来源:投稿 作者:橡皮
编辑:学姐

论文:https://arxiv.org/ftp/arxiv/papers/2205/2205.00908.pdf
代码:https://github.com/TooTouch/MemSeg
主要贡献
-
提出了一个精心设计的异常模拟策略,用于模型的自监督学习,该策略整合了目标前景、纹理和结构异常三个方面。
-
提出了具有更高效的特征匹配算法的记忆模块,并创新性地在U-Net结构中引入了正常模式的记忆信息来辅助模型学习。
-
通过以上两点,并结合多尺度特征融合模块和空间注意力模块,有效地将半监督式异常检测简化为端到端的语义分割任务,使半监督式图像表面缺陷检测更加灵活。
-
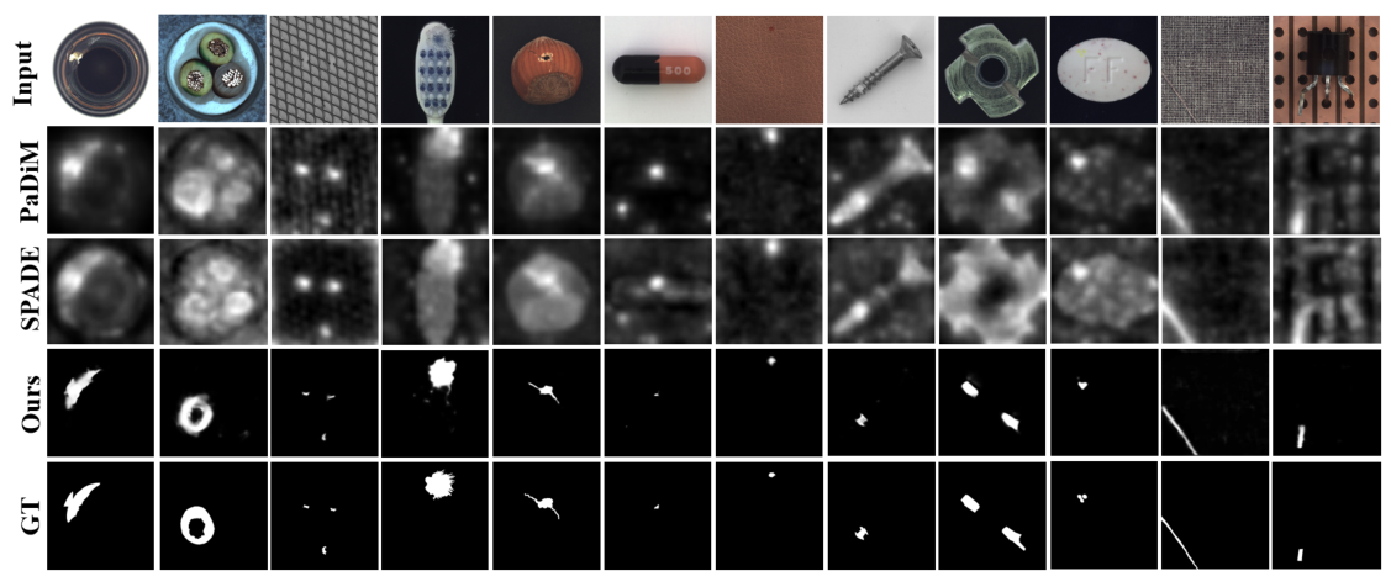
通过大量的实验验证,MemSeg在表面缺陷检测和定位任务中具有较高的准确性,同时更好地满足了工业场景下的实时性要求。
背景
工业场景中产品表面异常的检测对于工业智能的发展至关重要。表面缺陷检测是一个定位图像中异常区域的问题,如划痕和污点。
基于半监督的方法,大多数图像表面缺陷检测模型试图有效探索正常样本的一般模式。但由于CNN强大的泛化能力,异常区域也可能在推理阶段被正确重建,这显然违反了重建模型的基本假设。
基于嵌入的方法显示出比基于重建的方法更好的异常检测性能,但在推理阶段需要进行复杂的特征匹配操作,这给模型的推理带来了过多的计算成本。
鉴于现有方法的缺陷,「本文提出了基于内存的端到端分割网络(MemSeg)来完成产品表面的缺陷检测。」模型能端到端确定图像中的异常区域。同时,模型不完全依赖预训练的模型进行特征提取,缓解了源域和目标域之间分布不一致的问题。

方法概览
MemSeg基于U-Net架构,使用预训练的ResNet18作为编码器。从差异和共性的角度出发,MemSeg引入了模拟异常样本和记忆模块,以更有导向性的方式辅助模型学习,从而以端到端的方式完成了半监督的表面缺陷任务。同时,为了将记忆信息与输入图像的高层特征充分融合,MemSeg引入了多尺度特征融合模块(MSFF模块)和新颖的空间注意力模块,大大提升了异常定位的模型精度。

3.1 异常模拟策略
在工业场景中,异常现象以各种形式出现,在数据采集时不可能涵盖所有的异常现象,这限制了使用监督学习方法进行建模。然而,在半监督框架下,只使用正常样本而不与非正常样本进行比较,是不足以让模型学习到什么是正常模式的。在本文设计了一个更有效的策略来模拟异常样本,并在训练过程中引入异常样本,以完成自监督学习。MemSeg通过比较非正常模式来总结正常样本的模式,以减轻半监督学习的弊端。如图所示,本文提出的异常模拟策略主要分为三个步骤。
-
第一步,掩模图像M使用Perlin噪声和目标前景生成;
-
第二步,在噪声图像I_n中提取由M定义的ROI,生成噪声前景图像 ;
-
第三步,将噪声前景图像叠加到原始图像上,得到模拟的异常图像。

