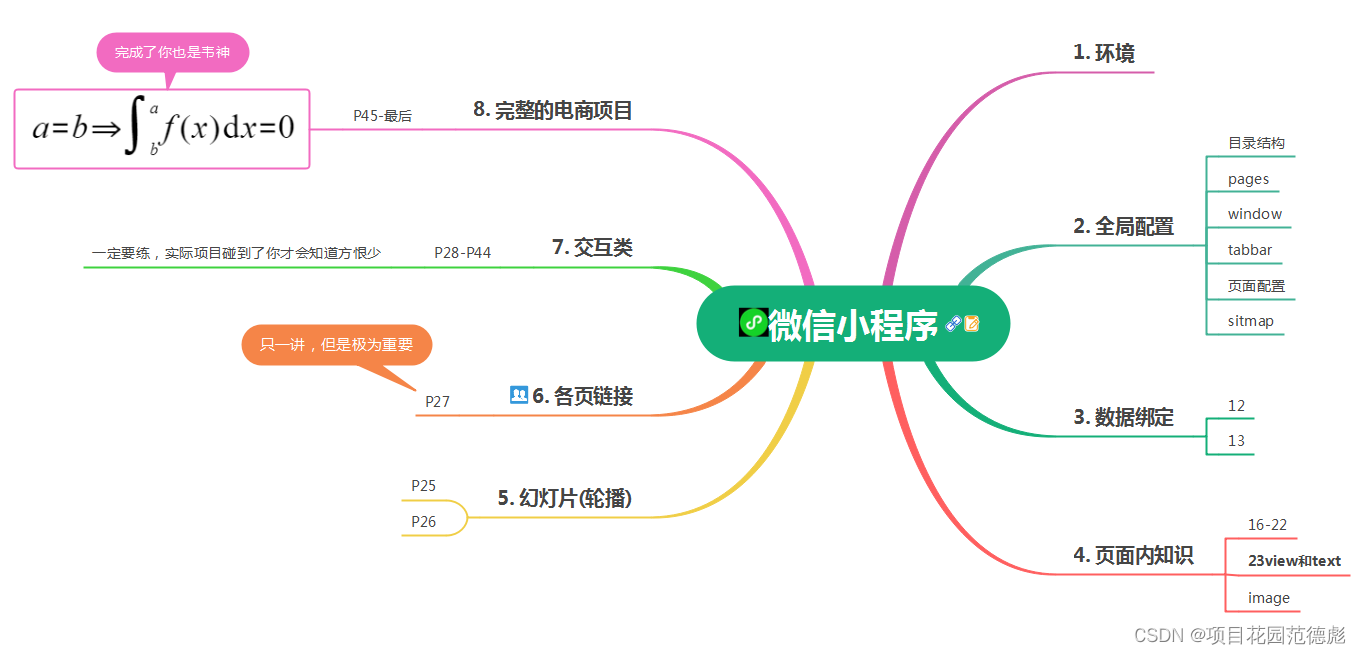
目录
- 1. 说明
- 2. 卷积运算
- 3. 填充
- 4. 池化
- 5. 卷积神经网络实战-手写数字识别的CNN模型
- 5.1 导入相关库
- 5.2 加载数据
- 5.3 数据预处理
- 5.4 数据处理
- 5.5 构建网络模型
- 5.6 模型编译
- 5.7 模型训练、保存和评价
- 5.8 模型测试
- 5.9 模型训练结果的可视化
- 6. 手写数字识别的CNN模型可视化结果图
- 7. 完整代码
1. 说明
从这篇文章开始介绍卷积神经网络CNN,CNN比ANN更适用于图片分类问题。
2. 卷积运算
卷积运算的过程如下图所示,灰度图像(可以认为是一个二维矩阵),通过将卷积核从最左上角贴合,然后将对应位置的数进行相乘再相加就得到了特征图的第一个数。
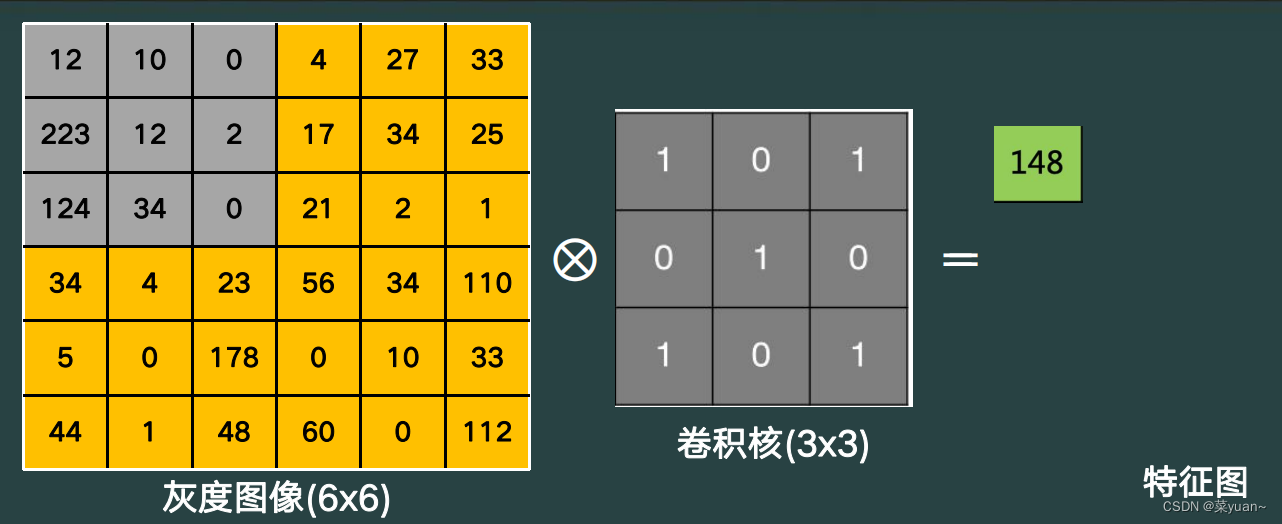
然后通过移动卷积核,再进行对应位置相乘再相加可以得到特征图的第二个结果,这里步长是1。
卷积核的运动方向是先往右运动,到了末尾,然后再向下移动并且回到开头,然后再继续向右运动,经过如此往复运动可以得到下图结果。
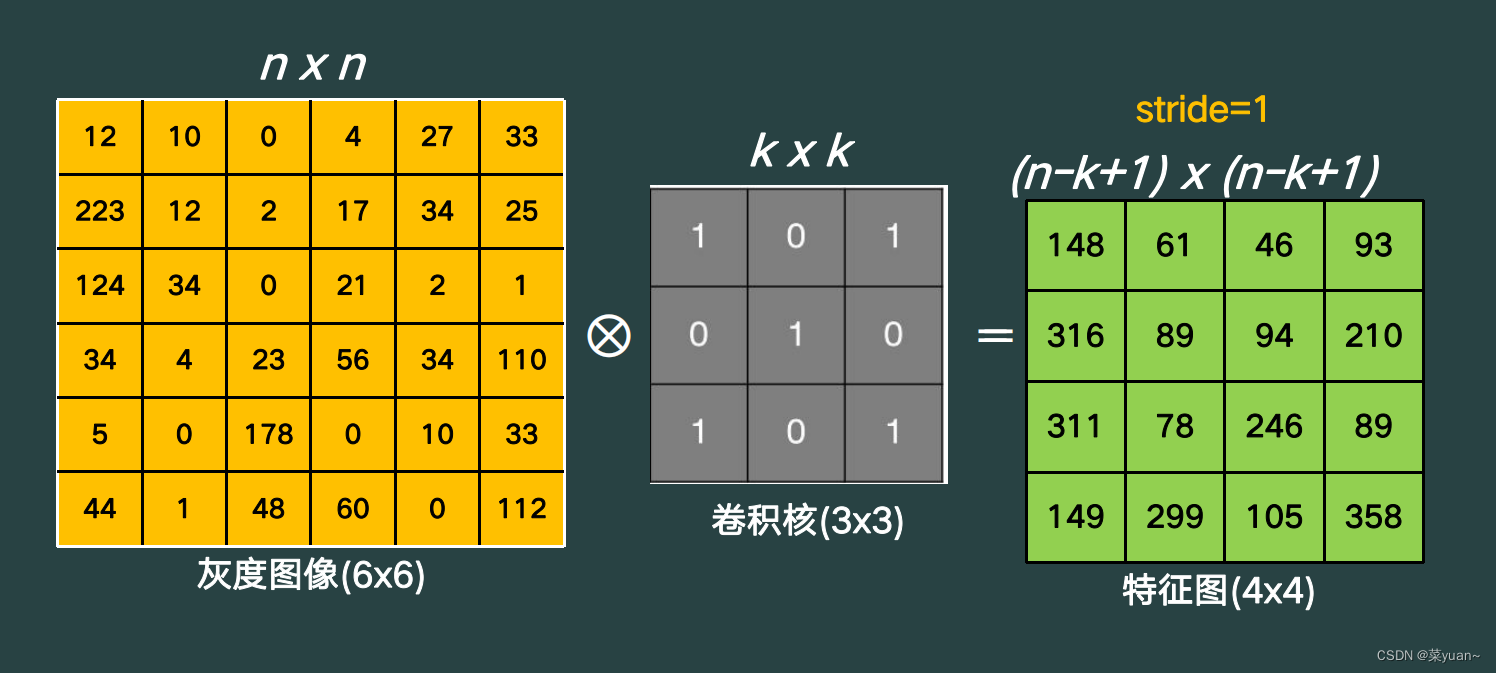
针对于单通道输入和多核现象,就是用每一个卷积核和单通道图像进行运算,最后得到两个特征图,如下图所示。
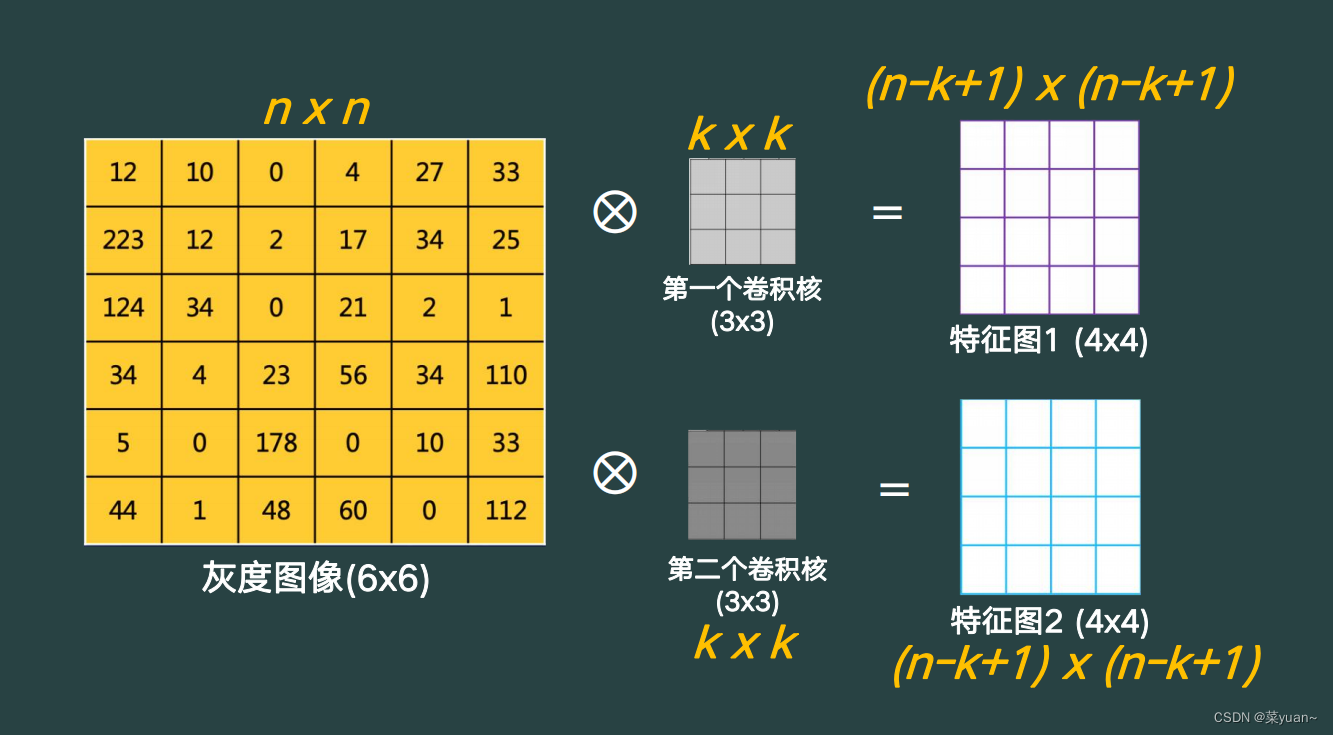
针对于多通道情况,如下图所示。
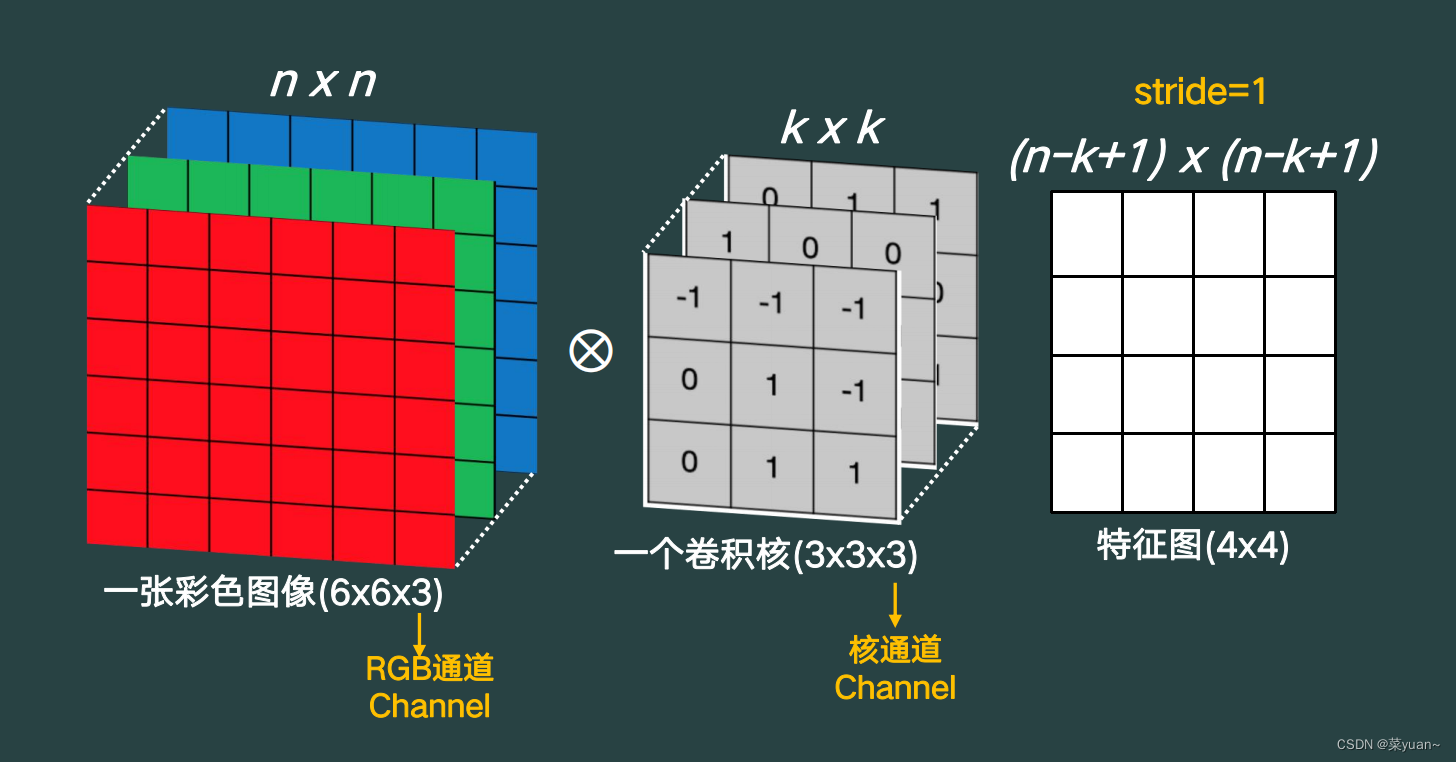
多通道的每个通道和卷积核的对应通道进行卷积,然后把所有通道的运算结果进行相加,得到特征图的结果,如下图。
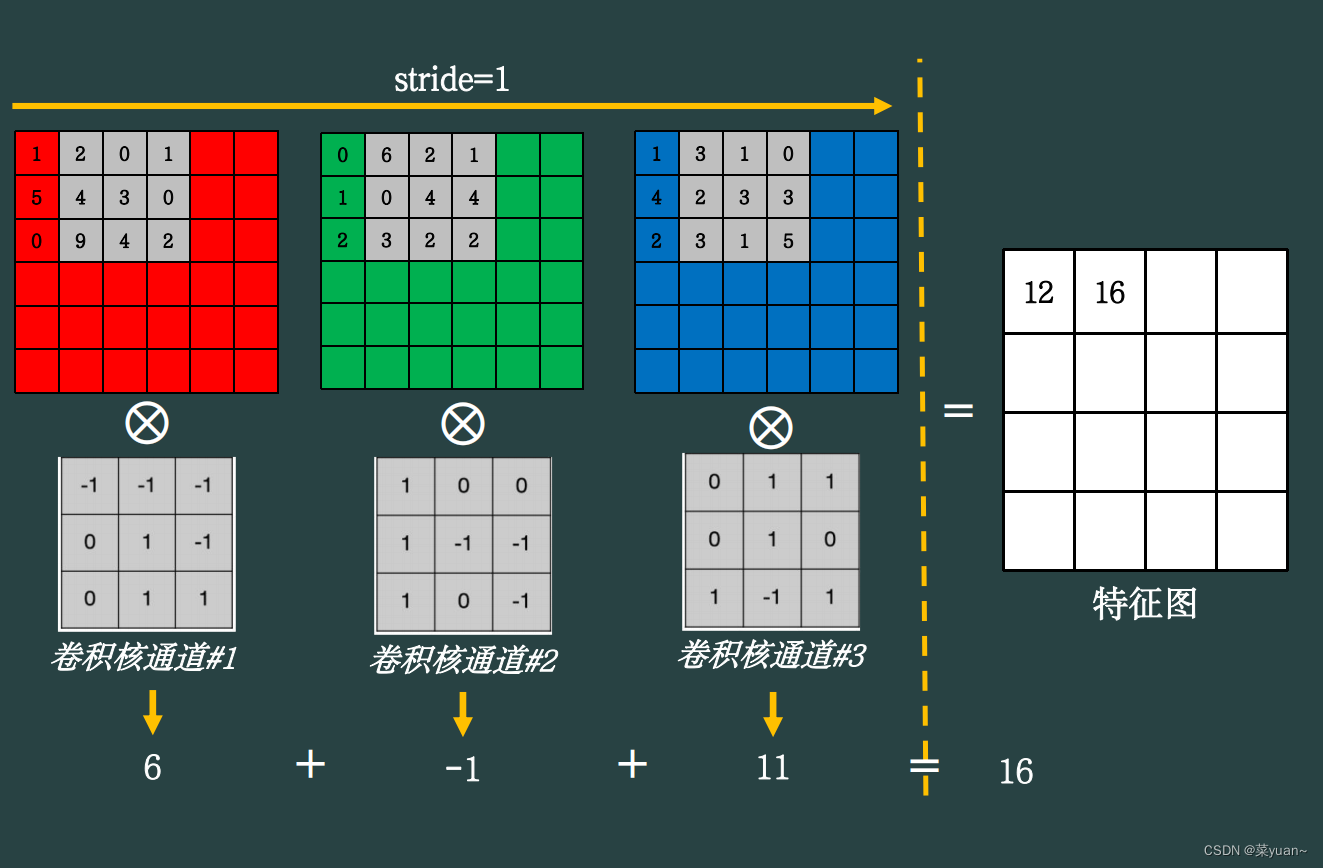
针对于多通道多核现象,就是将每个卷积核和多通道进行运算得到多个特征图,如下图所示。
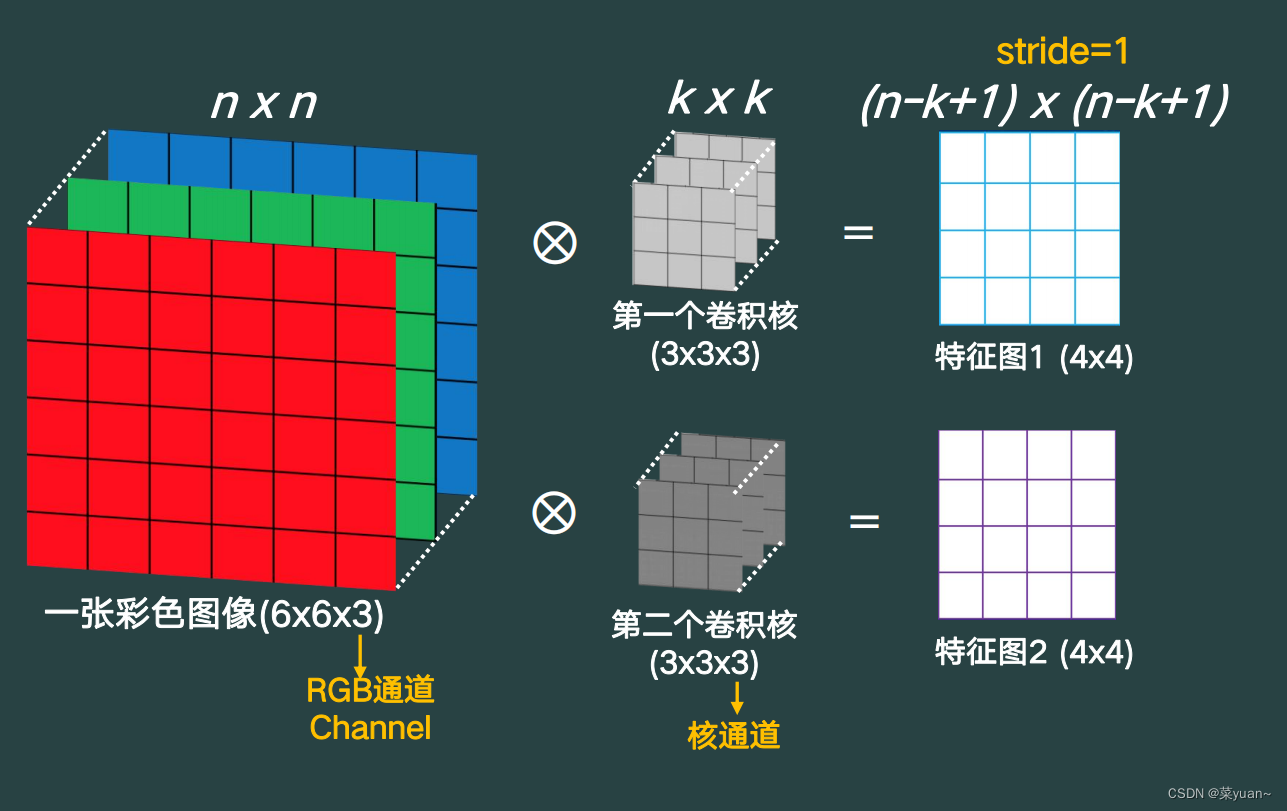
以上均是步长为1的情况,即卷积核每次移动一个像素。如果步长为2,即卷积核每次移动两个像素。
3. 填充
通过上述介绍,我们发现经过多层卷积之后特征图会变得越来越小,会造成信息的缺失,为了降低影响可以进行填充操作,即在特征图的外层加一圈0,然后和卷积核进行运算,如下图所示。
