1. 版本说明
本文档内容基于 flink-1.14.x,其他版本的整理,请查看本人博客的 flink 专栏其他文章。
2. 概述
Flink 是一种通用性框架,支持多种不同的部署方式。
本章简要介绍 Flink 集群的组成部分、用途和可用实现。如果你只是想在本地启动一个 Flink,我们建议你部署一个 Standalone 集群。
2.1. 概述和架构详解
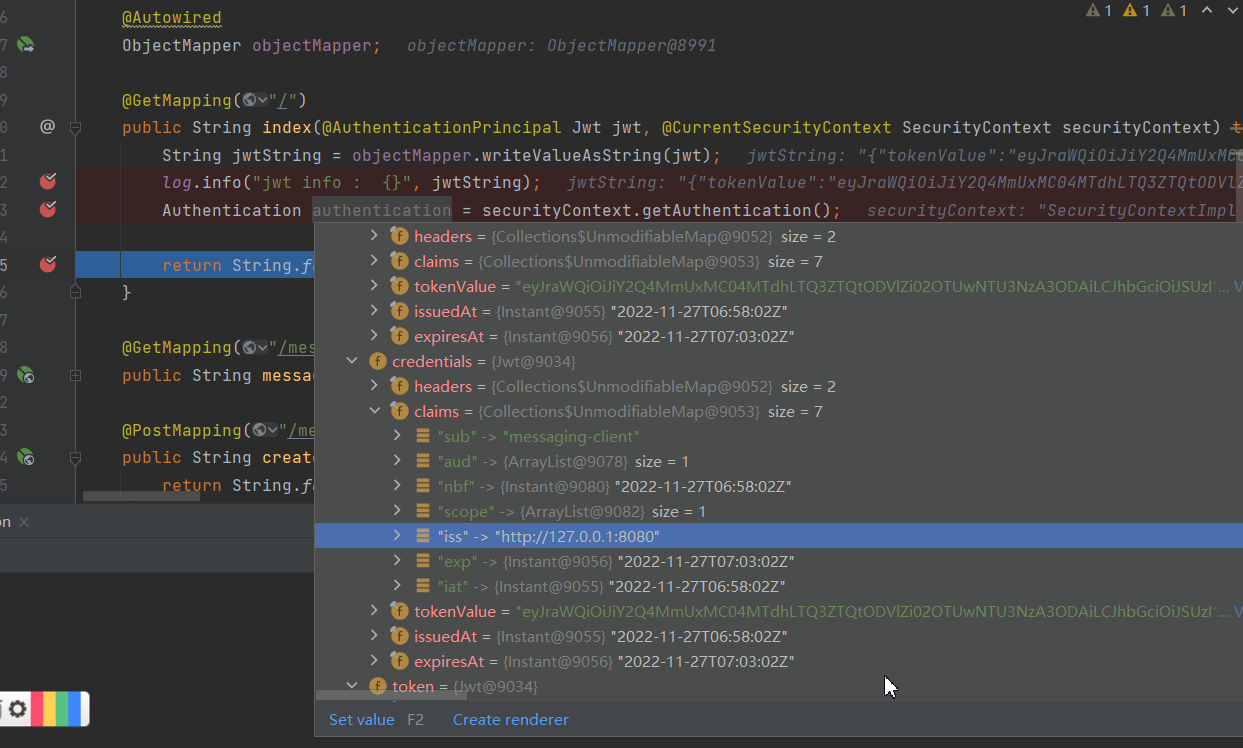
下图展示的是每个 Flink 集群的组成部分。首先会有一个在某处一直运行的客户端,这个客户端会将 Flink 应用程序中的代码转换为 JobGraph,并将其提交给 JobManager。
JobManager 会将任务分布到 TaskManager 中,TaskManager 会一直运行真正的算子,比如:source、转换、sink。
在部署 Flink 时,会有多个组成部分参与部署,我们已经将他们放到了下图下面的表格中。
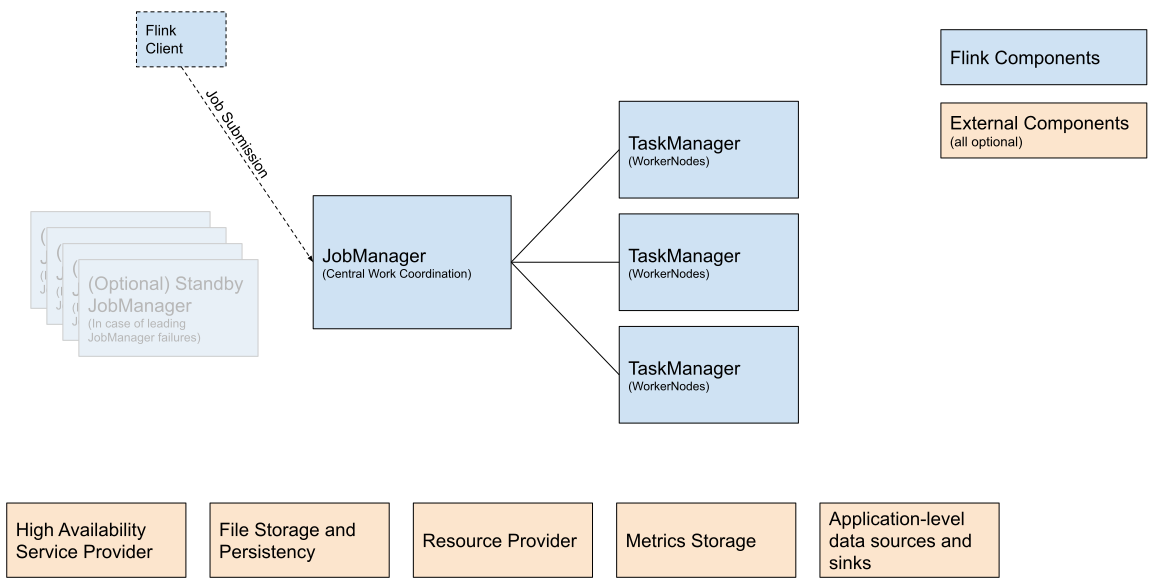
| 组件Component | 作用 | 实现方式 |
|---|---|---|
| Flink Client | 编译批或流程序为工作流执行图,之后该执行图会被提交给 JobManager。 | Command Line Interface REST Endpoint SQL Client Python REPL Scala REPL |
| JobManager | JobManager 是 Flink 工作协调组件的名称,JobManager 根据高可用、资源收集行为和支持的任务提交模式的不同,对不同的资源提供者有不同的实现。 JobManager 的任务提交模式: Application 模式:对每个程序单独运行一个集群,作业的主函数或客户端会在 JobManager 中执行。可以在一个程序中多次调用 execute/executeAsync。Per-Job 模式:对每个作业单独运行一个集群,作业的主函数或客户端只会在创建集群之前运行。 Session 模式:一个集群中运行多个作业的 TaskManager 会共享一个 JobManager。 | Standalone,这是 Flink 集群的标准模式,它只要求启动多个 JVM。通过 Docker, Docker Swarm / Compose, non-native Kubernetes 和其他模型部署这种模式也是可行的。 Kubernetes YARN |
| TaskManager | TaskManager 是真正执行 Flink 作业任务的服务。 | |
| 外部组件 (均可选) | ||
| 高可用服务提供者 | Flink 的 JobManager 可以在高可用模式下运行,该方式允许 Flink 作业在 JobManager 失败时进行恢复。为了更快的失败恢复,可以启动多个备用 JobManager。 | Zookeeper Kubernetes HA |
| 文件存储和持久化 | 对于用来恢复流作业的 checkpointing 来说,Flink 需要外部文件存储系统。 | 具体查看 FileSystems |
| 资源提供者 | Flink 可以通过不同的资源提供框架来部署,比如:Kubernetes、YARN、Mesos。 | 具体查看 JobManager 实现 |
| 指标存储 | Flink 组件会上报自己内部指标,Flink 作业也可以上报额外的作业特定的指标。 | 具体查看 指标上报 |
