encoder-decoder

分心模型:没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
attention中encoder-decoder特点
Encoder将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行输出预测,这样,在产生每一个输出的时候,都能找到当前输入对应的应该重点关注的序列信息,也就是说,每一个输出单词在计算的时候,参考的语义编码向量c都是不一样的,所以说它们的注意力焦点是不一样

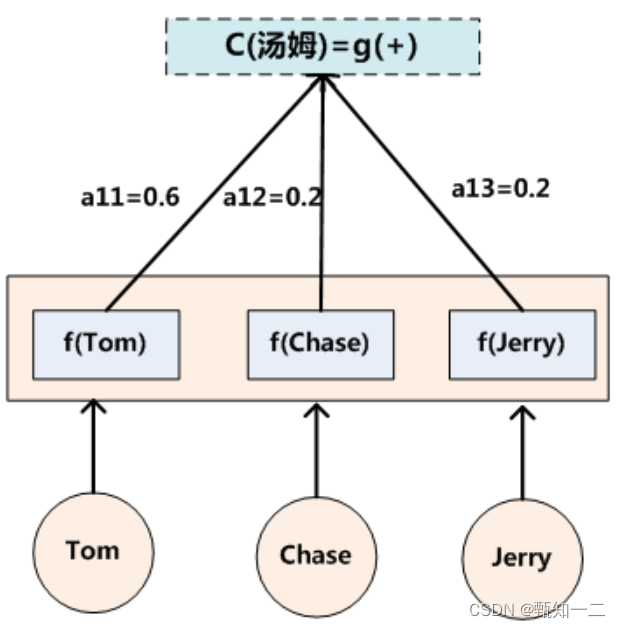
预测结果中的每个词汇的时候,每个语义向量c中的元素具有不同的权重
attention 优点
- Attention大大提高了机器翻译的表现
Decoder在每一步都更加关注源语言的不同部分 - Attention 解决了bottleneck problem
Decoder 可以直接关注到源语言的每个词,而不需要用一个向量来表示源句子 - Attention 可以缓解梯度消失问题
类似skip-connection - Attention 增加了可解释性
可以直观的看出来decoder在每一步更关注源语言的哪些部分
-只能在Decoder阶段实现并行运算,Encoder部分依旧采用的是RNN,LSTM这些按照顺序编码的模型,Encoder部分还是无法实现并行运算
Q K V 介绍
在注意力机制中,Q(Query)、K(Key)和V(Value)是三个重要的输入向量,它们在计算注意力权重时起到不同的作用。
-
Query(Q):Query是用来表示当前位置或当前时间步的输入信息,它用来计算注意力权重,决定模型在当前位置需要关注的信息。Query向量通常是通过对当前位置的输入进行线性变换得到的。
-
Key(K):Key用来表示其他位置或其他时间步的输入信息,它用来计算当前位置与其他位置之间的关联程度。Key向量通常也是通过对其他位置的输入进行线性变换得到的。
-
Value(V):Value用来表示其他位置或其他时间步的输入信息的实际值,它在计算注意力权重后被加权求和,得到最终的加权表示。Value向量通常也是通过对其他位置的输入进行线性变换得到的。
