🐱作者:一只大喵咪1201
🐱专栏:《网络》
🔥格言:你只管努力,剩下的交给时间!

在前面本喵已经带大家见识过了scoket网络通信的样子,现在开始深入学习网络的原理,本喵采取的策略是从顶层往底层讲解,也就是从应用层到数据链路层的顺序。
协议定制 | 序列化和反序列化 | 初识http
- 🔊再谈协议
- 🔊网络版本计算器
- 🎶服务端实现
- 协议定制
- 序列化和反序列化
- 🎶客户端实现
- 🔊Json序列化和反序列化
- 🔊初识http协议
- 🎶认识URL
- 🔊总结
🔊再谈协议
我们知道,协议就是一种“约定”,在前面的TCP/UDP网络通信的代码中,读写数据的时候都是按照"字符串"的形式来发送和接收的,如果我们要传送一些结构化的数据怎么办呢?
拿我们经常使用的微信聊天来举例:
聊天窗口中的信息包括头像(url),时间,昵称,消息等等,暂且将这几个信息看成是多个字符串,将这多个字符串形成一个结构化的数据:
struct/class message
{
string url;
string time;
string nickname;
string msg;
};
在聊天的过程中,通过网络发送的数据就成了上面代码所示的结构化数据,而不再是一个字符串那么简单。
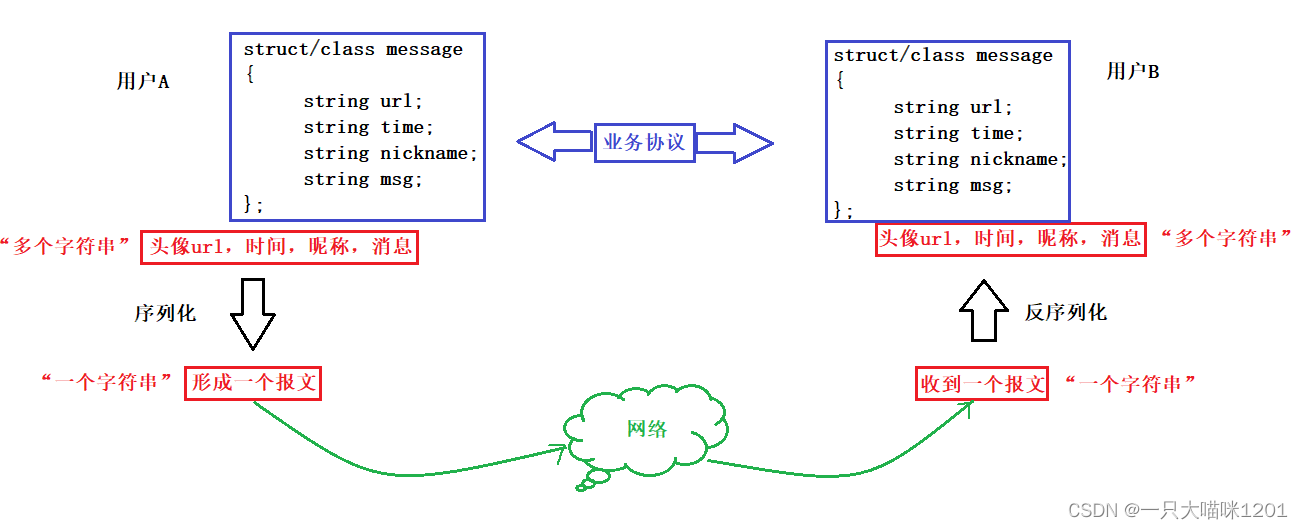
如上图所示,用户A发送的消息虽然只有msg,但是经过用户层(微信软件)处理后,又增加了头像,时间,昵称等信息,形成一个结构化的数据struct/class message。
这个结构化的数据再发送到网络中,但是在发送之前,必须将结构化的数据序列化,然后才能通过socket发送到网络中。
- 序列化:就是将任意类型的数据或者数据结构转换成一个字符串。
- 如上图中的
message结构体,序列化后就将所有成员合并成了一个字符串。
网络再将序列化后的数据发送给用户B,用户B接收到的报文必然是一个字符串。
然后用户B的应用层(微信软件)将接收到的报文进行反序列化,还原到原理的结构化数据message的样子,再将结构化数据中不同信息的字符串显式出来。
- 反序列化:就是将一个字符串中不同信息类型的字串提取出来,并且还原到结构化类型的数据。
- 业务结构数据在发送到网络中的时候,先序列化再发送。
- 收到的一定是序列化后的字节流,要先进行反序列化,然后才能使用。
本喵这里说的是TCP网络通信方式,它是面向字节流的,如果是UDP的就无需进行序列化以及反序列化,因为它是面向数据报的,无论是发送的还是接收到的,都是一个一个的数据。
在微信聊天的过程中,用户A发送message是一个结构化的数据,用户B接收到的message也是一个结构化的数据,而且它两的message中的成员变量都一样,如上图蓝色框中所示。
- 此时这个
message就是用户A和用户B之间制定的协议。
