作品展示:
随机选学具,辨认职业名称、说说工作内容、涂色、裁剪、交换卡片等
灵感来源:
最近在网上搜索“midjounery 简笔画”,发现一条宝藏“关键词”——可以直接生成简笔画风格(造型的外边框线加粗)的样式。

小红书https://www.xiaohongshu.com/explore/648a885b000000001300197c
具体关键词:
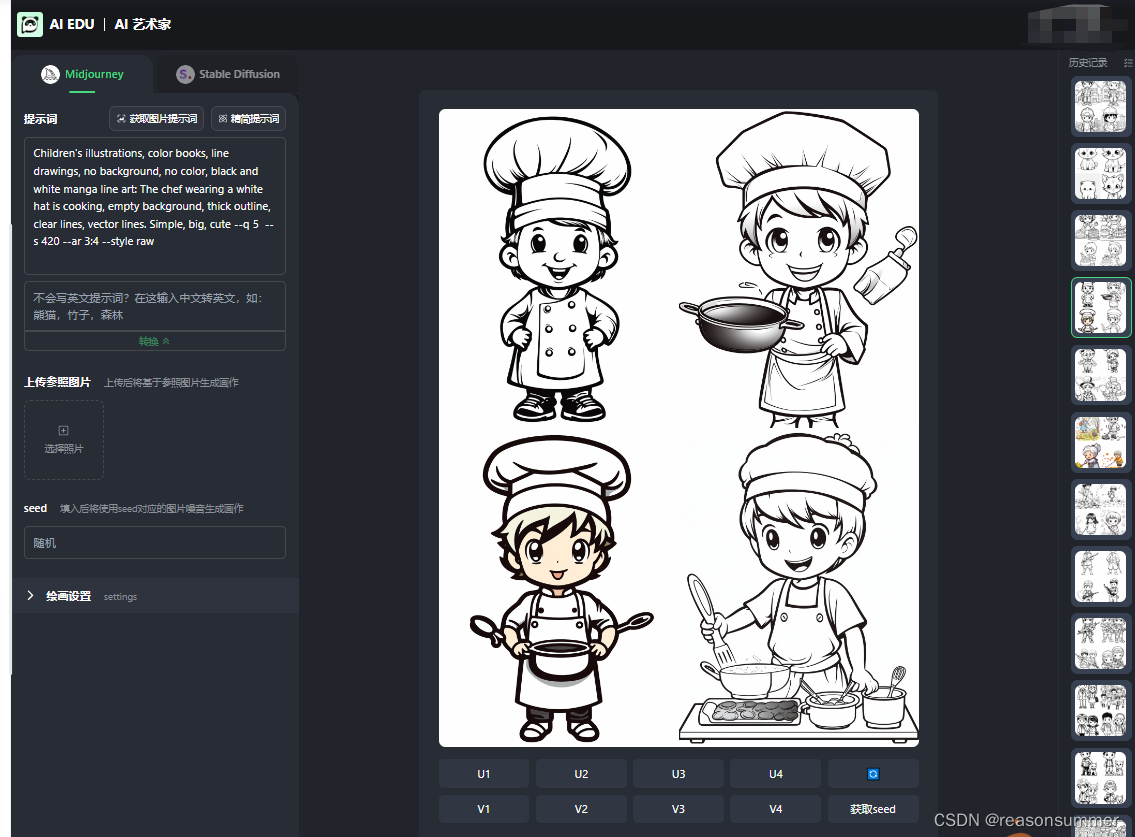
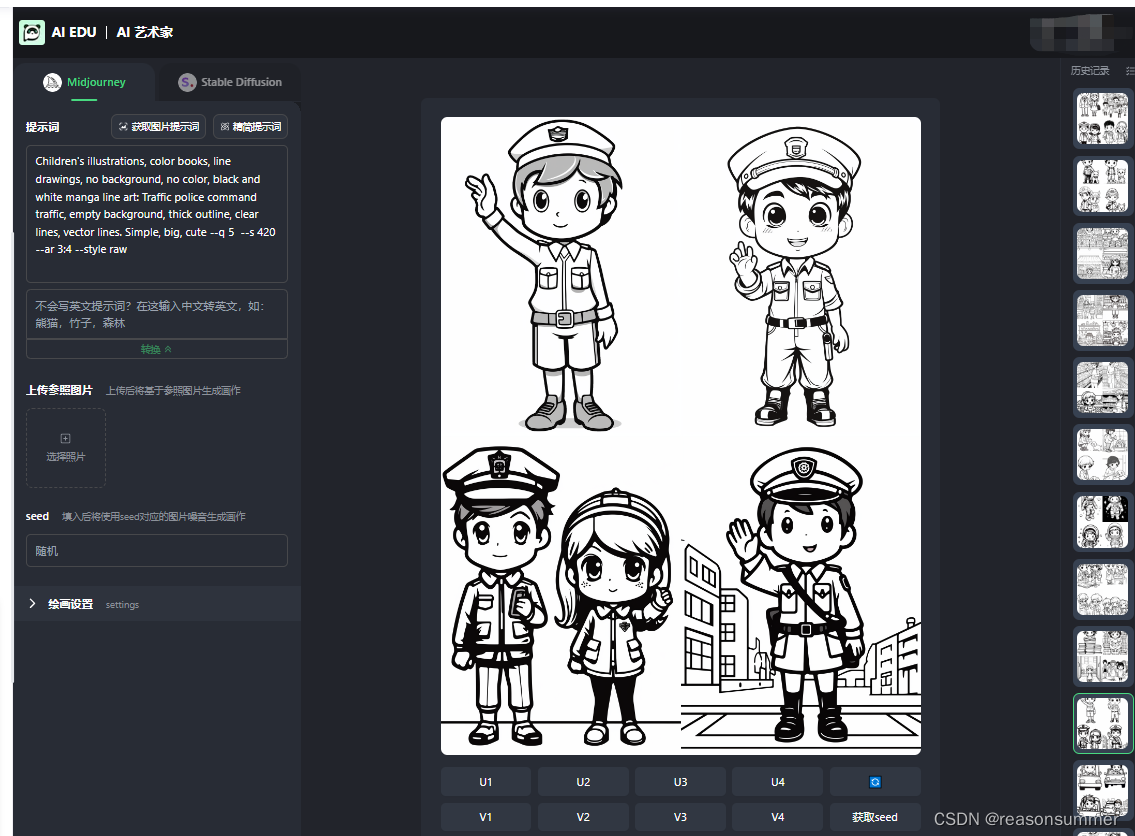
Midjourney绘图 | 简笔画 小小宇航员
关键词
illustration for toddlers coloring books, line drawing, no background, no colors, black and white comic line art for: The daring astronaut walked gingerly across the treacherous ice sheets of Europa, bravely enduring the harsh, subzero conditions. , empty background, thick outline, crisp lines, vector lines. simple, big, cute, --q 5 --v 5.1 --s 420 --ar 3:4 --style raw
幼儿插图,彩色书,线条画,没有背景,没有颜色,黑白漫画线条艺术:勇敢的宇航员小心翼翼地走在危险的木卫二冰盖上,勇敢地忍受着严酷的零度以下的条件。,空背景,粗轮廓,清晰的线条,矢量线。简单,大,可爱
背景需求:
因为范例是“”宇航员“”,所以我想这段关键词在Mmidjounery里生成职业相关(角色游戏)的简笔画插画(外轮廓粗线条),再用Python制作一套有4张卡片的A4学具。
参数替换说明
1、这条没有用niji,用了V 5.1