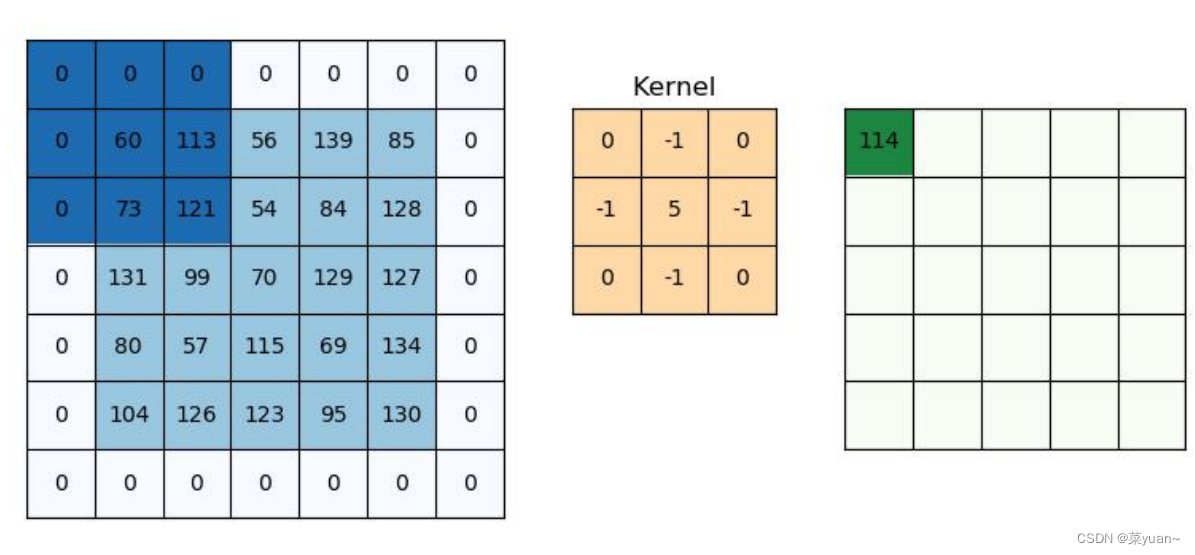
这时候卷积核的参数padding为same,不进行填充时候为valid,默认为valid。
4. 池化
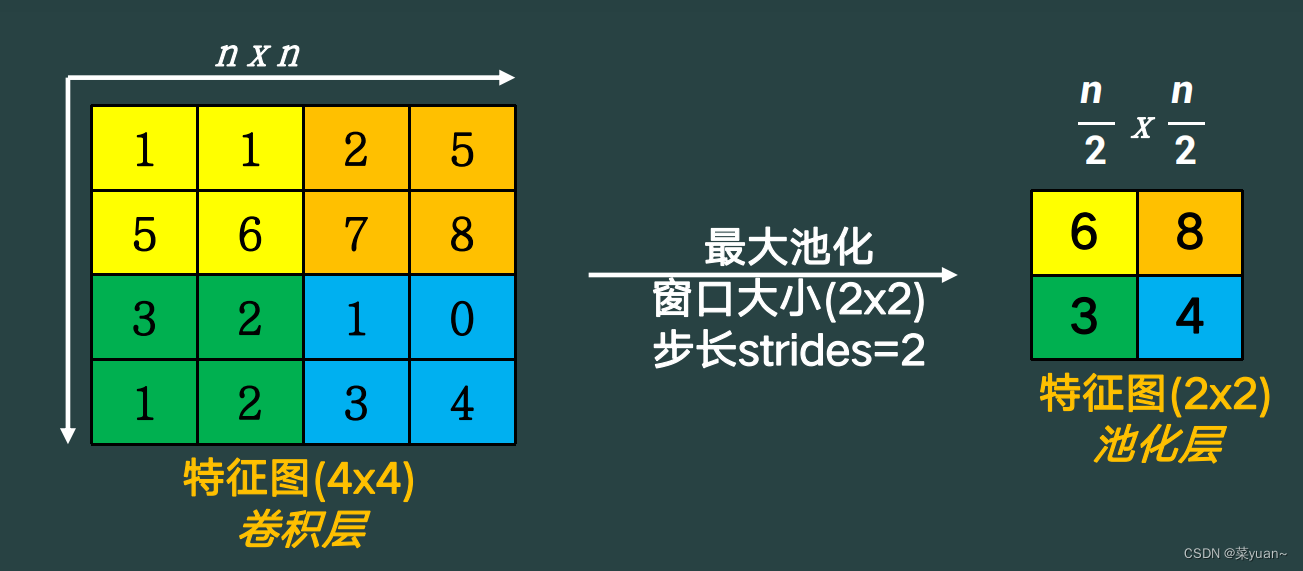
有时候特征图很大,网络的参数太多,为了降低网络的参数量,采用池化操作。池化可分为最大池化和平均池化。
最大池化,就是对特征图在每个池化区域内找出最大值作为输出结果,如下图。
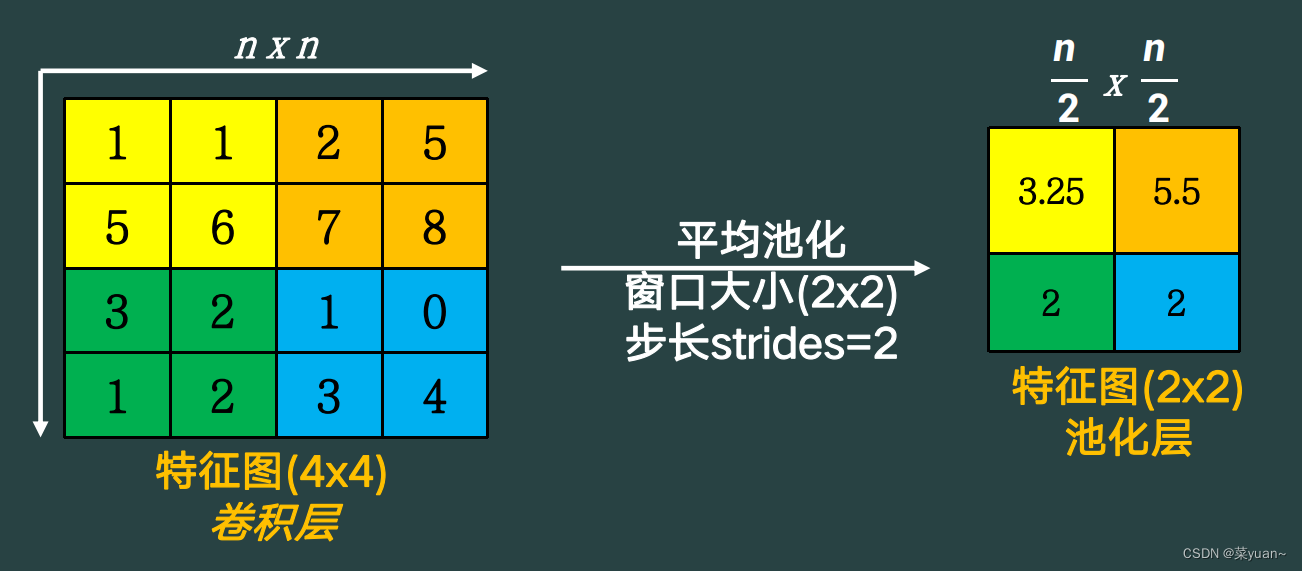
平均池化,就是对特征图在每个池化区域内找进行平均运算得到的结果作为输出结果,如下图。
5. 卷积神经网络实战-手写数字识别的CNN模型
5.1 导入相关库
以下第三方库是python专门用于深度学习的库
from keras.datasets import mnist
import matplotlib.pyplot as plt
from tensorflow import keras
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras.models import Sequential
from keras.callbacks import EarlyStopping
import tensorflow as tf
from keras import optimizers, losses
5.2 加载数据
把MNIST数据集进行加载
"1.加载数据"
"""
x_train是mnist训练集图片,大小的28*28的,y_train是对应的标签是数字
x_test是mnist测试集图片,大小的28*28的,y_test是对应的标签是数字
"""
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 加载mnist数据集
print('mnist_data:', x_train.shape, y_train.shape, x_test.shape, y_test.shape) # 打印训练数据和测试数据的形状
5.3 数据预处理
(1) 将输入的图片进行归一化,从0-255变换到0-1;
(2) 将输入图片的形状(60000,28,28)转换成(60000,28,28,1),便于输入给神经网络;