3.1 异常模拟策略步骤详解
第一步,生成二维佩林噪声P,然后通过阈值T对P进行二值化,得到掩码。佩林噪声有几个随机峰值,由它产生
的可以提取图像中连续的区域块。同时,考虑到采集的图像中一些工业成分的主体比例较小,如果不经处理直接进行数据增强,容易在图像的背景部分产生噪声,增加了模拟异常样本与真实异常样本在数据分布上的差异,不利于模型学习有效的判别信息,所以我们对这类图像采取了前景增强策略。即对输入图像I进行二值化处理,得到掩码
,并利用开或关操作去除二值化过程中产生的噪声。之后,通过对两个获得的掩模进行元素范围乘积,得到最终的掩模图像M。
第二步,掩膜图像M和噪声图像进行元素求积,得到
中由M定义的感兴趣区域(ROI)。在这个过程中引入了一个透明度系数δ,以平衡原始图像和噪声图像的融合,使模拟异常的模式更接近真实异常。因此,噪声前景图像是用以下公式生成的:

对于噪声图像 ,希望其最大透明度更高,以增加模型学习的难度,从而提高模型的稳健性。所以对于公式中的δ,将从[0.15, 1]中随机地、均匀地取样。
第三步,将噪声前景图像叠加到原始图像上,得到模拟的异常图像:

3.2 记忆模块和空间注意力图
-
记忆模块:
对于人类来说,识别异常的前提是知道什么是正常的,而异常区域是通过将测试图像与记忆中的正常图像进行比较得到的。受人类学习过程和基于嵌入的方法的启发,使用少量的正常样本作为记忆样本,并使用预先训练好的编码器(ResNet18)提取记忆样本的高级特征作为记忆信息,以帮助MemSeg的学习。
为了获得记忆信息,首先从训练数据中随机选择N个正常图像作为记忆样本,并将其输入编码器,分别从ResNet18的block1,2,3中得到三种尺寸的特征。这些具有不同分辨率的特征共同构成了记忆信息MI。需要强调的是,为了保证记忆信息和输入图像的高级特征的统一,冻结ResNet18中block1、2、3的模型参数,其他部分仍然可以训练。
这些不同分辨率的特征共同构成了输入图像II的信息。之后,计算II和所有内存信息MI之间的L2距离,所以得到输入图像和内存样本之间的N差信息DI:

对于N差异信息,以每个DI中所有元素的最小和为标准,得到II与MI之间的最佳差异信息㼿DI*;即:

最后,串联后的信息将经过多尺度特征融合模块进行特征融合,融合后的特征通过U-Net的跳转连接流向解码器。
3.2 记忆模块和空间注意力图
-
空间注意力图:
从具体的观察和实验中可以看出,最佳差异信息DI* 对异常区域的定位有重要影响。为了充分利用差异信息,我们利用DI* 提取三个空间注意图,用来加强对异常区域最佳差异信息的猜测。
对于DI* 中三个不同维度的特征,在通道维度上计算平均值,分别得到大小为16×16、32×32和64×64的三个特征图。16×16的特征图被直接用作空间注意图M3。在M3被上采样后,与32×32的特征图进行元素相乘运算,得到M2;而在M2被上采样后,与7个64×64的特征图进行元素相乘运算,得到M1。空间注意图M1-3分别对CI1-3得到的信息进行了加权处理。在数学上,解决M1、M2和M3的公式给出如下:

其中,C3表示DI3* 的通道数; DI3i* 表示DI3* 中通道i的特征图;和
分别表示上采样后得到的特征图M3和M2。
3.3 多尺度特征融合模块
在记忆模块的帮助下,我们得到了由输入图像信息II和最佳差异信息DI* 组成的串联信息CI。
直接使用CI,一方面有特征冗余的问题;另一方面,它增加了模型的计算规模,导致推理速度下降。鉴于多尺度特征融合在目标检测中的成功,一个直观的想法是在通道注意机制和多尺度特征融合策略的帮助下,将视觉信息和语义信息充分融合在串联的信息CI。
提出的多尺度特征融合模块如图所示:串联的信息最初由一个保持通道数的3×3卷积层进行融合。同时,考虑通道维度上两种信息的简单串联,用联合注意力来捕捉通道间的信息关系。然后,对于经坐标注意力加权的不同维度的特征,继续进行多尺度信息融合:首先利用上采样对不同维度的特征图进行分辨率对齐,然后利用卷积对通道数进行对齐,最后执行元素相加操作,实现多尺度特征融合。

3.4 训练约束
为了确保MemSeg的预测值接近其真值GT,使用L1损失和focal损失来保证图像空间中所有像素的相似性。与L2损失相比,L1损失约束下预测的分割图像保留了更多的边缘信息。同时,focal损失缓解了图像中正常和异常区域的面积不平衡问题,使模型更加关注困难样本的分割,以提高异常分割的准确性。
具体来说,利用(8)和(9)分别使模拟图像中的异常区域的真实值S和模型的预测值之间的L1 loss和focal loss最小。

最后,我们将所有这些约束条件合并为一个目标函数,得出以下目标函数:

在训练过程中,我们的优化目标是最小化由上式的目标函数。
4.实验


关注下方《学姐带你玩AI》🚀🚀🚀
回复“异常检测”获取全部论文PDF合集
码字不易,欢迎大家点赞评论收藏!