次用于更新模型的样本数
... @param target_update: 更新前的剧集数目标网络
... @param n_episode: 剧集数
... @param gamma: 折扣因子
... @param epsilon: epsilon_greedy的参数
... @param epsilon_decay: 递减因子
... """
... for episode in range(n_episode):
... if episode % target_update == 0:
... estimator.copy_target()
... policy = gen_epsilon_greedy_policy(
estimator, epsilon, n_action)
... state = env.reset()
... is_done = False
... while not is_done:
... action = policy(state)
... next_state, reward, is_done, _ = env.step(action)
... total_reward_episode[episode] += reward
... modified_reward = next_state[0] + 0.5
... if next_state[0] >= 0.5:
... modified_reward += 100
... elif next_state[0] >= 0.25:
... modified_reward += 20
... elif next_state[0] >= 0.1:
... modified_reward += 10
... elif next_state[0] >= 0:
... modified_reward += 5
... memory.append((state, action, next_state,
modified_reward, is_done))
... if is_done:
... break
... estimator.replay(memory, replay_size, gamma)
... state = next_state
... print('Episode: {}, total reward: {}, epsilon:
{}'.format(episode, total_reward_episode[episode], epsilon))
... epsilon = max(epsilon * epsilon_decay, 0.01)10.我们使用双 DQN 对1000剧集执行深度 Q 学习:
>>> n_episode = 1000我们将20每个步骤的重放样本大小设置为:
>>> replay_size = 20我们每 10 集更新一次目标网络:
>>> target_update = 10我们还跟踪每一集的总奖励:
>>> total_reward_episode = [0] * n_episode
>>> q_learning(env, dqn, n_episode, replay_size, target_update, gamma=.9, epsilon=1)
Episode: 0, total reward: -200.0, epsilon: 1
Episode: 1, total reward: -200.0, epsilon: 0.99
Episode: 2, total reward: -200.0, epsilon: 0.9801
……
……
Episode: 991, total reward: -151.0, epsilon: 0.01
Episode: 992, total reward: -200.0, epsilon: 0.01
Episode: 993, total reward: -158.0, epsilon: 0.01
Episode: 994, total reward: -160.0, epsilon: 0.01
Episode: 995, total reward: -200.0, epsilon: 0.01
Episode: 996, total reward: -200.0, epsilon: 0.01
Episode: 997, total reward: -200.0, epsilon: 0.01
Episode: 998, total reward: -151.0, epsilon: 0.01
Episode: 999, total reward: -200.0, epsilon: 0.01 11.然后我们显示情节奖励随时间变化的情节:
>>> import matplotlib.pyplot as plt
>>> plt.plot(total_reward_episode)
>>> plt.title('Episode reward over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Total reward')
>>> plt.show()这个怎么运作...
在步骤5中,经验回放函数首先随机选择replay_size 经验样本。然后它将每个经验转换为由输入状态和输出目标值组成的训练样本。最后,它使用选定的批次更新预测网络。
第 9步是双 DQN 中最重要的一步:它使用不同的网络来计算目标值,然后定期更新该网络。其余功能类似于具有经验回放的深度 Q 学习。
步骤 11中的可视化函数将产生以下图:
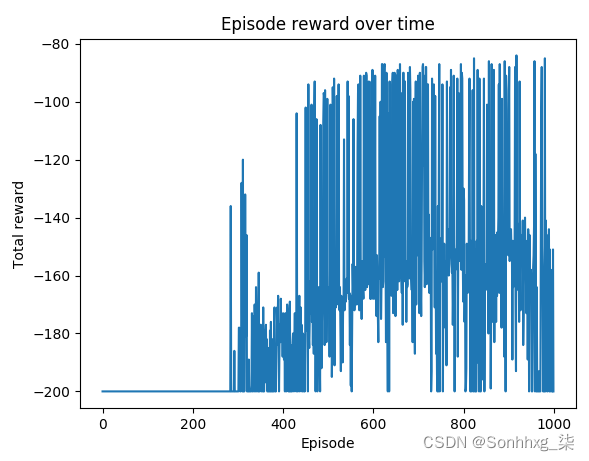
你可以看到,在大多数剧集中,在前400集之后,汽车会在大约80到160步后到达山顶。
在使用双 DQN 的深度 Q 学习中,我们创建了两个独立的网络,分别用于预测和目标计算。第一个用于预测和检索Q值,而第二个用于提供稳定的目标Q值。并且,一段时间后(假设每 10 集或 1,500 个训练步骤),我们将预测网络与目标网络同步。在这种双网络设置中,目标值是暂时固定的,而不是不断修改,因此预测网络有更稳定的目标可以学习。我们获得的结果表明双 DQN 优于单 DQN。
为 CartPole 调整双 DQN 超参数
在这个秘籍中,让我们使用双 DQN 解决 CartPole 环境。我们将演示如何微调双 DQN 中的超参数以获得最佳性能。
为了微调超参数,我们可以应用网格搜索技术来探索一组不同的值组合,并选择一个实现最佳平均性能的值。我们可以从一个粗略的值范围开始,然后逐渐缩小范围。并且不要忘记修复以下所有随机数生成器以确保可重复性:
- Gym环境随机数生成器
- epsilon-greedy 随机数生成器
- PyTorch 中神经网络的初始权重
怎么做...
