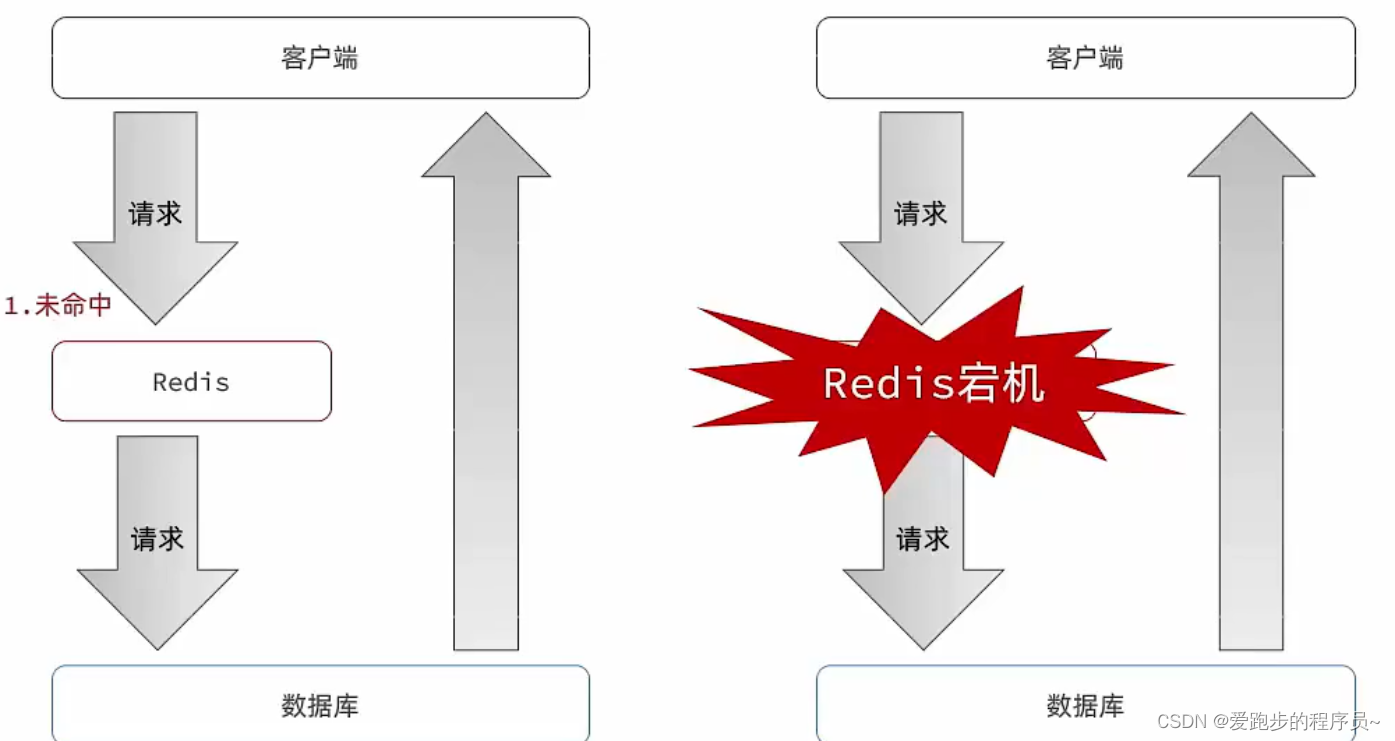
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。为了解决这个问题,我们可以采取以下几种方案。
1. 给不同的Key的TTL添加随机值
在设置缓存的过期时间(TTL)时,可以为不同的缓存key添加一个随机值。这样做的目的是为了避免大量缓存同时失效,从而减少数据库的压力。通过给不同的缓存key设置不同的过期时间,可以使得缓存的失效时间分散在不同的时间段,降低了缓存同时失效的概率。
下面是一个示例代码,演示了如何给缓存key添加随机值:
// 设置缓存key的过期时间,并添加随机值
public void setCacheWithRandomTTL(String key, Object value) {
int ttl = 3600; // 缓存过期时间为1小时
Random random = new Random();
int randomValue = random.nextInt(600); // 随机生成0-600的值
int finalTTL = ttl + randomValue; // 最终的过期时间为ttl + 随机值
redis.set(key, value, finalTTL);
}
2. 利用Redis集群提高服务的可用性
当使用单个Redis服务器时,如果该服务器宕机,将导致缓存不可用。为了提高服务的可用性,可以使用Redis集群。Redis集群将数据分布在多个节点上,当其中一个节点宕机时,其他节点仍然可以提供缓存服务。这样可以降低单点故障的风险,提高系统的稳定性。
下面是一个示例代码,演示了如何使用Redis集群:
// 创建Redis集群连接
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("127.0.0.1", 6379));
nodes.add(new HostAndPort("127.0.0.1", 6380));
JedisCluster jedisCluster = new JedisCluster(nodes);
// 使用Redis集群进行缓存操作
jedisCluster.set("key", "value");
String result = jedisCluster.get("key");
3. 给缓存业务添加降级限流策略
当缓存失效或Redis服务宕机时,为了避免大量请求直接访问数据库,可以给缓存业务添加降级限流策略。降级限流策略可以根据系统的负载情况,动态地限制请求的数量,从而保护数据库免受过多请求的冲击。
下面是一个示例代码,演示了如何给缓存业务添加降级限流策略:
RateLimiter rateLimiter = RateLimiter.create(100); // 每秒最多处理100个请求
if (rateLimiter.tryAcquire()) {
// 缓存业务处理逻辑
// ...
} else {
// 降级处理逻辑
// ...
}
4. 给业务添加多级缓存
除了使用Redis作为缓存,我们还可以在业务中添加多级缓存。多级缓存可以将数据缓存在不同的缓存层中,从而提高缓存的命中率和效率。比如,可以将热门数据缓存在内存中的Redis中,将冷门数据缓存在分布式缓存中,将持久化数据缓存在数据库中。
下面是一个示例代码,演示了如何给业务添加多级缓存:
Object result = localCache.get(key);
if (result == null) {
result = redis.get(key);
if (result == null) {
result = database.get(key);
if (result != null) {
redis.set(key, result);
}
}
localCache.set(key, result);
}
通过以上四种解决方案的组合应用,可以有效地解决缓存雪崩问题,提高系统的性能和可用性。
希望以上内容对你有所帮助!如有任何问题,请随时提问。