| 应用程序级别的数据 source 和 sink | 当应用程序级别的数据 source 和 sink 对应的组件不是 Flink 集群组件的一部分时,在计划新的 Flink 生产部署时,应该单独处理一下他们。将在 flink 作业中频繁使用的数据 source 和 sink 对应组件的依赖和 flink 放到一起可以显著提升性能。 | 比如: Apache Kafka Amazon S3 ElasticSearch Apache Cassandra 具体查看 Connectors |
2.2. 部署模式
可以通过以下三种方式中的一种执行 Flink 程序:
- Application Mode
- Per-Job Mode
- Session Mode
上面模式的不同点:
- 集群生命周期和资源隔离保证
- 应用程序的
main()方法是在客户端执行还是在集群上执行
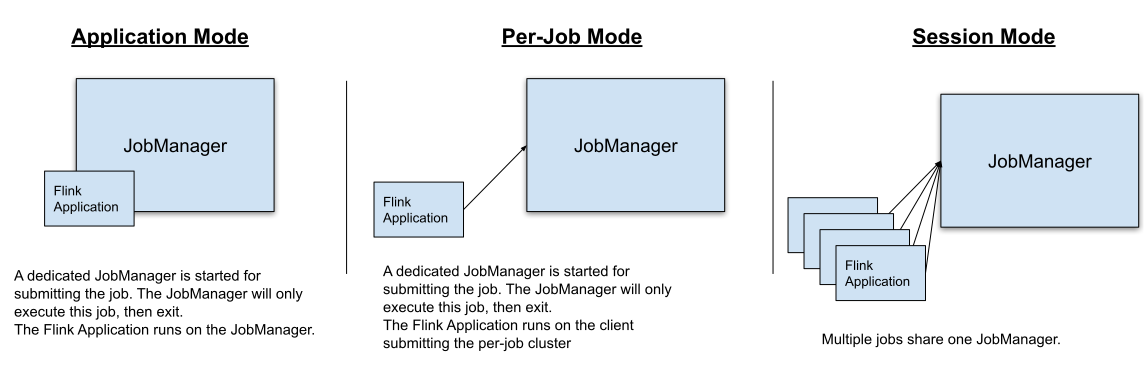
2.2.1. Application Mode
在其他所有的模式中,应用程序的 main() 方法都是在客户端侧执行,该执行步骤包括在本地下载应用程序依赖、执行 main() 方法来提取 Flink 运行时可以理解的代表物,比如 JobGraph、以及上传依赖和 JobGraph 到集群,这会造成客户端消耗大量的资源,包括占用一定的网络宽带来下载依赖并且上传二进制包到集群,占用 CPU 周期来执行 main() 方法。该问题在多个用户共享客户端时会更加明显。
Application 模式会对每个提交的程序创建一个集群,并且在 JobManager 中执行应用的 main() 方法。对每个应用创建一个集群的行为,可以将其看做为对一个作业单独创建了一个 session 集群,并且在应用程序完成后关闭。在这个架构下,Application 模式和 Per-Job 模式有相同的资源隔离和负载均衡保证,但其粒度是整个应用程序。
Application 模式会假设用户的 jar 已经在 classpath (usrlib 目录)中,并且 Flink 所有的组件(JobManager、TaskManager)都可以访问他们。换句话说,你的程序已经和 Flink 分布式捆绑到一起了。这种方式可以加快应用程序的部署和恢复进程,但是并不需要像其他模式模式一样通过 RPC 来分布式传输用户 jar 到 Flink 组件。
Application 模式会假设用户的 jar 已经在 classpath 中了。
在集群上执行
main()方法对你的代码来说可能还有其他的含义,比如你在环境中使用registerCachedFile()注册的任何路径,都必须可以被 JobManager 访问。注:如果这个路径对应的是本地文件,但是你把你的 Flink 程序部署到容器中了,则启动的 JobManager 就无法访问这个路径了。
相比于 Per-Job 模式,Application 模式运行程序提交多个作业组合的应用程序。作业执行的顺序不受部署模式的影响,而是受作业中启动方法调用的影响。
- 使用
execute()函数会造成阻塞,这会导致下个作业只能在当前这个作业完成后才会启动。 - 使用
executeAsync()函数不会造成阻塞,在当前作业完成之前,下个作业也会启动。
Application 模式运行包含多个
execute()函数调用的程序,但是在这种情况下不支持高可用。Application 模式的高可用只支持包含单个execute()函数调用的程序。另外,当在 Application 模式下运行的包含多个作业的程序(比如通过调用
executeAsync()方法),其中任何一个作业被去掉,则所有的作业都会被停止,并且 JobManager 也会停止。支持常规作业的完成,比如 source 关闭。
2.2.2. Per-Job模式