在计算注意力权重时,Query向量与Key向量之间的相似度决定了当前位置与其他位置之间的关联程度。相似度可以通过点积、缩放点积、加性等方式计算得到。然后通过对相似度进行归一化,得到注意力权重。最后,将注意力权重与对应位置的Value向量相乘并求和,得到当前位置的加权表示。
Q、K、V的引入使得注意力机制能够根据不同位置之间的关联程度,选择性地关注与当前任务相关的信息,提高模型的性能和泛化能力。

Q K V计算

注意力机制说白了就是要通过训练得到一个加权,自注意力机制就是要通过权重矩阵来自发地找到词与词之间的关系。
因此肯定需要给每个input定义tensor,然后通过tensor间的乘法来得到input之间的关系。
那这么说是不是给每个input定义1个tensor就够了呢?不够啊!如果每个input只有一个相应的q,那么q1和q2之间做乘法求取了a1和a2的关系之后,这个结果怎么存放怎么使用呢?而且a1和a2之间的关系是对偶的吗?如果a1找a2和a2找a1有区别怎么办?只定义一个这模型是不是有点太简单了

定义这3个tensor,一方面是为了学习输入之间的关系、找到和记录谁和谁的关系权重,一方面也是在合理的结构下引入了可学习的参数,使得网络具有更强的学习能力
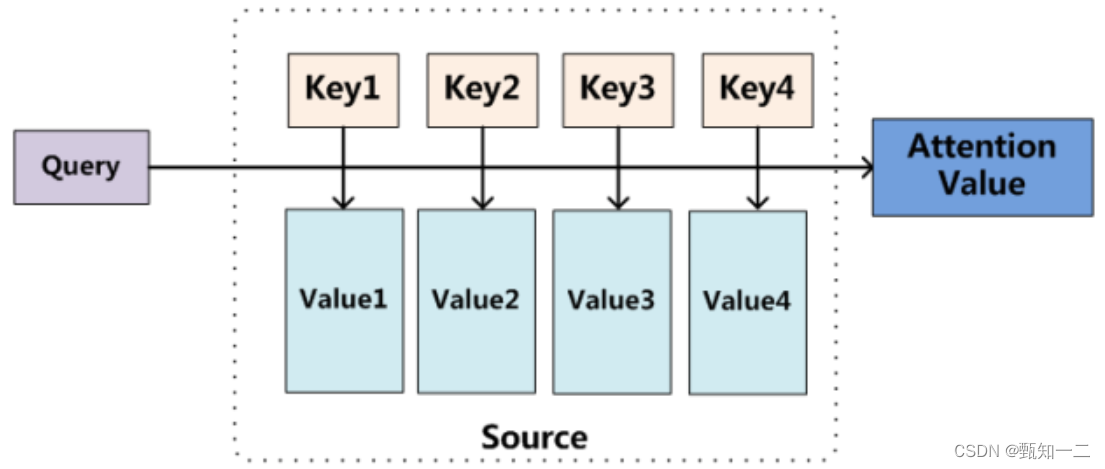
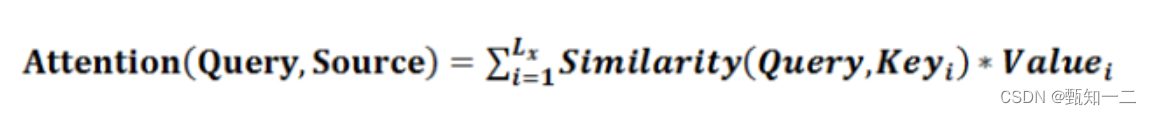
将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值
本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数
计算过程
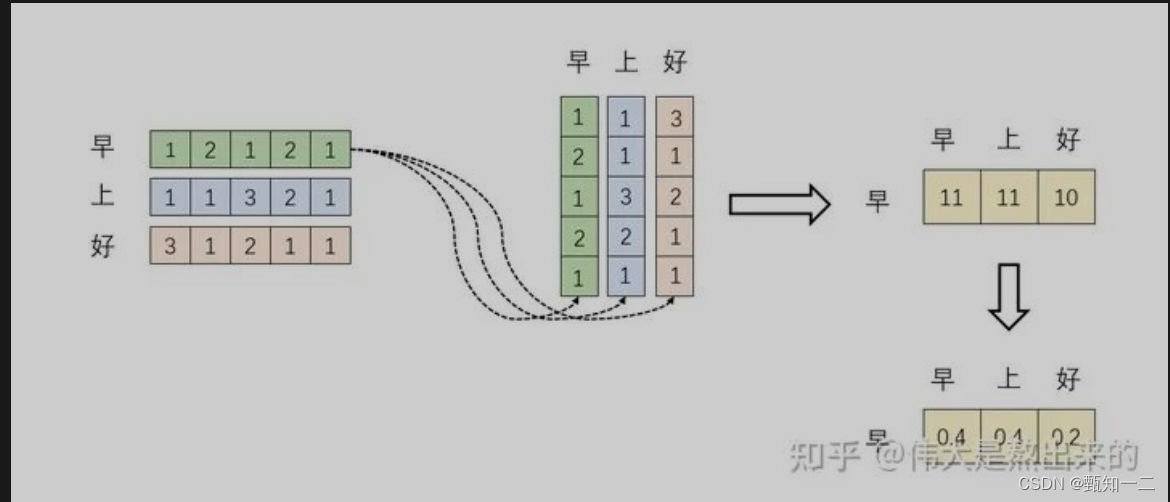
第一个过程是根据Query和Key计算权重系数
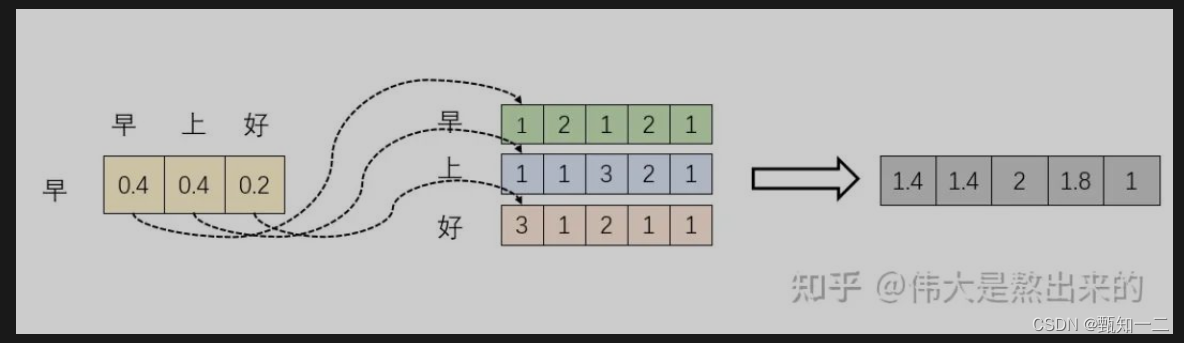
第二个过程根据权重系数对Value进行加权求和。
而第一个过程又可以细分为两个阶段:
第一个阶段根据Query和Key计算两者的相似性或者相关性;