用户A的message是按照什么顺序组成的,用户B就必须按照什么顺序去使用它的message。
在这里协议不再停留在感性认识的“约定”上,而且具体到了结构化数据message中。
🔊网络版本计算器
本喵通过实现一个网络版的计算器来讲解具体的用户协议定制以及序列化和反序列化的过程,其中用户向服务器发起计算请求,服务器计算完成后将结果响应给用户。
🎶服务端实现
参考上面微信聊天的过程,我们知道了,网络通信过程中,服务器要做的事情是:接收数据报->反序列化->进行计算->把结果序列化->发送响应到网络中。
今天的重点不在网络通信的建立连接,而是协议定制以及序列化和反序列化,所以本喵直接使用上篇文章中已经能建立好连接的服务器代码:
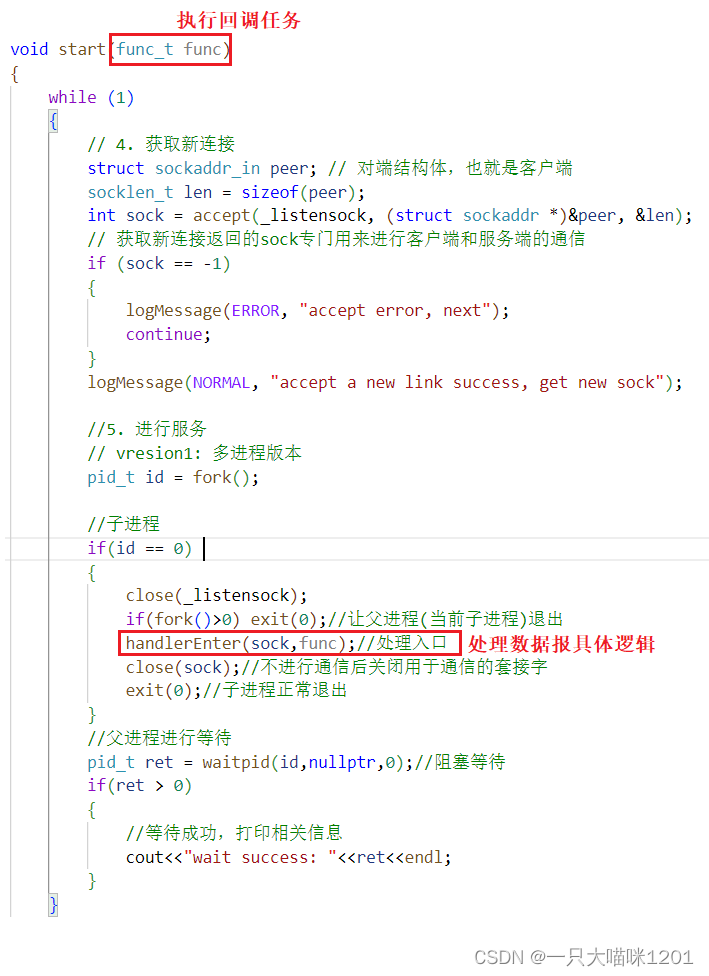
使用之前的TCP通信代码,客户端和服务端的网络连接已经成功建立了,这里使用多进程的方式来进行网络通信。接下来就是如何去处理这个数据报。
如上图红色框所示,处理的具体逻辑放到了handlerEnter函数中,在调用该函数的时候需要传两个参数,第一个是服务器accept后返回的套接字文件描述符sock,另一个是在服务端启动时调用start传入的回调函数(计算任务)。
- 这样做是为了让数据报的处理逻辑和底层网络连接进行解耦。
- 之后如果要修改对数据报的处理方式时,底层代码不用动,只需要修改
handlerEnter中的代码即可。
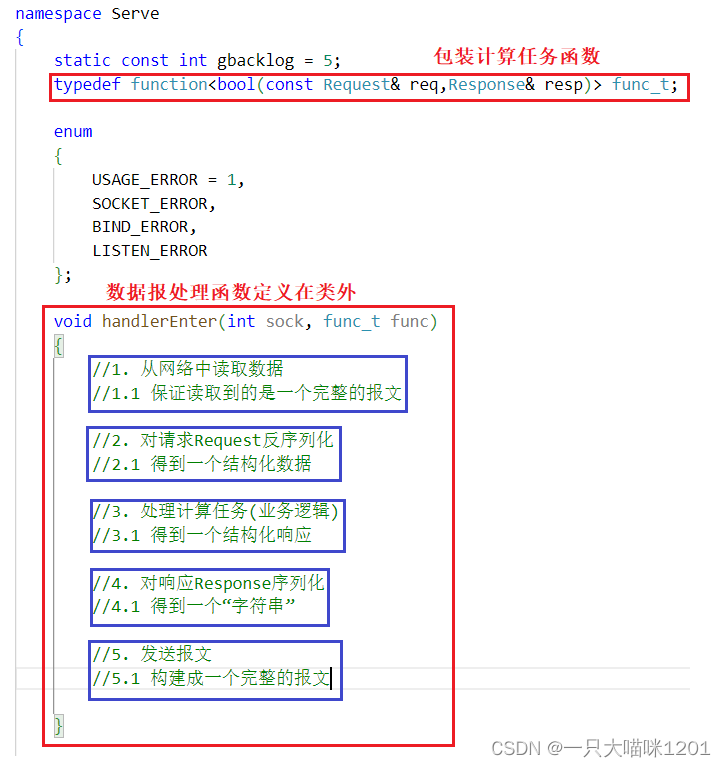
首先需要将进行计算的函数包装成func_t方便进行回调,计算函数的返回值是bool,两个参数分别是Request请求和Response响应。
本喵将handlerEnter处理数据报的函数定义在了calServe类外,也是为了和底层网络连接部分的代码解耦。
可以看到,在handlerEnter函数中,对数据报的处理分为五个部分,如上图中蓝色框,我们要做的就是将这五部分填充起来。
协议定制
通过微信聊天的例子,我们知道了,协议其实就是结构化数据,是客户端和服务端都知道的一种结构化数据,所以需要创建Request和Response两个结构。
本喵将所有属于协议的代码都放在protocol.hpp中:
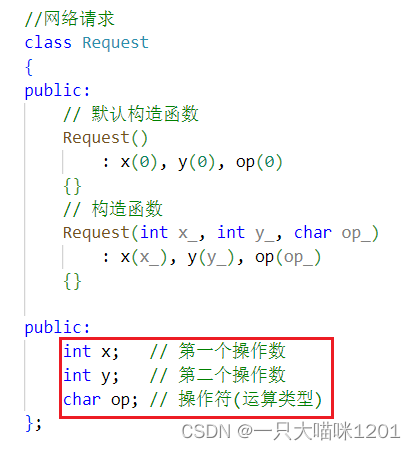
上图所示代码是Resquest,包含两个操作数x和y,以及操作符op,运算表达式的形式如1+1 。
网络请求Request是由客户端发送的,但是网络端也必须要知道Request中的内容,如x就表示第一个操作数y就表示第二个操作数,op表示计算的类型。
-
Request就是客户端和服务端之间的一个协议。
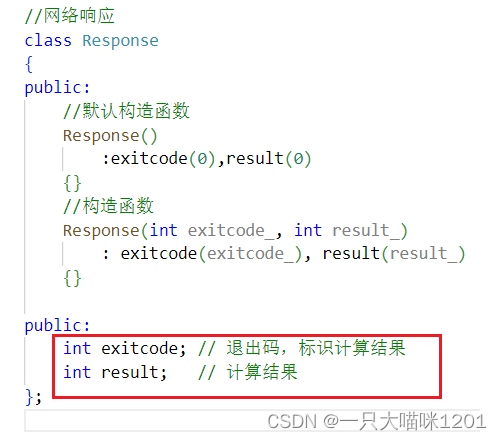
上图所示代码是Response,包含成员exitcode退出码和result计算结果。不同的退出码表示着不同的意义:

使用枚举将不同的退出码列举出来,如上图所示。
网络响应Response是由服务端发送的,同样客户端也必须知道Response中的内容,要知道exitcode是退出码,不同的退出码代表不同的意义,result是运算结果。
- [ ]
Response也是服务端和客户端之间的一个协议。
计算任务函数cal()
服务端进行计算任务的函数cal就是根据请求Request中的两个操作数以及运算符进行计算,并且将计算结果放入到Response中的exitcode以及result中。

在cal函数中,根据Request中的op运算类型进行加减乘除取模不同类型的运算,在除和取模时要判断第二个操作数是否是0,如果时设置相应的exitcode。
计算函数cal放在calServe.cpp中,在mian函数中启动服务器satrt的时候传入这个计算函数即可,具体调用是在handlerEnter中回调的。
-
cal和网络底层连接以及数据报的数据进行了解耦。
- 网络底层连接,数据报处理,具体计算任务,一共分为了三层,每一层之间都实现了解耦。
cal函数并不属于协议定制中的内容,只需要服务端知道即可,客户端无需知道。
读取一个完整报文
客户端发送的Request序列化后成为一个字符串,将这个字符串发送到网络中。
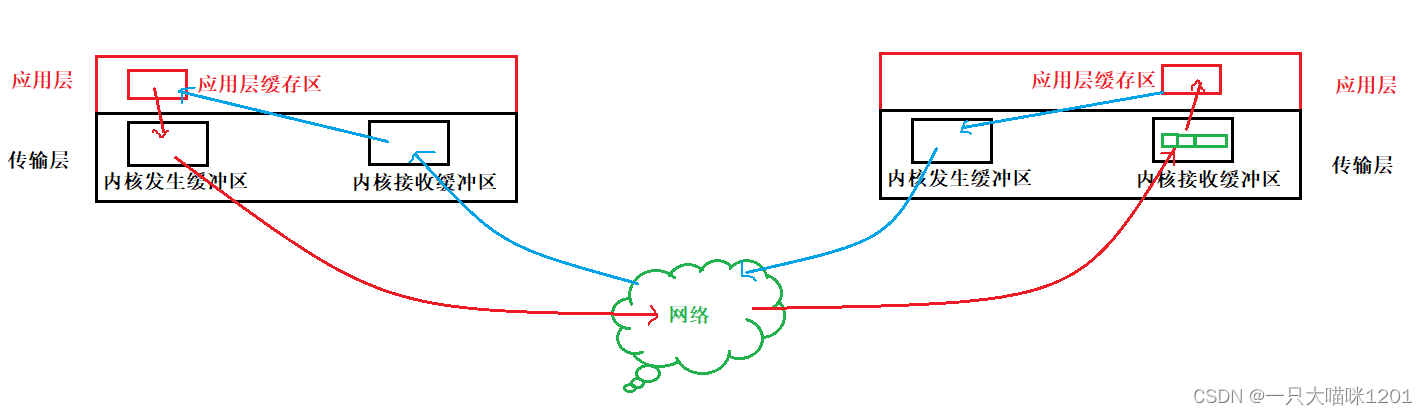
如上图所示,客户端序列化后的字符串存在于应用层的缓存区中,调用socket的系统调将字符串发送到传输层,也就是内核的发送缓冲区中,操作系统在适当的时间再将字符串发送到网络中。
服务端的操作系统将网络中的字符串接收到传输层,也就是内核的接收缓冲区中,应用层再调用socket的系统调用将字符串读取到应用层的缓存区中作进一步处理。
- 套接字在操作系统中属于文件,所以它采用的刷新策略是全缓冲。
所以无论是内核发送缓冲区还是内核接收缓冲区,里面存在的字符串肯定不止一个,也就是说存在的客户端请求有非常多个,如上图服务端内核接收缓冲区中的绿色小方块。
- 如何保证服务端从网络中读取的报文是一个完整的网络请求
Request呢?
tcp是面向字节流的,所以必须明确报文和报文的边界。常用的方式有三种:
- 定长:规定报文字符串的长度,每次读取固定字节个数。
- 特殊符号:通过特殊符号来作为报文和报文之间的分隔。
- 自描述方式:在报文前面加一个报头。
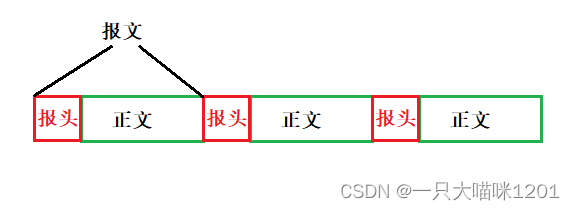
我们采用如上图所示的方式,也就是在正文前面加一个报头,属于上面三种方式中的自描述方式,此时报头加正文组成一个完整的报文。
在读取的时候,遇到报头认为这是报文的起始位置,直到下一个报头为止,之前的数据就是一个完整的报文,此时我们就明确了报文和报文之间的边界了。
本喵这里将正文的长度content_len以字符串的形式封装为报头,正文是客户端序列化以后的字符串content,再增加两个回车换行\r\n方便调试打印。
- 完整报文的形式:
"content_len"“\r\n”"conten"“\r\n”。
此时网络中就会存在很多个报文,形式如".....content_len"“\r\n”"conten"“\r\n”"content_len"“\r\n”"conten"“\r\n.....”,我们要做的就是提取出一个完整的报文。
本喵定义了函数recvPackage专门用来读取一个报文:
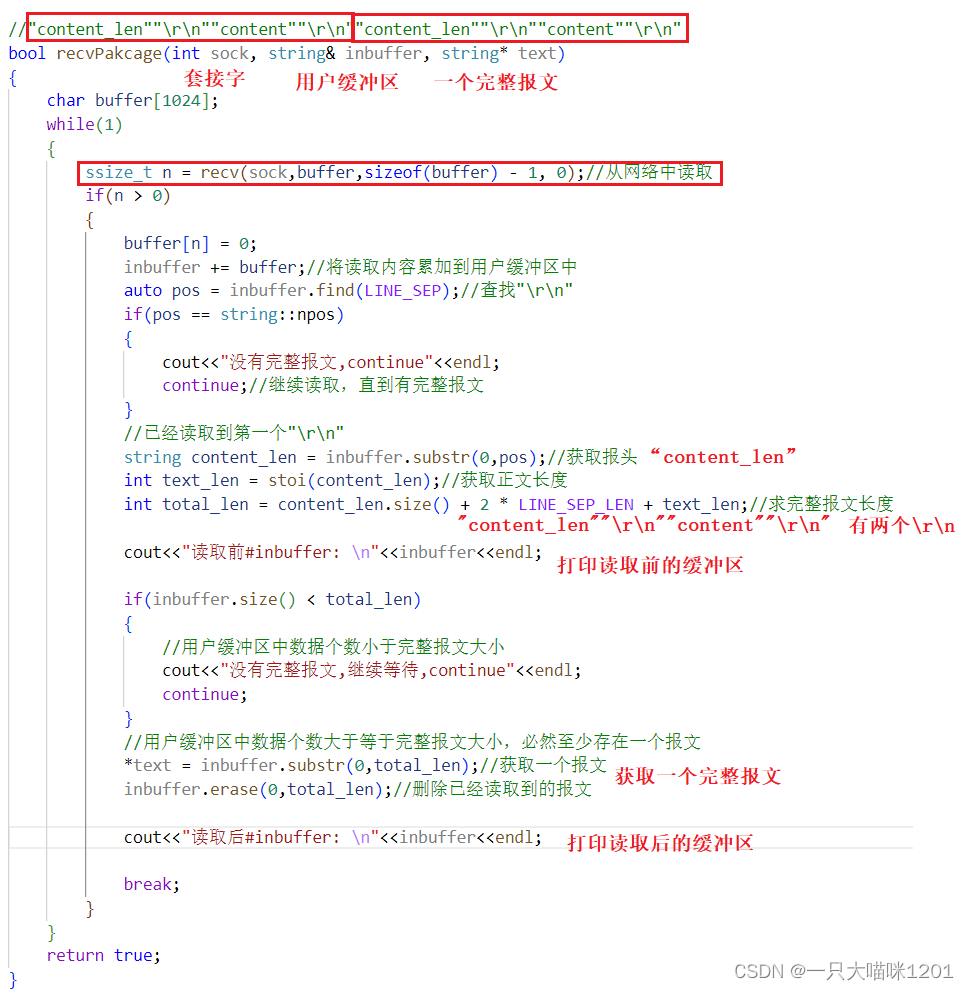
该函数有三个参数,第一个参数套接字的文件描述符sock,从该套接字中读取数据,第二个参数是一个输入型参数inbuffer,是应用层的缓冲区,由服务器来维护,第三个参数是一个输出型参数text,用来存放一个完整的报文。