2、把红色部分的“人物做什么”替换成其他职业即可。
图片准备:
各种职业(医生、护士、快递员、老师、厨师、警察、特警、司机等)
图片下载到一个文件里
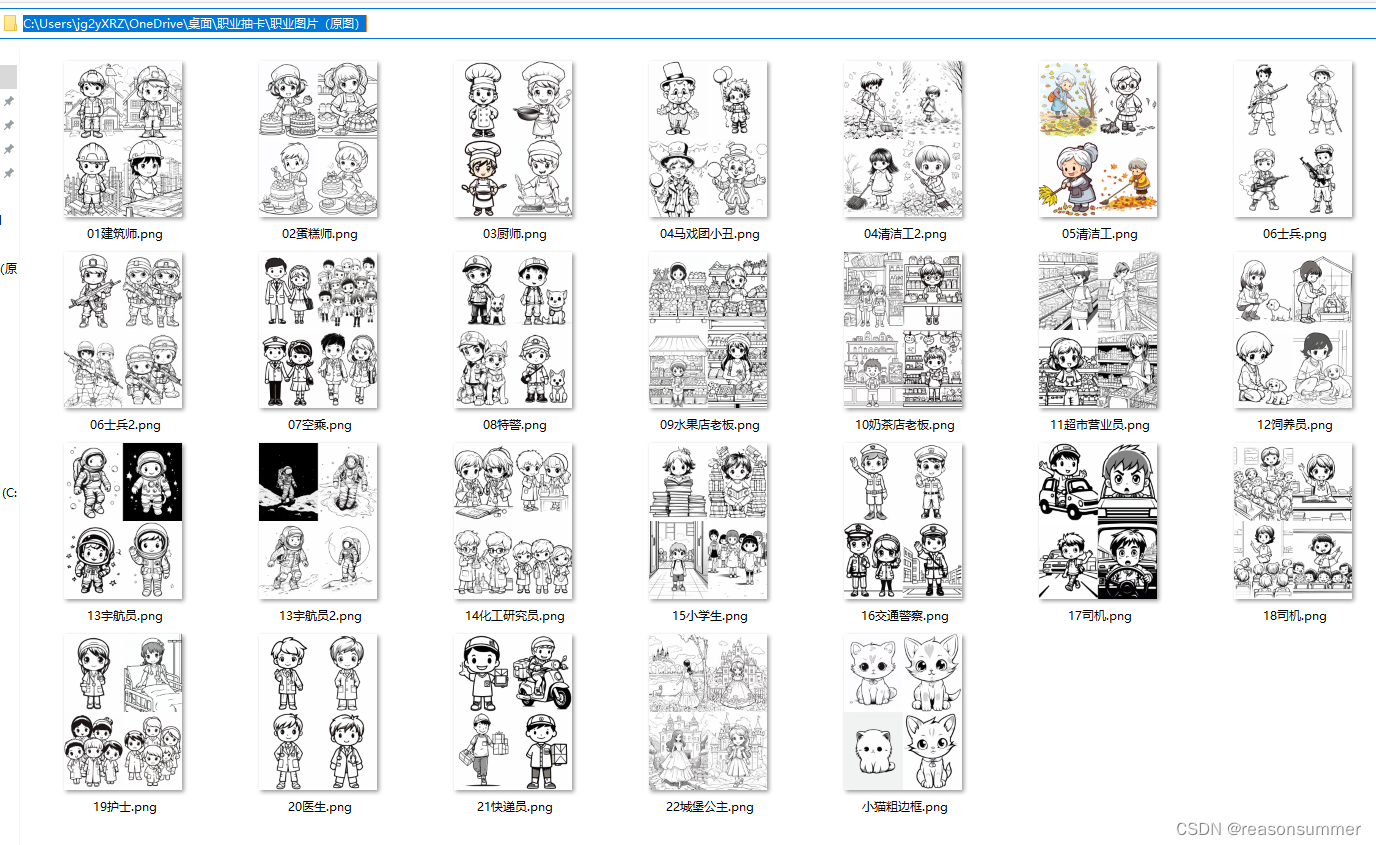
图片切割:
3:4图片的像素大小
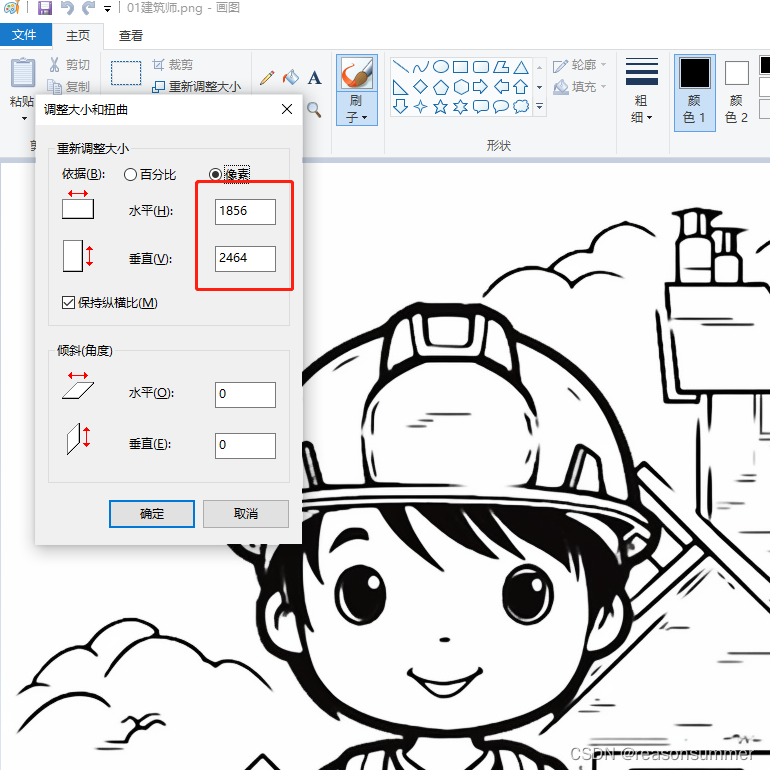
桌面新建2、3文件夹,把图片放在桌面上的2文件夹内。
用代码切割成四份
# 参考网址:https://blog.csdn.net/weixin_42182534/article/details/125773141?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E6%88%AA%E5%8F%96%E5%9B%BE%E7%89%87%E7%9A%84%E4%B8%80%E9%83%A8%E5%88%86&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-125773141.nonecase&spm=1018.2226.3001.4187
'''
功能:把midjounery 3*3方形矩阵,5*4矩阵、3*5矩阵切割 通用公式)
作者:阿夏
时间:2023年6月26日 19:51
'''
import os
import os.path
from PIL import Image
long=int(input('图片长度像素(1856)\n'))
wide=int(input('图片宽度像素(2464)\n'))
small_long=int(input('长边切分2(2*2)\n'))
small_wide=int(input('宽边切分2(2*2)\n'))
# 目前图片都是2*2,3*3排列
# 1:1图比例是2048
# 16:9图片比例 2912:1632
# 3:4图片比例 1856:2464
wj=input('文件夹名称\n')
z=0
longall=[]