第二个阶段对第一阶段的原始分值进行归一化处理;
这样,可以将Attention的计算过程抽象为如图10展示的三个阶段:
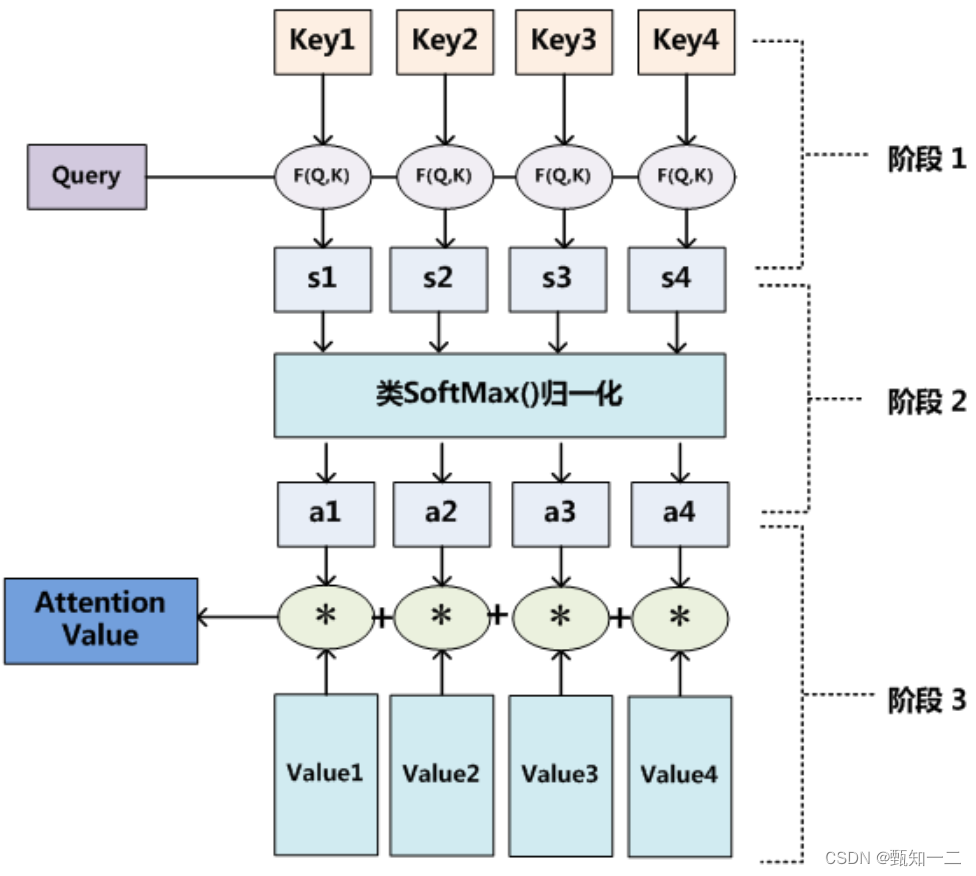
第一阶段
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个Key_i,计算两者的相似性或者相关性,
最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

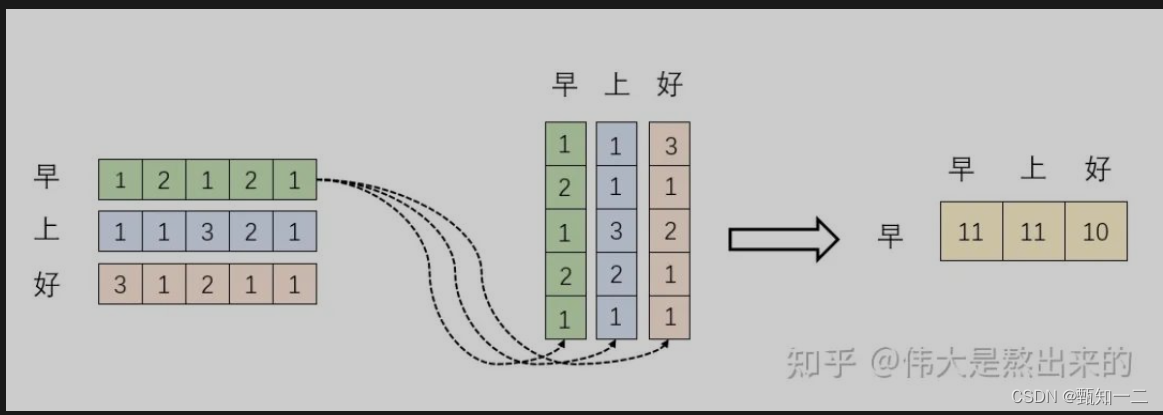
矩阵 是一个方阵,我们以行向量的角度理解,里面保存了每个向量与自己和其他向量进行内积运算的结果
向量的内积表征两个向量的夹角,表征一个向量在另一个向量上的投影
第二阶段
第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,
一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;
另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重
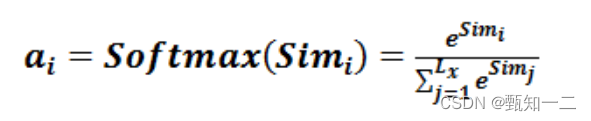
第三阶段
a_i即为value_i对应的权重系数,然后进行加权求和即可得到Attention数值
每一个维度的数值都是由三个词向量在这一维度的数值加权求和得来的
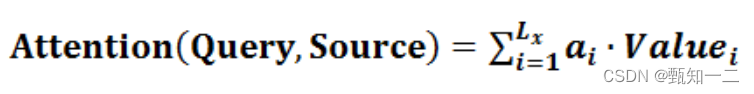
为什么attention可以产生聚焦的功能
Attention机制可以产生聚焦的功能,主要有以下几个原因:
-
选择性加权:Attention机制通过对输入序列中的不同位置进行加权,可以选择性地关注与当前任务相关的信息,而忽略与任务无关的信息。这样可以提高模型对于重要信息的关注程度,从而实现聚焦的效果。
-
上下文关联:Attention机制可以根据上下文关联性动态地调整加权,使得模型能够更好地理解输入序列中不同位置之间的关系。通过上下文关联,模型可以更准确地聚焦于与当前任务相关的信息,提升模型的性能。