这里使用recv系统调用来从套接字中读取数据,它的作用以及用法和tcp网络通信中使用read非常相似,只是多了一个参数0,表示阻塞式读取。
将读取到的数据放入到应用层缓冲区inbuffer中,然后进一步分析。
- 首先查找是否存在
\r\n,如果不存在,说明必然没有完整报文,继续读取,所以使用contine跳过后面代码。 - 当查找到
\r\n后,说明此时至少存在一个报头,将报头提取出来,并将对应的报文长度转化成int类型。 - 求取理论上一个完整报文长度
text_len,与inbuffer中的数据个数作比较,如果个数小于text_len,说明缓冲区中没有一个完整的报文,继续读取。 - 如果个数大于等于
text_len,说明和缓冲区中至少有一个完整的报文,可以拿走到text中。
- 这里并不怕
while(1)死循环导致进程阻塞,因为是多进程的。
此时我们就能保证读取一个完整的报文了。
分离报头
现在服务器已经能拿到一个完整的报文了,但是要使用的是报文中的正文,也就是有效载荷。
所以服务端需要一个专门用来解包报头的函数deLength,该函数也属于协议的一部分,所以放在protocol.hpp中,假设现在服务端已经接收到一个报文。

deLength函数有两个参数,第一个参数package就是服务端从网络中读取到的一个字符串,第二个参数text就是正文,是一个输出型参数。
先在package中查找\r\n,如果没有找到,说明这个报文不符合协议标准,返回false,如果找到则截取package中的子串,从0下标截取到\r\n的位置,得到的就是报头。
再从pos + LINE_SEP_LEN处开始截取,截取text_len正文长度个字节,放入输出型参数text中。
- 报头就是正文长度的字符串形式,使用
stoi函数转换成整形以后就是正文真正的长度。substr成员函数的第一个参数是截取字串的起始位置,第二个参数是截取的字节个数。
此时我们就能获取完整报文中的正文(有效载荷)了。
序列化和反序列化
虽然拿到了有效载荷,但是它仍然是一个字符串,进行计算任务需要的是结构化数据Request,所以此时就要进行反序列化。
Request序列化
但是要进行反序列化就必须知道是如何序列化的,前面都是假设已经序列化了,有效载荷就是序列化后的字符串,但是这个字符串具体是什么样子,也就是如何进行序列化的一直没有讲解,现在先来看了是如何进行序列化的。
服务器拿到的有效载荷(正文)一定是客户端发送来的Request的序列化结果,所以字符串中必然有x op y,本喵也是采用这种形式序列化的,三者之间使用空格隔开。
由于序列化的是Request,所以本喵将序列化的函数serialize定义成Request的成员函数:

只有一个参数out,这是一个输出型参数,序列化的结果就放在里面。将三个成员变量x op y变成字符串,再用两个空格隔开,拼接在一起的结果就是序列化后的字符串。
Request反序列化
由于反序列化的是Request,所以本喵将反序列化的函数deserialize定义成Request的成员函数:

该函数的参数in是一个输入型参数,就是去掉报头后的有效载荷,在函数中,将有效载荷根据空格将x op y分离出来,并转化成它们作为成员变量的类型,反序列化就结束了,就可以获得结构化的Request。
- 有效载荷中的
op是字符串,通过[]访问得到是字符char类型,不用再转化,因为成员变量op的类型就是char。
有了反序列的方法后,就可以继续实现我们的handlerEnter了。在拿到有效载荷后,使用Request中的deserialize进行反序列或得到结构化的数据。
然后回调cal函数进行计算,计算的结果是放在Response中的。
Response序列化
Request的序列化和反序列化实现了,趁热打铁,将Response的序列化和反序列化也实现了,本喵采用的是exitcode result的格式,同样将两个成员变量用空格隔开。
同样是成员函数serialize:

Response只有两个成员函数,序列化更简单,本喵不再讲解。
Response反序列化

Response有效载荷中只有一个空格,非常好分离字串,本喵不再讲解。
将计算后的响应Response使用serialize进行序列化,然后再封装报头"content_len"。
此时还需要一个封装报头的函数enLength,报头同样也是协议中的一部分,所以本喵将其放在protocol.hpp中。
封装报头,就是将序列化后的字符串长度以字符串的形式加到前面,再加几个回车换行符,形成"content_len""\r\n""content""\r\n"的形式。

enLength有两个参数,第一个参数text表示有效载荷,就是结构化数据序列化后的字符串,第二个参数package是加上报头以及回车换行后的完整报文。实现比较简单,本喵就不讲解了。
- 序列化的方法也是协议,无论是客户端还是服务端都必须知道是如何序列化和反序列化的。
- 报头也是协议,客户端和服务端都必须知道报头的形式和增加的规则。
此时协议部分的代码已经写完了,接下来就是将这些函数按照合理的顺序放入handlerEnter中了。

如上图代码所示,就是将协议应用起来。

这里在向网络中发送的时候,使用的是系统调用send,用法和tcp网络通信中的write类似,同样只是多了最后一个参数0,表示阻塞式发送。
- 处理顺序:接收完整请求报文 → 请求去报头 → 请求反序列化 → 业务处理 → 响应序列化 → 响应增加报头 → 完整响应报文发送。
🎶客户端实现
客户端同样也是使用tcp网络通信中的客户端代码,所以网络连接部分就不用再管了。
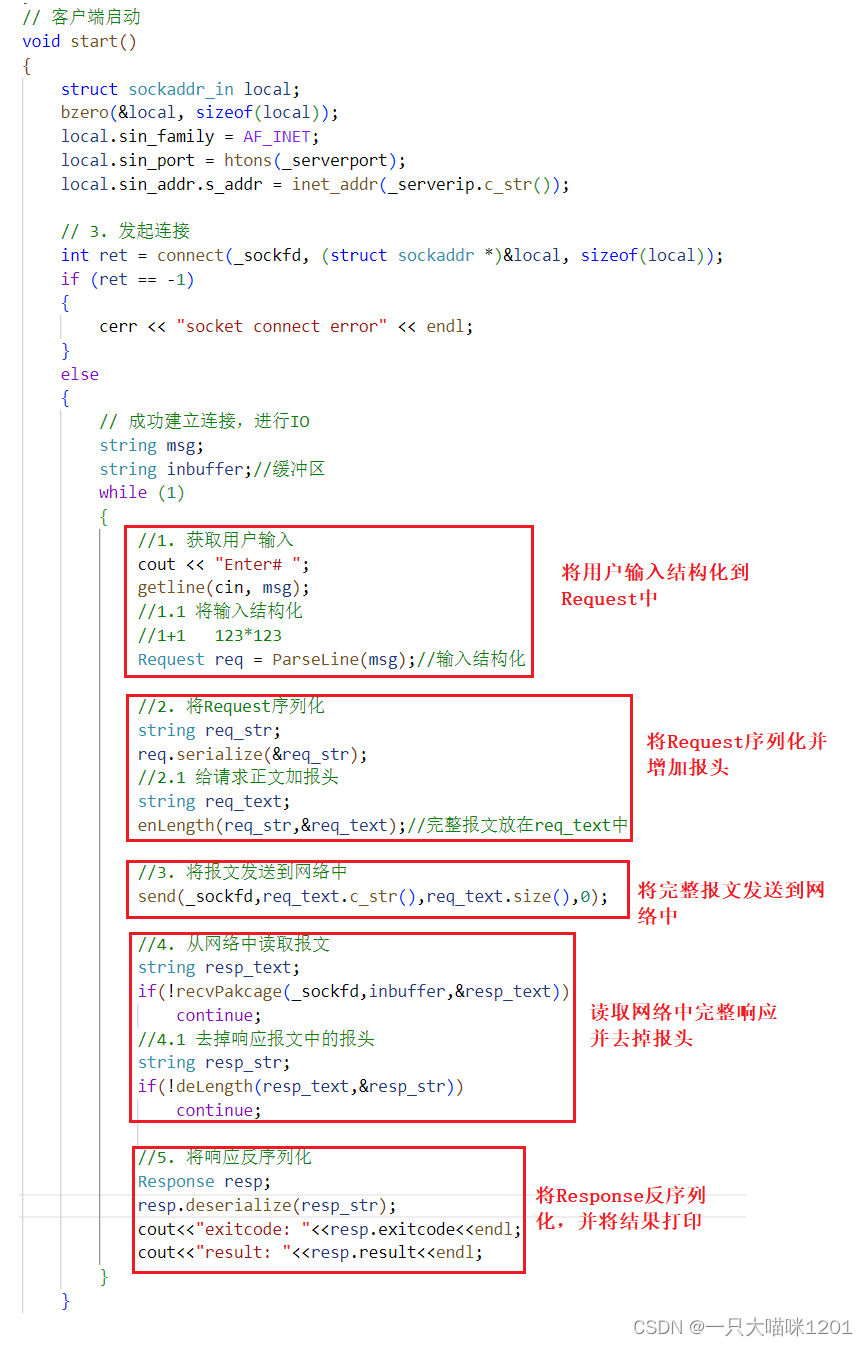