longall.append(z)
for l in range(1,small_long+1):
ll=float(long/small_long*l)
longall.append(ll)
print(longall)
# 右侧边的所有参数 长/X
# [0, 512, 1024, 1536, 2048]
wideall=[]
wideall.append(z)
for w in range(1,small_wide+1):
ww=float(wide/small_wide*w)
wideall.append(ww)
print(wideall)
# 下边的所有参数 宽/X
# [0, 682.6666666666666, 1365.3333333333333, 2048.0]
pic=[]
for x in range(0,small_wide):
for y in range(0,small_long):
z1=longall[y]
z2=wideall[x]
z3=longall[y+1]
z4=wideall[x+1]
pic.append(z1)
pic.append(z2)
pic.append(z3)
pic.append(z4)
print(len(pic))
# # 4*3图为例hang
# 第1行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[0]
# z3=longall[1] [2] [3] [4]
# z4=wideall[1]
# 第2行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[1]
# z3=longall[1] [2] [3] [4]
# z4=wideall[2]
# 第3行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[2]
# z3=longall[1] [2] [3] [4]
# z4=wideall[3]
# 总结:
# z1=long[0:4] 每张图左侧的坐标会变 ,索引数字不断从0,1/4,2/4,3/4
# z2=宽数量 宽的索引,不断增加
# z3=long[0+1:4+1] 每张图右侧 索引数+1 从1/4,2/4,3/4,4/4(=长)20
# z4=宽+1 宽的索引+1
# 定义文件所在文件夹
image_dir = r'C:\Users\jg2yXRZ\OneDrive\桌面\{}'.format(wj)
for parent, dir_name, file_names in os.walk(image_dir): # 遍历每一张图片
for filename in file_names:
print(filename)
pic_name = os.path.join(parent, filename)
image = Image.open(pic_name)
_width, _height = image.size
print(_width, _height)
qfall=4
# 每张图有4个坐标
n=0
for p in range(int(len(pic)/4)):
pp=pic[p*4:p*4+4]
print(pp)
# 定义裁剪范围(left, upper, right, lower)1024
# # box = image.crop((0,0,123,123))
box = image.crop((pp[0],pp[1],pp[2],pp[3]))
name = filename[:-4]+'_'+str(n) +'.png'
print(name)
# # # ,pp[3],pp[4],pp[5],pp[6],pp[7],pp[8],pp[9]))
# # name = filename[:-4]+'_'+str(p) +'.png'2048
box.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\3\{}'.format(name))