为了提供更好的资源隔离保证,Per-Job 模式使用资源提供者框架(比如:YARN、Kubernetges)对每个提交的作业都会启动一个集群,该集群只对这个作业可用。当作业完成时,集群会关闭,并且清除所有的缓存资源,比如文件。这可以保证更好的资源隔离,对于有问题的作业,只能关闭它自己的 TaskManager。另外,该模式会将压力分散给多个 JobManager,以为每个作业都有一个 JobManager。因此,Per-Job 资源分配模型是很多生产案例的首选。
2.2.3. Session模式
Session 模式假设已经有一个正在运行的集群了,并且使用该集群的资源来执行被提交的作业。同一个 session 集群中运行的程序会使用相同的资源进行计算。这样做的好处是,你无需为每个提交的作业启动一个完整的集群而消耗更多的资源。但是,如果某个有问题的作业造成 TaskManager 停止,则所有运行在该 TaskManager 上的作业都会被停止。除了失败的作业会造成负面影响外,还还意味着可能会出现大规模作业恢复,所有重新启动的作业都会并发地访问文件系统,使其他服务无法使用该文件系统。此外,让一个集群运行多个作业意味着 JobManager 将承受更多的负载,JobManager 需要负责集群中所有作业的监控。
2.2.4. 总结
在 Session 模式中,集群的生命周期独立于集群中运行的任何作业,并且所有的作业都可以共享资源。Per-Job 模式对每个被提交的作业都会单独的集群而造成额外的资源消耗,但是这会有更好的资源隔离保证,资源并不会在作业之间共享。这种情况下,集群的生命周期绑定与在其上运行的作业。最后,Application 模式会对每个程序创建一个 session 集群,并且在集群中执行应用程序的 main() 方法。
2.3. 供应商解决方案
很多供应商都提供了管理或全套的 Flink 解决方案,但是这些供应商都没有得到 Apache Flink PMC 的官方支持,请参考供应商的文档说明来了解如何在生产上使用他们。
2.3.1. 阿里云实时计算
官网
支持环境: 阿里云
2.3.1.1. Amazon EMR
官网
支持环境: AWS
2.3.1.2. Amazon Kinesis Data
官网
支持环境: AWS
2.3.1.3. Cloudera DataFlow
官网
支持环境: AWS Azure Google On-Premise
2.3.1.4. Eventador
官网
支持环境: AWS
2.3.1.5. 华为云流服务
官网
支持环境: 华为
2.3.1.6. Ververica平台
官网
支持环境: AliCloud AWS Azure Google On-Premise
3. 资源提供者
3.1. 原生Kubernetes
该章描述如何原生地部署 flink 到 Kubernetes 上。
3.1.1. 入门指南
该入门指南章节会指导你在 Kubernetes 上安装一个完成功能的 flink 集群。
3.1.1.1. 概述
Kubernetes 是一个受欢迎的容器管理系统,它可以自动完成应用程序部署,扩容和管理。flink 的原生 Kubernetes 整合允许你直接将 flink 部署到一个正在运行的 Kubernetes 集群上。另外,取决于请求的资源,flink 也可以动态分配和清理 TaskManager,因为 flink 可以直接和 Kubernetes 对话。
3.1.1.2. 准备
入门指南章节驾驶已经运行的 Kubernetes 就能已经满足了以下要求:
- Kubernetes >= 1.9.
- 可以通过
~/.kube/config配置的可以列出、创建、删除 pod 和服务的 KubeConfig,可以通过运行kubectl auth can-i <list|create|edit|delete> pods命令来校验权限。 - 启用 Kubernetes DNS.