直接在calClient.hpp的start中增加客户端的代码逻辑,如上图代码所示。
首先是获取用户输入,客户端从键盘上输入1+1这种形式的运算表达式,数字和字符之间紧挨着,没有空格。
使用函数ParseLine将用户输入按照Request的协议规定形成结构化数据:
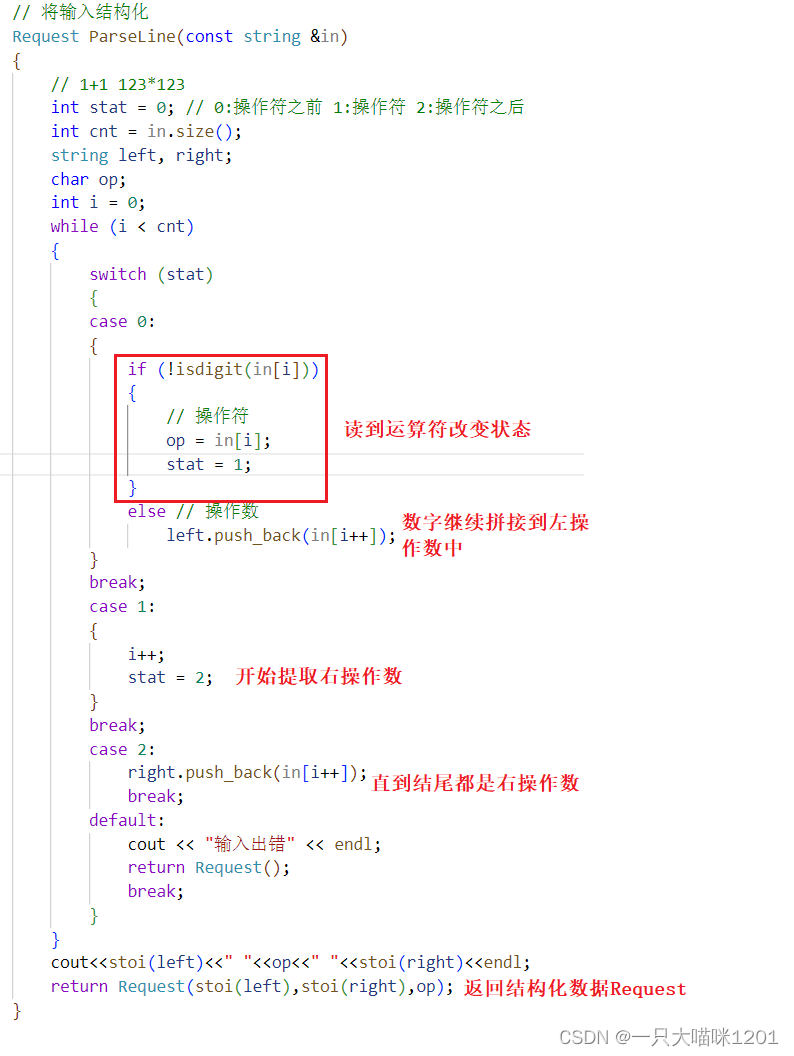
这是一种简易的状态机写法,不同状态表示提取到了输入字符串的不同部分,最终将输入的字符串转化成结构化数据Request。
接下来就是将结构化数据Request序列化,增加报头,然后通过系统调用send发送到网络中。
之后就是从网络中读取服务器的响应报文,同样使用recvPackage来读取一个完整的响应报文,之后去掉报头,再进行反序列化,得到结构化响应Response,并将里面的退出码exitcode和运算结果result打印出来。
- 顺序:获取用户输入并结构化 → 将请求序列化并增加报头 → 将完整请求报文发送到网络中 → 从网络中读取完整响应报文 → 去掉响应报文的报头并且反序列化 → 输出计算结果
在这个过程中,同样会使用到协议规定的enLength,deLength,serialize,deserialze,recvPackage等函数,这些就是客户端和服务端之间的约定,也就是协议。
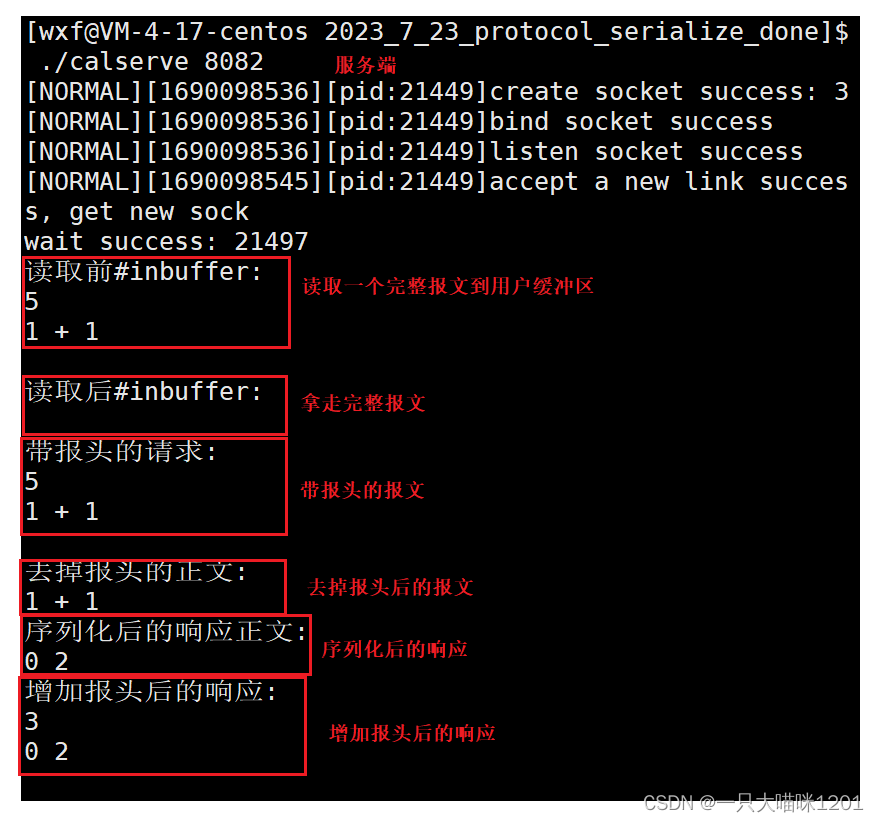
服务端从网络中读取了完整的一个报文,一旦被读走,用户层的缓冲区中这个报文就不在了,将带报头的报文去掉报头,然后进行反序列并计算,将结果放入到Response响应了,并且序列化和增加报头,最后发送到网络中。
- 从打印的调试信息中可以看到关键步骤中字符串的变化。