我们使用双 DQN 解决 CartPole 环境,如下所示:
1.导入必要的模块并创建 CartPole 环境:
>>> import gym
>>> import torch
>>> from collections import deque
>>> import random
>>> import copy
>>> from torch.autograd import Variable
>>> env = gym.envs.make(“CartPole- v0")2.我们将重用上一节DQN开发的课程,开发双深度 Q 网络秘诀。
3.我们将重用gen_epsilon_greedy_policy我们在开发深度 Q 网络 秘籍中开发的函数,这里不再赘述。
4.现在,我们将使用双 DQN 开发深度 Q 学习:
>>> def q_learning(env, estimator, n_episode, replay_size,
target_update=10, gamma=1.0, epsilon=0.1,
epsilon_decay=.99):
... """
... 使用双 DQN 的深度 Q 学习,与体验重播
... @param env: Gym 环境
... @param estimator: DQN 对象
... @param replay_size: 我们每次用于更新模型的样本数
... @param target_update: 更新前的剧集数目标网络
... @param n_episode: 剧集数
... @param gamma: 折扣因子
... @param epsilon: epsilon_greedy 的参数
... @param epsilon_decay: epsilon 递减因子
... """
... for episode in range(n_episode):
... if episode % target_update == 0:
... estimator.copy_target()
... policy = gen_epsilon_greedy_policy(
estimator, epsilon, n_action)
... state = env.reset()
... is_done = False
... while not is_done:
... action = policy(state)
... next_state, reward, is_done, _ = env.step(action)
... total_reward_episode[episode] += reward
... memory.append((state, action,
next_state, reward, is_done))
... if is_done:
... break
... estimator.replay(memory, replay_size, gamma)
... state = next_state
... epsilon = max(epsilon * epsilon_decay, 0.01)5.然后我们指定神经网络的形状,包括输入的大小、输出的大小、隐藏层和集数,以及用于评估性能的集数:
>>> n_state = env.observation_space.shape[0]
>>> n_action = env.action_space.n
>>> n_episode = 600
>>> last_episode = 2006.然后我们为以下超参数定义一些值以在网格搜索中探索:
>>> n_hidden_options = [30, 40]
>>> lr_options = [0.001, 0.003]
>>> replay_size_options = [20, 25]
>>> target_update_options = [30, 35]7.最后,我们执行网格搜索,在每次迭代中,我们根据一组超参数创建一个 DQN,并让它学习 600 集。然后,我们通过平均最后 200 集的总奖励来评估其性能:
>>> for n_hidden in n_hidden_options:
... for lr in lr_options:
... for replay_size in replay_size_options:
... for target_update in target_update_options:
... env.seed(1)
... random.seed(1)
... torch.manual_seed(1)
... dqn = DQN(n_state, n_action, n_hidden, lr)
... memory = deque(maxlen=10000)
... total_reward_episode = [0] * n_episode
... q_learning(env, dqn, n_episode, replay_size,
target_update, gamma=.9, epsilon=1)
... print(n_hidden, lr, replay_size, target_update,
sum(total_reward_episode[-last_episode:])/last_episode)这个怎么运作...