- 默认服务账号有创建、删除 pod 的 RBAC 权限。
如果有部署Kubernetes 集群的疑问,可以参考 如何部署 Kubernetes 集群。
3.1.1.3. 在Kubernetes上启动Flink Session
一旦你有了一个正在运行的Kubernetes 集群,并且配置了 kubectl 来指向它,你就可以通过一下方式来启动一个 Session 模式 的 flink 集群:
# (1) 启动 Kubernetes 会话
$ ./bin/kubernetes-session.sh -Dkubernetes.cluster-id=my-first-flink-cluster
# (2) 提交 flink 案例 job
$ ./bin/flink run \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster \
./examples/streaming/TopSpeedWindowing.jar
# (3) 通过删除集群部署来停止 Kubernetes 会话
$ kubectl delete deployment/my-first-flink-cluster
在使用 Minikube 时,你需要调用
minikube tunnel以在Minikube 上暴露 Flink 的负载平衡服务
恭喜!你已经成功地通过在 Kubernetes 上部署 flink 来运行 flink 程序了。
3.1.2. 部署模式
对于生产案例,我们建议使用 Application 模式 来部署 flink 程序,该模式对程序提供了很好的隔离性。
3.1.2.1. Application模式
请参考 部署模式概述 来获取 application 模式更高级的相关知识。
Application 模式 要求用户代码已经和 flink 镜像捆绑到一起了,因为该模式会在集群上运行用户代码的 main() 方法,application 模式会在程序终止后确保清除所有的 flink 组件。
flink 社区提供了一个可以被用于捆绑用户代码的 基础 Docker 镜像。
FROM flink
RUN mkdir -p $FLINK_HOME/usrlib
COPY /path/of/my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
在使用**自定义镜像名称 custom-image-name **创建和发布了 Docker 镜像之后,你就可以通过如下命令来启动一个 application 集群了:
$ ./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=custom-image-name \
local:///opt/flink/usrlib/my-flink-job.jar
注:local 只支持 Application 模式 schema。
kubernetes.cluster-id 选项用来指定集群名称,并且是必选项。如果没有指定该选项,则 Flink 会生成一个随机名称。
kubernetes.container.image 选项指定启动 pod 的镜像。
application 集群一旦部署完毕,你就可以与它互动了:
# 列出集群上运行的 job
$ ./bin/flink list --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster
# 取消运行的 job
$ ./bin/flink cancel --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster <jobId>
你可以通过在 bin/flink 后设置 -Dkey=value 格式的 key-value 对来覆盖 conf/flink-conf.yaml 中的配置。
3.1.2.2. Per-Job模式
请参考 部署模式概述 来获取 application 模式更高级的相关知识。
Flink on Kubernetes 不支持 Per-Job 集群模式。
3.1.2.3. Session模式
请参考 部署模式概述 来获取 application 模式更高级的相关知识。
已经在上面的入门指南章节中描述了如何部署一个 Session 集群了。
Session 模式可以通过两种模式执行:
- detached mode (分离模式,默认):
kubernetes-session.sh脚本会在 Kubernetes 上部署 flink 集群,然后终止本地客户端。 - attached mode (附加模式,
-Dexecution.attached=true):kubernetes-session.sh本地客户端会保持运行,并且允许使用命令来控制运行的 flink 集群。比如通过stop命令来停止正在运行的 Session 集群,通过help命令来列出所有支持的命令。
可以通过如下命令来重新附加正在运行的 Session 集群到 my-first-flink-cluster 集群 id 上:
$ ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=true
你可以通过在运行 bin/kubernetes-session.sh 脚本时添加 -Dkey=value 格式的 key-value 对来覆盖 conf/flink-conf.yaml 文件中的配置。
3.1.2.3.1. 停止运行的Session集群
你可以通过删除 Flink 部署 或使用如下命令来停止 cluster id 为 my-first-flink-cluster 的 Session 集群:
$ echo 'stop' | ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=true
3.1.3. Flink on Kubernetes指南
3.1.3.1. 在Kubernetes上配置Flink
可以在配置页面找到 Kubernetes 相关配置选项。
flink 通过 Fabric8 Kubernetes client 和 Kubernetes APIServer进行交互,以 创建/删除 Kubernetes 资源,比如:部署、Pod、ConfigMap、Service 等,同时也包括查看 Pod 和 ConfigMap。除了上面提到的 flink 配置选项,也可以通过系统属性或环境变量配置的专家选项来配置 Fabric8 Kubernetes 客户端。
比如,用户可以通过下面的 Flink 配置选项来设置最大的并发请求数,该配置允许 Kubernetes HA 服务在 session 集群上运行更多的 job。请注意,每个 Flink job 将会消耗 3 个并发请求。
containerized.master.env.KUBERNETES_MAX_CONCURRENT_REQUESTS: 200
env.java.opts.jobmanager: "-Dkubernetes.max.concurrent.requests=200"
3.1.3.2. 访问Flink Web UI
可以通过 kubernetes.rest-service.exposed.type 配置选项来暴露 Flink 的 Web UI 和 REST 终端服务。
- ClusterIP:暴露服务的集群内部 IP,该服务只能在集群内部访问。如果想要访问 JobManager UI 或提交 job 到已存在会话,你需要启动一个本地代理。之后,你就可以通过访问
localhost:8081来提交一个 flink job 到会话或查看 dashboard了。
$ kubectl port-forward service/<ServiceName> 8081
- NodePort:使用指定的端口号(
NodePort)来暴露每个节点 IP 上的服务。可以通过<NodeIP>:<NodePort>来连接 JobManager 服务,也可以通过 Kubernetes ApiServer 地址来代替NodeIP。可以在 kube 配置文件中找到这个地址。 - LoadBalancer:负载均衡,使用云提供商的负载均衡器对外公开服务。因为云提供商和 Kubernetes 需要一些时间来准备负载均衡,因此你可以通过客户端日志来获取 JobManager Web 接口的