如上图所示,客户端用户输入1+1并发送给服务端后,从服务端的响应中获取了正确的运算结果。
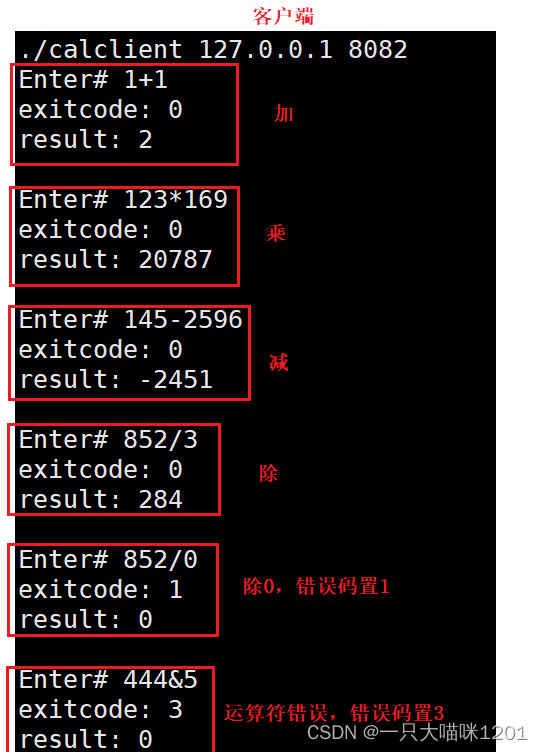
将打印信息屏蔽掉一个,可以看到,客户端提出的计算请求服务器都进行了对应的响,当发生除0错误以及运算符错误时也会设置响应的退出码exitcode。
🔊Json序列化和反序列化
前面本喵手写了一遍如何进行序列化以及反序列化,目的是为了能够更好的感受到序列化和反序列化也是协议的一部分,以及协议被制订的过程。
虽然序列化和反序列化可以自己实现,但是非常麻烦,有一些现成的工具可以直接进行序列化和反序列化,如:
- json——使用简单。
- protobuf——比较复杂,局域网或者本地网络通信使用较多。
- xml——其他编程语言使用(如Java等)。
这里本喵只介绍json的使用,同时这也是使用最广泛的,有兴趣的小伙伴可以去了解下protobuf。
- 对于序列化和反序列化,有现成的解决方案,绝对不要自己去写。
- 序列化和反序列化不等于协议,协议仍然可以自己制定。
安装及注意事项:
在使用json之前,需要先在Linux机器上安装json工具,使用yum去安装:
如上图所示就是安装成功了。

json安装后,它的头文件json.h所在路径为/usr/include/jsoncpp/json/,由于编译器自动查找头文件只到usr/include,所以在使用json时,包含头文件的形式为jsoncpp/json/json.h。
json是一个动态库,它所在路径为/lib64/,完整的名字为libjsoncpp.sp,在使用的时候,编译器会自动到/lib64路径下查找所用的库,所以这里不用包含库路径,但是需要指定库名,也就是掐头去尾后的结果jonscpp。

在makefile中,编译的时候需要指定库名-ljsoncpp,再增加一个宏-DMYSELF,为了实现条件编译。
使用:
Json数据的格式是采用键值对的形式,如:
"first" : x
"second" : y
"oper" : op
"exitcode" : exitcode
"result" : result
就是将不同类型的变量和一个字符串绑定起来形成键值对,序列化的时候将多个字符串拼接在一起形成一个字符串。反序列化的时候再将多个字符串拆开,根据键值对的对应关系找到绑定的变量。
- 这仅仅是一个感性的认识,有兴趣的小伙伴可以自行研究,本喵这里只讲如何使用
Json这个工具。
- 先使用
Json对Request进行序列化和反序列化:

在Request中的序列化serialize函数中使用条件编译,如果#define MYSELF则使用本喵手写的序列化代码,如果没有定义MYSELF则使用Json来序列化。
Json::Value root创建的Value类型对象root可以看作是一个万能对象,然后就是使用root["字符"] = 变量的形式将不同类型的变量和字符串绑定在一起形成键值对。
然后创建Json::FastWriter writer对象writer,再使用write()方法进行序列化,返回的结果就是string类型,所以可以直接赋值给*out。

反序列化同样使用条件编译。
首先需要创建一个万能对象root,然后再创建一个Json::Reader reader对象,调用方法parse()将字符串in反序列化,并且将反序列化后的结果(多个字符串)放入到万能对象root中。
再根据键值对中的key值,也就是"first"等字符串找到绑定的变量,由于此时反序列化后的变量也是字符串,所以需要使用asInt()转化成int类型,此时就完成了反序列化。
- 再使用
Json对Response进行序列化和反序列化:

Response中只有两个成员变量,所以序列化和反序列化起来更简单,做法和Request一样,本喵就不再讲解了,代码如上图所示。
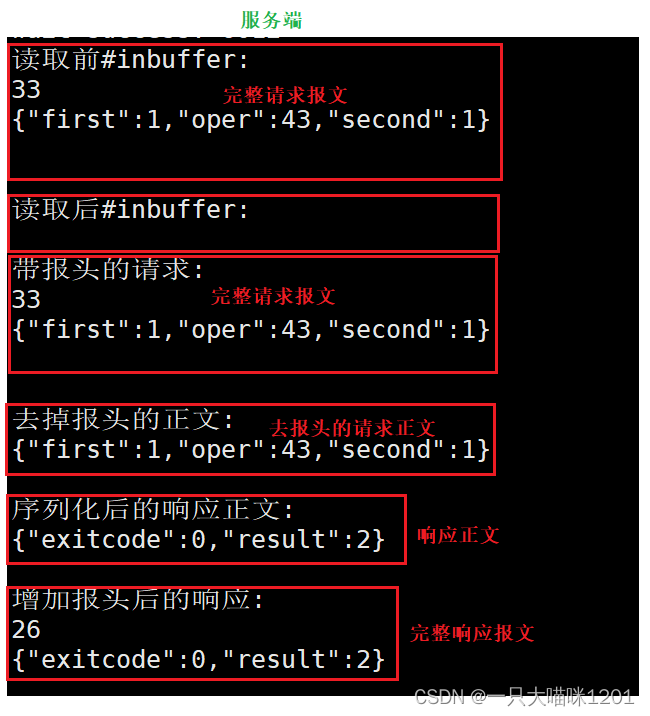
此时服务端中的报文格式就成了{"first" : 1, "oper" : 43(+), "seconde" : 1}键值对数组的形式了,这就是使用Json序列化后的结果。