n+=1
# print('Done!')
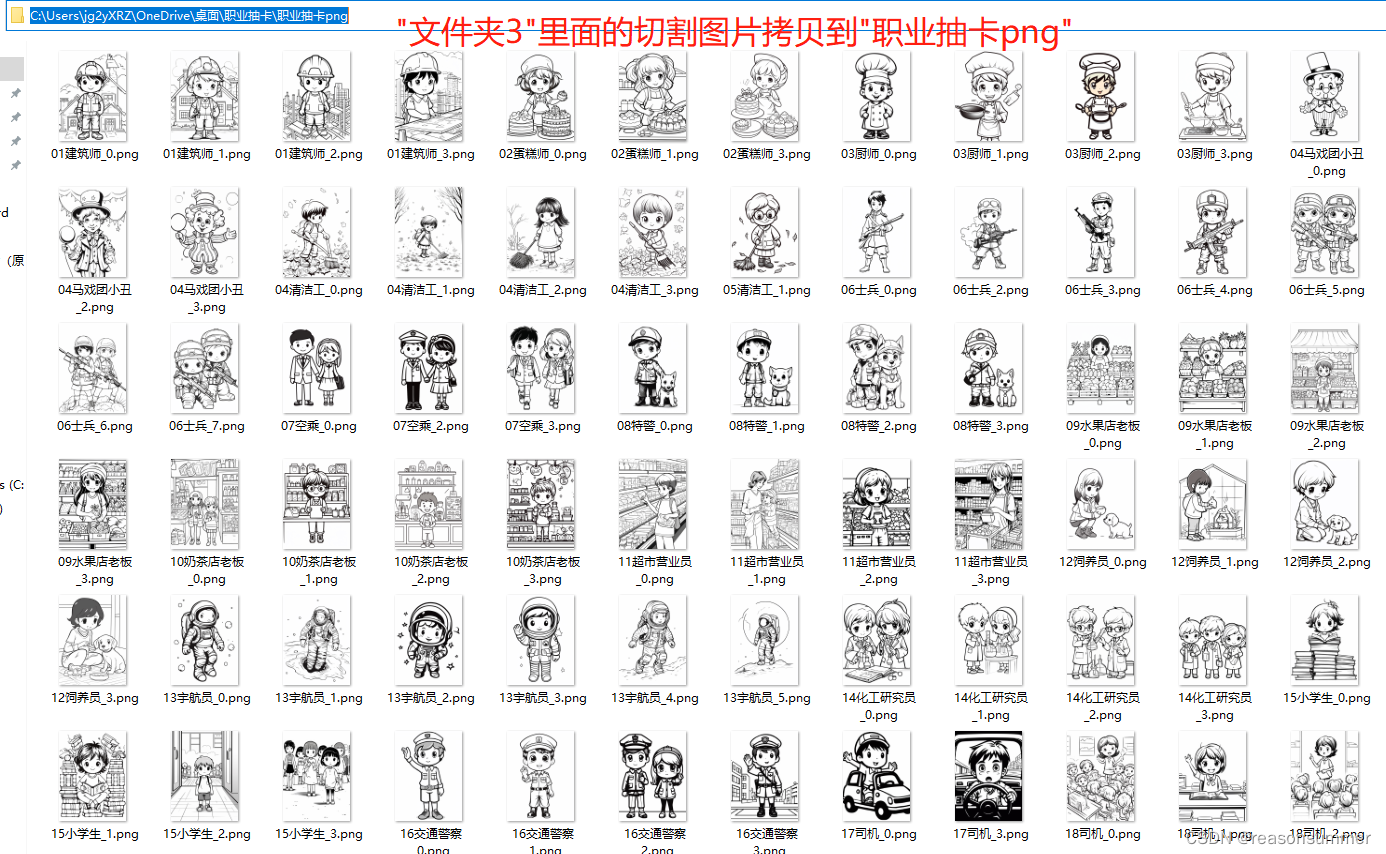
删除一些不想要的图片(人物有颜色的、有黑色背景的、人物数量过多)
素材准备:
WORD模板
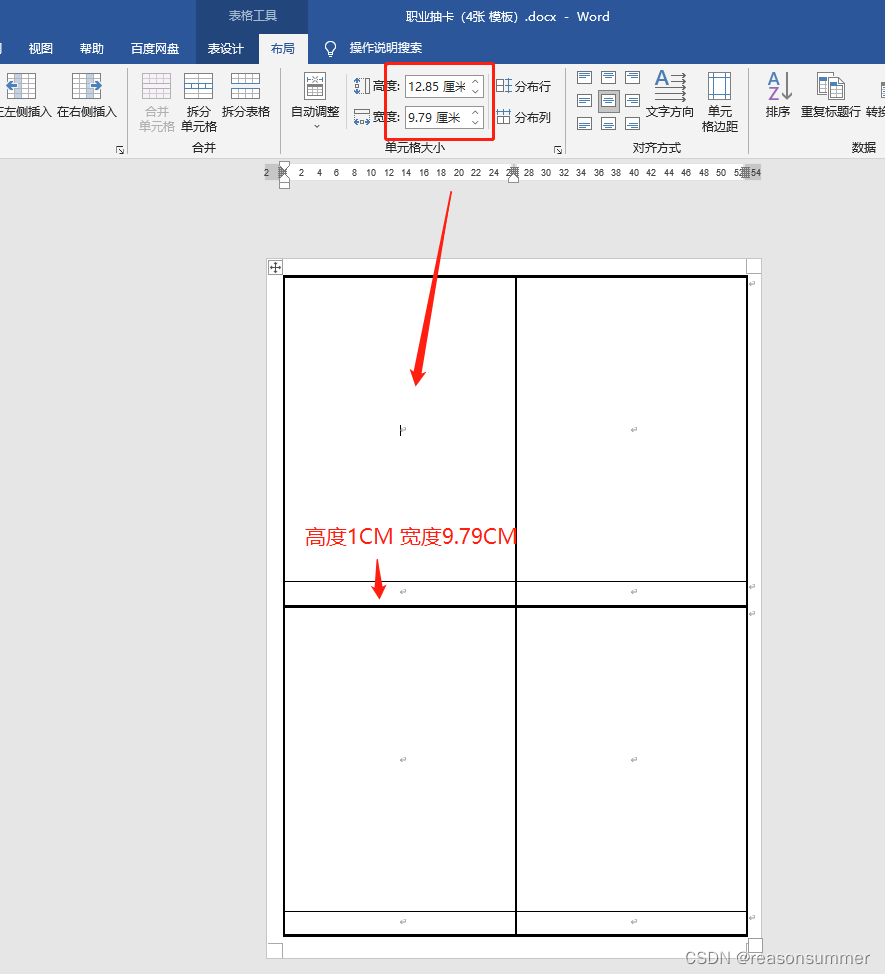
图片准备:
删除一些不想要的图片(人物有颜色的、有黑色背景的、人物数量过多)
随机抽卡4张代码
# -*- coding: utf-8 -*-
'''
目的:
1、根据职业抽卡每张A4抽4张职业(可能重复)
2、作者:阿夏
时间:2023年7月22日)
'''
import os
# sum=int(input('最大数字(6张、8张、10张、12张图片)\n'))
# size=float(input('图片尺寸(1.6、1.4、1.1、0.8)\n'))
num=int(input('生成多少份(28人)\n'))
Number=4
print('----------第1步:提取所有的扑克牌的路径------------')
path=[]
p=r"C:\Users\jg2yXRZ\OneDrive\桌面\职业抽卡\职业抽卡png"
# 过滤:只保留png结尾的图片
imgs=os.listdir(p)
for img in imgs:
if img.endswith(".png"):
path.append(p+'\\'+img)
# 所有图片的路径
print(path)
print(imgs)
# ['01汉堡.svg', '02汉堡可乐.svg', '03肉夹馍.svg', '04鸡腿.svg', '05面条.svg', '06披萨.svg', '07爆米花.svg', '08寿司.svg', '09苹果.svg', '10橙子.svg', '11樱桃.svg', '12葡萄.svg', '13西瓜.svg', '14牛油果.svg', '15糖果.svg', '16杯子蛋糕.svg', '17甜甜圈.svg', '18蛋筒.svg', '19蛋糕.svg', '20棒棒糖.svg', '21面包.svg', '22棒冰.svg', '23水果盘.svg']
# print('----------第2步:新建一个临时文件夹------------')
# # 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\职业抽卡\零时Word')
print('----------第3步:随机抽取12张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,num):
