全文链接:http://tecdat.cn/?p=32118
假如你有一个购物类的网站,那么你如何给你的客户来推荐产品呢?(点击文末“阅读原文”获取完整文档、数据)
相关视频
这个功能在很多电商类网站都有,那么,通过SQL Server Analysis Services的数据挖掘功能,你也可以轻松的来构建类似的功能。
将分为三个部分来演示如何实现这个功能。
此篇文章演示了如何帮助客户使用SQL Server Analysis Services基于此问题来构建简单的挖掘模型。
步骤
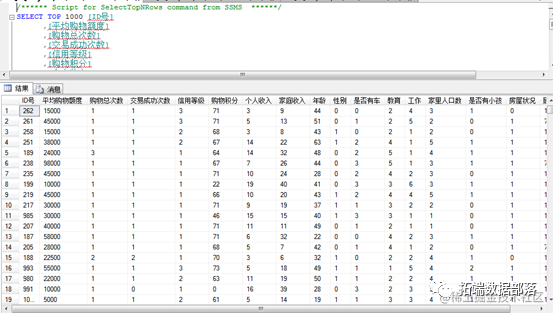
准备工作:数据.xls 数据导入数据库中。


在相应数据库中找到对应的数据
(1) 打开visual studio,新建项目,选择商业智能项目,analysis services项目
将data-mining数据库中的数据导入数据源


在可用对象中,将要分析数据所在表添加到包含的对象中,继续下一步。
在解决方案资源管理器中,右键单击挖掘结构,选择新建挖掘结构。

选择microsoft 决策树,继续下一步
设置测试集和训练集
勾选允许钻取,完成。
然后对模型进行部署,继而进行挖掘(点击运行)
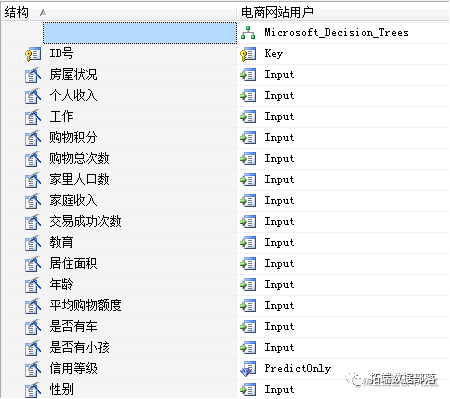
决策树模型
以下我们对电商购物网站的用户的信誉等级进行预测,使用其他用户的特征属性对其进行预测分类。建立如下的决策树模型。
从决策树模型的结果来看,
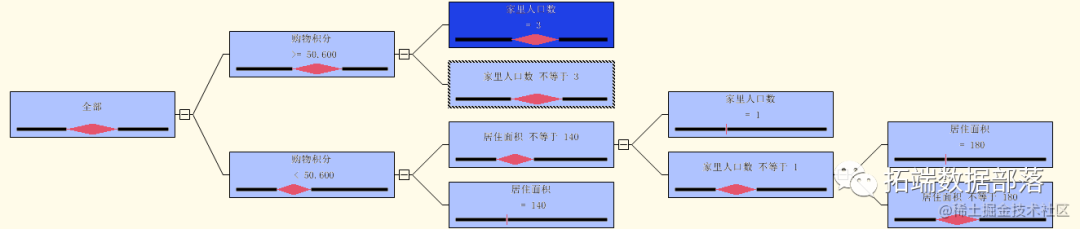
树一共有5个分支。其中重要节点分别为购物积分、家里人口数、居住面积、居住面积等。
点击标题查阅往期内容

PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像

左右滑动查看更多
01
02

03
04

从图中可以看到购物积分越高的用户,决策树得到的用户信誉等级越高。同时家里人口数越多,则信誉等级也越高。说明购物积分直接影响着信誉等级。一般购物次数越多则买家的信誉越高。同时家里人口数越多,则该用户在网上购物的开支越多。因此会导致网上购物越多,最后导致信誉增加。