(3) 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数, 计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算 独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0。
"2.数据预处理"
def preprocess(x, y): # 数据预处理函数
x = tf.cast(x, dtype=tf.float32) / 255. # 将输入的图片进行归一化,从0-255变换到0-1
x = tf.reshape(x, [28, 28, 1])
"""
# 将输入图片的形状(60000,28,28)转换成(60000,28,28,1),
相当于将图片拉直,便于输入给神经网络
"""
y = tf.cast(y, dtype=tf.int32) # 将输入图片的标签转换为int32类型
y = tf.one_hot(y, depth=10)
"""
# 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数,
计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算
独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0
"""
return x, y
5.4 数据处理
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
batchsz = 128 # 每次输入给神经网络的图片数
"""
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
"""
db = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建训练集对象
db = db.map(preprocess).shuffle(60000).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集对象
ds_val = ds_val.map(preprocess).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
5.5 构建网络模型
构建了两层卷积层,两层池化层,然后是展平层(将二维特征图拉直输入给全连接层),然后是三层全连接层。
"3.构建网络模型"
model = Sequential([Conv2D(filters=6, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Conv2D(filters=16, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Flatten(),
Dense(120, activation='relu'),
Dense(84, activation='relu'),
Dense(10,activation='softmax')])
model.build(input_shape=(None, 28, 28, 1)) # 模型的输入大小
model.summary() # 打印网络结构
5.6 模型编译
模型的优化器是Adam,学习率是0.01,
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"4.模型编译"
model.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
"""
模型的优化器是Adam,学习率是0.01,
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"""
5.7 模型训练、保存和评价
模型训练的次数是5,每1次循环进行测试;
以.h5文件格式保存模型;
得到测试集的正确率。
"5.模型训练"
history = model.fit(db, epochs=5, validation_data=ds_val, validation_freq=1)
"""
模型训练的次数是5,每1次循环进行测试
"""
"6.模型保存"
model.save('cnn_mnist.h5') # 以.h5文件格式保存模型
"7.模型评价"
model.evaluate(ds_val) # 得到测试集的正确率
5.8 模型测试
对模型进行测试
"8.模型测试"