执行完第 7 步,我们得到如下网格搜索结果:
30 0.001 20 30 143.15
30 0.001 20 35 156.165
30 0.001 25 30 180.575
30 0.001 25 35 192.765
30 0.003 20 30 187.435
30 0.003 20 35 122.42
30 0.003 25 30 169.32
30 0.003 25 35 172.65
40 0.001 20 30 136.64
40 0.001 20 35 160.08
40 0.001 25 30 141.955
40 0.001 25 35 122.915
40 0.003 20 30 143.855
40 0.003 20 35 178.52
40 0.003 25 30 125.52
40 0.003 25 35 178.85我们可以看到,最佳平均奖励是通过n_hidden=30, lr=0.001, replay_size=25、target_update=35.、和192.77的组合实现的。
随意进一步微调超参数以获得更好的 DQN 模型。
在这个秘籍中,我们用双 DQN 解决了 CartPole 问题。我们使用网格搜索微调了超参数的值。在我们的示例中,我们优化了隐藏层的大小、学习率、重放批量大小和目标网络更新频率。我们还可以探索其他超参数,例如剧集数、初始 epsilon 和 epsilon 衰减值。对于每个实验,我们保持随机种子固定,以便 Gym 环境的随机性、epsilon-greedy 动作以及神经网络的权重初始化保持不变。这是为了确保性能的再现性和可比性。每个 DQN 模型的性能都是通过最后几集的平均总奖励来衡量的。
开发决斗深度 Q 网络
在本秘籍中,我们将开发另一种高级类型的 DQN,决斗 DQN ( DDQN )。特别是,我们将看到 Q 值的计算如何在 DDQN 中分为两部分。
在 DDQNs 中,Q 值是用以下两个函数计算的:
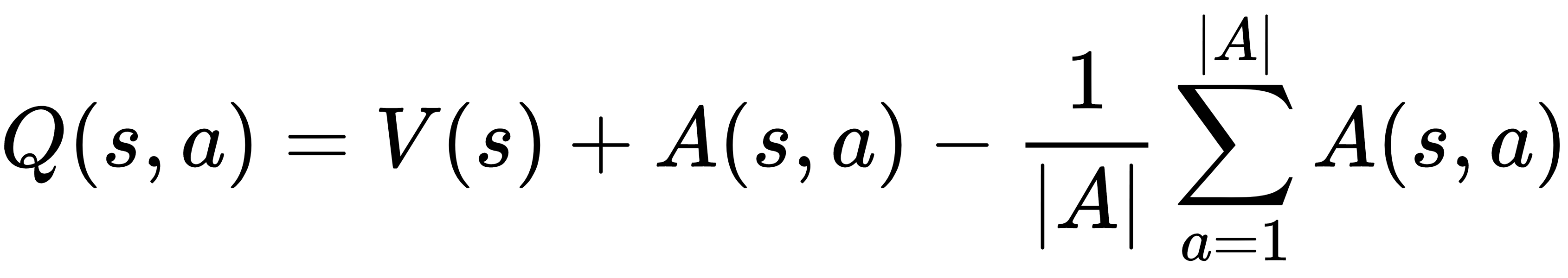
这里,V(s)是状态值函数,计算处于状态s的值;A(s, a)是依赖于状态的动作优势函数,估计在状态s下采取动作a比采取其他动作好多少。通过将 value和advantage函数解耦,我们能够适应这样一个事实,即我们的智能体在学习过程中可能不一定同时查看价值和优势。换句话说,使用 DDQN 的代理可以根据自己的喜好有效地优化其中一个或两个功能。
怎么做...
我们使用 DDQN 解决 Mountain Car 问题,如下所示:
1.导入必要的模块并创建 Mountain Car 环境:
>>> import gym
>>> import torch
>>> from collections import deque
>>> import random
>>> from torch.autograd import Variable
>>> import torch.nn as nn
>>> env = gym.envs.make("MountainCar-v0")2.接下来,我们定义DDQN模型如下:
>>> class DuelingModel(nn.Module):
... def __init__(self, n_input, n_output, n_hidden):
... super(DuelingModel, self).__init__()
... self.adv1 = nn.Linear(n_input, n_hidden)
... self.adv2 = nn.Linear(n_hidden, n_output)
... self.val1 = nn.Linear(n_input, n_hidden)
... self.val2 = nn.Linear(n_hidden, 1)
...
... def forward(self, x):
... adv = nn.functional.relu(self.adv1(x))
... adv = self.adv2(adv)
... val = nn.functional.relu(self.val1(x))
... val = self.val2(val)
... return val + adv - adv.mean()3.据此,我们在类中使用DDQN模型DQN:
>>> class DQN():
... def __init__(self, n_state, n_action, n_hidden=50, lr=0.05):
... self.criterion = torch.nn.MSELoss()
... self.model = DuelingModel(n_state, n_action, n_hidden)
... self.optimizer = torch.optim.Adam(self.model.parameters(), lr)班级的其余部分DQN保持不变。
4.我们将重用gen_epsilon_greedy_policy我们在开发深度 Q 网络秘籍中开发的功能,在此不再赘述。
5.我们将重用我们在使用经验回放改进 DQN食谱q_learning中开发的功能,在此不再重复。
6.然后我们指定神经网络的形状,包括输入、输出和隐藏层的大小,设置0.001为学习率,并相应地创建一个 DQN:
>>> n_state = env.observation_space.shape[0]
>>> n_action = env.action_space.n
>>> n_hidden = 50
>>> lr = 0.001
>>> dqn = DQN(n_state, n_action, n_hidden, lr)7.接下来,我们定义保存体验的缓冲区:
>>> memory = deque(maxlen=10000)新的样本将被添加到队列中,只要10000队列中的样本多于样本,旧的样本就会被删除。
8.然后我们使用 DDQN 对600剧集执行深度 Q 学习:
>>> n_episode = 600我们将20每个步骤的重放样本大小设置为:
>>> replay_size = 20我们还跟踪每一集的总奖励:
>>> total_reward_episode = [0] * n_episode
>>> q_learning(env, dqn, n_episode, replay_size, gamma=.9,
epsilon=.3)9.现在,我们可以显示情节奖励随时间变化的情节:
>>> import matplotlib.pyplot as plt
>>> plt.plot(total_reward_episode)
>>> plt.title('Episode reward over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Total reward')
>>> plt.show()这个怎么运作...