NodePort。你可以使用命令kubectl get services/<cluster-id>-rest来获取 EXTERNAL-IP,然后手动构造负载均衡的 JobManager Web 接口:http://<EXTERNAL-IP>:8081
请参考官网文档在 Kubernetes 上发布服务来获取更多信息。
取决于你的实际环境,通过
LoadBalancerREST 服务启动 flink 集群,可能会让集群公开访问,这通常会让集群可以执行任意代码。
3.1.3.3. 登录
Kubernetes 会整合 conf/log4j-console.properties 和 conf/logback-console.xml 为一个 ConfigMap,然后暴露给 pod。对这些文件的改变对新启动的集群是可见的。
3.1.3.3.1. 访问日志
默认情况下,JobManager 和 TaskManager 会将日志输出到控制台,同时写入到每个 pod 的 /opt/flink/log 目录下。STDOUT 和 STDERR 只会直接输出到控制台,可以通过下面的命令访问他们:
$ kubectl logs <pod-name>
如果 pod 正在运行,你也可以使用 kubectl exec -it <pod-name> bash 来查看日志或对运行进行 debug 调试。
3.1.3.3.2. 访问TaskManagers日志
为了不浪费资源,flink 会自动清除空闲的 TaskManager,该行为会导致访问每个 pod 的日志更加困难。你可以通过配置 resourcemanager.taskmanager-timeout 来增加 TaskManager 的空闲时间,以让自己有更多的时间来查看日志文件。
3.1.3.3.3. 手动改变日志级别
如果你已经配置你的日志记录器可以自动获取配置更改,则你可以通过更改单独的 ConfigMap 来动态调整日志级别,假设 Cluster id 为 my-first-flink-cluster,则可以使用如下命令进行更改:
$ kubectl edit cm flink-config-my-first-flink-cluster
3.1.3.4. 使用插件
为了使用插件,你必须将他们拷贝到 Flink JobManager/TaskManager pod 中的正确位置。你可以使用无需挂载卷的内置插件,或构建一个自定义 Docker 镜像。比如,使用如下命令对你的 Flink session 集群启用 S3 插件:
$ ./bin/kubernetes-session.sh
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.14.4.jar \
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.14.4.jar
3.1.3.5. 自定义Docker镜像
如果你想使用自定义 Docker 镜像,则可以通过配置选项 kubernetes.container.image 来指定它,Flink 社区提供了一个非常好用的 Flink Docker 镜像 。通过如何自定义 Flink’s Docker 镜像查看如何启用插件,增加依赖,以及其他选项。
3.1.3.6. 使用隐私
Kubernetes Secrets 是一个包括一些隐私数据的对象,比如密码,token,或 key。这些信息可能会放在一个 pod 或镜像中。Flink on Kubernetes 可以通过两种方式使用这些隐私:
- 通过 pod 文件使用隐私
- 通过环境变量使用隐私
3.1.3.6.1. 在Pod中使用隐私文件
下面的命令会将名为 mysecret 的隐私挂载到标准 pod 下的 /path/to/secret 目录:
$ ./bin/kubernetes-session.sh -Dkubernetes.secrets=mysecret:/path/to/secret
名为 mysecret 的隐私中的用户名和密码可以在 /path/to/secret/username 和 /path/to/secret/password 文件中找到。查看 Kubernetes 官网文档 获取更多细节。
3.1.3.6.2. 使用隐私作为环境变量
下面的命令可以将标准 pod 中名为 mysecret 的隐私暴露为环境变量:
$ ./bin/kubernetes-session.sh -Dkubernetes.env.secretKeyRef=\
env:SECRET_USERNAME,secret:mysecret,key:username;\
env:SECRET_PASSWORD,secret:mysecret,key:password
环境变量 SECRET_USERNAME 包含用户名,SECRET_PASSWORD 包含密码。查看 Kubernetes 官网文档 获取更多细节。
3.1.3.7. on Kubernetes高可用
对于 on Kubernetes 高可用,可以查看高可用服务。
将 kubernetes.jobmanager.replicas 配置为一个大于 1 的值,可以启动备用 JobManager,以此加快失败恢复。注意,高可用只有在启动备用 JobManager 后才可用。
3.1.3.8. 手动清理资源
Flink 使用 Kubernetes OwnerReference’s 来清理所有的集群组件。所有 Flink 创建的资源,包括 ConfigMap、Service 和 Pod,都有被设置到 deployment/<cluster-id> 中的 OwnerReference。当部署被删除时,所有相关联的资源都会被自动删除。
$ kubectl delete deployment/<cluster-id>
3.1.3.9. 支持的Kubernetes版本
目前,所有 >= 1.9 版本的 Kubernetes 都支持。
3.1.3.10. 命名空间
Kubernetes 命名空间通过资源配额在多个用户之间集群资源。Flink on Kubernetes 可以使用命名空间来启用 Flink 集群。可以通过 kubernetes.namespace 配置命名空间。
3.1.3.11. RBAC
Role-based access control (RBAC) 是企业中基于角色的单个用户访问计算和网络资源的常规方法吗,用户可以配置用于 JobManager 访问 kubernetes 集群内的 Kubernetes API 服务的 RBAC 角色和服务账号。
每个命名空间都有默认的服务账号,但是默认的服务账号可能没有访问和删除 Kubernetes 集群内 pod 的权限,用户可能需要更新默认服务账号的权限,或指定其他绑定了正确角色的服务账号。
$ kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=default:default
如果你不想使用默认服务账号,可以使用如下命令创建一个新的名为 flink-service-account 的服务账号,并且设置角色绑定,然后使用配置选项 -Dkubernetes.service-account=flink-service-account 让 JobManager pod 使用 flink-service-account 服务账号来创建或删除 TaskManager pod 和 leader ConfigMap,新的账号也允许 TaskManager 查看 leader ConfigMap 来检索 JobManager 和 ResourceManager 的地址。
$ kubectl create serviceaccount flink-service-account
$ kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=default:flink-service-account