sample = next(iter(ds_val)) # 取一个batchsz的测试集数据
x = sample[0] # 测试集数据
y = sample[1] # 测试集的标签
pred = model.predict(x) # 将一个batchsz的测试集数据输入神经网络的结果
pred = tf.argmax(pred, axis=1) # 每个预测的结果的概率最大值的下标,也就是预测的数字
y = tf.argmax(y, axis=1) # 每个标签的最大值对应的下标,也就是标签对应的数字
print(pred) # 打印预测结果
print(y) # 打印标签数字
5.9 模型训练结果的可视化
对模型的训练结果进行可视化
"9.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy'] # 获取模型训练中的accuracy
val_acc = history.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = history.history['loss'] # 获取模型训练中的loss
val_loss = history.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show() # 将结果显示出来
6. 手写数字识别的CNN模型可视化结果图
Epoch 1/5
469/469 [==============================] - 12s 22ms/step - loss: 0.1733 - accuracy: 0.9465 - val_loss: 0.0840 - val_accuracy: 0.9763
Epoch 2/5
469/469 [==============================] - 11s 21ms/step - loss: 0.0704 - accuracy: 0.9793 - val_loss: 0.0581 - val_accuracy: 0.9819
Epoch 3/5
469/469 [==============================] - 11s 22ms/step - loss: 0.0566 - accuracy: 0.9833 - val_loss: 0.0576 - val_accuracy: 0.9844