-
多头注意力:在一些复杂的任务中,单一的注意力机制可能无法满足需求。多头注意力机制可以同时关注输入序列中的不同部分,从而实现多个聚焦点的功能。通过多头注意力,模型可以同时关注多个相关的信息,提高模型的表达能力和泛化能力。
总的来说,Attention机制通过选择性加权和上下文关联的方式,可以使模型更好地聚焦于与当前任务相关的信息,提高模型的性能和泛化能力。
怎么样选择性加权
选择性加权是通过计算注意力权重来实现的。常见的计算注意力权重的方法有以下几种:
-
点积注意力(Dot Product Attention):将查询向量与键向量进行点积操作,然后经过softmax函数得到注意力权重。这种方法适用于序列长度相对较短的情况,计算效率高。
-
缩放点积注意力(Scaled Dot Product Attention):在点积注意力的基础上,通过除以一个缩放因子,可以控制注意力权重的分布范围,提高模型的稳定性和泛化能力。
-
加性注意力(Additive Attention):将查询向量和键向量通过全连接层映射到一个共同的特征空间,然后计算特征之间的相似度,再经过softmax函数得到注意力权重。这种方法可以处理更复杂的注意力权重计算,但计算复杂度较高。
-
多头注意力(Multi-head Attention):将输入序列通过多个不同的查询、键和值映射矩阵进行线性变换,然后分别计算多个注意力权重。最后将多个注意力权重进行拼接或加权求和,得到最终的加权表示。多头注意力可以同时关注多个相关的信息,提高模型的表达能力。
在选择性加权时,可以根据具体任务和数据的特点选择合适的注意力计算方法。不同的注意力计算方法可能适用于不同的场景,需要根据具体情况进行选择和调整。
self attention
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。
本质上是目标语单词和源语单词之间的一种单词对齐机制
而Self-Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制
self-attention优点
-
引入Self-Attention后会更容易捕获句子中长距离的相互依赖的特征,