第2步是Dueling DQN的核心部分。它由两部分组成,动作优势( adv ) 和状态值( val )。同样,我们以一个隐藏层为例。
执行第 9 步将产生以下图:

在 DDQNs 中,预测的 Q 值是两个元素的结果:状态值和动作优势。第一个估计在某种状态下有多好。第二个表示与替代方案相比,采取特定行动要好多少。这两个元素分别计算并组合到 DQN 的最后一层。您会记得,传统的 DQN 仅更新状态下给定动作的 Q 值。DDQNs 更新所有动作(不仅仅是给定的动作)可以利用的状态值,以及动作的优势。因此,DDQN 被认为更健壮。
将深度 Q 网络应用于 Atari 游戏
到目前为止,我们处理的问题都相当简单,应用 DQN 有时有点矫枉过正。在这个和下一个秘籍中,我们将使用 DQN 来解决 Atari 游戏,这些问题要复杂得多。
我们将使用 Pong ( https://gym.openai.com/envs/Pong-v0/ ) 作为本食谱中的示例。它模拟 Atari 2600 游戏 Pong,其中代理与另一位玩家打乒乓球。在这个环境中观察到的是屏幕的RGB图像(参考下面的截图):

这是一个形状为 (210, 160, 3) 的矩阵,这意味着图像的大小为210 * 160,并且具有三个 RGB 通道。
代理人(右侧)在比赛期间上下移动以击球。如果没中,另一位玩家(左边)得 1 分;类似地,如果其他玩家未命中,则代理将获得 1 分。谁先得到 21 分,谁就是游戏的赢家。代理在 Pong 环境中可以采取以下 6 种可能的操作:
- 0:NOOP:代理保持静止
- 1:FIRE:不是有意义的动作
- 2:RIGHT:代理向上移动
- 3:LEFT:代理向下移动
- 4:RIGHTFIRE:与 2 相同
- 5:LEFTFIRE:与5相同
每个动作在k帧的持续时间内重复执行( k可以是 2、3、4 或 16,具体取决于 Pong 环境的特定变体)。奖励为以下任意一项:
- -1:代理人错过了球。
- 1:对方丢球。
- 0:否则。
Pong 中210 * 160 * 3的观察空间比我们习惯处理的要大很多。因此,我们将图像缩小到84 * 84并将其转换为灰度,然后再使用 DQN 来解决它。
怎么做...
我们将从探索 Pong 环境开始,如下所示:
1.导入必要的模块并创建 Pong 环境:
>>> import gym
>>> import torch
>>> import random
>>> env = gym.envs.make("PongDeterministic-v4")在此 Pong 环境变体中,一个动作是确定性的,并在 16 帧的持续时间内重复执行。
2.看看观察空间和动作空间:
>>> state_shape = env.observation_space.shape
>>> n_action = env.action_space.n
>>> print(state_shape)
(210, 160, 3)
>>> print(n_action)
6
>>> print(env.unwrapped.get_action_meanings())
['NOOP', 'FIRE', 'RIGHT', 'LEFT', 'RIGHTFIRE', 'LEFTFIRE']3.指定三个动作:
>>> ACTIONS = [0, 2, 3]
>>> n_action = 3这些动作不是移动,是向上移动,是向下移动。
4.让我们采取随机行动并渲染屏幕:
>>> env.reset()
>>> is_done = False
>>> while not is_done:
... action = ACTIONS[random.randint(0, n_action - 1)]
... obs, reward, is_done, _ = env.step(action)
... print(reward, is_done)
... env.render()
0.0 False
0.0 False
0.0 False
……
……
0.0 False
0.0 False
0.0 False
-1.0 True你会在屏幕上看到两个玩家正在打乒乓球,尽管代理输了。
5.现在,我们开发一个屏幕处理函数来缩小图像并将其转换为灰度:
>>> import torchvision.transforms as T
>>> from PIL import Image
>>> image_size = 84
>>> transform = T.Compose([T.ToPILImage(),
... T.Grayscale(num_output_channels=1),
... T.Resize((image_size, image_size),
interpolation=Image.CUBIC),
... T.ToTensor(),
... ])现在,我们只定义一个将图像缩小到84 * 84的缩放器:
>>> def get_state(obs):
... state = obs.transpose((2, 0, 1))
... state = torch.from_numpy(state)
... state = transform(state)
... return state此函数将调整后的图像重新整形为大小 (1, 84, 84):
>>> state = get_state(obs)
>>> print(state.shape)
torch.Size([1, 84, 84])现在,我们可以开始使用双 DQN 解决环境问题,如下所示:
1.此时我们将使用具有两个隐藏层的更大的神经网络,因为输入大小约为 21,000:
>>> from collections import deque
>>> import copy
>>> from torch.autograd import Variable
>>> class DQN():
... def __init__(self, n_state, n_action, n_hidden, lr=0.05):
... self.criterion = torch.nn.MSELoss()
... self.model = torch.nn.Sequential(
... torch.nn.Linear(n_state, n_hidden[0]),
... torch.nn.ReLU(),
... torch.nn.Linear(n_hidden[0], n_hidden[1]),