Epoch 4/5
469/469 [==============================] - 11s 22ms/step - loss: 0.0573 - accuracy: 0.9833 - val_loss: 0.0766 - val_accuracy: 0.9784
Epoch 5/5
469/469 [==============================] - 11s 22ms/step - loss: 0.0556 - accuracy: 0.9844 - val_loss: 0.0537 - val_accuracy: 0.9830

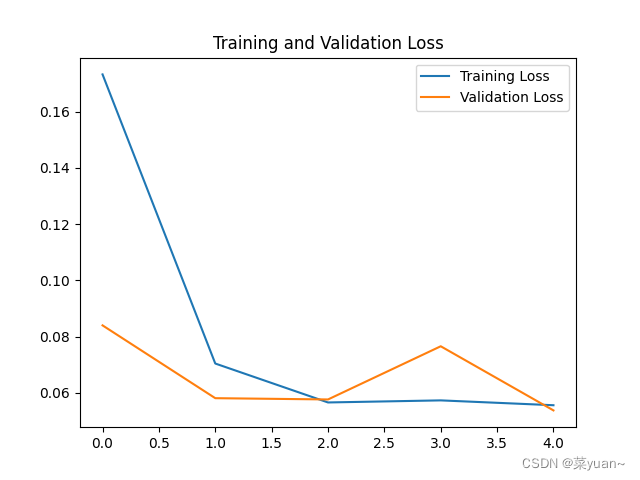
从以上结果可知,模型的准确率达到了98%。
7. 完整代码
from keras.datasets import mnist
import matplotlib.pyplot as plt
from tensorflow import keras
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras.models import Sequential
from keras.callbacks import EarlyStopping
import tensorflow as tf
from keras import optimizers, losses
"1.加载数据"
"""
x_train是mnist训练集图片,大小的28*28的,y_train是对应的标签是数字
x_test是mnist测试集图片,大小的28*28的,y_test是对应的标签是数字
"""
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 加载mnist数据集
print('mnist_data:', x_train.shape, y_train.shape, x_test.shape, y_test.shape) # 打印训练数据和测试数据的形状
"2.数据预处理"
def preprocess(x, y): # 数据预处理函数
x = tf.cast(x, dtype=tf.float32) / 255. # 将输入的图片进行归一化,从0-255变换到0-1