请参考官网 Kubernetes 文档 RBAC Authorization 来获取更多信息。
3.1.3.12. Pod模板
Flink 允许通过模板文件来定义 JobManager 和 TaskManager pod,这种方式支持使用 Flink Kubernetes 配置选项 中没有直接支持的高级特性。使用 kubernetes.pod-template-file 来指定包含 pod 定义的本地文件,该文件将被用于初始化 JobManager 和 TaskManager。主要的容器名称应该被定义为 flink-main-container。请看考 pod 模板案例 来获取更多信息。
3.1.3.12.1. 通过Flink覆盖属性
一些 pod 模板文件中的属性会被 flink 覆盖,解析有效属性值的算法如下:
-
Defined by Flink:用户无法配置这些属性。
-
Defined by the user:用户可以自由的指定这些属性值,Flink 框架不会设置任何源于配置选项和模板的额外值和有效值。
优先顺序:首先采用指定的配置选项中的值,然后取 pod 模板中的值,如果都没有指定,则最后采用配置选项的默认值。
-
Merged with Flink:Flink 会合并用户定义的值,遵循上面的优先顺序,在遇到同名字段的情况下,Flink 值具有优先级。
参考下面表中列出的所有可以被覆盖的 pod 属性,pod 模板中定义的所有未在下表列出的属性值都不会起作用。
Pod 元数据
| 键 | 种类 | 关联的配置选项 | 描述 |
|---|---|---|---|
| name | Defined by Flink | JobManager pod 名称将会被在部署中定义的 kubernetes.cluster-id 覆盖。TaskManager pod 名称将会被 Flink ResourceManager 生成的 <clusterID>-<attempt>-<index> 覆盖。 | |
| namespace | Defined by the user | kubernetes.namespace | JobManager 部署和 TaskManager pod 都会在用户指定的命名空间中创建。 |
| ownerReferences | Defined by Flink | JobManager 和 TaskManager pod 的所有者参考经常被设置为 JobManager 部署,请参考 kubernetes.jobmanager.owner.reference 来控制何时删除部署。 | |
| annotations | Defined by the user | kubernetes.jobmanager.annotations kubernetes.taskmanager.annotations | Flink 将增加通过 Flink 配置选项指定的额外注释。 |
| labels | Merged with Flink | kubernetes.jobmanager.labels kubernetes.taskmanager.labels | Flink 会增加一些内置的标签到用户自定义的值上。 |
Pod 属性
| 键 | 种类 | 关联的配置选项 | 描述 |
|---|---|---|---|
| imagePullSecrets | Defined by the user | kubernetes.container.image.pull-secrets | Flink 会增加通过 Flink 配置选项指定的额外拉取到的隐私。 |
| nodeSelector | Defined by the user | kubernetes.jobmanager.node-selector kubernetes.taskmanager.node-selector | Flink 会增加通过 Flink 配置选项指定的额外的节点选择器。 |
| tolerations | Defined by the user | kubernetes.jobmanager.tolerations kubernetes.taskmanager.tolerations | Flink 会增加通过 Flink 配置选项指定的额外的容错。 |
| restartPolicy | Defined by Flink | 通常指定 JobManager pod ,从来不指定 TaskManager pod。JobManager pod 通常会被部署重启,TaskManager 不应该被重启。 | |
| serviceAccount | Defined by the user | kubernetes.service-account | JobManager 和 TaskManager pod 将会通过用户定义的服务账号来创建。 |
| volumes | Merged with Flink | Flink 会增加一些内置的 ConfigMap 卷,比如:flink-config-volume,hadoop-config-valute,以用来传递 Flink 配置和 hadoop 配置。 |
主容器属性
| 键 | 种类 | 关联的配置选项 | 描述 |
|---|---|---|---|
| env | Merged with Flink | containerized.master.env.{ENV_NAME} containerized.taskmanager.env.{ENV_NAME} | Flink 会增加一些内置的环境变量到用户自定义的值上。 |
| image | Defined by the user | kubernetes.container.image | 容器镜像将根据用户自定义值的优先顺序进行解析。 |
| imagePullPolicy | Defined by the user | kubernetes.container.image.pull-policy | 容器镜像拉取策略将根据用户自定义值的优先顺序进行解析。 |
| name | Defined by Flink | 容器名称将会被 Flink 的 “flink-main-container” 值覆盖。 | |
| resources | Defined by the user | Memory: jobmanager.memory.process.size taskmanager.memory.process.size CPU: kubernetes.jobmanager.cpu kubernetes.taskmanager.cpu | 内存和 cpu 资源(包括请求和限制)将会被 Flink 的配置选项覆盖,所有其他的资源(比如临时存储)将会被留下。 |
| containerPorts | Merged with Flink | Flink 会增加一些内置的容器端口号,比如:rest、jobmanager-rpc、blob、taskmanager-rpc。 | |
| volumeMounts | Merged with Flink | Flink 会增加一些内置的卷挂载,比如:flink-config-volume、hadoop-config-volume,这对于传递 flink 配置和 hadoop 配置是很有必要的。 |
3.1.3.12.2. Pod模板案例
pod-template.yaml
apiVersion: v1
kind: Pod
metadata:
name: jobmanager-pod-template
spec:
initContainers:
- name: artifacts-fetcher
image: artifacts-fetcher:latest
# 使用 wget 或其他工具从远程存储获取用户 jar
command: [ 'wget', 'https://path/of/StateMachineExample.jar', '-O', '/flink-artifact/myjob.jar' ]
volumeMounts:
- mountPath: /flink-artifact
name: flink-artifact
containers:
# 不要修改主容器名称
- name: flink-main-container
resources:
requests:
ephemeral-storage: 2048Mi
limits:
ephemeral-storage: 2048Mi
volumeMounts:
- mountPath: /opt/flink/volumes/hostpath
name: flink-volume-hostpath
- mountPath: /opt/flink/artifacts
name: flink-artifact
- mountPath: /opt/flink/log
name: flink-logs
# 使用 sidecar 容器推送日志到远程存储或做一些其他的 debug 事情
- name: sidecar-log-collector
image: sidecar-log-collector:latest
command: [ 'command-to-upload', '/remote/path/of/flink-logs/' ]
volumeMounts:
- mountPath: /flink-logs
name: flink-logs
volumes:
- name: flink-volume-hostpath
hostPath:
path: /tmp
type: Directory
- name: flink-artifact
emptyDir: { }
- name: flink-logs
emptyDir: { }
3.2. yarn
3.2.1. 入门指南
该入门指南章节会指导你在 YARN 上配置一个完整的 Flink 集群。
3.2.1.1. 概述
Apache Hadoop YARN 是很多数据处理框架爱用的资源提供者,Flink 服务可以提交到 YARN 的 ResourceManager,然后通过 YARN 的 NodeManager 来提供容器,然后 Flink 会部署他的 JobManager 和 TaakManager 示例到这些容器上。
Flink 可以基于在 JobManager 上运行的 job 所需要的 slot 来动态收集和清理 TaskManager 资源。
3.2.1.2. 准备
入门指南章节假定已经有一个可用的 YARN 环境了,并且版本号 ≥ 2.4.1。YARN 环境可以通过 Amazon EMR、Google Cloud DataProc 或 Cloudera 产品来很方便的提供。该入门指南并不要求手动部署本地 YARN 环境 或 集群部署 。
- 可以通过运行
yarn top来确定你的 YARN 集群已经准备好接收 Flink 程序了,该命令应该不展示任何错误信息。 - 从 下载页面 下载 Flink 分布式文件,并解压。
- 重要:请确保已经设置了
HADOOP_CLASSPATH环境变量,可以通过运行echo $HADOOP_CLASSPATH命令来检查。如果没有设置,请通过以下命令来设置:
export HADOOP_CLASSPATH=`hadoop classpath`
3.2.1.3. 在yarn上启动flink session
确保设置了 HADOOP_CLASSPATH 环境变量之后,就可以启动 YARN session 了,并且提交案例 job:
# 假定在 root 目录下解压了 Flink 分布式文件
# (0) export HADOOP_CLASSPATH
export HADOOP_CLASSPATH=`hadoop classpath`
# (1) 启动 YARN Session
./bin/yarn-session.sh --detached
# (2) 你可以通过命令行输出打印的最有一行中的 URL 或通过 YARN ResourceManager web UI 来访问 Flink web 页面
# (3) 提交案例 job
./bin/flink run ./examples/streaming/TopSpeedWindowing.jar
# (4) 停止 YARN session,请将下面的 application id 替换为 yarn-session.sh 命令输出的 application id
echo "stop" | ./bin/yarn-session.sh -id application_XXXXX_XXX
恭喜!你已经成功的通过部署 Flink on YARN 来运行 Flink 程序了。
3.2.2. Flink on YARN支持的部署模式
对于生产案例,我们监建议使用 Per-job 或 Application 模式 来部署 Flink 程序,这些模式对程序有更好的隔离性。
3.2.2.1. Application模式
请参考 deployment 模式概述 来获取 application 模式的高级知识。
Application 模式将在 YARN 上启动一个 Flink 集群,然后运行在 YARN 中的 JobManager 执行应用程序中的 main() 方法。集群将会在程序运行完成后马上关闭,也可以使用 yarn application -kill <ApplicationId> 或通过取消 Flink job 来停止集群。
./bin/flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar
一旦部署了 Application 模式的集群,你就可以与它进行交互操作,比如取消或触发 savepoint。
# 列出集群中运行的 job
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
# 取消运行的 job
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
注意,取消 Application 集群中的 job 将会停止集群。
为了发挥 application 模式的所有潜力,可以考虑使用 yarn.provided.lib.dirs 配置选项并且提前上传你的应用程序 jar 到一个可以被集群所有节点访问的位置,具体命令如下:
./bin/flink run-application -t yarn-application \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" \
hdfs://myhdfs/jars/my-application.jar
上述命令可以让 job 提交更加轻量,因为需要的 Flink jar 和应用程序 jar 可以通过指定的远程位置获取,而不是通过客户端上传到集群。
3.2.2.2. Per-Job模式
请参考 deployment 模式概述 来获取 application 模式的高级知识。
Per-job 集群模式会在 YARN 上启动一个 Flink 集群,然后在本地运行提供的程序 jar 包,最后将 JobGraph 提交到 YARN 中的 JobManager。如果你指定了 --detached 参数,本地客户端会在提交被接受之后马上停止。
YARN 中的 per-job 集群会在 job 停止之后马上停止。
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
Per-job 集群一旦部署完毕,你就可以进行和它进行交互操作了,比如取消 job ,或触发一个 savepoint。
# 列出集群运行的 job
./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
# 取消运行的 job
./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
注意,取消 per-job 集群中的 job,将会停止 per-job 集群。
3.2.2.3. Session模式
请参考 deployment 模式概述 来获取 application 模式的高级知识。
我们已经在上面的入门指南中说明了 Session 模式的部署。
Session 模式有两种操作模式:
- attached mode(默认):