因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小 -
Self-Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
-
除此外,Self-Attention对于增加计算的并行性也有直接帮助作用
https://mp.weixin.qq.com/s/RFLPII-1gQAa8hjuULyEjw
非常好的解释
Attention 和 self-attention 的区别是什么
- 在神经网络中,通常来说你会有输入层(input),应用激活函数后的输出层(output),在RNN当中你会有状态(state)。如果attention (AT) 被应用在某一层的话,它更多的是被应用在输出或者是状态层上,而当我们使用self-attention(SA),这种注意力的机制更多的实在关注input上。
- Attention (AT) 经常被应用在从编码器(encoder)转换到解码器(decoder)。比如说,解码器的神经元会接受一些AT从编码层生成的输入信息。在这种情况下,AT连接的是两个不同的组件(component),编码器和解码器。但是如果我们用SA,它就不是关注的两个组件,它只是在关注你应用的那一个组件。那这里他就不会去关注解码器了,就比如说在Bert中,使用的情况,我们就没有解码器。
- SA可以在一个模型当中被多次的、独立的使用(比如说在Transformer中,使用了18次;在Bert当中使用12次)。但是,AT在一个模型当中经常只是被使用一次,并且起到连接两个组件的作用。
- SA比较擅长在一个序列当中,寻找不同部分之间的关系。比如说,在词法分析的过程中,能够帮助去理解不同词之间的关系。AT却更擅长寻找两个序列之间的关系,比如说在翻译任务当中,原始的文本和翻译后的文本。这里也要注意,在翻译任务重,SA也很擅长,比如说Transformer。
- **AT可以连接两种不同的模态,**比如说图片和文字。**SA更多的是被应用在同一种模态上,**但是如果一定要使用SA来做的话,也可以将不同的模态组合成一个序列,再使用SA。