然后可以看到依赖网络。依赖网络图是指预测变量和其他变量直接的依赖性。从图中可以看到在用户属性中,几个属性会影响信用等级,包括购物积分、次数、居住面积以及人口数量。

聚类
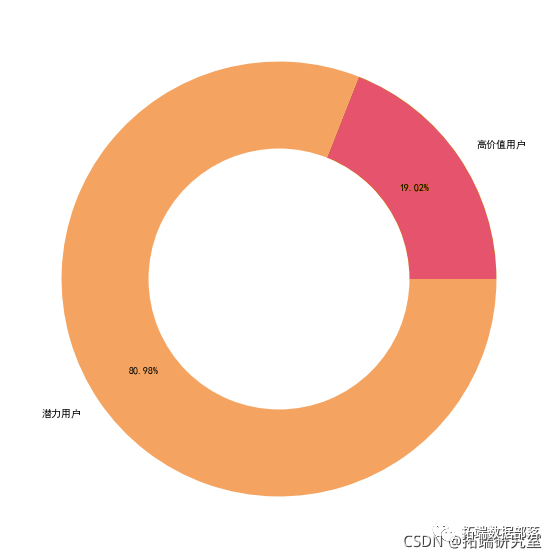
从聚类结果可以看到,聚类将所有用户分成了10个信用级别。

从不同类别的依赖图可以看到,类别10、4、8、5之间具有较强的相关关系。说明这几个类别中的信用级别是类似的。下面可以具体看下每个类别中的各个属性的分布的比例。


从上图可以看到不同类别的购物积分是不同的。
总的来看,相对来说,第4和7类别的购物积分最小的,其他几个类别中积分较高,因此可以认为这些类别中的用户的信用级别较高。同时可以看到这些类别的其他信息,这类用户的月收入较低,购物次数也较小。同时可以看到,这类用户大多的交易成功也较少。另一方面,可以看到低购物积分用户中 ,家庭人口数也较小。

从每个类别的倾向程度来看,购物总次数多的用户交易成功次数也高。从另一方面来看,月收入较高的用户,倾向于是非分类1的用户,也就是它们的信用等级较好。同时可以看到,户交易成功次数多喝购物积分高的用户倾向于非分类1的用户。说明用户的信用等级相对较高。另一方面,可以看到拥有房屋的用户的交易成功次数 电商网站购物次数反而低于没有房屋的用户,可能是因为没有房屋的用户年龄段较低,因此更倾向于网络购物。
然后建立关联规则挖掘模型
运行关联规则,得到以下重要的关联规则

关联规则就是发现数据集中相互有关联的项目。它已经成为数据挖掘领域中具有重要影响的一种算法。也是数据挖掘领域的一个重要分支。最近几年已经被广泛的应用。在电子商务领域,关联规则技术主要用于物品链接页面等的推荐,它只需要购物记录的数据即可,而不需要过多的商品信息,通过关联规则可以发现用户的一些常见的购物模式和购物规律。找出用户通常会一起购买的商品。从而对用户进行推荐和挖掘。

本文中分析的数据和完整文档分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整数据资料。
本文选自《SQL SERVER ANALYSIS SERVICES决策树、聚类、关联规则挖掘分析电商购物网站的用户行为数据》。


点击标题查阅往期内容
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
spss modeler用决策树神经网络预测ST的股票
R语言中使用线性模型、回归决策树自动组合特征因子水平
R语言中自编基尼系数的CART回归决策树的实现
R语言用rle,svm和rpart决策树进行时间序列预测
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言ISLR工资数据进行多项式回归和样条回归分析
R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
如何用R语言在机器学习中建立集成模型?
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
在python 深度学习Keras中计算神经网络集成模型
R语言ARIMA集成模型预测时间序列分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言基于Bootstrap的线性回归预测置信区间估计方法
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
matlab使用分位数随机森林(QRF)回归树检测异常值

![]()