客户端中的报文格式成了{"exitcode" : 0, "result" : 2}的形式,这也是Json序列化后的结果。
Json序列化后的样子虽然和本喵自己写的不一样,但是并不影响,它只要是一个字符串就可以。Json反序列化后的样子是结构化的,和本喵写的一样,这才是重点,因为真正使用的是结构化数据。
在后面会经常使用到Json,更多的用法在以后会慢慢讲解。
- 序列化和反序列化可以使用
Jons完成,但是报头的增加和去除仍然需要使用我们自己写的enLength和deLength两个函数。 - 报头属于我们自己制定的协议,序列化和反序列化并不影响我们的协议。
🔊初识http协议
网络部分到目前为止,我们已经学习了三部分:
- 基本
socket通信写完,包括tcp和udp的网络通信。 - 一般的服务器设计原则和方式 + 常见的各种常见。
- 自定义协议 + 序列化和反序列化。
今天本喵写的协议是应用层的协议,本喵在写的同时,别人有没有可能写?肯定有,这样一来就会存在很多个人写的不同的应用层协议。
- 所以,已经有大佬针对常见的应用场景,早就写好了常见的协议软件,供我们使用。
hhtp/https就属于这些写好了的常见软件。
先不管http是什么,但是我们知道,它做的事情和我们前面做的事情是一样的,包括:
- 接收完整报文,并且去掉报头。
- 有效载荷反序列化。
- 用户使用结构化数据执行任务。
- 将结构化数据序列化成字符串。
- 给有效载荷增加报头。
- 发生完整报文。
虽然我们现在不知道它是如何实现的,但毫无疑问,http协议肯定比我们写的复杂,而且也更加好用,所以之后我们也不用再自己写了,直接用现成的就可以。
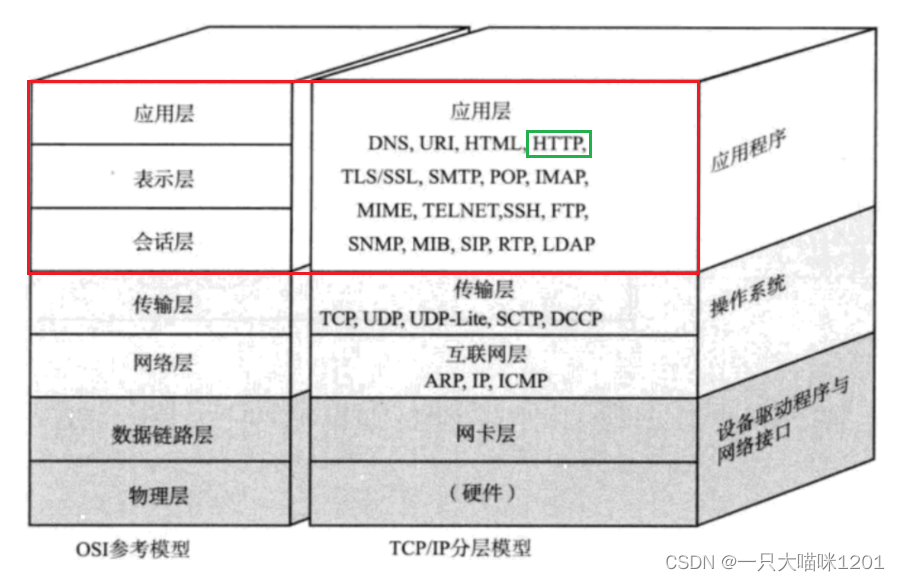
还记得这张图嘛,在OSI模型中,网络可以分为七层,而在TCP/IP模型中,网络分为五层,这是将OSI中的上三层,包括会话层,表示层,应用层归为了一层,统称为应用层。
本喵前面写的网络版计算机中,一共也是分为三层:
- 底层网络连接为一层,包括
class calServe类中的所有成员。这一层对应对应OSI中的会话层。 - 在成员函数
start(func_t func)中调用的handlerEnter为一层,这一层专门用来处理网络中的数据的。对应OSI中的表示层。 - 具体的计算函数
cal为一层,它在表示层被回调,执行真正的业务逻辑。对应OSI中的应用层。
从上图中可以看到,http就位于TCP\IP模型中的应用层,所以OSI模型中的上三层工作http也会做,也就是上面本喵列举的进行序列化和反序列化等六个内容。
🎶认识URL
- 平时我们俗称的“网址”其实就是说的URL。
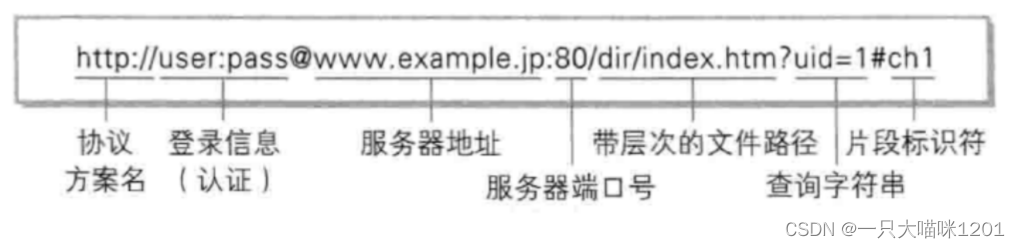
如上图所示是一个使用http协议的网址,以及它隔断字符表示的意思,今天只是见见,不作讲解。

如上图所示的URL是本喵博客主页的网址。
使用的协议是https协议,对比上面http协议的URL发现没有了端口号,这是因为端口号都默认了,使用http协议的进程,端口号是80。使用https协议的进程,端口号是443。
划绿色线的是域名,域名经过域名解析以后就变成了IP地址,所以域名本质上就是一个IP地址,用来标识一台网络主机的唯一性。有IP地址,有端口号,就已经能标识一个进程在网络中的唯一性了。
域名后面的/不要理解为我们Linux机器上的根目录,它是web根目录,也就是说这个根目录是被指定的,可以是任意一个文件夹。
根目录后面的黑色线是文件路径,这个路径下放的就是客户端想要的东西,网络请求就是客户端将数据从服务器的这个路径下拿走。
- 我们平时从网上看到的图片,视频,音频等等网络资源,都静静的放在服务器的磁盘上。
而http协议也可以从服务器拿下来对应的网络资源,这些资源都可以看作是资源文件(本质上也就是文件),又因为服务器上资源种类繁多,但是http都能搞定,所以http被叫做超文本传输协议。
http的具体内部本喵后面会详细讲解。
🔊总结
今天的重点内容就是实实在在的手写了具体的协议,让我们对协议的认识更加深刻。之后无论是序列化还是协议都直接用现成的就好,但是要知道现成的干了什么事情。