... torch.nn.ReLU(),
... torch.nn.Linear(n_hidden[1], n_action)
... )
... self.model_target = copy.deepcopy(self.model)
... self.optimizer = torch.optim.Adam(
self.model.parameters(), lr)2.该课程的其余部分与开发双深度 Q 网络食谱DQN中的课程相同,只是对方法进行了一些小改动: replay
>>> def replay(self, memory, replay_size, gamma):
... """
... 目标网络的经验重播
... @param memory: 经验列表
... @param replay_size: 我们 每次用来更新模型的样本的数量我们
... @param gamma:折扣因子
... """
... if len(memory) >= replay_size:
... replay_data = random.sample(memory, replay_size)
... states = []
... td_targets = []
... for state, action, next_state, reward,
is_done in replay_data:
... states.append(state.tolist())
... q_values = self.predict(state).tolist()
... if is_done:
... q_values[action] = reward
... else:
... q_values_next = self.target_predict(
next_state).detach()
... q_values[action] = reward + gamma *
torch.max(q_values_next).item()
... td_targets.append(q_values)
... self.update(states, td_targets)3.我们将重用gen_epsilon_greedy_policy我们在开发深度 Q 网络秘籍中开发的函数,这里不再赘述。
4.现在,我们将使用双 DQN 开发深度 Q 学习:
>>> def q_learning(env, estimator, n_episode, replay_size,
target_update=10, gamma=1.0, epsilon=0.1,
epsilon_decay=.99):
... """
... 使用双 DQN 的深度 Q 学习,与体验重播
... @param env: Gym 环境
... @param estimator: DQN 对象
... @param replay_size: 我们每次用于更新模型的样本数
... @param target_update: 更新前的剧集数目标网络
... @param n_episode: 剧集数
... @param gamma: 折扣因子
... @param epsilon: epsilon_greedy 的参数
... @param epsilon_decay: epsilon 递减因子
... """
... for episode in range(n_episode):
... if episode % target_update == 0:
... estimator.copy_target()
... policy = gen_epsilon_greedy_policy(
estimator, epsilon, n_action)
... obs = env.reset()
... state = get_state(obs).view(image_size * image_size)[0]
... is_done = False
... while not is_done:
... action = policy(state)
... next_obs, reward, is_done, _ =
env.step(ACTIONS[action])
... total_reward_episode[episode] += reward
... next_state = get_state(obs).view(
image_size * image_size)
... memory.append((state, action, next_state,
reward, is_done))
... if is_done:
... break
... estimator.replay(memory, replay_size, gamma)
... state = next_state
... print('Episode: {}, total reward: {}, epsilon:
{}'.format(episode, total_reward_episode[episode],
epsilon))
... epsilon = max(epsilon * epsilon_decay, 0.01)给定大小[210, 160, 3]的观察值,这会将其转换为更小大小的灰度矩阵[84, 84]并将其展平,以便我们可以将其馈送到我们的网络中。
5.现在,我们指定神经网络的形状,包括输入层和隐藏层的大小:
>>> n_state = image_size * image_size
>>> n_hidden = [200, 50]其余超参数如下:
>>> n_episode = 1000
>>> lr = 0.003
>>> replay_size = 32
>>> target_update = 10现在,我们相应地创建一个 DQN:
>>> dqn = DQN(n_state, n_action, n_hidden, lr)6.接下来,我们定义保存体验的缓冲区:
>>> memory = deque(maxlen=10000)7.最后,我们执行深度 Q 学习并跟踪每一集的总奖励:
>>> total_reward_episode = [0] * n_episode
>>> q_learning(env, dqn, n_episode, replay_size, target_update, gamma=.9, epsilon=1)这个怎么运作...