yarn-session.sh客户端提交 Flink 集群到 YARN,但是本地客户端依然会保持运行,并且追踪集群的状态。如果集群运行失败,则客户端会展示错误信息。如果客户端被终止,它也会给集群发送关闭信号。 - detached mode (
-dor--detached):yarn-session.sh客户端提交 Flink 集群到 YARN,然后客户端返回。要停止 Flink 客户端,则需要调用其他的客户端,比如 YARN tools。
session 模式会在 /tmp/.yarn-properties-<username> 中创建一个隐藏的配置文件,该配置文件会在提交 job 时被通过命令行接口集群获取。
你也可以在提交 Flink job 的命令行接口中手动指定目标 YARN 集群,示例如下:
./bin/flink run -t yarn-session \
-Dyarn.application.id=application_XXXX_YY \
./examples/streaming/TopSpeedWindowing.jar
你可以通过下面的命令重新附加到一个 YARN session 集群:
./bin/yarn-session.sh -id application_XXXX_YY
除了通过 conf/flink-conf.yaml 文件指定 配置 之外,你也可以在使用 ./bin/yarn-session.sh 提交时使用 -Dkey=value 参数来指定任何配置。
YARN session 客户端也有一些“短参数”用于设置,可以通过运行 ./bin/yarn-session.sh -h 命令来列出他们。
3.2.3. Flink on YARN参考
3.2.3.1. 在YARN上配置flink
在 配置页面 可以找到 YARN 的所有配置。
下面的配置参数通过 Flink on YARN 来管理,他们可以在框架运行时被覆盖:
jobmanager.rpc.address:被动态设置为 Flink on YARN 中运行 JobManager 容器的地址io.tmp.dirs:如果没有设置,Flink 将会设置为通过 YARN 定义的临时目录high-availability.cluster-id:在 HA 服务中会自动生成 ID 来区分多个集群
你可以通过 HADOOP_CONF_DIR 环境变量将额外的 Hadoop 配置文件传递给 Flink,该变量接收一个包含 Hadoop 配置文件的目录。默认情况下,所有需要的 Hadoop 配置文件都是通过 HADOOP_CLASSPATH 环境变量来获取并加载的。
3.2.3.2. 资源分配
如果无法使用已获取到的资源运行提交的 job,则运行在 YARN 上的 JobManager 会请求额外的 TaskManager 资源。在指定的 session 模式下运行时,如果需要,则 JobManager 会收集额外的 TaskManager 资源来运行提交的其他 Job。不再使用的 TaskManager 将会在超时之后被清理。
YARN 实现了 JobManager 和 TaskManager 的 process 内存配置,上报的 VCore 数量默认等于每个 TaskManager 配置的 slot 数量。yarn.containers.vcores 允许指定自定义值来覆盖 vcore 的数量,为了让这个参数生效,需要开启 YARN 集群的 CPU 调度。
失败的容器(包括 JobManager)将会被 YARN 换下。可以通过 yarn.application-attempts(默认为1)来配置 JobManager 容器重启的最大次数。一旦耗尽所有的尝试,则 YARN 程序将会失败。
3.2.3.3. on YARN高可用
on YARN 高可用可以通过 YARN 和 高可用服务 组合实现。
一旦配置了 HA 服务,它将会持久化 JobManager 元数据,并执行 leader 选举。
YARN 会进行失败 JobManager 的重启工作。JobManager 的重启最大次数通过两个配置参数定义:
- flink 的 yarn.application-attempts 配置,默认值为 2。
- YARN 的 yarn.resourcemanager.am.max-attempts 配置,默认值也是 2,但该配置值会限制上面的配置值。
注意,当部署为 on YARN 时,Flink 会管理 high-availability.cluster-id 配置参数,Flink 会设置该值为默认的 YARN application id。在 YARN 上部署高可用集群时不要覆盖该参数。存储到 HA 后端(比如 zookeeper)的 cluster ID 被用于区分不同的高可用集群。覆盖该配置参数会导致多个 YARN 集群影响彼此。
3.2.3.3.1. 容器关闭行为
- 2.3.0 < YARN version < 2.4.0:如果 application master 出现失败,则所有的容器都会被重启。
- 2.4.0 < YARN version < 2.6.0:在 application master 出现失败时,TaskManager 容器依然会保持运行。该行为的优点是:启动速度会更快,而且用户无需再次获取容器资源。
- YARN version >= 2.6.0:失败重试的时间间隔设置为 Flink 的 Akka 超时时间。失败重试时间间隔说的是:只有系统在一个间隔发现应用程序尝试了最大次数后,该程序才会被杀死。这可以避免长时间的 job 耗尽他的尝试次数。
Hadoop YARN 2.4.0 有个大 bug(已经在 2.5.0 中修复):YARN 会阻止从一个已经启动的 Application Master/JobManager 容器上重启容器。查看 FLINK-4142 来获取更多细节。我们建议至少使用 Hadoop 2.5.0 来部署 YARN 高可用。
3.2.3.4. 支持的Hadoop版本
Flink on YARN 从 Hadoop 2.4.1 开始支持,支持所有 >= 2.4.1 版本的 Hadoop,包括 Hadoop 3.x。
为了提供 Flink 需要的 Hadoop 依赖,我们建议设置在入门指南章节提到的 HADOOP_CLASSPATH 环境变量。
如果无法进行上述设置,也可以将依赖放到 Flink 的 lib/ 目录下。
Flink 也提供了预打包的 Hadoop fat jar,可以将他们放到 lib/ 目录下,可以在 Downloads / Additional Components 页面找到他们。这些预打包的 fat jar 通过 shade 打包方式,避免了公共库的依赖冲突。Flink 社区没有测试这些预打包 jar 和 YARN 的整合。
3.2.3.5. 在YARN上运行flink并且开启防火墙
一些 YARN 集群会使用防火墙来控制集群和外网的通信,在这种配置下,Flink job 只能通过集群内网提交到 YARN session。如果在生产上不可行,Flink 允许对 REST 端点配置一个端口号范围,用于客户端与集群之间通信。通过配置端口号范围,用户就可以通过防火墙来提交 job 到 Flink 上了。
通过 rest.bind-port 配置参数来指定 REST 端点的端口号,该配置选项接受单个端口号(比如:50010)、范围(比如 50000-50025)、或同时使用两者。
3.2.3.6. 用户jar和Classpath
默认情况下,Flink 在运行单个 job 时会将用户的 jar 放到系统 classpath 中,该行为可以通过 yarn.per-job-cluster.include-user-jar 参数控制。
当设置该参数为 DISABLED 时,Flink 会将 jar 放到用户的 classpath 中。
用户 jar 在 classpath 中的位置可以通过设置 yarn.per-job-cluster.include-user-jar 参数为下面的某个值来控制:
ORDER:默认值,将 jar 按照字段序放到系统 classpath。FIRST:将 jar 放到系统 classpath 开头。LAST:将 jar 放到系统 classpath 最后。