文章目录
- 一、分类指标函数
- 1.1 precision_score函数
- 1.2 recall_score函数
- 1.3 accuracy_score函数
- 1.4 f1_score函数
- 1.5 precision_recall_curve函数
- 1.6 roc_curve函数
- 1.7 roc_auc_score函数
- 1.8 classification_report函数
- 二、二分类任务
- 三、多分类任务
- 3.1 Macro Average(宏平均)
- 3.2 Micro Average(微平均)
- 3.3 宏平均 vs. 微平均
在前面的文章中,我们已经介绍了分类指标Precision,Recall,F1-Score的定义和计算公式:详解分类指标Precision,Recall,F1-Score
我们可以知道,精度(precision)、查全率(recall)、F1的计算,是针对于二分类器来定义的。他们的计算,只与y_true和y_pred有关,要求y_true和y_pred中只含有0和1两个类别。
我们在实际计算上述二分类任务的评价指标时,可以直接调用sklearn中的函数库实现。
一、分类指标函数
1.1 precision_score函数
- precision_score函数用于计算分类结果的查准率。
– 官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html
– 函数定义:
sklearn.metrics.precision_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None)
1.2 recall_score函数
- recall_score函数用于计算分类结果的查全率。
– 官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html#sklearn.metrics.recall_score
– 函数定义:
sklearn.metrics.recall_score(y_true, y_pred, labels=None, pos_label=1,
average='binary', sample_weight=None)
1.3 accuracy_score函数
accuracy_score函数用于计算分类结果的准确率。
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
1.4 f1_score函数
f1_score函数用于计算分类结果的值。
sklearn.metrics.f1_score(y_true, y_pred, labels=None, pos_label=1,
average='binary', sample_weight=None)
1.5 precision_recall_curve函数
precision_recall_curve函数用于计算分类结果的P-R曲线。
sklearn.metrics.precision_recall_curve(y_true, probas_pred, pos_label=None,
sample_weight=None)
1.6 roc_curve函数
roc_curve函数用于计算分类结果的ROC曲线。其原型为:
sklearn.metrics.roc_curve(y_true, y_score, pos_label=None, sample_weight=None,
drop_intermediate=True)
1.7 roc_auc_score函数
oc_auc_score函数用于计算分类结果的ROC曲线的面积AUC。
sklearn.metrics.roc_auc_score(y_true, y_score, average='macro', sample_weight=None)
1.8 classification_report函数
sklearn中的classification_report函数用于显示主要分类指标的文本报告,在报告中显示每个类的精确度,召回率,F1值等信息。
sklearn.metrics.classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2)
二、二分类任务
对二分类模型来说,可以直接调用 sklearn.metrics 中的 precision_score, recall_score 和 f1_score 来进行计算,将函数中的 average 参数设置为binary (average='binary') 即可。
应用示例:
from sklearn.metrics import precision_score, recall_score, f1_score, classification_report
y_true = [1, 1, 1, 1, 1, 0, 0, 0, 0, 1]
y_pred = [1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
precision = precision_score(y_true, y_pred, average='binary')
print('precision:', precision)
recall = recall_score(y_true, y_pred, average='binary')
print('recall:', recall)
f1_score = f1_score(y_true, y_pred, average='binary')
print('f1_score:', f1_score)
输出结果如下:
precision: 0.714285714286
recall: 0.833333333333
f1_score: 0.769230769231
我们还可以使用 classification_report 函数来查看每一类的分类情况:
target_names = ['class 0', 'class 1']
cla_report = classification_report(y_true, y_pred, target_names=target_names)
print('cla_report:', cla_report)
输出结果如下:
precision recall f1-score support
class 0 0.67 0.50 0.57 4
class 1 0.71 0.83 0.77 6
avg / total 0.70 0.70 0.69 10
三、多分类任务
前面提到,传统的精度(precision)、查全率(recall)、F1的计算公式,只适用于二分类模型。
对多分类模型来说,要用Macro Average(宏平均)或Micro Average(微平均)规则来进行F1(或者P、R)的计算。
3.1 Macro Average(宏平均)
宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值。
