1、构建SVM情感分析模型
读取数据
使用pandas的库读取微薄数据读取并使进行数据打乱操作
import pandas as pd
test = pd.read_csv(".\\weibo.csv")
test_data = pd.DataFrame(test)[:1000]
test_data
打乱数据
re_test_data = test_data.sample(frac=1).reset_index(drop=True)
分词处理
对处理后的数据进行分词处理这里我们使用python的jieba库
import jieba_fast as jieba
import re
# 使用jieba进行分词
def chinese_word_cut(mytext):
# 去除[@用户]避免影响后期预测精度
mytext = re.sub(r'@\w+','',mytext)
# 去除数字字母的字符串
mytext = re.sub(r'[a-zA-Z0-9]','',mytext)
return " ".join(jieba.cut(mytext))
# apply的方法是将数据着行处理
re_test_data['cut_review'] = re_test_data.review.apply(chinese_word_cut)
停用词处理
import re
# 获取停用词列表
def get_custom_stopwords(stop_words_file):
with open(stop_words_file,encoding='utf-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
cachedStopWords = get_custom_stopwords(".\\stopwords.txt")
数据分割
分词后我们对数据进行训练数据分分割处理
X = re_test_data['remove_strop_word']
y = re_test_data.label
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
使用TFIDF和朴素贝叶斯训练数据
%%time
# 加载模型及保存模型
from sklearn.externals import joblib
# 朴素贝叶斯算法
from sklearn.naive_bayes import MultinomialNB
# TFIDF模型
from sklearn.feature_extraction.text import TfidfVectorizer
# 管道模型可将两个算法进行连接
from sklearn.pipeline import Pipeline
# 将TFIDF模型和朴素贝叶斯算法连接
TFIDF_NB_Sentiment_Model = Pipeline([
('TFIDF', TfidfVectorizer()),
('NB', MultinomialNB())
])
# 取三万条数据进行训练
nbm = TFIDF_NB_Sentiment_Model.fit(X_train[:80000],y_train[:80000])
nb_train_score = TFIDF_NB_Sentiment_Model.score(X_test,y_test)
joblib.dump(TFIDF_NB_Sentiment_Model, 'tfidf_nb_sentiment.model')
print(nb_train_score)
使用TFIDF和SVM训练数据
%%time
from sklearn.svm import SVCTFIDF_SVM_Sentiment_Model = Pipeline([
('TFIDF', TfidfVectorizer()),
('SVM', SVC(C=0.95,kernel="linear",probability=True))
])
TFIDF_SVM_Sentiment_Model.fit(X_train[:30000],y_train[:30000])
svm_test_score = TFIDF_SVM_Sentiment_Model.score(X_test,y_test)
joblib.dump(TFIDF_SVM_Sentiment_Model, 'tfidf_svm1_sentiment.model')
模型预测
# model = joblib.load('tfidf_svm1_sentiment.model')
model = joblib.load('tfidf_nb_sentiment.model')
# 获取停用词列表
cachedStopWords = get_custom_stopwords(".\\stopwords.txt")
# 判断句子消极还是积极
def IsPoOrNeg(text):
# 加载训练好的模型
# model = joblib.load('tfidf_nb_sentiment.model')
# 去除停用词
text = remove_stropwords(text,cachedStopWords)
# jieba分词
seg_list = jieba.cut(text, cut_all=False)
text = " ".join(seg_list)
# 否定不处理
text = Jieba_Intensify(text)
# y_pre =model.predict([text])
proba = model.predict_proba([text])[0]
if proba[1]>0.4:
print(text,":此话极大可能是积极情绪(概率:)"+str(proba[1]))
return "积极"
else:
print(text,":此话极大可能是消极情绪(概率:)"+str(proba[0]))
return "消极"IsPoOrNeg("什么玩意 不好 不开心")
预测结果如下:![]()
对疫情评论数据进行处理
import pandas as pd
# 去除停用词和特殊字符
def review_process(text):
return text.replace("🙏","")
# 读取csv的数据并取评论数据集
weibo = pd.read_csv("./Datashuju.csv",header=None)
weibo = pd.DataFrame(weibo[1])
# 去除特殊字符
weibo[1]= weibo[1].apply(review_process)
# 清除空行数据
weibo = weibo.dropna()
疫情评论词词云图
# pip install wordcloud
#生成词云
import wordcloud
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 将数组转化为字符串
word_show = ' '.join(weibo[1])
w = wordcloud.WordCloud(font_path="msyh.ttc", width=1000, height= 700,background_color="white", max_words=100)
# 传入功能主治的字符串生成词云图
w.generate(word_show)
w.to_file("hot_word.jpg")plt.figure(figsize=(8,8.5))
plt.imshow(w, interpolation='bilinear')
plt.axis('off')
plt.title('评论内容词云图', fontsize=30)
plt.show()

情感统计
weibo[2] = None
weibo[2] = weibo[1].apply(IsPoOrNeg)

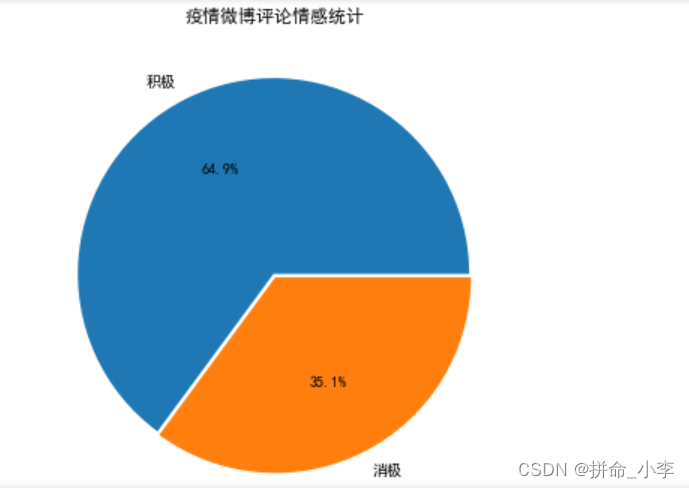
疫情微薄评论情感统计图
lable = list(dict(weibo[2].value_counts()).keys())
value = list(weibo[2].value_counts())
explode=[0.01,0.01]
plt.figure(figsize=(6, 6))
plt.pie(value,explode=explode,labels=lable,autopct='%1.1f%%')#绘制饼图
plt.title('疫情微博评论情感统计')
plt.show()
![]()