Pong 中的观察比我们在本章中迄今为止使用的环境复杂得多。它是一个210 * 160屏幕大小的三通道图像。因此,我们首先将其转换为灰度图像,将其缩小为84 * 84,然后将其展平,以便将其输入全连接神经网络。由于我们有大约 6,000 维的输入,我们使用两个隐藏层来适应复杂性。
在 Atari 游戏中使用卷积神经网络
在之前的秘籍中,我们将 Pong 环境中观察到的每个图像都视为一个灰度数组,并将其提供给一个全连接的神经网络。扁平化图像实际上可能会导致信息丢失。为什么我们不使用图像作为输入呢?在这个秘籍中,我们会将卷积神经网络( CNN ) 合并到 DQN 模型中。
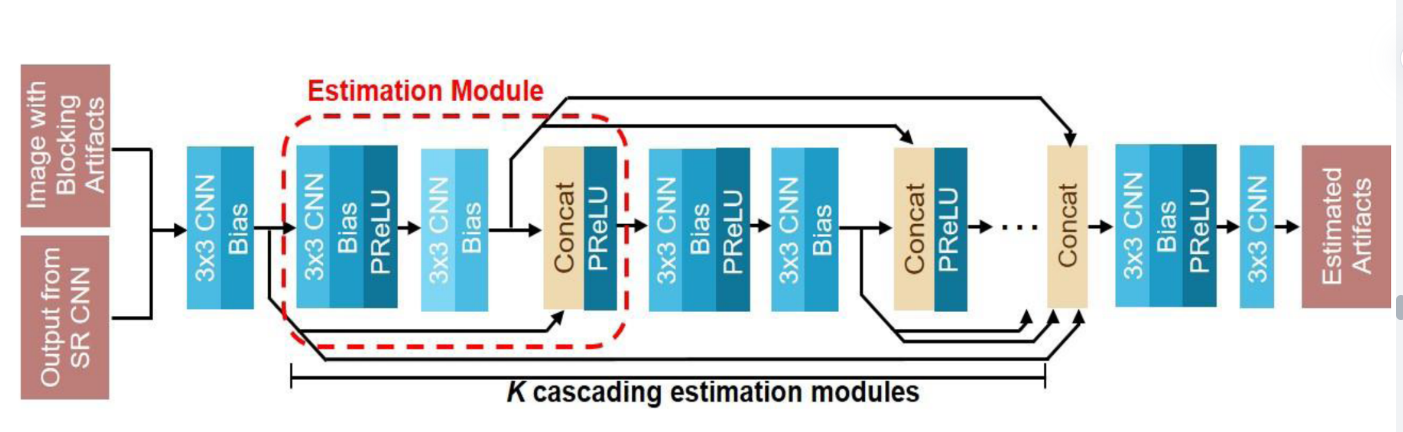
CNN 是处理图像输入的最佳神经网络架构之一。在 CNN 中,卷积层能够有效地从图像中提取特征,这些特征将传递到下游的全连接层。此处描述了具有两个卷积层的 CNN 示例:
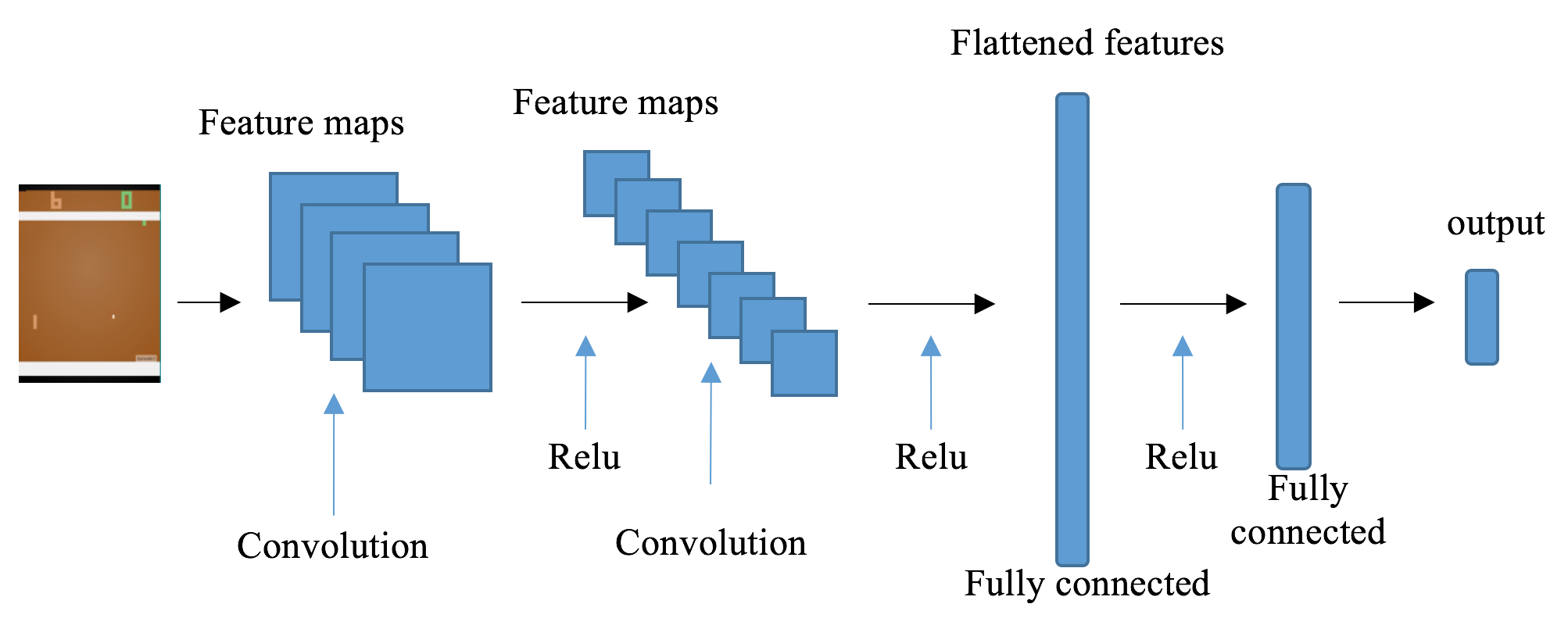
可以想象,如果我们只是将图像扁平化为矢量,我们将丢失一些关于球所在位置以及两名球员所在位置的信息。这些信息对模型学习很重要。通过 CNN 中的卷积运算,此类信息由多个过滤器生成的一组特征图表示。
同样,我们将图像从210 * 160缩小到84 * 84,但保留了三个 RGB 通道,这次没有将它们展平为一个数组。
怎么做...
让我们使用基于 CNN 的 DQN 解决 Pong 环境,如下所示:
1.导入必要的模块并创建 Pong 环境:
>>> import gym
>>> import torch
>>> import random
>>> from collections import deque
>>> import copy
>>> from torch.autograd import Variable
>>> import torch.nn as nn
>>> import torch.nn.functional as F
>>> env = gym.envs.make("PongDeterministic-v4")2.然后,我们指定三个动作:
>>> ACTIONS = [0, 2, 3]