Macro Average(宏平均)会首先针对每个类计算评估指标,如查准率Precesion,查全率 Recall , F1 Score。然后对他们取平均得到Macro Precesion, Macro Recall, Macro F1。具体计算方式如下:
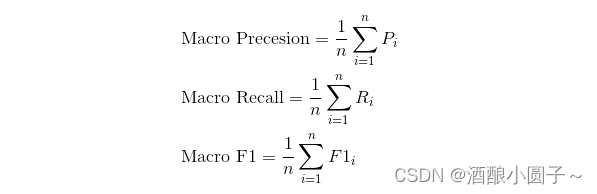
举例来说,假设是三个类别的分类模型:
y_true=[1,2,3]
y_pred=[1,1,3]
Macro Average F1的计算过程如下:
(1)将第1个类别设置为True(1),非第1个类别的设置为False(0),计算P1, R1。
y_true=[1,0,0]
y_pred=[1,1,0]
P1 = (预测为1且正确预测的样本数)/(所有预测为1的样本数) = TP/(TP+FP) = 1/(1+1)=0.5
R1 = (预测为1且正确预测的样本数)/(所有真实情况为1的样本数) = TP/(TP+FN)= 1/1 = 1.0
F1_1 = 2*(PrecisionRecall)/(Precision+Recall)=20.5*1.0/(0.5+1.0)=0.6666667
(2)将第2个类别设置为True(1),非第2个类别的设置为False(0),计算P2, R2。
y_true=[0,1,0]
y_pred=[0,0,0]
P2 = (预测为1且正确预测的样本数)/(所有预测为1的样本数) = TP/(TP+FP) =0.0
R2 = (预测为1且正确预测的样本数)/(所有真实情况为1的样本数) = TP/(TP+FN)= 0.0
F1_2 = 2*(Precision*Recall)/(Precision+Recall)=0
(3)将第3个类别设置为True(1),非第3个类别的设置为False(0),计算其P3, R3。
y_true=[0,0,1]
y_pred=[0,0,1]
P3 = (预测为1且正确预测的样本数)/(所有预测为1的样本数) = TP/(TP+FP) = 1/1=1.0
R3 = (预测为1且正确预测的样本数)/(所有真实情况为1的样本数) = TP/(TP+FN)= 1/1 = 1.0
F1_3 = 2*(PrecisionRecall)/(Precision+Recall)=21.0*1.0/(1.0+1.0)=1.0
(4)对P1、P2、P3取平均为P,对R1、R2、R3取平均为R,对F1_1、F1_2、F1_3取平均F1。
P=(P1+P2+P3)/3=(0.5+0.0+1.0)/3=0.5
R=(R1+R2+R3)/3=(1.0+0.0+1.0)/3=0.6666666
F1 = (0.6666667+0.0+1.0)/3=0.5556
最后这个取平均后的得到的P值/R值,就是Macro规则下的P值/R值。对这个3类别模型来说,它的F1就是0.5556。
【基于sklearn 实现 Macro Average】:
下面给出基于sklearn计算Macro Average(宏平均)的样例,将函数中的 average 参数设置为macro (average='macro') 即可。
from sklearn.metrics import precision_score, recall_score, f1_score
y_true = [1, 2, 3]
y_pred = [1, 1, 3]
precision = precision_score(y_true, y_pred, average='macro')
print('precision:', precision)
recall = recall_score(y_true, y_pred, average='macro')
print('recall:', recall)
f1_score = f1_score(y_true, y_pred, average='macro')
print('f1_score:', f1_score)
输出结果如下:
precision: 0.5
recall: 0.666666666667
f1_score: 0.555555555556
3.2 Micro Average(微平均)
Micro Average(微平均)会考虑到所有类别的贡献,将所有类别的预测结果合并在一起,然后计算整体的性能指标。
Micro-average = (TP + FP) / (TP + TN + FP + FN)
分母就是输入分类器的预测样本个数,分子就是预测正确的样本个数(无论类别)。
对于Micro F1而言,Micro F1 = Micro Recall = Micro Precesion = Accuracy。
【基于sklearn 实现 Micro Average】:
下面给出基于sklearn计算Micro Average(微平均)的样例,将函数中的 average 参数设置为micro (average='micro') 即可。
from sklearn.metrics import precision_score, recall_score, f1_score
y_true = [1, 2, 3]
y_pred = [1, 1, 3]
precision = precision_score(y_true, y_pred, average='micro')
print('precision:', precision)
recall = recall_score(y_true, y_pred, average='micro')
print('recall:', recall)
f1_score = f1_score(y_true, y_pred, average='micro')
print('f1_score:', f1_score)
输出结果如下:
precision: 0.666666666667
recall: 0.666666666667
f1_score: 0.666666666667
3.3 宏平均 vs. 微平均
-
Macro平均:对每个类别的性能指标分别计算平均值,然后再对这些平均值求平均。
– 在Macro平均中,对于每个类别,分别计算查准率、查全率和F1分数,并对这些指标进行简单平均。
– Macro平均给予每个类别相同的权重,不考虑样本数量的差异,因此能够平等对待每个类别。
– Macro平均更适用于每个类别的性能对整体性能均等重要的情况。 -
Micro平均:将所有类别的预测结果合并在一起,然后计算整体的性能指标。
– 在Micro平均中,所有类别的真正例、假正例和假负例的数量总和用于计算查准率、查全率和F1分数。
– Micro平均给予每个样本相同的权重,无论其属于哪个类别,因此对于样本数量不均衡的问题,Micro平均会偏向于样本数量多的类别。
– Micro平均更适用于在不同类别上有明显不均衡样本分布的情况,且更关注整体性能而不是每个类别的个别性能。
总结来说:Macro平均是对每个类别的结果进行独立计算,并对各个类别的结果进行平均,适用于每个类别的性能对整体性能均等重要的情况。而Micro平均是将所有类别的结果合并成一个总体进行计算,适用于样本数量不均衡或关注整体性能的情况。而选择使用哪种平均方法取决于具体的问题和需求。