x = tf.reshape(x, [28, 28, 1])
"""
# 将输入图片的形状(60000,28,28)转换成(60000,28,28,1),
相当于将图片拉直,便于输入给神经网络
"""
y = tf.cast(y, dtype=tf.int32) # 将输入图片的标签转换为int32类型
y = tf.one_hot(y, depth=10)
"""
# 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数,
计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算
独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0
"""
return x, y
batchsz = 128 # 每次输入给神经网络的图片数
"""
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
"""
db = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建训练集对象
db = db.map(preprocess).shuffle(60000).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集对象
ds_val = ds_val.map(preprocess).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
"3.构建网络模型"
model = Sequential([Conv2D(filters=6, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Conv2D(filters=16, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Flatten(),
Dense(120, activation='relu'),
Dense(84, activation='relu'),
Dense(10,activation='softmax')])
model.build(input_shape=(None, 28, 28, 1)) # 模型的输入大小
model.summary() # 打印网络结构
"4.模型编译"
model.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
"""
模型的优化器是Adam,学习率是0.01,
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"""
"5.模型训练"
history = model.fit(db, epochs=5, validation_data=ds_val, validation_freq=1)
"""
模型训练的次数是5,每1次循环进行测试
"""
"6.模型保存"
model.save('cnn_mnist.h5') # 以.h5文件格式保存模型
"7.模型评价"
model.evaluate(ds_val) # 得到测试集的正确率
"8.模型测试"
sample = next(iter(ds_val)) # 取一个batchsz的测试集数据
x = sample[0] # 测试集数据
y = sample[1] # 测试集的标签
pred = model.predict(x) # 将一个batchsz的测试集数据输入神经网络的结果
pred = tf.argmax(pred, axis=1) # 每个预测的结果的概率最大值的下标,也就是预测的数字
y = tf.argmax(y, axis=1) # 每个标签的最大值对应的下标,也就是标签对应的数字
print(pred) # 打印预测结果
print(y) # 打印标签数字
"9.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy'] # 获取模型训练中的accuracy
val_acc = history.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = history.history['loss'] # 获取模型训练中的loss
val_loss = history.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show() # 将结果显示出来