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\职业抽卡\职业抽卡(4张 模板).docx')
# # 制作列表
# for z in range(2): # 5行组合循环2次 每页两张表
# 23个图形随机抽取12个
figure=random.sample(path,Number) # 12个图片随机写入4个
print(figure)
# 路径 ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\08特警_3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\08特警_2.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\06士兵2_1.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\20医生_1.png']
# 提取名称
title=[]
for t in figure:
tt=t[44:-6]
title.append(tt)
# 路径 ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\08特警_3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\08特警_2.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\06士兵2_1.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\职业抽卡\\职业抽卡png\\20医生_1.png']
print(title)
table = doc.tables[0] # 只有一个表格
# 帖图片的单元格
bg1=['00','01','20','21']
for t1 in range(len(bg1)): # 02
pp1=int(bg1[t1][0:1])
qq1=int(bg1[t1][1:2])
# print(p)
k1=figure[t1]
print(pp1,qq1,k1)#
# 写入图片
run=doc.tables[0].cell(pp1,qq1).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(k1),width=Cm(9.69),height=Cm(12.65)) # 1.5的图片最多6个
table.cell(pp1,qq1).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# 帖文字的单元格
bg2=['10','11','30','31']
for t2 in range(len(bg2)): # 02
pp2=int(bg2[t2][0:1])
qq2=int(bg2[t2][1:2])
# print(p)
k2=title[t2]
print(pp2,qq2,k2)#
# 写入职业名称
run=table.cell(pp2,qq2).paragraphs[0].add_run(k2) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(15) #输入字体大小默认30号 一行里(可以一页两份)
run.font.bold= True #是否加粗
run.font.color.rgb = RGBColor(200,200,200) #数字小,颜色深0-255
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp2,qq2).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\职业抽卡\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/职业抽卡/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/职业抽卡/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/职业抽卡/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/职业抽卡/(打印合集)职业抽卡4张({}人共{}份).pdf".format(num,num))
file_merger.close()
# doc.Close()
# # # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/职业抽卡/零时Word') #递归删除文件夹,即:删除非空文件夹
终端运行
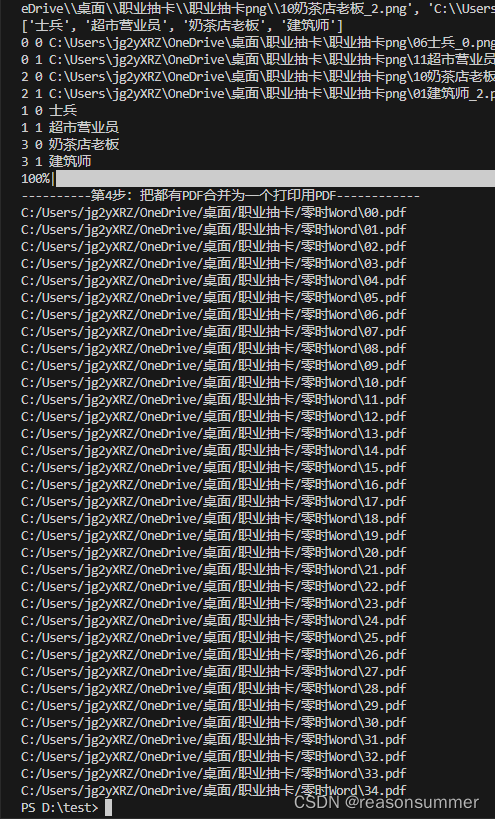
结果展示



每一页上的4个图案都不一样,但是可能会有职业重复(如:2个快递员)
教学流程:
1、语言:幼儿可以辨认人物的职业
2、美术:再尝试涂色(12色蜡笔涂色效果不好,最好还是用水彩马克笔),
3、手工:剪成四块
4、游戏:鼓励幼儿探索玩法(预设玩法:交换卡片、人物分类(收集同职业卡片)