>>> n_action = 3这些动作不是移动,是向上移动,是向下移动。
3.现在,我们开发一个图像处理函数来缩小图像:
>>> import torchvision.transforms as T
>>> from PIL import Image
>>> image_size = 84
>>> transform = T.Compose([T.ToPILImage(),
... T.Resize((image_size, image_size),
interpolation=Image.CUBIC),
... T.ToTensor()])
We now define a resizer that downsizes the i我们现在定义一个将图像缩小到84 * 84的缩放器,然后我们将图像重塑为 ( 3, 84, 84 ):
>>> def get_state(obs):
... state = obs.transpose((2, 0, 1))
... state = torch.from_numpy(state)
... state = transform(state).unsqueeze(0)
... return state4.现在,我们开始通过开发CNN模型来解决Pong环境:
>>> class CNNModel(nn.Module):
... def __init__(self, n_channel, n_action):
... super(CNNModel, self).__init__()
... self.conv1 = nn.Conv2d(in_channels=n_channel,
out_channels=32, kernel_size=8, stride=4)
... self.conv2 = nn.Conv2d(32, 64, 4, stride=2)
... self.conv3 = nn.Conv2d(64, 64, 3, stride=1)
... self.fc = torch.nn.Linear(7 * 7 * 64, 512)
... self.out = torch.nn.Linear(512, n_action)
...
... def forward(self, x):
... x = F.relu(self.conv1(x))
... x = F.relu(self.conv2(x))
... x = F.relu(self.conv3(x))
... x = x.view(x.size(0), -1)
... x = F.relu(self.fc(x))
... output = self.out(x)
... return output5.我们现在将使用我们刚刚在模型中定义的 CNNDQN模型:
>>> class DQN():
... def __init__(self, n_channel, n_action, lr=0.05):
... self.criterion = torch.nn.MSELoss()
... self.model = CNNModel(n_channel, n_action)
... self.model_target = copy.deepcopy(self.model)
... self.optimizer = torch.optim.Adam(
self.model.parameters(), lr)6.该课程的其余部分与开发双深度 Q 网络食谱DQN中的课程相同,只是replay对方法进行了一些小改动:
>>> def replay(self, memory, replay_size, gamma):
... """
... 目标网络的经验重播
... @param memory: 经验列表
... @param replay_size: 我们每次用来更新模型的样本的数量
... @param gamma: 折扣因子
... """
... if len(memory) >= replay_size:
... replay_data = random.sample(memory, replay_size)
... states = []
... td_targets = []
... for state, action, next_state, reward,
is_done in replay_data:
... states.append(state.tolist()[0])
... q_values = self.predict(state).tolist()[0]
... if is_done:
... q_values[action] = reward
... else:
... q_values_next = self.target_predict(
next_state).detach()
... q_values[action] = reward + gamma *
torch.max(q_values_next).item()
... td_targets.append(q_values)
... self.update(states, td_targets)7.我们将重用gen_epsilon_greedy_policy我们在开发深度 Q 网络 秘籍中开发的函数,这里不再赘述。
8.现在,我们使用双 DQN 开发深度 Q 学习:
>>> def q_learning(env, estimator, n_episode, replay_size,
target_update=10, gamma=1.0, epsilon=0.1,
epsilon_decay=.99):
... """
... 使用双 DQN 的深度 Q 学习,与体验重播
... @param env: Gym 环境
... @param estimator: DQN 对象
... @param replay_size: 我们每次用于更新模型的样本数
... @param target_update: 更新前的剧集数目标网络
... @param n_episode: 剧集数
... @param gamma: 折扣因子
... @param epsilon: epsilon_greedy 的参数
... @param epsilon_decay: epsilon 递减因子
... """
... for episode in range(n_episode):
... if episode % target_update == 0:
... estimator.copy_target()
... policy = gen_epsilon_greedy_policy(
estimator, epsilon, n_action)
... obs = env.reset()
... state = get_state(obs)
... is_done = False
... while not is_done:
... action = policy(state)
... next_obs, reward, is_done, _ =
env.step(ACTIONS[action])
... total_reward_episode[episode] += reward
... next_state = get_state(obs)
... memory.append((state, action, next_state,
reward, is_done))
... if is_done:
... break
... estimator.replay(memory, replay_size, gamma)
... state = next_state
... print('Episode: {}, total reward: {}, epsilon: {}'
.format(episode, total_reward_episode[episode], epsilon))
... epsilon = max(epsilon * epsilon_decay, 0.01)9.然后我们指定剩余的超参数如下:
>>> n_episode = 1000
>>> lr = 0.00025
>>> replay_size = 32
>>> target_update = 10相应地创建一个 DQN:
>>> dqn = DQN(3, n_action, lr)10.接下来,我们定义保存体验的缓冲区:
>>> memory = deque(maxlen=100000)11.最后,我们执行深度 Q 学习并跟踪每一集的总奖励:
>>> total_reward_episode = [0] * n_episode
>>> q_learning(env, dqn, n_episode, replay_size, target_update, gamma=.9, epsilon=1)这个怎么运作...
步骤 3中的图像预处理函数首先将每个通道的图像缩小到84 * 84,然后将其尺寸更改为(3, 84, 84)。这是为了确保将具有正确尺寸的图像提供给网络。
在步骤 4中,CNN 模型具有三个卷积层和每个卷积层之后的 ReLU 激活函数。最后一个卷积层生成的特征图然后被展平并馈送到具有 512 个节点的完全连接的隐藏层,然后是输出层。
将 CNN 合并到 DQN 中首先由 DeepMind 提出,发表于Playing Atari with Deep Reinforcement Learning ( https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf )。该模型将图像像素作为输入并输出估计的未来奖励值。它也适用于观察游戏屏幕图像的其他 Atari 游戏环境。卷积组件是一组有效的分层特征提取器。他们可以从复杂环境中的原始图像数据中学习特征表示,并为它们提供全连接层以学习成功的控制策略。
请记住,前面示例中的训练通常需要几天时间,即使在 GPU 上也是如此,而在 2.9 GHz Intel i7 四核 CPU 上则需要大约 90 个小时。
如果您不熟悉 CNN,请查看以下资料:
- 第 4 章,来自使用 Python 的动手深度学习架构的CNN 架构(Packt Publishing,Yuxi (Hayden) Liu 和 Saransh Mehta 着)
- 第 1 章,使用卷积神经网络进行手写数字识别,以及第 2 章,R 深度学习项目中智能车辆的交通标志识别(Packt Publishing,作者:Yuxi (Hayden) Liu 和 Pablo Maldonado)


![[附源码]JAVA毕业设计学生公寓管理系统(系统+LW)](https://img-blog.csdnimg.cn/dc565216e6324f20bb60a48e1b24002e.png)